title: GAN网络详解(一) - 基本原理及数学推导 date: 2022-05-12 00:00:47 tags: GAN
生成对抗网络(GAN)的出现可以说在深度学习领域具有划时代的意义,如今GAN也被广泛应用于各种机器学习的场景之中.GAN系列也是我个人学习过程的收获和心得,分享出来希望可以学习进步,欢迎批评指正
本系列预计使用四个部分分别介绍:
- GAN的基本原理及数学推导
- GAN的不足之处
- WGAN-CP,以及后续的改进版本WGAN-GP
- 一个我的Github项目,使用WGAN-GP生成动漫头像
GAN的基本原理
GAN的基本原理其实非常简单.假设我们有两个网络,G(Generator)和D(Discriminator)
- G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)
- D是一个判别网络,判别一张图片是不是"真实的". 它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率. 0 ~ 1 的范围表示判别器认为这张图像是真实图像的概率是多少.
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D.而D的目标就是尽量把G生成的图片和真实的图片分别开来.这样,G和D构成了一个动态的"博弈过程".
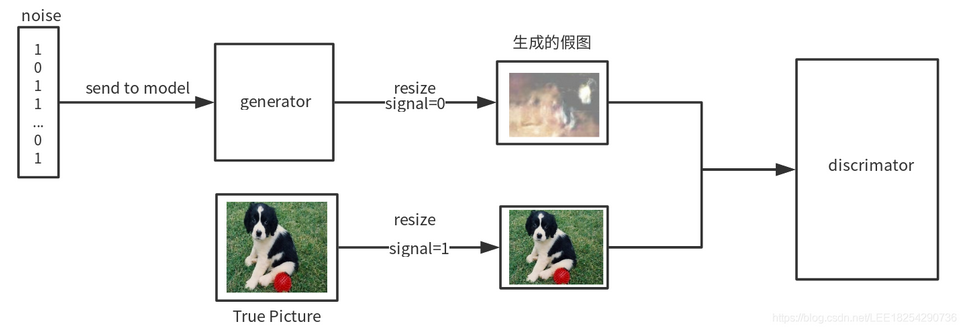
图源:https://blog.csdn.net/LEE18254290736/article/details/97371930
最后博弈的结果是什么? 在最理想的状态下,G可以生成足以"以假乱真"的图片G(z).对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5.这个思想还是比较巧妙的.
这里借用李沐老师在GAN论文逐段精读中的讨论,我觉得讲解的非常清楚
{% note info %} 假设你在玩游戏,你的显示器是4K的分辨率60fps,然后我说我要学一个生成器可以也能够生成跟游戏一样的图片,具体来说就是要生成一个 x ,大约是800万像素点,就是一个长为800万维的一个多维随机变量,我们认为每一个像素的值都是由后面的一个分布来控制的就是这个 pg,当我们知道我们这个分布其实就是对应的我们游戏那一个程序
那么我们的生成模型怎么样输出 x 呢? 在一个输入的噪音变量上面叫噪音变量是 z 然后这个分布是 pz. z 你可以认为就是一个100维的一个向量每一个元素是一个均值为0方差为1的一个高斯噪音.我的生成模型就是把 z 映射成 x
那么回到这个游戏的例子假设,你想生成游戏的图片,我去反汇编你的游戏代码,然后把代码给你拎出来那我就真正的知道这个游戏是怎么生成出来的,但是这种途径是代表的我们要去构造那个分布,在计算上比较难计算
那么索性干脆就不管那个游戏程序怎么来的,虽然是 4k 的图片但是实际上呢他背后就是一些代码控制,可能就是那么100个变量控制.哪个人物出现在哪个位置,然后他们在干什么事情.虽然我不知道具体是什么东西,那么我估摸着你大概就是一个100维的向量足以表达你这些背后隐藏的一些逻辑
因为我们知道 MLP 理论上可以拟合任何一个函数,那我就干脆说构造一个差不多大小的向量然后这个 MLP 都强行把这个 z 映射成我要的那些 x 使的长得很像就行了
这个好处是算起来比较简单,但坏处也很明显.因为MLP其实不是真正的去了解他的代码,那么就是说我看到某一个图片的时候我很难去找到他背后对应的 z 是什么东西,而只能反过来说我每次随机的给你一个 z 然后看你看手气,生成一个也还像样的一个图片就行了,所以这是他带来的不方便的地方
{% endnote %}
{% note info %} 对于判别器D来说,D 也是个 MLP,他的作用是把800万的像素的图片放进来然后他输出一个标量
他要去判断你这个 x 到底是来自你真实采样的数据呢还是你生成出来的图片
在前面那个例子就是说你的这个图片到底是来自于在游戏中的截图还是你的生成器生出来的图片
因为我们知道我们的数据到底是哪里来的所以我们就给数据一个标号.如果来自真实的数据就是 1如果来自于生成器就是 0 那我们就采样一些数据训练一个两类的分类器 {% endnote %}
论文中也给出了博弈双方的数学公式
$$ \min\limits_{G}\max\limits_{D}V(D,G) = E_{x\thicksim p_{data(x)}}[\log D(x)] + E_{z\thicksim p_{z(z)}}[\log(1-D(G(z)))] $$
这个公式看上去很复杂,其实他是D G 共同求解的一个博弈过程.
对于x,z分别来自两个分布,一个是真实数据的分布data,一个是噪声的分布Z. D的计算式是 $\log D(x) + \log(1-D(g(z)))$,理想状态D可以完美区分来自真实图片x的数据(D(X)=1)和来自生成器图片的数据(D(G(z))=0),即 $\log 1 + \log 1 = 0$ ,但事实上判别器D存在误分类的问题,所以两项都为负值,优化的方向是max,希望求得最大为0
对于生成器 G 的优化只有一项,G的目的就是使得判别器误判,也就是期望D(G(z))=1,希望后式从 $\log(1-0)=0$ 优化到 $\log(1-1)= -\infty$
这是一个双人的minmax游戏,需要生成器G和判别器D同时训练,同时优化.
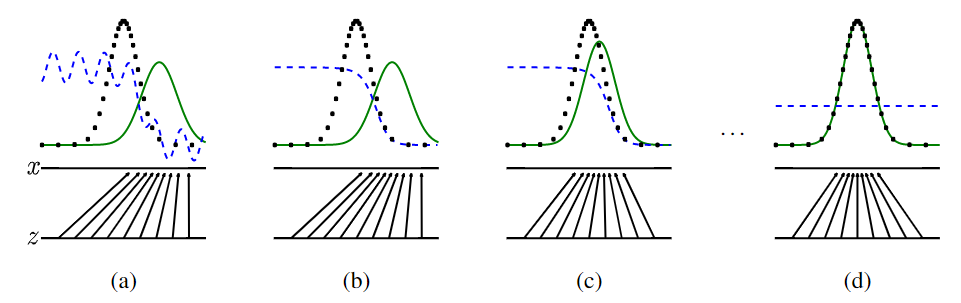
最开始a状态真实图像的分布$p_{data}$(黑线)和生成的图像$p_z$(绿线)具有显著的差异,判别器(蓝线)可以很轻易的分辨,后来两者的分布趋势逐渐相似,直至最后完全相同,此时判别器已无法准确分辨(0.5)
GAN的算法思路
论文也提供了具体的算法伪代码

{% note success %} 该算法的语言描述为,一共进行N次循环迭代,每次迭代首先训练K(默认为1)次判别器,从噪音分布$p_z$中取m个噪音样本输入给G生成图片,和从真实分布$p_{data}$中的m个真实样本一起,反向传播计算更新判别器D的梯度,正向更新求最大
然后再从噪音分布$p_z$中取m个噪声样本,更新生成器G的梯度,反向更新求最小 {% endnote %}
pytorch版本的简略代码如下,值得一提的是GAN论文本身并没有提出模型的结构,如果读者有兴趣可以自己构建两个模型然后找一些数据集来训练一下.
import torch
import torch.nn as nn
# define the model structure by yourself
D = discriminator()
G = generator()
# compute BCE_Loss using real images where BCE_Loss(x, y): - y * log(D(x)) - (1-y) * log(1 - D(x))
loss_fn = nn.BCELoss()
d_optimizer = torch.optim.Adam(D.parameters())
g_optimizer = torch.optim.Adam(G.parameters())
for epoch in EPOCHS:
for id, data in enumerate(train_loader):
# init labels for real images and fake images
real_labels = torch.ones(32)
fake_labels = torch.zeros(32)
# first update for discriminator
for i in range(k):
# init random noise
z = torch.randn((32,100,1,1))
real_images = data
outputs = D(real_images)
d_loss_real = loss_fn(outputs,real_labels)
fake_images = G(z)
outputs = D(fake_images)
d_loss_fake = loss_fn(outputs,fake_labels)
# calculate d_loss
d_loss = d_loss_real + d_loss_fake
# update D
D.zero_grad()
d_loss.backward()
d_optimizer.step()
# start to update G
z = torch.randn((32,100,1,1))
fake_images = G(z)
outputs = D(fake_images)
g_loss = loss_fn(outputs,fake_labels)
D.zero_grad()
G.zero_grad()
g_loss.backward()
g_optimizer.step()这种思路看起来没什么问题,但是在实际训练的时候存在很多问题.
就好比警察和造假钞的人,如果你的警察特别厉害,一旦造出来一点假钞一下子就把造假钞的人一窝端了,那么你也得不到很好的假钞. 反过来如果说你的警察很弱,随便造一点假钞就能蒙混过关,那么造假钞的人没有动力去更新技术迭代机器了.最理想的情况是旗鼓相当的对手,互有胜负相互进步.Discriminator的火候把握令GAN网络的训练十分不稳定.
此外在训练初期,生成器G的生成效果很差,这时候你很容易就可以把判别器D训练的很好,这时候计算梯度更新G的时候由于判别器D训练的非常好,计算出的损失值很小,$\log(1-D(G(z)))$接近0,梯度很小,很难训练G
论文中也提出了一种改进做法是损失变为 $-\log(D(G(z)))$,这样做避免了梯度消失的问题,但是带来了新的问题,将会在下一节中介绍
GAN的数学推导
对于之前提到的
$$ V(D,G) = E_{x\thicksim p_{data(x)}}[\log D(x)] + E_{z\thicksim p_{z(z)}}[\log(1-D(G(z)))] $$
我们将期望E展开 $E_{x\thicksim p}f(x) = \int_x p(x)f(x)dx$,得到
$$ V(D,G) = \int_x p_{data(x)}\log D(x)dx + \int_z p_{z(z)}\log(1-D(G(z)))dz $$
然后将G(z)用x替换,得到
$$ V(D,G) = \int_x p_{data(x)}\log D(x)dx + \int_z p_{g(x)}\log(1-D(x))dx $$
合并两项得到
$$ V(D,G) = \int_x p_{data(x)}\log D(x) + p_{g(x)}\log(1-D(x))dx $$
里面的函数就是对于一个x,在两个分布data(x),g(x),求积分. 我们可以将其简化为
$$ V = a\log y + b \log(1-y) $$
这个函数是一个凸函数,我们可以很容易的计算其导数为0的位置
$$ \frac{a}{y} - \frac{b}{1-y} = 0 $$
$$ y = \frac{a}{a+b} $$
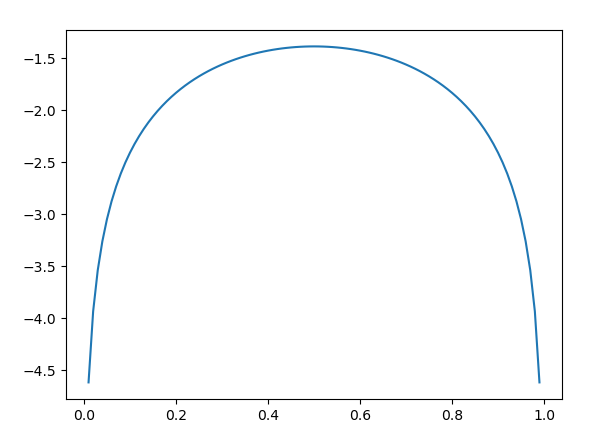
当G固定住了,最优的D的计算式为:
$$ D^*_G(x) = \frac{P_{data}(x)}{P_{data}(x) + P_g(x)} $$
其中data代表真实数据的分布,$P_{data}$也就是说我把一个x放在这个分布中得到的概率是多少. $P_g$就是生成器所拟合的分布中将x带入后的概率
一个分布的概率是在 $[0\thicksim 1]$之间的,所以这个概率值的范围也是$[0\thicksim 1]$的,同时当data和g的分布完全相同时这个值取到0.5,表示这两个分布我是完全分不开的
{% note info %} 单独看这个公式也是非常有用的. D 的训练过程就是单独从两个分布里取数据,使用之前的目标函数训练一个二分类的分类器,如果说这个分类器给的值是0.5那么就代表这两个分布是重合的
当我们希望判断训练数据样本和测试数据样本或者说真实环境中的样本是否相同时,我们就可以训练一个二分类分类器,如果不能成功分类那么就可以说明这两个分布是相同的 {% endnote %}
所以我们现在得到了最有情况下D的计算式,将其带入D G的共同优化公式之中
$$ \min\limits_{G}\max\limits_{D}V(D,G) = E_{x\thicksim p_{data(x)}}[\log D(x)] + E_{z\thicksim p_{z(z)}}[\log(1-D(G(z)))] $$
得到对于G的优化公式为
katex这个多行公式显示不出来
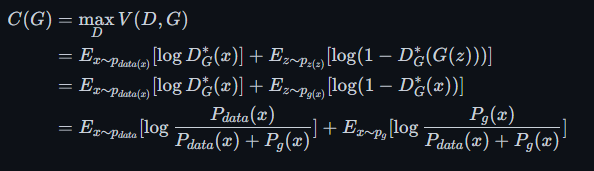
最后的结果可以表示为两个KL散度之和
{% note info %} KL散度是用来衡量两个分布之间的差异程度,若两者差异越小,KL散度越小,反之亦反.当两分布一致时,其KL散度为0
$KL(P||Q) = E_{x\thicksim p}\log\frac{p(x)}{q(x)}$
KL散度是非对称的,即$KL(P||Q)\neq KL(Q||P)$
关于更多有关KL散度可以参考-博客 {% endnote %}
所以上式可以修改为
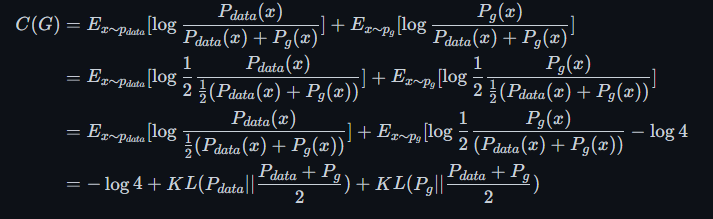
为了得到最小的G,只需要使 $KL(P_{data}||\frac{P_{data}+P_g}{2})$ 和 $KL(P_g||\frac{P_{data}+P_g}{2})$同时取最小值0,即$P_{data}=P_g$
{% note info %} 同时作者也提到了将两个KL散度合并为JS散度,这里就不做展开了,有兴趣的朋友可以了解一下
$C(G) = -\log4 + 2*JSD(p_{data}||p_g)$
{% endnote %}
所以现在可以通过数学推导得出公式计算的合理性,即只有生成器生成的分布和真实图片分布相同时才会取得最小值,优化的方向没有问题
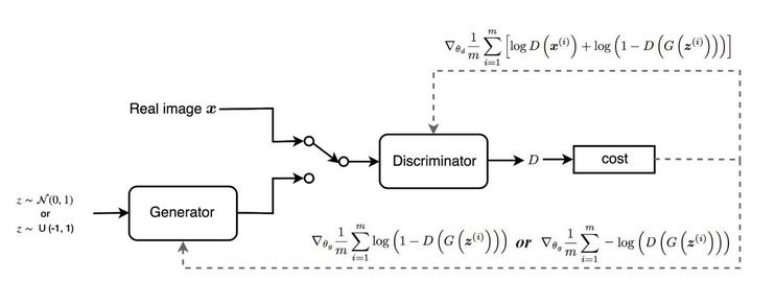
不过正如前文所说,GAN网络的训练的过程是十分困难的,因为需要兼顾D G两者的训练程度,极其不稳定.
尽管GAN论文存在一些问题,但并不妨碍这是一个很有创新性的工作,后期也有很多人对原始GAN网络进行改进.比如下一节将会介绍的DCGAN,WGAN等等