title: GAN网络详解(四) - 使用WGAN生成动漫头像 date: 2022-05-19 17:38:22 tags: GAN
本文将会介绍一个我的项目,使用WGAN-GP生成动漫头像.
项目地址: Github-Anime-WGAN

简介
其实这个项目的起因很简单,就是想动手实践一下,顺着GAN往下学就到了WGAN-GP,然后就搜了搜代码找了一个很不错的项目跟着改了改,然后完成了这次任务
关于具体的训练细节,实验结果,潜在空间探索等等内容我都在项目的README里面写的很详细了,这里不再赘述,主要想讲一讲一些细节的部分
有关模型
DCGAN,WGAN模型都继承了BasicGAN,所有的函数定义,基本实现什么的也都放在了这里,子类专注于重载train方法就可以了
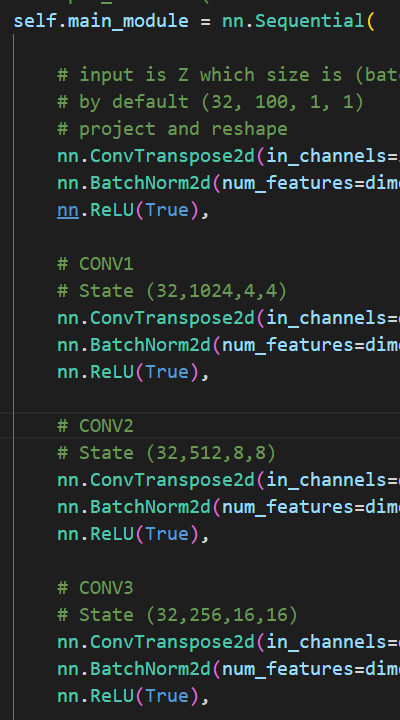
最开始我尝试了DCGAN来训练,遇到了经典的 mode collapse问题, 详见之前的文章.于是我调查了一些原因,最后选择使用WGAN-GP来跑
最开始的我找的两个数据集都是96x96的,然后我改了改模型的结构,输出了一份64x64的动漫头像

这是一些比较好的结果,看起来还不错
然后我就想扩大这个图像的分辨率,变成256x256的,然后我就想找一个数据集256x256像素的,但是没找到.然后我索性就直接搞了爬虫去自己爬,然后动漫人脸识别,然后再剔除不好的样本,前前后后搞了好长好长时间,数据集在这里,结果第二天我就找到了一个512x512的数据集,更大,更好,真的不知道说啥了...
接下来就是该模型,于是我就照葫芦画瓢呗,改一个256x256的,但是马上就出了问题
首先就是来的一个问题,模型太大了,连续的卷积这个维度太高了,爆显存了.于是我又调整维度,又去改batch size,最后好不容易可以正常训练了.
然后又马上来了一个更致命的问题,生成的图像及其诡异,具有非常明显的诡异色块?这我也没改啥啊? 于是我赶紧去调查了一下,发现了这其实是一个转置卷积操作带来的问题 : 棋盘效应
反卷积有许多解释和不同的名称,包括“转置卷积”
{% note info %} 关于这个问题,这篇文章其实已经探讨的非常详细了
问题就是出在这个转置卷积的操作 nn.ConvTranspose2d.当我们让神经网络生成图像时,我们经常让它们从低分辨率、高级描述中构建图像。这允许网络描述粗略的图像,然后生成详细图像
为了做到这一点,我们需要一些方法来从较低分辨率的图像到较高的图像。我们通常使用反卷积运算来执行此操作。粗略地说,反卷积层允许模型使用小图像中的每个点在较大的图像中“绘制”正方形
不幸的是,反卷积很容易产生“不均匀的重叠”,在某些地方比在其他地方放置更多的隐喻颜料。特别是,当内核大小(输出窗口大小)不能被步幅(顶部点之间的间距)整除时,反卷积具有不均匀的重叠。虽然原则上,网络可以仔细学习权重以避免这种情况,但实际上神经网络很难完全避免它 {% endnote %}
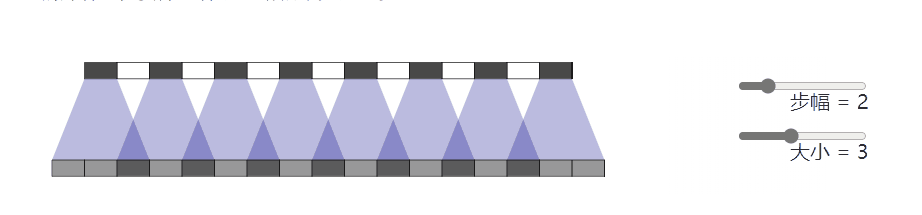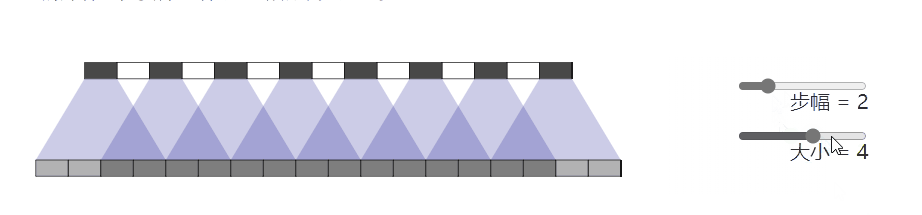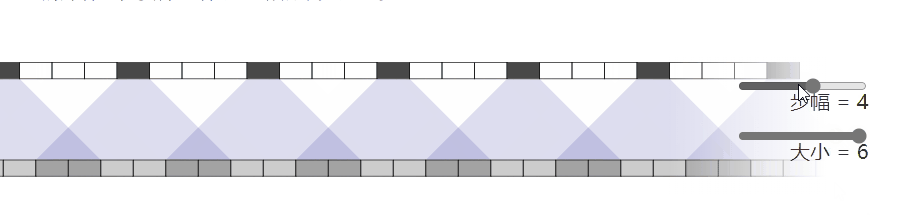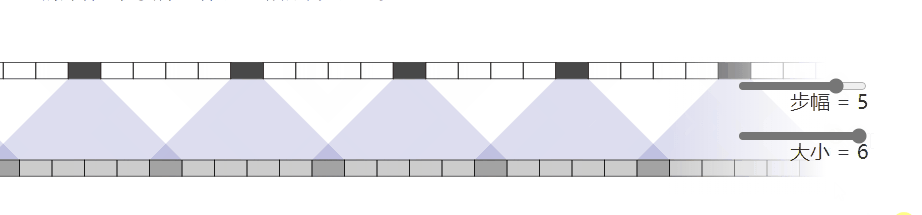
一个更加直观的例子
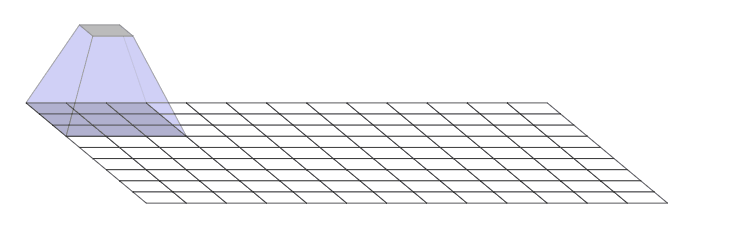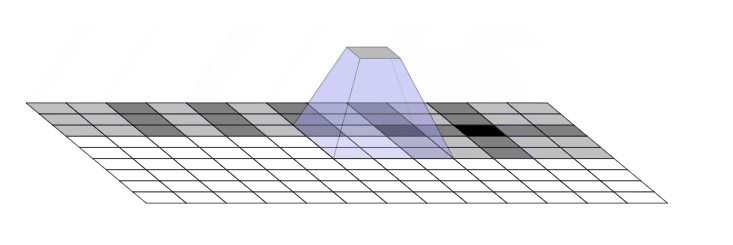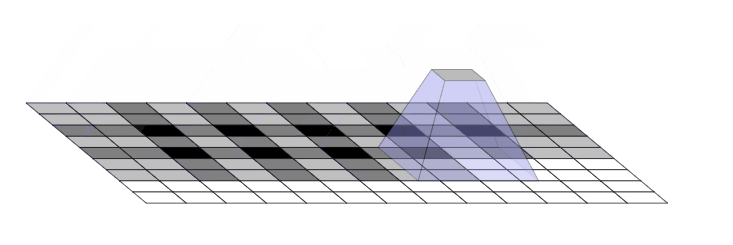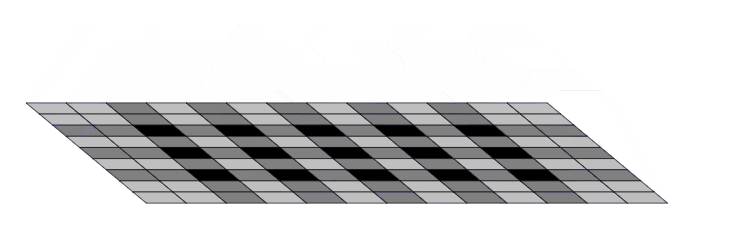
现在,神经网络在创建图像时通常使用多层反卷积,从一系列较低分辨率的描述中迭代构建更大的图像。虽然这些堆叠的反卷积可以抵消伪像,但它们通常会复合,从而在各种尺度上创建伪影
一种方法是将上采样从卷积分离到更高的分辨率,以计算特征。例如,您可以调整图像大小(使用最近邻插值或双线性插值),然后执行卷积层。这似乎是一种自然的方法,并且大致类似的方法在图像超分辨率
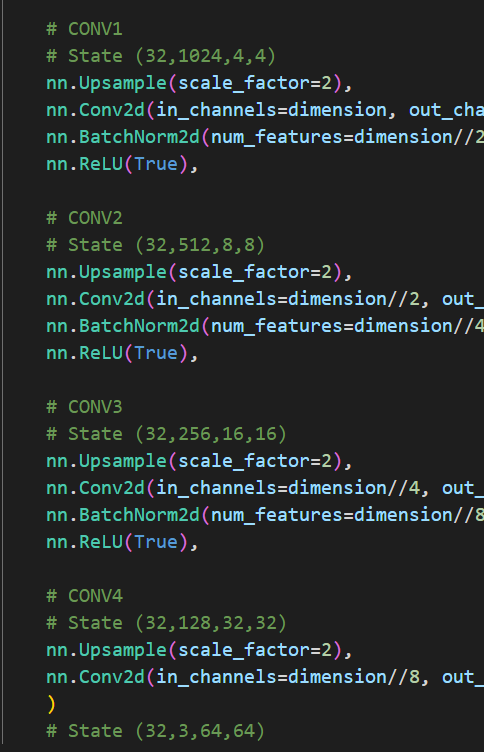
这就是我为什么又给64x64的模型补做了WGANP,它的改变就是将 nn.ConvTranspose2d 调整为 nn.Unsample + nn.Conv2d
 |  |
|---|
虽然在64x64的并不明显,但是要是在256x256里使用反卷积这种棋盘效应会及其明显,很遗憾我并没有保留当时的图片,现在也找不到了,不过确实及其明显
后来我改成了上采样+卷积仍然效果不好,依然很差很差,于是我又去找了找其他的论文,发现了一个论文也是做这个动漫头像生成的,但是这个论文比较早了,更新的论文我也没有去调研,有点懒得搞了.
这个论文还给了一个可以直接在线体验的网站: https://make.girls.moe/#/ , 感觉还是挺好的,虽然有时候头发颜色白色生成的不是很好(老白毛控了) 然后我就去学这篇论文的架构,它用了残差的思想,所以我也加了残差连接,结果还是不理想,现在大概是长成这样

后来我就懒得搞了,搞一个64x64得了,一下子扩展维度这个怕是有点困难,也许小模型还凑活看看大模型就不太好使了
有关评价指标可以参考文章