title: cache date: 2022-12-28 20:18:43 tags: 体系结构
cache
众所周知,不同存储技术的访问时间差异很大,速度较快的技术每字节成本要比速度较慢的技术高,而且容量小.
下图是一个经典的计算机存储器结构层次,高层向底层走存储设备变得更慢,更便宜和更大.
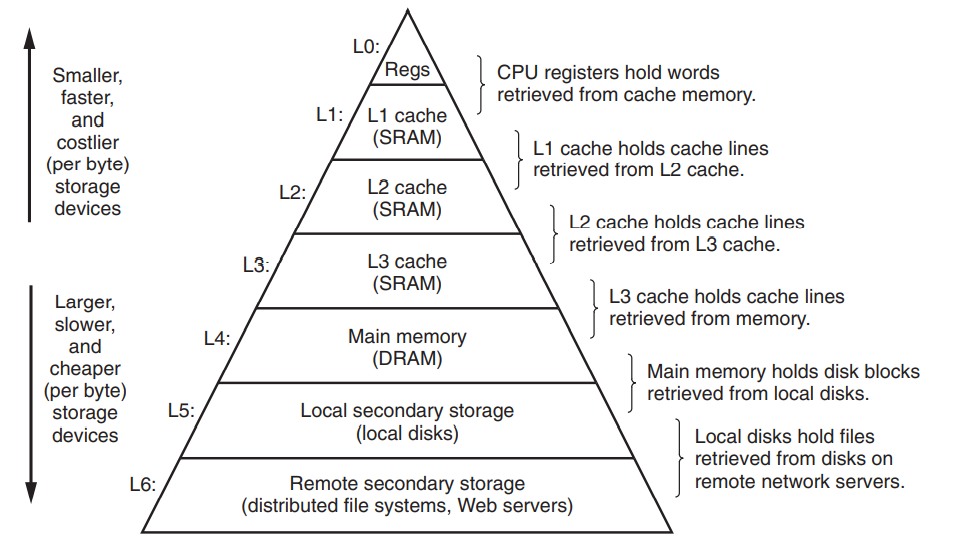
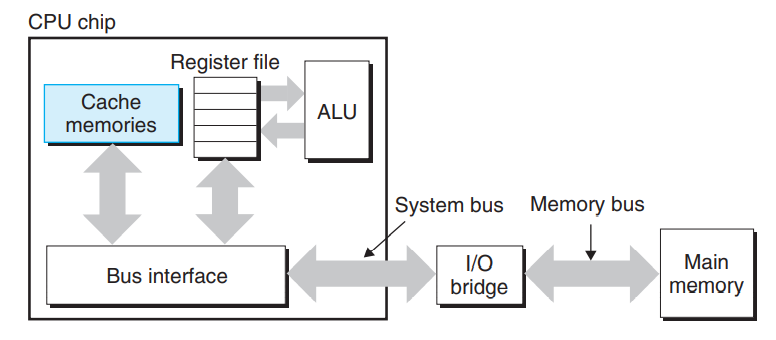
早期计算机系统的存储器层次只有三层,CPU寄存器,DRAM主存储器,磁盘存储.由于CPU和主存之间的频率逐渐增大,系统设计者被迫在CPU寄存器文件和主存之间插入了一个小的SRAM高速缓存,被称为L1高速缓存(一级缓存),如下图所示.L1高速缓存的访问速度几乎和寄存器一样快,典型的是4个时钟周期.
缓存组织结构
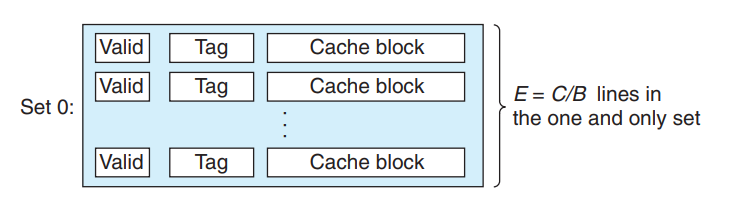
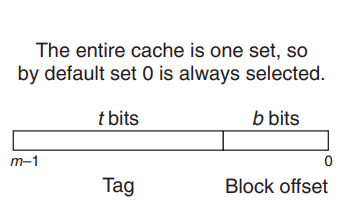
一般而言,高速缓存的结构可以用元组(S,E,B,m)来描述, S指一共有S个高速缓存组,每组E行,每一行中有效的缓存块的个数为B, m为主存物理地址长度(通常为64). 组织结构如下图所示:
每一个缓存块的大小都是 1 byte, 缓存块的个数 B 和 S 都是 2 的幂次, 即
S = 2^s,B = 2^b.
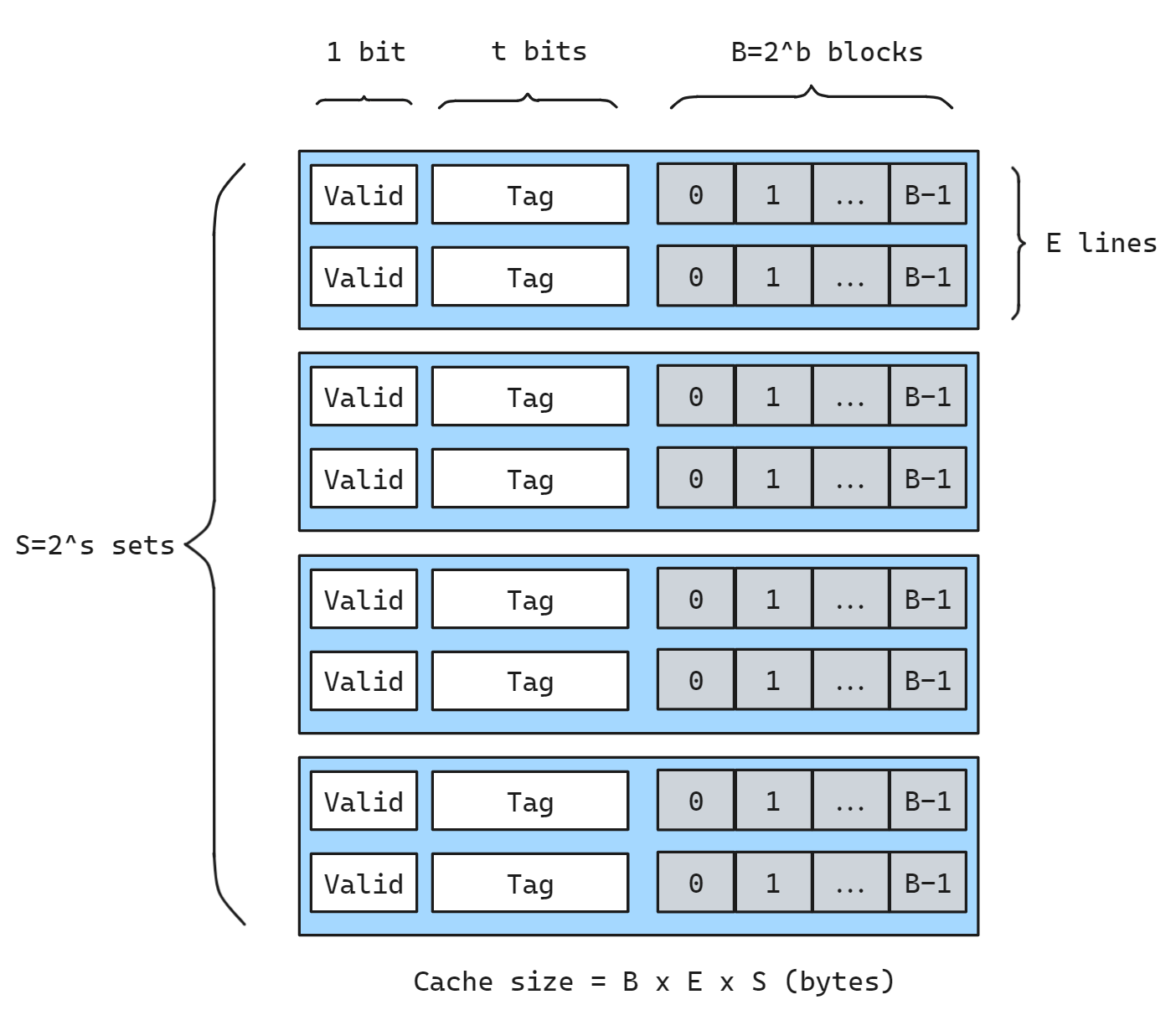
缓存总大小为 B x E x S 字节, 即图中灰色部分.
每一个缓存行除了缓存块还有 1 位有效位, 用于表示这个行是否包含有意义的信息; 以及 t 位标记位.
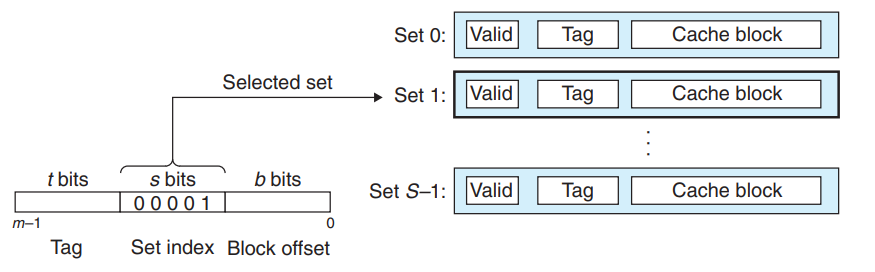
对于一个虚拟地址, 其在缓存中的地址会被划分成如下格式.
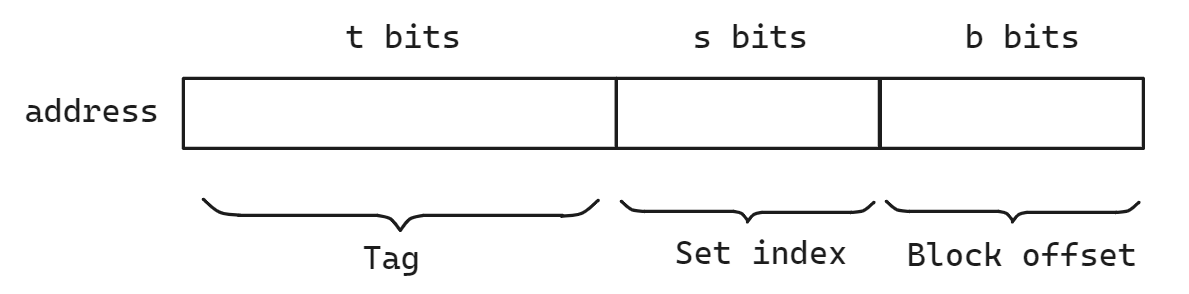
高速缓存一共S组,一共需要s位(2^s=S)来对应每一组, 每一行是一个高速缓存行.其中每一行有1位有效位,t位标记位,和B字节的缓存块大小, 因为计算机的地址长度m是确定的(一般32或者64),B字节大小的缓存块需要b位的偏移量来表示(2^b=B), 这里的t是计算出来的, 组索引占用s位, 每一个缓存块索引占 b 位, 所以 t = m-b-s, 即剩余部分都留作 tag 位
高速缓存可以被分为不同的类:
- 直接映射高速缓存
- 组相联高速缓存
- 全相联高速缓存
下面我们分别讨论一下
直接映射高速缓存
每个组只有一行(E=1)的高速缓存被称为直接映射高速缓存,这种情况是最容易实现和理解的
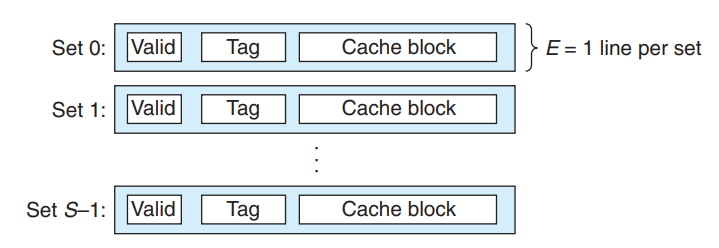
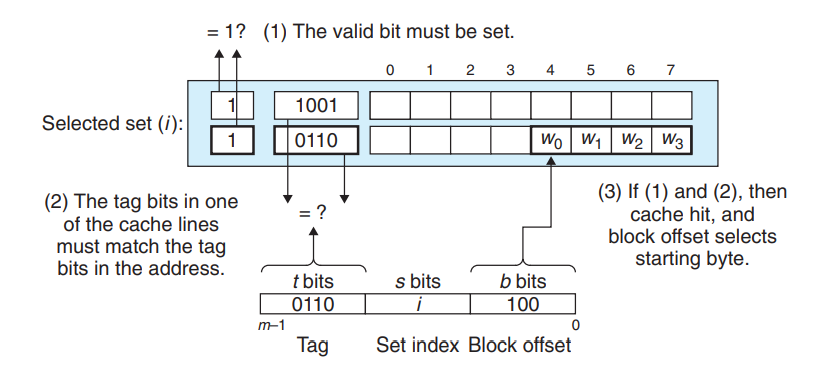
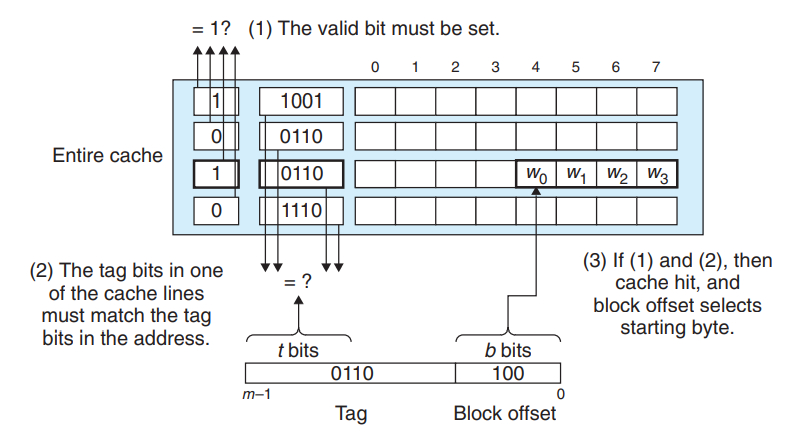
现在一条加载指令指示CPU从主存地址A中读取一个字,那么此时高速缓存如何判断此时缓存中是否保存着A地址处那个字的副本呢?
这个过程被分为三个部分: 组选择 + 行匹配 + 字选择
- 组选择
给定地址A,我们可以根据之前计算的t,s,b的数据截取其中s的部分,这是组索引,我们将高速缓存看成是一个关于组的移位数据,那么这些组索引位就是一个到这个数组的索引,例如下图中映射到组1
- 行匹配
上一步中已经选择了某个组,接下来就是确定这一组中是否存在A地址所在的缓存块,在直接映射高速缓存中这很容易因为只有一行.
首先判断有效位必须为1,如果没有设置有效位那么这个缓存块是没有意义的.接着截取A地址中的标记t,与缓存块中的标记t判断,如果相同则说明缓存命中.否则缓存不命中
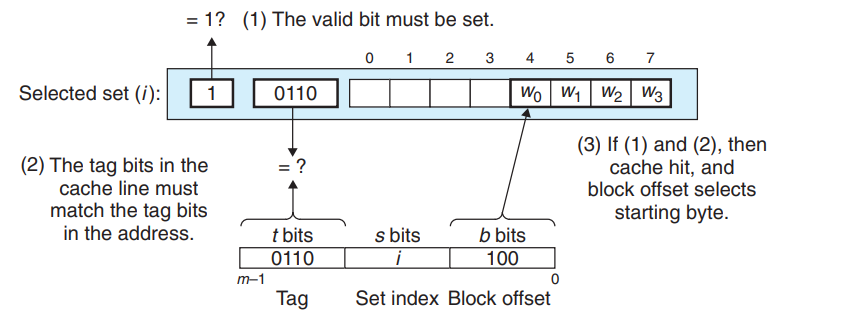
- 字选择
最后一步就是根据b在缓存块B中找到对应的位置,这里的b就是块偏移,如上图所示
每个缓存行会缓存 B 个块, b 位地址可以索引对应的块, 对于不同的类型数据(char short int)只需要依次索引(1/2/4)个缓存块即可
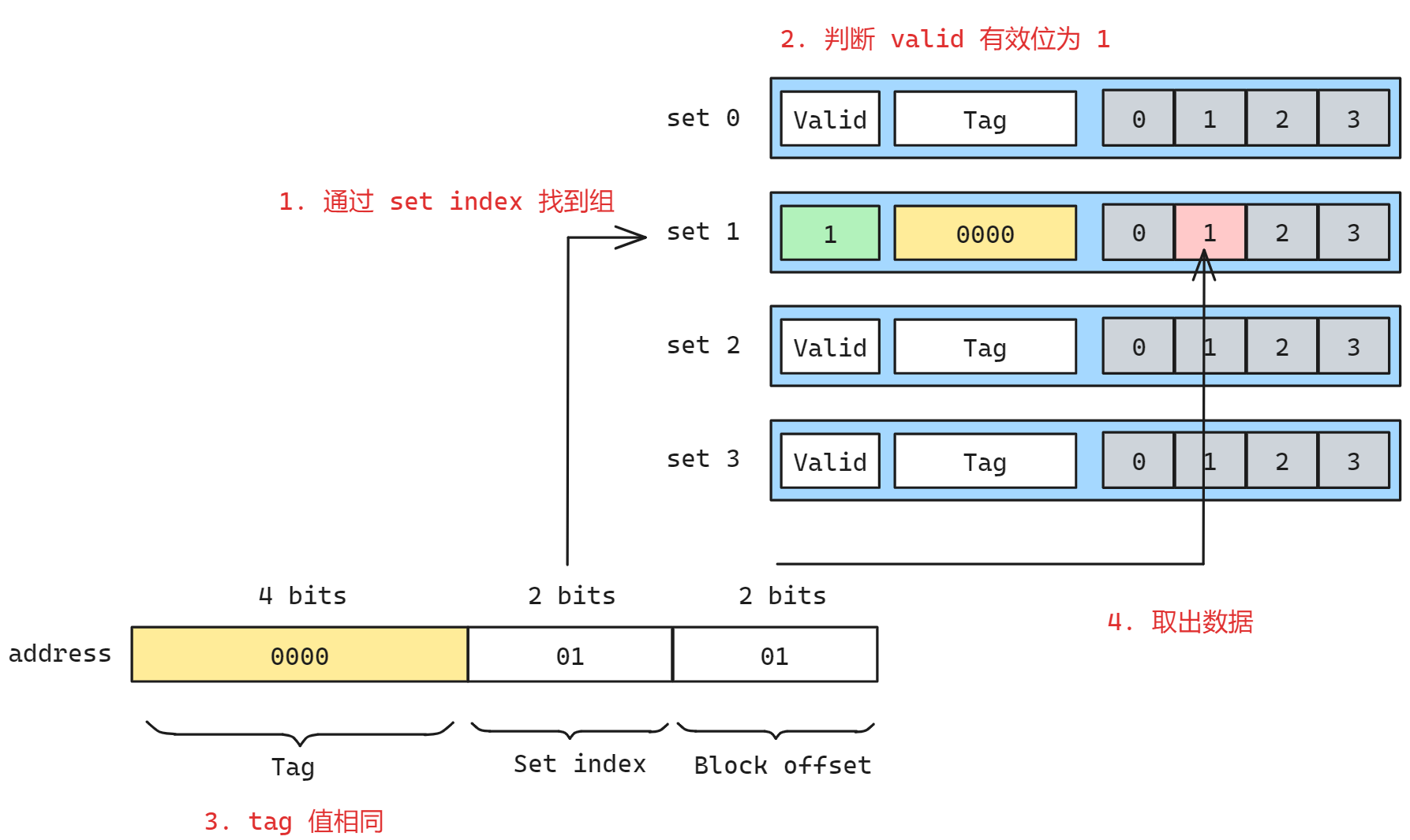
我们这里假设有如下的一个高速缓存,(S,E,B,m)=(4,1,4,8),换句话说高速缓存有4个组(S),s=2,每个组一行(E=1),每个块两个字节(b=2),地址8位(m=8), 则该缓存的结构如下图所示
计算可得 tag 位的长度 t = 8-2-2 = 4
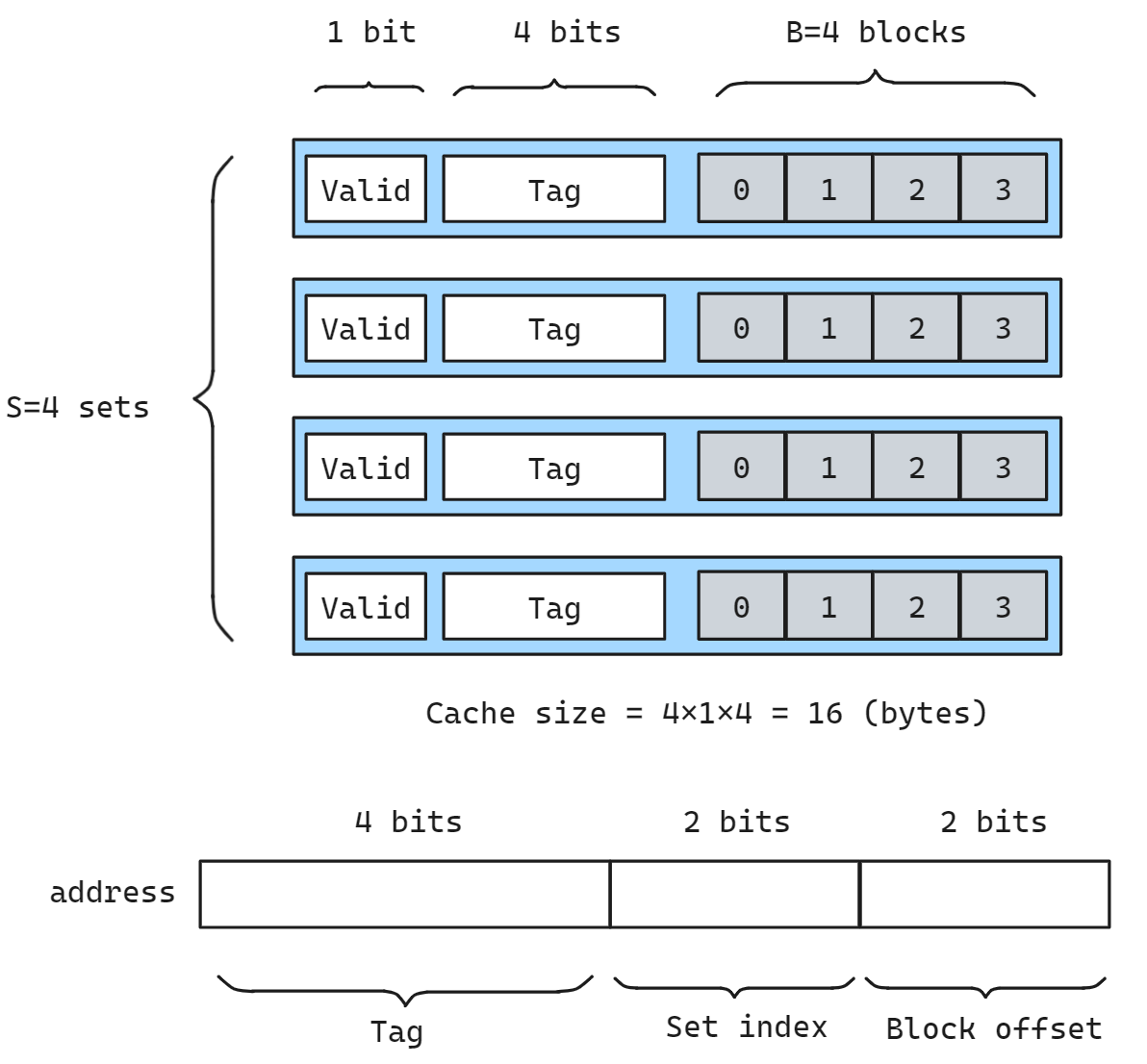
那么此时如果我们要读取地址 0x00000101 的 1 字节数据, 流程如下:
- 划分地址, 找到 tag, set, offset 的部分, 根据 set index 找到对应的缓存组
- 判断 valid 有效位为 1, 说明其是一个有效的缓存块, 若为 0 则认为缓存失效
- 判断 tag
0000和该缓存行的 tag0000是否相同, 如果相同则说明是相同的数据, 否则无效
- 取出数据
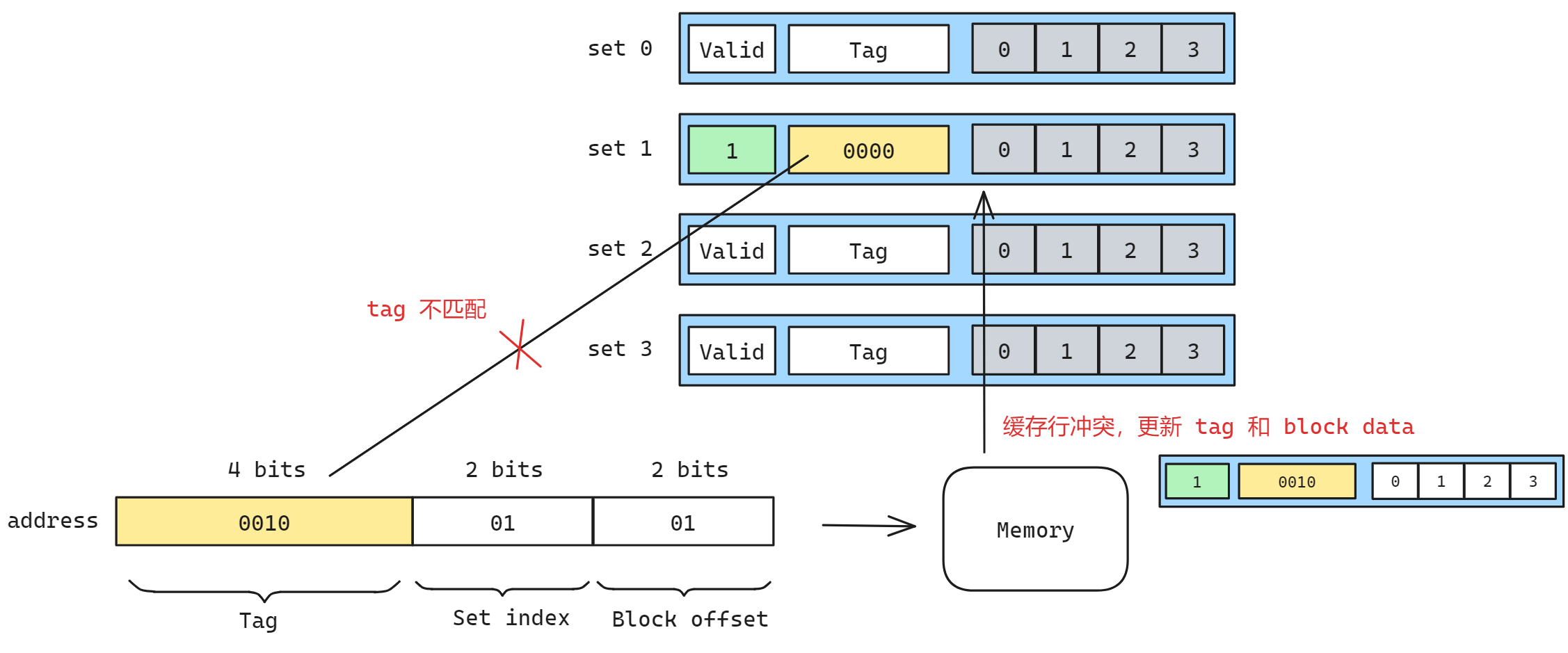
但是我们发现对于另一个地址 0x00100101 地址来说, 其 set index 与 0x00000101 相同, 也会映射到这个组. 此时 tag 不匹配发生缓存不命中, 需要再去内存中取数据, 然后使用新的数据更新缓存行, 新的 tag 新的 data
组相联高速缓存
直接映射高速缓存冲突不命中造成的问题源于每个组只有一行, 那么我们自然可以想到每一个组设置多个缓存行, 这就是组相联高速缓存
组选择和字选择阶段都没有变化,唯一的区别就是在行选择的阶段,由于有多行,所以进行有效位和标记位判断的时候需要扫描所有行
- 通过 set index 找到对应的组
- 依次判断组内所有的缓存行, 如果 valid 且 tag 相同, 则取数据
- 否则发生缓存不命中, 去内存中找, 选择一个缓存行进行更新
全相联高速缓存
全相联是指所有的组全部连接在一起, 直接省去了 S 的部分, 全相联中S=1,只有唯一的一个组,此时E=C/B, 如下图所示
且因为S=1,所以s=0,所以地址被划分为标记位和偏移量
其他选择方式与组相联完全相同,甚至砍掉了第一步的组选择, 直接搜索所有行
因为高速缓存电路必须并行的遍历所有行,匹配所有标记位,所以构造一个又大又快的相联高速缓存困难且昂贵,因此全相联高速缓存指适合做小的高速缓存, 例如虚拟内存中的快表TLB
高速缓存的写
高速缓存的读比较容易,但是写的情况就要复杂很多了.
假设我们要写一个已经缓存了的字(写命中,write hit),在告诉缓存更新它的副本w之后应该如何更新w在层次结构中低一层的副本呢?
最简单的办法称为写直达(write-through),就是立即将w的高速缓存块写回到低一层中,但是缺点是每次写回都会引起总线流量.
另一种办法称为写回(write back),尽可能地推迟更新,只有当替换算法要驱逐这个更新过的块时才把它写回到低一层中. 由于局部性,写回能显著的减少总线流量,但是它的缺点是增加了复杂性,高速缓存必须为每个高速缓冲行维护一个额外的修改位(dirty bit)表明这个高速缓冲块是否被修改过
另一个问题就是如何处理写不命中(write miss),一种方法称为写分配(write allocate),加载相应的低一层的块到高速缓冲,然后更新这个高速缓冲块.但是缺点是每次不命中都会导致一个块从低一层传送到高速缓冲.
另一种方法称为非写分配(not write allocate),避开高速缓冲,直接把这个字写到低一层中
为写操作优化高速缓存是一个细致且困难的问题,这里不再展开
真实的高速缓存层次
目前我们一直假设高速缓存中只保存程序数据,但事实上高速缓存除了保存数据也保存指令.保存指令的高速缓存称为i-cache,保存程序数据的高速缓存称为d-cache,既保存指令又保存数据的高速缓存称为统一的高速缓存
现代处理器包括独立的i-cache和d-cache,这样做有很多原因,有两个独立的高速缓存,处理器可以同时读一个指令字和一个数据字.i-cache通常是只读的,因此比较简单,并且可以针对不同的访问模式优化这两个高速缓存,可以有不同的块大小,相联度和容量
下图是Intel Core i7处理器的高速缓存层次,每个CPU芯片有四个核,每个核有自己私有的L1 i-cache L1 d-cache和L2统一高速缓存,所有核共享L3统一高速缓存,这里的一个有趣的特性是所有的SRAM高速缓存都在CPU芯片上
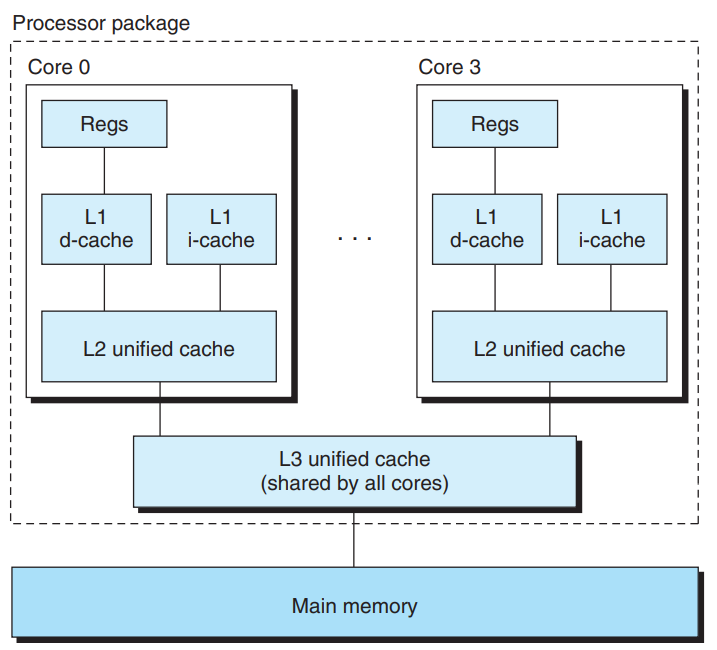
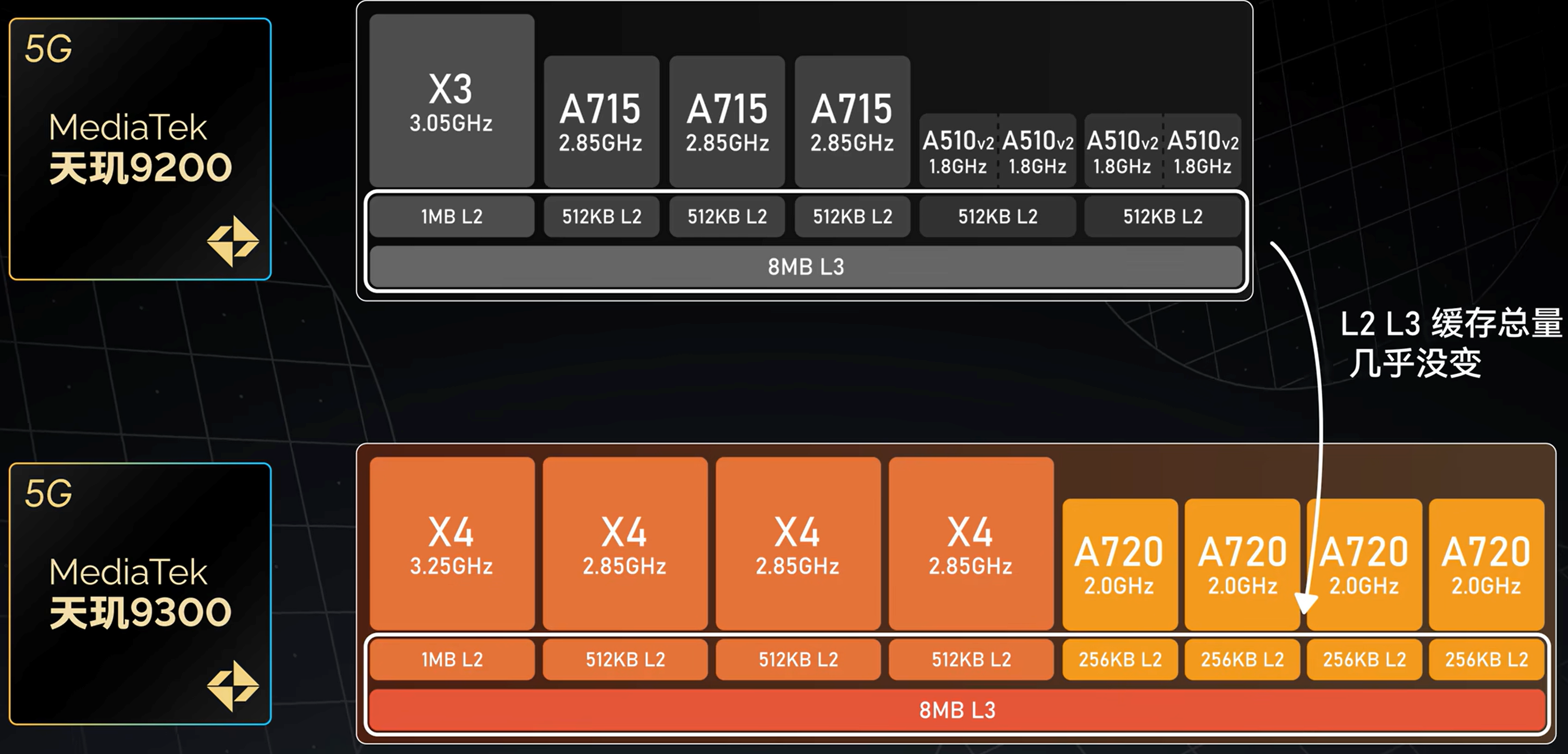
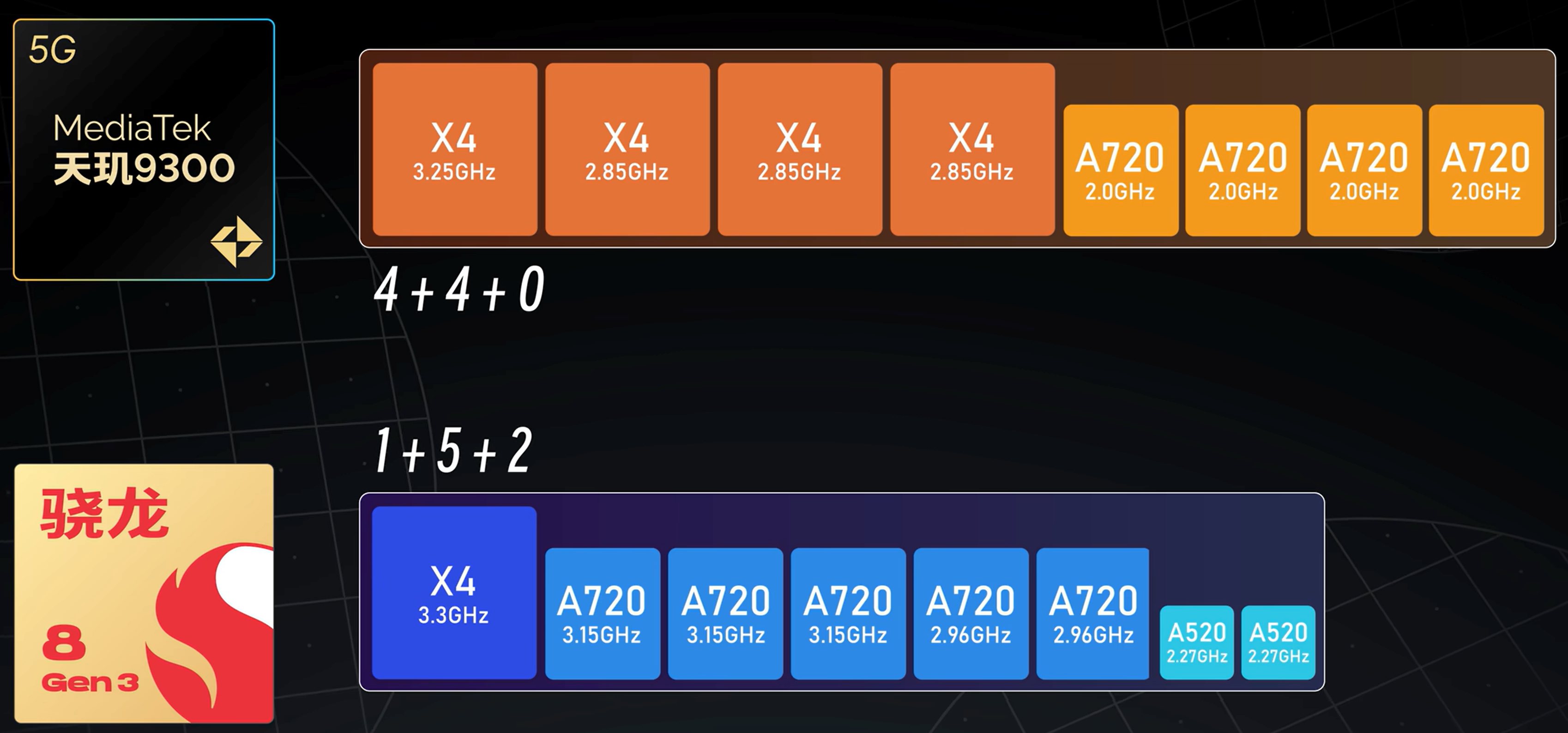
如今的处理器基本都是 3 级缓存结构, 如下图所示:
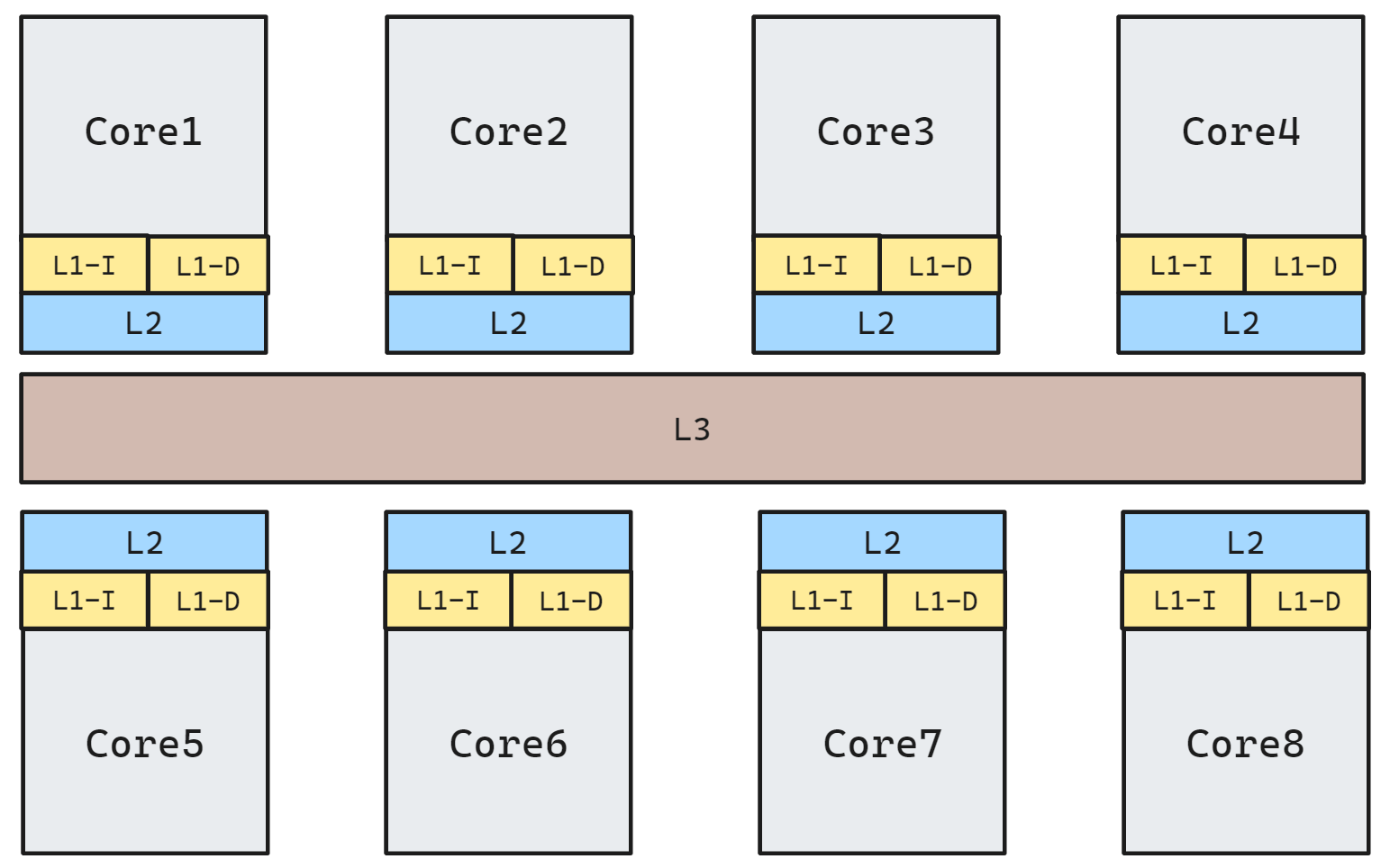
不同大小核的缓存大小也可能不相同

可以直接使用如下指令查看当前系统的缓存大小
$ lscpu
Caches (sum of all):
L1d: 384 KiB (8 instances)
L1i: 256 KiB (8 instances)
L2: 10 MiB (8 instances)
L3: 24 MiB (1 instance)