execve
shell 中最常见的操作就是执行程序, 此时 shell 会 fork 出一个子进程然后通过调用 execve() 来执行对应的任务。
if ((pid = fork()) == 0) {
// 子进程执行任务
if (execve(argv[0],argv,environ) < 0) {
printf("%s: Command not found\n",argv[0]);
exit(0);
}
} else {
// 父进程
wait();
}关于 shell 的实现参见 09-ShellLab
exec() 是一个函数族, 有诸如 execl/execlp/execle 等功能相似但实际上都是调用execve的库函数, 最核心的 execve 函数加载并运行可执行目标文件filename,并且带参数列表argv和环境变量列表envp,与fork返回两次不同。execve调用一次并且不返回,只有出现错误,比如找到不到filename才会返回到调用程序, 成功执行后原先子进程的栈。数据以及堆段会直接被新程序所替换
#include <unistd.h>
int execve(const char *filename, char *const argv[], char *const envp[]);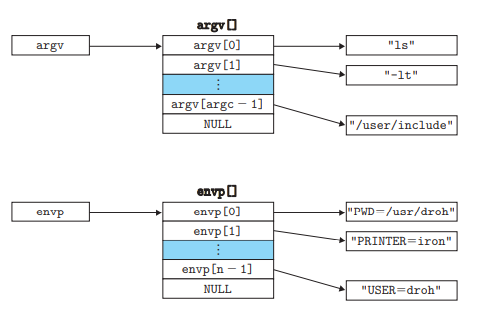
其中参数列表的数据结构如上图所示
argv变量指向一个null结尾的指针数组,每个指针指向一个参数字符串,通常来说argv[0]是可执行目标文件的名字
envp变量指向一个null结尾的指针数据,每个指针指向一个字符串,每个串都是类似"name=value"的键值对
一个进程一旦调用 exec函数,它本身就"死亡"了,系统把代码段替换成新程序的代码,放弃原有的数据段和堆栈段,并为新程序分配新的数据段与堆栈段,唯一保留的就是进程的 PID.也就是说,对系统而言,还是同一个进程,不过执行的已经是另外一个程序了。
加载过程
当用户进程调用 execve 时,系统会从用户态切换到内核态,并进入内核的相应处理函数。这个处理过程大致可以分为以下几步:
- 用户态调用: 用户进程调用
execve函数。
- 系统调用入口: 系统调用通过中断或快速系统调用路径进入内核, 根据 execve syscall number 定位到
sys_execve函数。// fs/exec.c SYSCALL_DEFINE3(execve, const char __user *, filename, const char __user *const __user *, argv, const char __user *const __user *, envp) { return do_execve(getname(filename), argv, envp); }详见 syscall
do_execve 是核心函数,它主要负责处理用户传入的参数、进行安全检查以及最终的进程替换。指向程序参数argv和环境变量envp两个数组的指针以及数组中所有的指针都位于虚拟地址空间的用户空间部分。因此内核在当问用户空间内存时, 需要将其复制到内核空间。
__user宏定义为空, 该宏的作用只是用来标记信息以便自动化工具检测
将指针封装为 user_arg_ptr 后进入 do_execveat_common, 该函数主要执行三部分内容:
- 创建
linux_binprm结构体并初始化该结构体用来保存要要执行的文件相关的信息, 包括可执行程序的路径, 参数和环境变量的信息。这个结构体内容比较多, 关键字段如下
struct linux_binprm { struct file *executable; /* Executable to pass to the interpreter */ struct file *interpreter; struct file *file; /* 要执行的文件 */ int argc, envc; /* 命令行参数和环境变量数目 */ const char *filename; /* 要执行的文件的名称 */ char buf[BINPRM_BUF_SIZE]; /* 保存可执行文件的头128字节 */ } __randomize_layout;
- 将用户空间的参数拷贝到内核空间
- 调用copy_strings_kernel()从内核空间获取二进制文件的路径名称
- 调用copy_string()从用户空间拷贝环境变量和命令行参数
- bprm_execve 执行程序
static int do_execveat_common(int fd, struct filename *filename,
struct user_arg_ptr argv,
struct user_arg_ptr envp,
int flags)
{
struct linux_binprm *bprm;
int retval;
bprm = alloc_bprm(fd, filename); // 创建二进制参数结构体,包含了关于可执行文件的信息
// 将用户提供的 argv 和 envp 复制到内核空间
retval = copy_string_kernel(bprm->filename, bprm);
if (retval < 0)
goto out_free;
bprm->exec = bprm->p;
retval = copy_strings(bprm->envc, envp, bprm);
if (retval < 0)
goto out_free;
retval = copy_strings(bprm->argc, argv, bprm);
if (retval < 0)
goto out_free;
/*
* When argv is empty, add an empty string ("") as argv[0] to
* ensure confused userspace programs that start processing
* from argv[1] won't end up walking envp. See also
* bprm_stack_limits().
*/
if (bprm->argc == 0) {
retval = copy_string_kernel("", bprm);
if (retval < 0)
goto out_free;
bprm->argc = 1;
}
// // 加载可执行文件
retval = bprm_execve(bprm, fd, filename, flags);
out_free:
free_bprm(bprm);
out_ret:
putname(filename);
return retval;
}bprm_execve 中也分为三部分
- 调用 do_open_execat() 以可执行的模式打开文件
在打开文件时 do_open_execat() 的 open_flag 中包含
__FMODE_EXEC, 如果文件并没有可执行权限, 那么此时将会通过返回错误终止。关于读写执行权限的判断会有 vfs 交由下层的文件系统处理, 详见 vfs
static struct file *do_open_execat(int fd, struct filename *name, int flags) { struct file *file; int err; struct open_flags open_exec_flags = { .open_flag = O_LARGEFILE | O_RDONLY | __FMODE_EXEC, .acc_mode = MAY_EXEC, .intent = LOOKUP_OPEN, .lookup_flags = LOOKUP_FOLLOW, }; if ((flags & ~(AT_SYMLINK_NOFOLLOW | AT_EMPTY_PATH)) != 0) return ERR_PTR(-EINVAL); if (flags & AT_SYMLINK_NOFOLLOW) open_exec_flags.lookup_flags &= ~LOOKUP_FOLLOW; if (flags & AT_EMPTY_PATH) open_exec_flags.lookup_flags |= LOOKUP_EMPTY; file = do_filp_open(fd, name, &open_exec_flags); if (IS_ERR(file)) goto out; }
- 调用 sched_exec() 找到最小负载的CPU,用来执行该二进制文件
- exec_binprm 执行
static int bprm_execve(struct linux_binprm *bprm,
int fd, struct filename *filename, int flags)
{
struct file *file;
int retval;
file = do_open_execat(fd, filename, flags);
retval = PTR_ERR(file);
if (IS_ERR(file))
goto out_unmark;
sched_exec();
bprm->file = file;
retval = exec_binprm(bprm);
if (retval < 0)
goto out;
return retval;
}exec_binprm 的核心函数 search_binary_handler 用于查找和设置可执行文件格式的处理器。这个函数会搜索已注册的可执行文件格式(binfmt)并尝试找到可以处理给定二进制文件的格式.这种机制允许内核支持多种不同的可执行文件格式,例如 ELF、script 等。
注意到代码片段中使用了循环和 depth 变量是用来限制内核在查找合适的可执行文件格式处理器时可以进行的重写(rewrite)或重试的次数。这里的注释说明了内核在放弃之前允许的最大重写级别是 4 级。这是因为某些特殊的可执行文件可能需要特定的格式处理器来加载.例如,一个可执行文件可能是一个脚本,它本身又调用了另一个程序。内核需要递归地查找合适的处理器来处理这些情况。
例如执行
.sh文件实际上就会转化为调用 bash 执行.sh
static int exec_binprm(struct linux_binprm *bprm)
{
/* This allows 4 levels of binfmt rewrites before failing hard. */
for (depth = 0;; depth++) {
struct file *exec;
if (depth > 5)
return -ELOOP;
ret = search_binary_handler(bprm);
if (ret < 0)
return ret;
if (!bprm->interpreter)
break;
exec = bprm->file;
bprm->file = bprm->interpreter;
bprm->interpreter = NULL;
}
return 0;
}search_binary_handler
search_binary_handler 是进程装载的核心函数,它负责找到合适的二进制处理程序(比如 ELF 加载器)并调用它来装载可执行文件。
前文我们提到了 Linux 下标准的可执行文件格式是 ELF, 但严格来说其实只要一个文件拥有可执行权限, 并且可以被内核中的某一种解释器正确加载, 那么他就可以运行。
除了标准 ELF 格式 linux 也支持其他不同的可执行程序格式, 例如以 #!/bin/bash 开头的脚本文件, 或者以 #!/bin/python3 开头的 python 文件。各个可执行程序的执行方式不尽相同, 因此linux内核每种被注册的可执行程序格式都用 linux_bin_fmt 来存储, 其中记录了可执行程序的加载和执行函数
// include/linux/binfmts.h
struct linux_binfmt {
struct list_head lh;
struct module *module;
int (*load_binary)(struct linux_binprm *);
int (*load_shlib)(struct file *);
#ifdef CONFIG_COREDUMP
int (*core_dump)(struct coredump_params *cprm);
unsigned long min_coredump; /* minimal dump size */
#endif
} __randomize_layout;其提供了3种方法来加载和执行可执行程序
- load_binary: 通过读存放在可执行文件中的信息为当前进程建立一个新的执行环境
- load_shlib: 用于动态的把一个共享库捆绑到一个已经在运行的进程, 这是由uselib()系统调用激活的
- core_dump: 在名为core的文件中, 存放当前进程的执行上下文。这个文件通常是在进程接收到一个缺省操作为"dump"的信号时被创建的, 其格式取决于被执行程序的可执行类型
所有支持的格式都需要通过 register_binfmt 函数注册到内核当中, 该函数的作用就是将一个结构体头插到 format 全局变量的链表中
/* Registration of default binfmt handlers */
static inline void register_binfmt(struct linux_binfmt *fmt)
{
__register_binfmt(fmt, 0);
}
void __register_binfmt(struct linux_binfmt * fmt, int insert)
{
write_lock(&binfmt_lock);
insert ? list_add(&fmt->lh, &formats) :
list_add_tail(&fmt->lh, &formats);
write_unlock(&binfmt_lock);
}当实现了一个新的可执行格式的模块正被装载时, 也执行这个函数, 当模块被卸载时, 执行 unregister_binfmt()函数。可以动态的加载卸载新可执行文件的模块
在代码库中全局搜索该函数, 可以看到内核支持的所有可执行文件格式
grep -rnw . -e 'register_binfmt' --include \*.c --include \*.h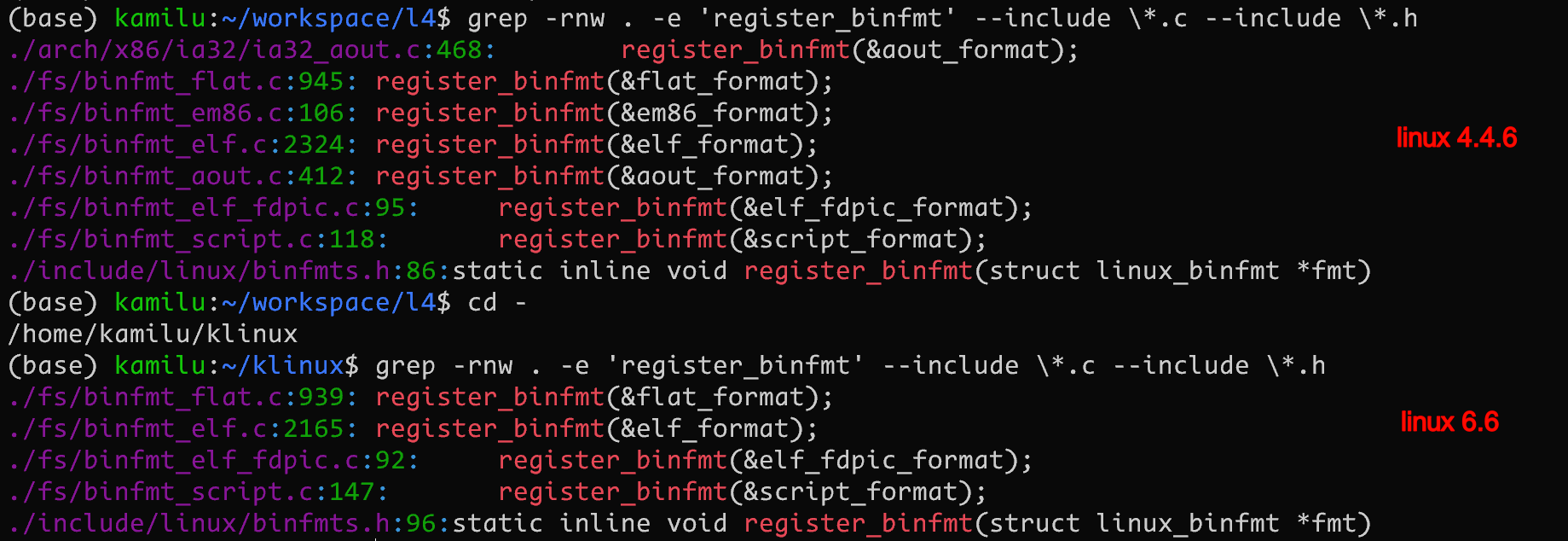
6.6 相比于 4.4.6 删除了对于 em86/a.out 格式的支持
对应的注册位置见 binfmt_elf.c binfmt_flat.c binfmt_script.c
当我们执行一个可执行程序的时候, 内核会 list_for_each_entry 遍历所有注册的linux_binfmt对象, 对其调用 load_binrary 方法来尝试加载, 直到加载成功为止。
static int search_binary_handler(struct linux_binprm *bprm)
{
bool need_retry = IS_ENABLED(CONFIG_MODULES);
struct linux_binfmt *fmt;
int retval;
retval = prepare_binprm(bprm); // 读取该文件前 256 字节保存在 buf 中
if (retval < 0)
return retval;
list_for_each_entry(fmt, &formats, lh) {
if (!try_module_get(fmt->module))
continue;
read_unlock(&binfmt_lock);
retval = fmt->load_binary(bprm);
read_lock(&binfmt_lock);
put_binfmt(fmt);
if (bprm->point_of_no_return || (retval != -ENOEXEC)) {
read_unlock(&binfmt_lock);
return retval;
}
}
}load_binary 为各个加载解释器的实现的方法, 例如对于最常见的 shell 脚本, 通常其开头都有 #!/bin/bash. 此时会读取其内容判断是否是以 "#!" 开头, 然后解析取出解释器的路径 /bin/bash 保存到 i_name 中, 打开该文件重新执行(前文提到的多次查找解释器)
#!/bin/python3处理 python 文件也是同理
static int load_script(struct linux_binprm *bprm)
{
const char *i_name, *i_sep, *i_arg, *i_end, *buf_end;
struct file *file;
int retval;
/* Not ours to exec if we don't start with "#!". */
if ((bprm->buf[0] != '#') || (bprm->buf[1] != '!'))
return -ENOEXEC;
// ...
// i_name 被解析为 /bin/bash
retval = bprm_change_interp(i_name, bprm);
if (retval < 0)
return retval;
/*
* OK, now restart the process with the interpreter's dentry.
*/
file = open_exec(i_name);
if (IS_ERR(file))
return PTR_ERR(file);
bprm->interpreter = file;
return 0;
}对于其他格式的文件我们不深入研究, 下文重点介绍一下 ELF 文件的加载和执行。对于 ELF 文件格式, list_for_each_entry(fmt, &formats, lh) 循环查找最终会匹配到 ELF 的函数调用 load_elf_binary, 从 execve 系统调用进入到 elf 文件加载执行的函数调用栈如下所示
do_execveat_common [exec.c]
bprm_execve [exec.c]
exec_binprm [exec.c]
search_binary_handler [exec.c]
load_elf_binary [binfmt_elf.c]load_elf_binary
load_elf_binary 是装载处理 ELF 文件的核心逻辑, 这个函数很长我们分几段来看。
- 检查目标程序ELF头部
- load_elf_phdrs 加载目标程序的程序头表
- 如果需要动态链接, 则寻找和处理解释器段
- 检查并读取解释器的程序表头
- 装入目标程序的段segment
- 填写程序的入口地址
- create_elf_tables填写目标文件的参数环境变量等必要信息
- START_THREAD 宏准备进入新的程序入口
检查ELF头部
在进入 load_elf_binary 之前, search_binary_handler 中会调用 prepare_binprm() 读取映像文件的前 256 个字节对 bprm->buf 进行填充, 读取头部数据目的是判断文件的格式,每种可执行文件的格式的开头几个字节都是很特殊的,特别是开头4个字节,常常被称做魔数(Magic Number)
通过对魔数的判断可以确定文件的格式和类型。比如
- ELF的可执行文件格式的头4个字节为0x7F/'e'/"1'/"f';
- Java 的可执行文件格式的头4个字节为'c'/'a'/"f"/'e';
- Shell 脚本或perl/python 等这种解释型语言的脚本,那么它的第一行往往是"#!/bin/sh"或"#!/usr/bin/perl"或"#!/usr/bin/python",这时候前两个字节"#和"!就构成了魔数
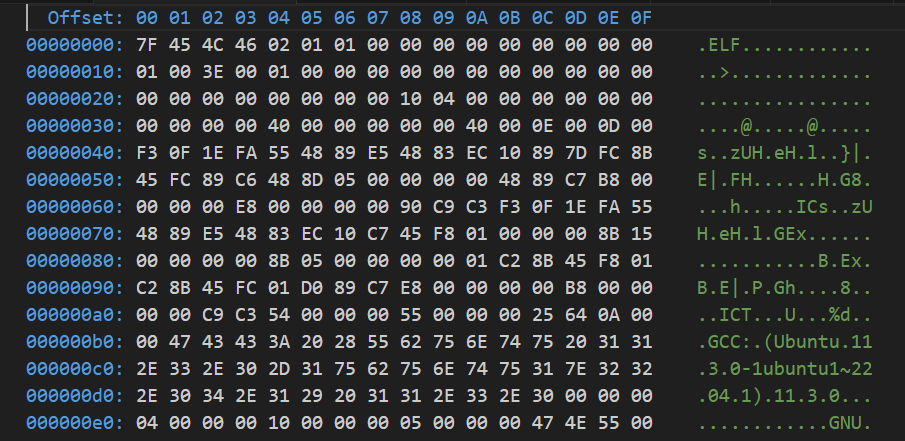
魔数用来确定文件的类型, 操作系统在加载可执行文件的时候会确认魔数是否正确, 如果不正确会拒绝加载
此处的逻辑为判断文件开头是否为 ELF 魔数, 并检查 ELF 类型以及处理器架构。
static int prepare_binprm(struct linux_binprm *bprm)
{
loff_t pos = 0;
memset(bprm->buf, 0, BINPRM_BUF_SIZE);
return kernel_read(bprm->file, bprm->buf, BINPRM_BUF_SIZE, &pos);
}
static int load_elf_binary(struct linux_binprm *bprm)
{
struct elfhdr *elf_ex = (struct elfhdr *)bprm->buf;
retval = -ENOEXEC;
// 判断开头四个字节为 "\177ELF"
if (memcmp(elf_ex->e_ident, ELFMAG, SELFMAG) != 0)
goto out;
// 判断是可执行文件或者动态链接库
if (elf_ex->e_type != ET_EXEC && elf_ex->e_type != ET_DYN)
goto out;
// 判断可执行文件和内核的处理器架构相同
if (!elf_check_arch(elf_ex))
goto out;
}加载程序头表
从编译/链接和运行的角度看,应用程序和库程序的链接有两种方式。
- 一种是固定的、静态的链接,就是把需要用到的库函数的目标代码(二进制)代码从程序库中抽取出来,链接进应用软件的目标映像中;
- 另一种是动态链接,是指库函数的代码并不进入应用软件的目标映像,应用软件在编译/链接阶段并不完成跟库函数的链接,而是把函数库的映像也交给用户,到启动应用软件目标映像运行时才把程序库的映像也装入用户空间(并加以定位),再完成应用软件与库函数的链接。
Linux内核既支持静态链接的ELF映像,也支持动态链接的ELF映像,而且装入/启动ELF映像必需由内核完成,而动态链接的实现则既可以在内核中完成,也可在用户空间完成。
因此,GNU把对于动态链接ELF映像的支持作了分工:
把ELF映像的装入/启动入在Linux内核中;而把动态链接的实现放在用户空间(glibc),并为此提供一个称为"解释器"(ld-linux.so.2)的工具软件,而解释器的装入/启动也由内核负责,这在后面我们分析ELF文件的加载时就可以看到
前文我们介绍了关于 ELF文件格式 和 动态链接 的相关知识, 虽然 ELF 分为很多段且每个段有不同的作用, 但是在最终执行时操作系统内核只关心需要装载的段, program header(程序头表)中保存了这部分的信息
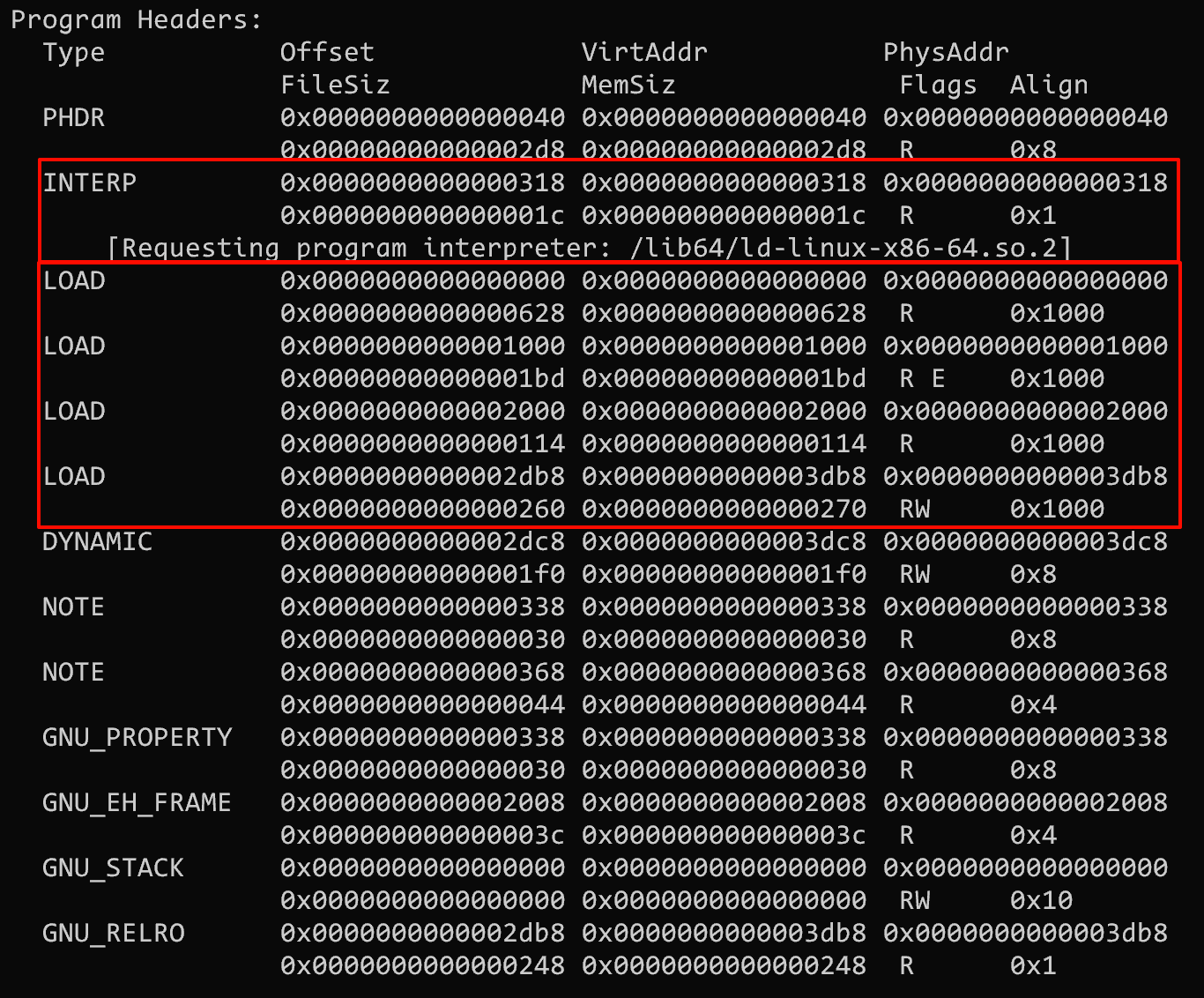
上图中 LOAD 的部分就是需要装载的段, 可以看到分为三种类型
- R(只读): 对应只读数据段
- RE(可读可执行): 对应代码段
- RW(可读可写): 对应数据段
采用动态链接的文件还会有动态链接的解释器的段, 下文介绍
由于动态链接的种种优势, 绝大部分 ELF 包括编译器的默认编译选项都会生成动态链接的可执行文件
寻找解释器
如果需要动态链接, 则寻找和处理解释器段。使用 load_elf_phdrs 加载程序头之后查找解释器段。"解释器"段的类型为 PT_INTERP, 如果找到就根据其位置的 p_offset 和大小 p_filesz 把整个"解释器"段的内容读入缓冲区。该段实际上只是一个字符串, 即解释器的文件名, 64位机器上对应的叫做 /lib64/ld-linux-x86-64.so.2
这是一个指向
/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2的软链接
有了解释器的文件名以后,就通过 open_exec() 打开这个文件, 并读取解释器头部 256 字节数据
static int load_elf_binary(struct linux_binprm *bprm)
{
// ...
elf_phdata = load_elf_phdrs(elf_ex, bprm->file);
elf_ppnt = elf_phdata;
for (i = 0; i < elf_ex->e_phnum; i++, elf_ppnt++) {
char *elf_interpreter;
if (elf_ppnt->p_type == PT_GNU_PROPERTY) {
elf_property_phdata = elf_ppnt;
continue;
}
if (elf_ppnt->p_type != PT_INTERP)
continue;
elf_interpreter = kmalloc(elf_ppnt->p_filesz, GFP_KERNEL);
retval = elf_read(bprm->file, elf_interpreter, elf_ppnt->p_filesz,
elf_ppnt->p_offset);
interpreter = open_exec(elf_interpreter);
interp_elf_ex = kmalloc(sizeof(*interp_elf_ex), GFP_KERNEL);
if (!interp_elf_ex) {
retval = -ENOMEM;
goto out_free_file;
}
/* Get the exec headers */
retval = elf_read(interpreter, interp_elf_ex,
sizeof(*interp_elf_ex), 0);
}
}检查并读取解释器的程序表头
如果需要加载解释器, 前面经过一趟for循环已经找到了需要的解释器信息 elf_interpreter, 它也是当作一个ELF文件, 因此跟目标可执行程序一样, 我们需要load_elf_phdrs加载解释器的程序头表program header table
static int load_elf_binary(struct linux_binprm *bprm)
{
// ...
/* Some simple consistency checks for the interpreter */
if (interpreter) {
retval = -ELIBBAD;
/* Not an ELF interpreter */
if (memcmp(interp_elf_ex->e_ident, ELFMAG, SELFMAG) != 0)
goto out_free_dentry;
/* Verify the interpreter has a valid arch */
if (!elf_check_arch(interp_elf_ex) ||
elf_check_fdpic(interp_elf_ex))
goto out_free_dentry;
/* Load the interpreter program headers */
interp_elf_phdata = load_elf_phdrs(interp_elf_ex, interpreter);
}
}至此我们已经把目标执行程序和其所需要的解释器都加载初始化, 并且完成检查工作, 也加载了程序头表program header table, 下面开始加载程序的段信息
装入目标程序的段
这段代码从目标映像的程序头中搜索类型为 PT_LOAD 的段。在二进制映像中,只有类型为 PT_LOAD 的段才是需要装入的。当然在装入之前,需要确定装入的地址,只要考虑的就是页面对齐,还有该段的p_vaddr域的值(上面省略这部分内容).确定了装入地址后,就通过elf_map()建立用户空间虚拟地址空间与目标映像文件中某个连续区间之间的映射, 其返回值为实际映射的起始地址
static int load_elf_binary(struct linux_binprm *bprm)
{
// ...
for(i = 0, elf_ppnt = elf_phdata; i < elf_ex->e_phnum; i++, elf_ppnt++) {
// ...
if (elf_ppnt->p_type != PT_LOAD)
continue;
// ...
error = elf_map(bprm->file, load_bias + vaddr, elf_ppnt,
elf_prot, elf_flags, total_size);
}
}设置入口点
完成了目标程序和解释器的加载, 同时目标程序的各个段也已经加载到内存了, 我们的目标程序已经准备好了要执行了, 但是还缺少一样东西, 就是我们程序的入口地址, 没有入口地址, 操作系统就不知道从哪里开始执行内存中加载好的可执行映像
这段程序的逻辑非常简单:
- 如果需要装入解释器,就通过 load_elf_interp 装入其映像, 并把将来进入用户空间的入口地址设置成解释器映像的入口地址
- 若不装入解释器,那么这个入口地址就是目标映像本身的入口地址。
static int load_elf_binary(struct linux_binprm *bprm)
{
// ...
if (interpreter) {
elf_entry = load_elf_interp(interp_elf_ex,
interpreter,
load_bias, interp_elf_phdata,
&arch_state);
// ...
} else {
elf_entry = e_entry;
// ...
}
}参数与环境变量
在完成装入,启动用户空间的映像运行之前,还需要为目标映像和解释器准备好一些有关的信息,这些信息包括常规的argc、envc等等,还有一些"辅助向量(Auxiliary Vector)".这些信息需要复制到用户空间,使它们在CPU进入解释器或目标映像的程序入口时出现在用户空间堆栈上。这里的 create_elf_tables() 就起着这个作用
详见 装载 进程栈初始化
static int
create_elf_tables(struct linux_binprm *bprm, const struct elfhdr *exec,
unsigned long interp_load_addr,
unsigned long e_entry, unsigned long phdr_addr)
{
struct mm_struct *mm = current->mm;
unsigned long p = bprm->p;
int argc = bprm->argc;
int envc = bprm->envc;
// ...
if (put_user(argc, sp++))
return -EFAULT;
/* Populate list of argv pointers back to argv strings. */
p = mm->arg_end = mm->arg_start;
while (argc-- > 0) {
size_t len;
if (put_user((elf_addr_t)p, sp++))
return -EFAULT;
len = strnlen_user((void __user *)p, MAX_ARG_STRLEN);
if (!len || len > MAX_ARG_STRLEN)
return -EINVAL;
p += len;
}
if (put_user(0, sp++))
return -EFAULT;
mm->arg_end = p;
/* Populate list of envp pointers back to envp strings. */
mm->env_end = mm->env_start = p;
while (envc-- > 0) {
size_t len;
if (put_user((elf_addr_t)p, sp++))
return -EFAULT;
len = strnlen_user((void __user *)p, MAX_ARG_STRLEN);
if (!len || len > MAX_ARG_STRLEN)
return -EINVAL;
p += len;
}
if (put_user(0, sp++))
return -EFAULT;
mm->env_end = p;
/* Put the elf_info on the stack in the right place. */
if (copy_to_user(sp, mm->saved_auxv, ei_index * sizeof(elf_addr_t)))
return -EFAULT;
return 0;
}进入新的程序入口
STEART_THREAD() 宏操作会将eip和esp改成新的地址,就使得CPU在返回用户空间时就进入新的程序入口。这里新的地址入口就是前文计算的 elf_entry, 如果存在解释器映像,那么这就是解释器映像的程序入口,否则就是目标映像的程序入口
static int load_elf_binary(struct linux_binprm *bprm)
{
// ...
START_THREAD(elf_ex, regs, elf_entry, bprm->p);
}该宏展开之后的功能就是重新设置寄存器的值, 将 IP 指向新的地址
static void
start_thread_common(struct pt_regs *regs, unsigned long new_ip,
unsigned long new_sp,
unsigned int _cs, unsigned int _ss, unsigned int _ds)
{
regs->ip = new_ip;
regs->sp = new_sp;
regs->cs = _cs;
regs->ss = _ss;
regs->flags = X86_EFLAGS_IF;
}符号的动态解析
前面我们提到了内核空间中ELF文件的加载工作
内核的工作
- 内核首先读取ELF文件头部,再读如各种数据结构,从这些数据结构中可知各段或节的地址及标识,然后调用mmap()把找到的可加载段的内容加载到内存中。同时读取段标记,以标识该段在内存中是否可读、可写、可执行。其中,文本段是程序代码,只读且可执行,而数据段是可读且可写。
- 从PT_INTERP的段中找到所对应的动态链接器名称,并加载动态链接器。通常是/lib/ld-linux.so.2.
- 内核把新进程的堆栈中设置一些标记对,以指示动态链接器的相关操作。
- 内核把控制权传递给动态链接器。
动态链接器的工作并不是在内核空间完成的, 而是在用户空间完成的, 比如C语言程序则交给C运行时库来完成, 这个并不是我们今天内核学习的重点, 而是由glic完成的,但是其一般过程如下
动态链接器的工作
- 动态链接器检查程序对共享库的依赖性,并在需要时对其进行加载。
- 动态链接器对程序的外部引用进行重定位,并告诉程序其引用的外部变量/函数的地址,此地址位于共享库被加载在内存的区间内。动态链接还有一个延迟定位的特性,即只有在"真正"需要引用符号时才重定位,这对提高程序运行效率有极大帮助。
- 动态链接器执行在ELF文件中标记为。init的节的代码,进行程序运行的初始化。
- 程序开始执行
动态链接相关详见 动态链接