ELF文件格式
Linux 中的可执行文件(.out), 目标文件(.o), 静态库(.a) 动态库(.so) 等都按照 ELF 文件格式进行存储, 我们可以借助 readelf 和 objudmp 来查看 ELF 文件的相关信息, 也可以利用 elf.h 头文件来对其进行解析和处理
20世纪90年代, 一些厂商联合成立了一个委员会, 起草并发布了一个 ELF 文件格式标准供公开使用, 并希望所有人都可以遵循这项标准并从中获益。1993 年委员会发布了 ELF 文件标准, 当时参与该委员会的有来自于编译器的厂商, 比如 Watcom(Watcom C/C++ 编译器) 和 Borland(Borland Turbo Pascal 编译器); 来自 CPU 的厂商比如 IBM 和 Intel; 来自操作系统的厂商比如IBM 和 Microsoft. 1995 年委员会发布了 ELF1.2标准, 自此委员会完成了自己的使命, 不久就解散了, 所以 ELF 文件格式标准的最新版本也是最后一个版本就是 1.2
本文详细介绍一下 ELF 文件格式, 我们使用如下的一个 C 程序作为示例, 其后的分析均使用该文件的编译产物(gcc-11.3)
int printf(const char *format, ...);
int global_init_var = 84;
int global_zero_var = 0;
int global_uninit_var;
void func1(int i) {
printf("%d\n",i);
}
int main(void) {
static int static_var = 85;
static int static_zero_var = 0;
static int static_var2;
int a = 1;
int b;
func1(static_var + static_var2 + a + b);
}使用 gcc 编译器得到 .o 文件
gcc -c SimpleSection.c -o SimpleSection.oELF 段格式
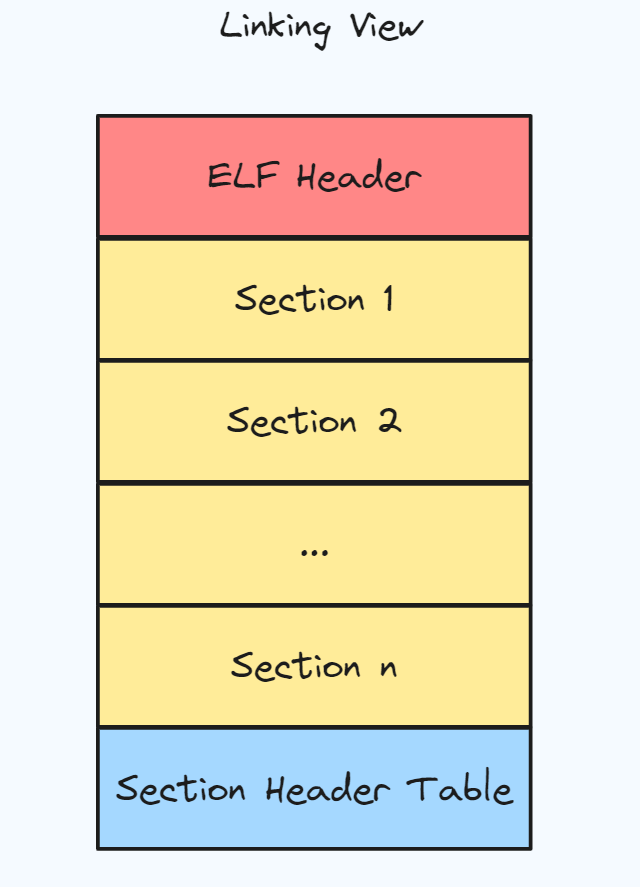
ELF 文件的作用有两个,一是用于程序链接(为了生成程序);二是用于程序执行(为了运行程序). ELF 目标文件格式可以分为两部分
- 段(Section), 每个段有各自的作用
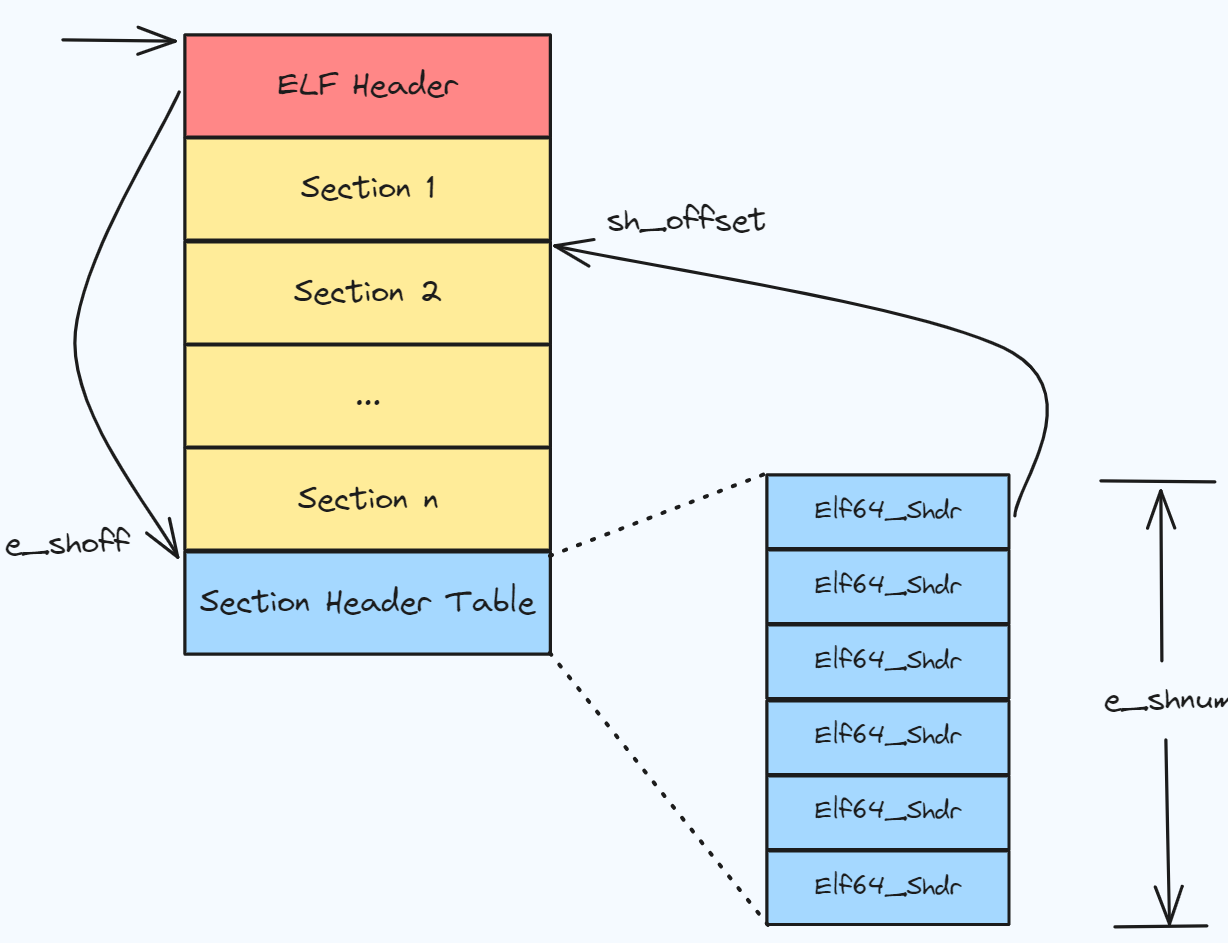
- 段表(Section Header Table), 该表描述了 ELF 包含的所有段的信息, 比如每个段的段名,段长度,文件中的偏移量,读写权限和段的其他属性, 如下图所示
链接的其中一个过程就是将多个目标文件中各个段合并到一起, 相同性质的段组合为一个大段, 如下所示
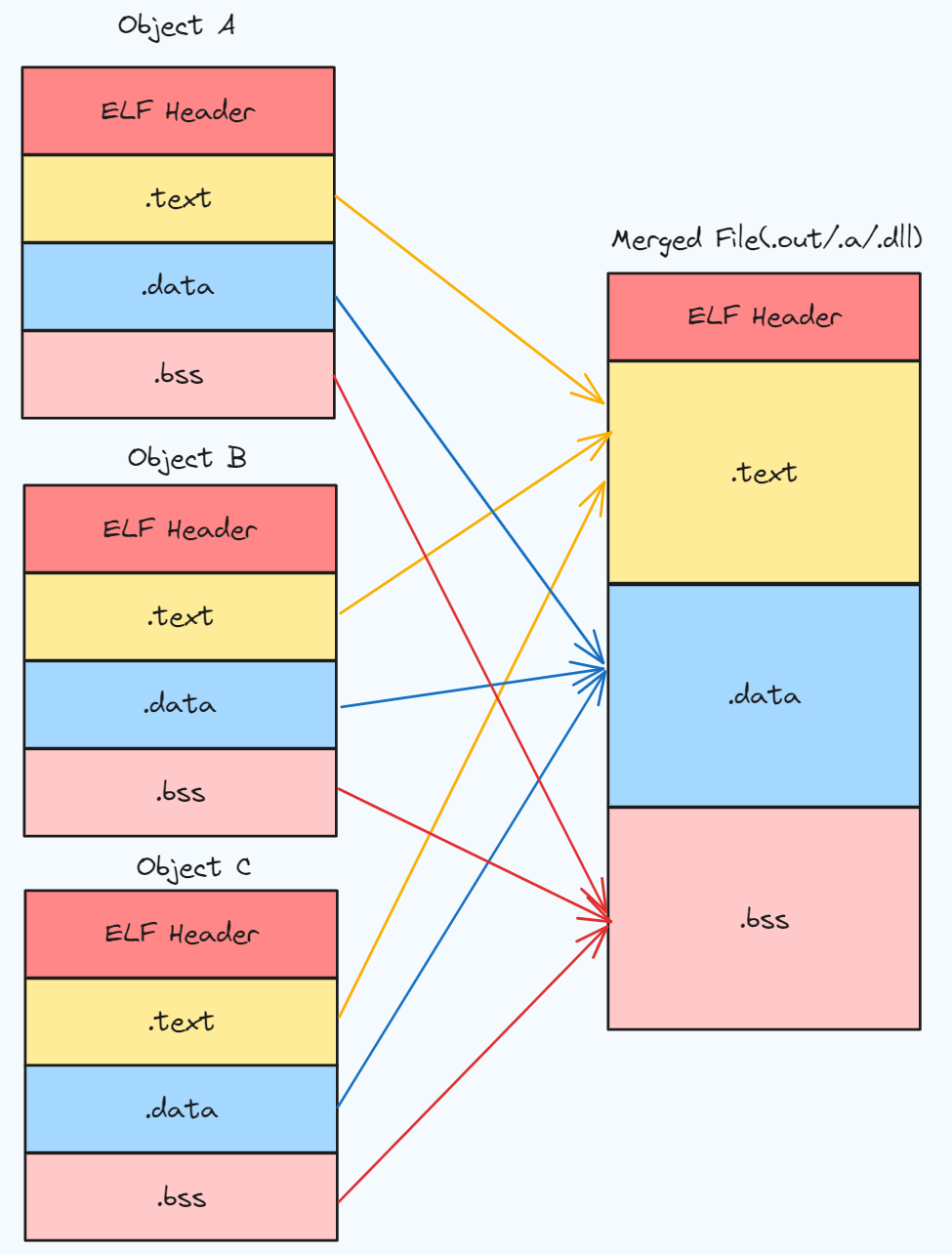
正常来说 section 应该翻译为节, segment 翻译为段, 由于下文我们讨论单个目标文件的 ELF 格式, section 统称为段
段分布
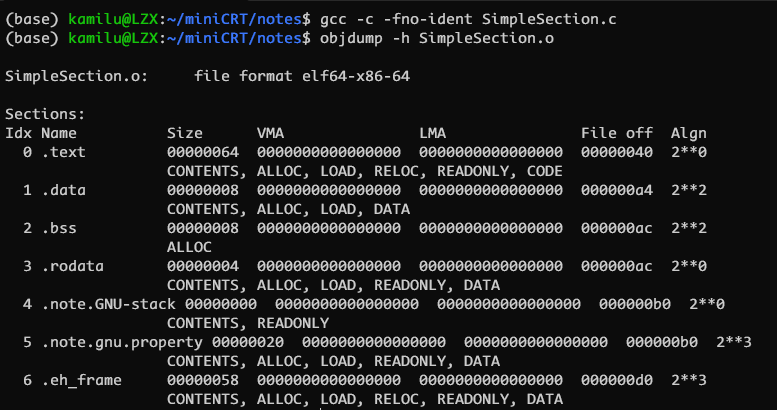
ELF 文件中有很多个段组成, 可以使用 readelf -S 可以查看一个 ELF 文件的所有段的信息, 比如查看前文提到的 SimpleSection.o, 它会依次列出所有段的信息, 如下所示
笔者在 binutils 实现了 readelf, 感兴趣的读者可自行阅读源码
(base) kamilu@LZX:~/miniCRT/notes$ readelf -S SimpleSection.o
There are 14 section headers, starting at offset 0x410:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040
0000000000000064 0000000000000000 AX 0 0 1
[ 2] .rela.text RELA 0000000000000000 000002f0
0000000000000078 0000000000000018 I 11 1 8
[ 3] .data PROGBITS 0000000000000000 000000a4
0000000000000008 0000000000000000 WA 0 0 4
[ 4] .bss NOBITS 0000000000000000 000000ac
0000000000000008 0000000000000000 WA 0 0 4
[ 5] .rodata PROGBITS 0000000000000000 000000ac
0000000000000004 0000000000000000 A 0 0 1
[ 6] .comment PROGBITS 0000000000000000 000000b0
000000000000002e 0000000000000001 MS 0 0 1
[ 7] .note.GNU-stack PROGBITS 0000000000000000 000000de
0000000000000000 0000000000000000 0 0 1
[ 8] .note.gnu.pr[...] NOTE 0000000000000000 000000e0
0000000000000020 0000000000000000 A 0 0 8
[ 9] .eh_frame PROGBITS 0000000000000000 00000100
0000000000000058 0000000000000000 A 0 0 8
[10] .rela.eh_frame RELA 0000000000000000 00000368
0000000000000030 0000000000000018 I 11 9 8
[11] .symtab SYMTAB 0000000000000000 00000158
0000000000000138 0000000000000018 12 8 8
[12] .strtab STRTAB 0000000000000000 00000290
0000000000000060 0000000000000000 0 0 1
[13] .shstrtab STRTAB 0000000000000000 00000398
0000000000000074 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
D (mbind), l (large), p (processor specific)根据输出信息可以画出整个 ELF 文件的排布, Offset 对应每一个段的起始位置, Size 对应段的大小
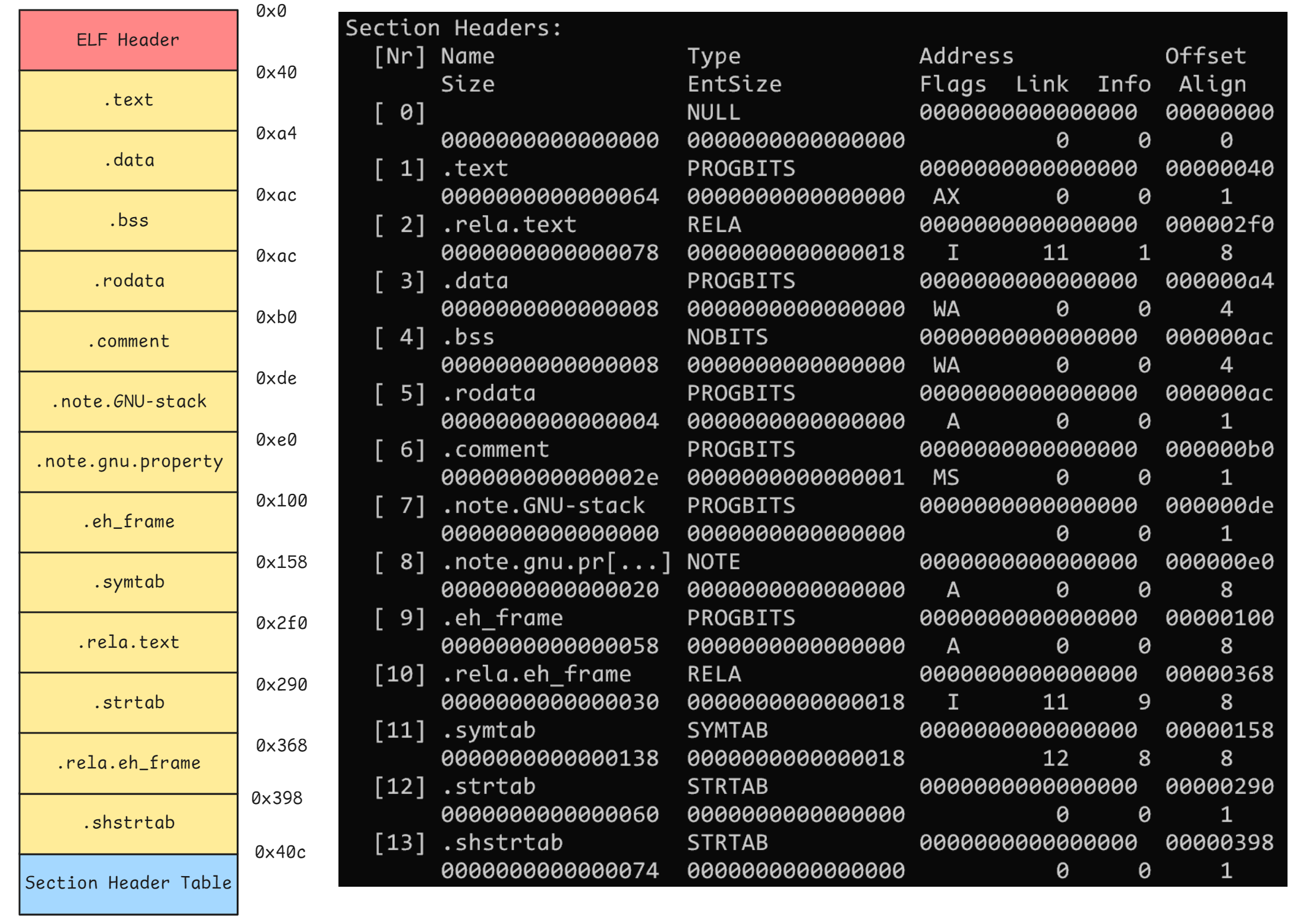
其中第一个无名段是一个特殊的段, 它包含了描述整个文件的基本属性, 被称为ELF 文件头(ELF Header); 其余 1-13 段则各自有其作用。
我们可以计算一下所有段的大小, 最后一个段 shstrtab 的大小为 0x74, 所以段结尾的地址是 0x398 + 0x74 = 0x40c
由此可知 [0x000-0x40c] 之间分别对应各个段, [0x40c-0x410] 地址对齐。0x410 之后是段表。
段表并不算一个段, 它是独立于段之外的, 用于记录所有段信息的一个数组。ELF Header 是一个需要单独处理的特殊块, 始终位于文件起始位置。
段表
每一个段有各自的含义和信息, ELF 并没有将这些信息分布保存在每一个段中, 而是使用 (Section Header Table)段表 来统一保存所有段的信息。
段表实际上是一个数组, 数组中每一个元素都是 Elf64_Shdr 结构体, 用于储存每一个段的信息。其定义如下所示, 这些属性对应段的段名,段长度,文件中的偏移量,读写权限和段的其他属性
typedef struct {
uint32_t sh_name; // 段名
uint32_t sh_type; // 段类型
uint64_t sh_flags; // 段标志位
Elf64_Addr sh_addr; // 段虚拟地址
Elf64_Off sh_offset; // 段偏移
uint64_t sh_size; // 段长度
uint32_t sh_link; // 段链接信息
uint32_t sh_info; // 段链接信息
uint64_t sh_addralign; // 段地址对齐
uint64_t sh_entsize; // 段条目的长度
} Elf64_Shdr;该结构体长度为 64 字节, 因此所有段一共 64 x 14 = 896 (0x380) 字节。前文我们计算了所有段的长度和为 0x410, 所以可以计算得到整个 ELF 文件的总字节数为 0x410 + 0x380 = 0x790 = 1936 字节。可以使用 du 查看该文件大小, 这也印证了我们的计算结果
(base) kamilu@LZX:~/miniCRT/notes$ du -b SimpleSection.o
1936 SimpleSection.oELF Header
注意到段表位于所有段的最后面, 那么如何通过偏移量找到段表的位置呢?
前面我们提到了第 0 个无名段 ELF Header 是整个 ELF 文件的文件头, 段表的起始地址和段的数量都记录在 ELF Header 当中
我们可以使用 readelf -h 参数查看 ELF 文件头信息。其中高亮的两行, Start of section headers(段表的起始地址) 1040 对应我们之前计算的 0x410. 段数量为 14.
(base) kamilu@LZX:~/miniCRT/notes$ readelf -h SimpleSection.o
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 1040 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 14
Section header string table index: 13ELF Header 的结构体如下所示, 相关结构体元素的含义以注释的形式说明。, 其中的 e_shoff 就记录了段表在整个 ELF 文件中的偏移地址, e_shnum 记录了段的个数
typedef struct {
unsigned char e_ident[EI_NIDENT]; // 一些信息
uint16_t e_type; // 文件类型
uint16_t e_machine; // CPU类型
uint32_t e_version; // ELF版本号
ElfN_Addr e_entry; // 入口地址
ElfN_Off e_phoff; // 程序头入口
ElfN_Off e_shoff; // 段表在文件中的偏移
uint32_t e_flags; // 标志位
uint16_t e_ehsize; // ELF文件头大小
uint16_t e_phentsize; // 程序头大小
uint16_t e_phnum; // 程序头个数
uint16_t e_shentsize; // 段表描述符大小, 等同于 sizeof(ElfN_Ehdr)
uint16_t e_shnum; // 段表描述符数量
uint16_t e_shstrndx; // 段表字符串表的在段表中的索引值
} ElfN_Ehdr;也就是说只需要读取文件开头的 ELF Header 就可以获取到该 ELF 文件的基本信息, 以及段表的位置; 再根据读取段表, 就可以得到每一个段的信息。
段
区分不同段的作用主要是为了将指令和数据的存放区分开, 这样的好处主要有如下三点:
- 易于设置读写权限: 指令区域只读, 代码区域可读写,防止程序指令被有意/无意改写
- 现代CPU的缓存属性: 有益于程序的局部性
- 多副本可共享
使用 size 查看一个 ELF 文件的代码段/数据段/BSS段的长度
这里的大小不是。o文件的大小, 只是段的大小, 可以使用
du -b SimpleSection.o查看总大小(1936b)
$ size SimpleSection.o
text data bss dec hex filename
224 8 8 240 f0 SimpleSection.o其中 text 的大小并不是指 .text 段, 而是 .text(0x64) + .rodata(0x4) + .note.GNU-stack(0) + .note.gnu.property(0x20) + .eh_frame(0x58) = 0xe0 = 224
因此找到每一个段的流程如下:
- 读取 ELF Header, 找到段表在文件中的偏移
e_shoff和 段表描述符数量e_shnum
- 根据段表偏移量 e_shoff 找到段表起始位置
- 段表是一个大数组, 一共 e_shnum 个项, 每一个项都是 Elf64_Shdr, 根据其中的 sh_offset 找到对应的段
上文我们看到了 ELF 中的有 14 个段, 其中 .comment .note.GNU-stack .note.gnu.property .eh_frame, 它们并不是当前的重点, 我们暂时忽略。
.comment: 注释信息段.comment 段是一种特殊的段,用于保存目标文件的注释信息。具体来说,它包含了编译器和汇编器使用的注释信息,例如编译器版本/编译选项/时间戳和作者等。
.comment 段的主要作用是为了方便开发者在需要时查看目标文件的注释信息,以便了解目标文件的编译环境和作者等相关信息。该段的大小通常很小,对程序的执行没有影响,因为它只是用于存储元数据。
在实际开发中,.comment 段的信息可以用于调试/版本控制和审计等方面。例如,如果您在调试时遇到了问题,您可以查看目标文件的注释信息,以确定该文件是由哪个编译器和版本生成的。同样,如果您需要对软件进行审计,您可以查看 .comment 段的信息,以确保该软件是由可信的开发者编写的,并且没有被修改或篡改过。在某些情况下如果希望禁用 .comment 段,以减小目标文件的大小或隐藏一些编译器和版本信息。您可以使用编译器选项
-fno-ident可以看到最终目标文件当中没有 .comment 段了
可以使用如下指令查看 .comment 段的内容
$ objdump -s --section=.comment SimpleSection.o SimpleSection.o: file format elf64-x86-64 Contents of section .comment: 0000 00474343 3a202855 62756e74 75203131 .GCC: (Ubuntu 11 0010 2e332e30 2d317562 756e7475 317e3232 .3.0-1ubuntu1~22 0020 2e30342e 31292031 312e332e 3000 .04.1) 11.3.0.
.note.GNU-stack:用于指定堆栈的执行权限。如果这个段存在,表示堆栈是不可执行的;如果不存在,则堆栈是可执行的。这对于一些安全性和执行优化方面的考虑很重要。例如,栈的可执行性可能被关闭以防止一些攻击。
.note.gnu.property:包含了一些特定于GNU的属性,用于在运行时提供额外的信息。这些属性通常与特定的优化或调试选项相关。这个段的内容是一些键值对,描述了与程序执行相关的一些属性,例如是否启用了某些特定的优化。
.eh_frame:包含了异常处理框架信息。在程序执行期间,如果发生异常(如C++中的异常),这些信息用于确定如何正确地展开调用栈以查找适当的异常处理程序。这对于调试和程序执行的可靠性都很重要。
14 个段除去 ELF Header 以及上面暂不关心的 4 个段还有 9 个段, 他们分别是 .text, .data, .bss, .rodata, .rela.text, .rela.eh_frame, .symtab, .strtab, .shstrtab, 下面我们依次介绍一下
代码段(.text)
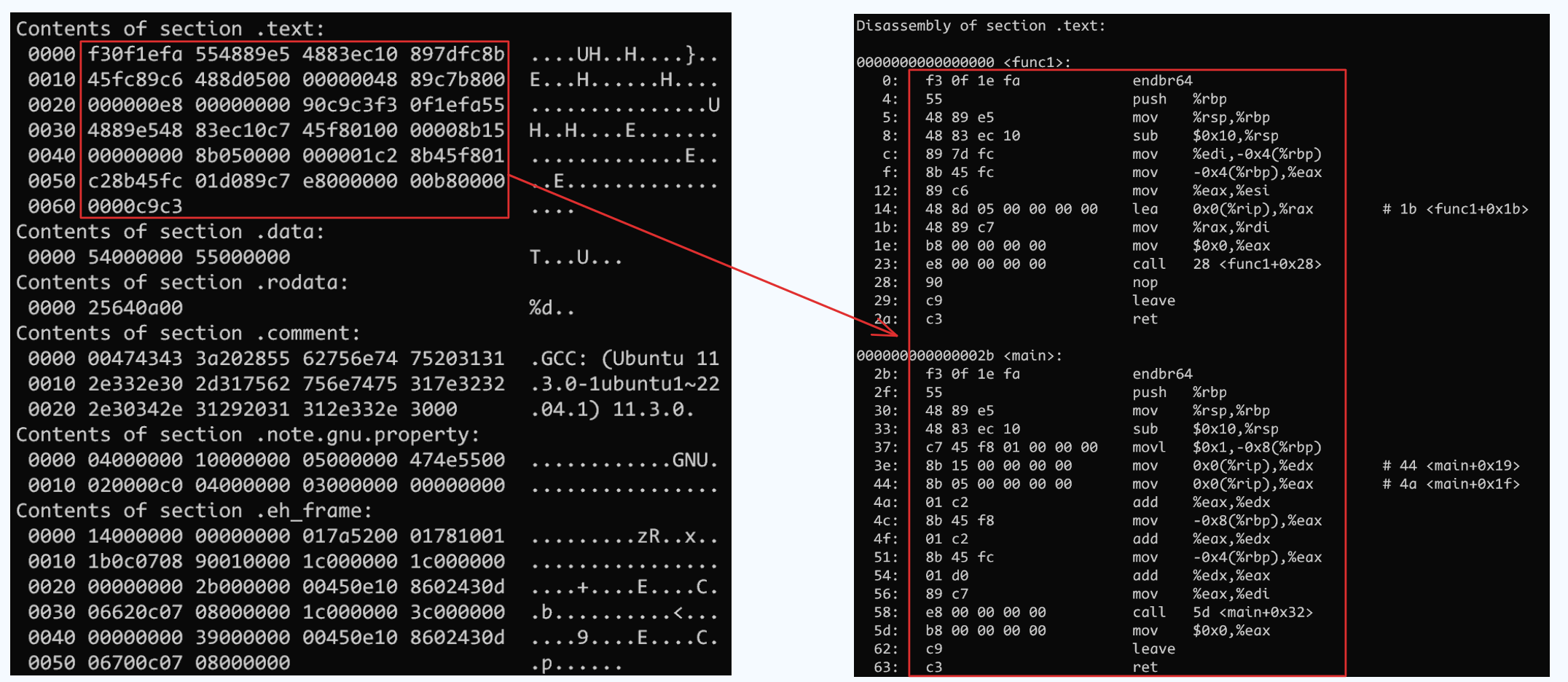
程序源码编译后的机器指令保存在代码段中, 这也是唯一一个可以具有可执行权限的段, 程序运行起来后的 CPU 会从代码段的起始位置开始执行
# 使用 objdump 查看反汇编
objdump -s -d SimpleSection.o可以看到 .text 段的二进制内容对应右侧的反汇编代码
数据段(.data .bss .rodata)
我们将 .data .bss .rodata 统称为数据段, 但他们三者略有差别。
int printf(const char *format, ...);
int global_init_var = 84;
int global_zero_var = 0;
int global_uninit_var;
void func1(int i) {
printf("%d\n",i);
}
int main(void) {
static int static_var = 85;
static int static_zero_var = 0;
static int static_var2;
int a = 1;
int b;
func1(static_var + static_var2 + a + b);
}.data: 已初始化的数据段- 初始化不为 0 的全局变量(global_init_var)
- 初始化不为 0 的局部静态变量(static_var)
.bss: 未初始化的数据段- 没有初始化的全局变量(global_uninit_var)
- 没有初始化的局部静态变量(static_var2)
- 初始化为 0 的全局变量(global_zero_var)
- 初始化为 0 的局部静态变量(static_zero_var)
没有初始化的默认值为 0, 和初始化为 0 效果相同
单独分出来 .bss 段是因为 .data 段中需要为一个已经初始化的变量分配空间用于存放初始化的值, 如果初始值是 0 那么其实就没有必要分配。这些变量在程序运行时确实需要占据内存空间, 但是没有必要在在可执行程序中为它们分配空间。.bss 段只是为初始值0的变量预留一个位置
.rodata: 只读数据段, 例如程序中的字符串常量 "%d\n", 其 ASCII 值分别为0x25 0x64 0x0a 0x00
.data 段中保存的是 int global_init_var = 84(0x54), static int static_var = 85(0x55), 四字节小端存储
符号表和重定位表
符号表和重定位表在可执行文件中并不是必须的, 但是在目标文件中这两个段的信息非常重要, 它涉及到之后链接器 ld 对于地址进行重定位.
- 符号表为
Elf64_Sym数组, sh_type 为SHT_SYMTAB或SHT_DYNSYM
- 重定位表为
Elf64_Rela数组, sh_type 为SHT_RELA
如果要找到所有的符号表和重定位表, 那么只需要遍历段表的所有项, 判断 sh_type 类型即可
可以在生成可执行文件时使用
-s选项去掉相关信息。
对于与链接相关的重定位表(.rela)和符号表(.symtab), 段表项(Elf64_Shdr)中的 sh_link 和 sh_info 字段有意义, 其余段的段表项这两个字段无意义。
对于重定位表 RELA, sh_link 代表该段所对应的符号表(.symbol)的下标, sh_info 表示它作用的重定位的段。如下所示。
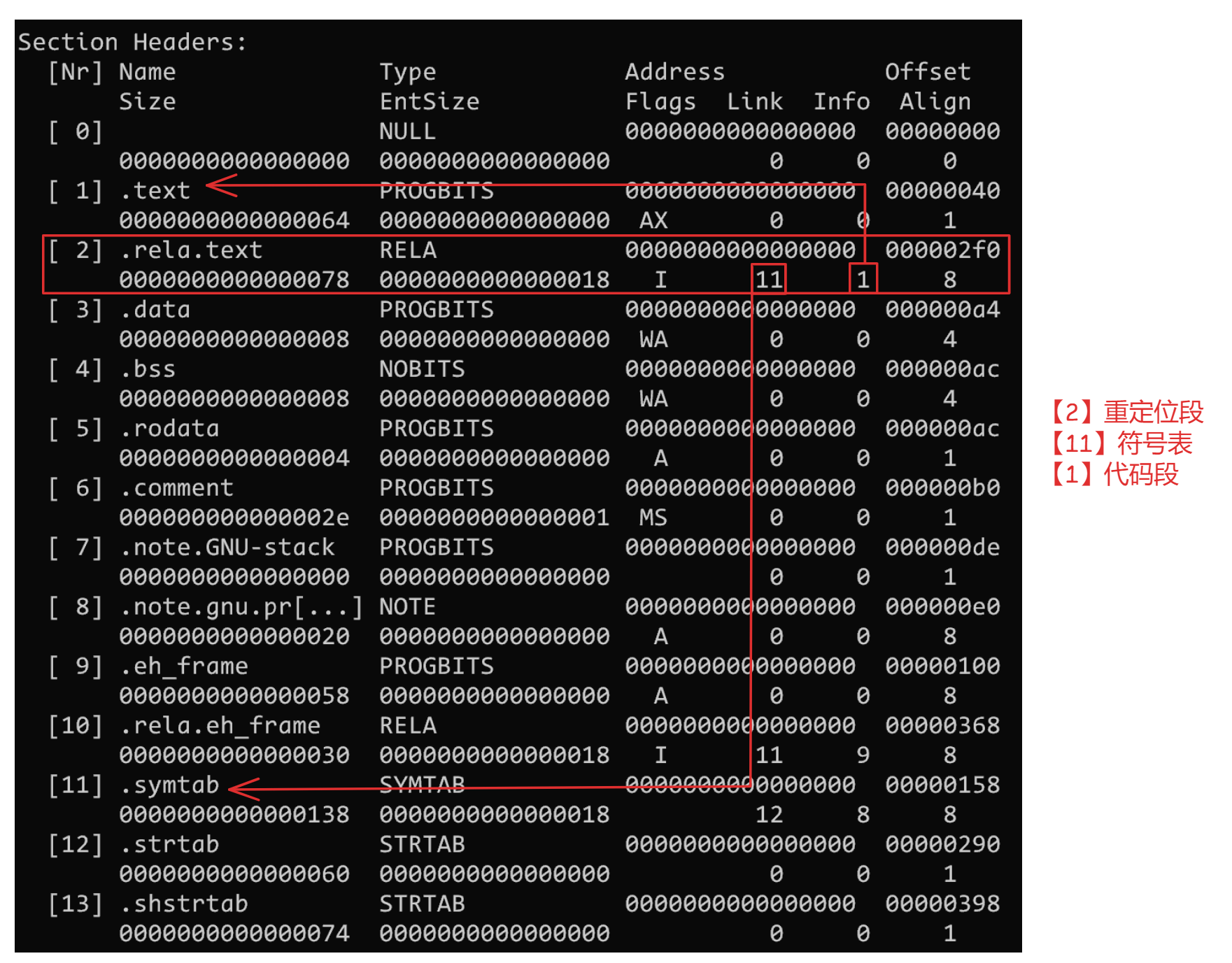
- [2] 的类型为 RELA 说明是一个重定位段, 表项为 Elf64_Rela 结构体, 其中记录需要重定位的符号的索引, 地址, 偏移量
typedef struct{ Elf64_Addr r_offset; /* 地址 */ Elf64_Xword r_info; /* 重定位类型和符号索引 */ Elf64_Sxword r_addend; /* 偏移量 */ } Elf64_Rela;[2] 段的段表项(Elf64_Shdr)中的
sh_link和sh_info为 [11] 和 [1], 分别对重定位符号所在的符号表和需要重定位的段
- [11] 为符号表。表项为 Elf64_Sym 结构体,
sh_link指向对应的字符串表(通常是 .strtab), st_info 的低4位用于符号类型, 高4位用于符号绑定信息, 成员含义如下所示typedef struct { Elf64_Word st_name; /* 符号名称(字符串表索引) */ unsigned char st_info; /* 符号类型和绑定 */ unsigned char st_other; /* 符号可见性 */ Elf64_Section st_shndx; /* 节索引 */ Elf64_Addr st_value; /* 符号值 */ Elf64_Xword st_size; /* 符号大小 */ } Elf64_Sym;
- [1] 为代码段, 是重定位过程中需要修改的段
重定位的相关内容详见 静态链接
字符串表(.strtab)和段表字符串表(.shstrtab)
ELF 文件中需要保存许多字符串名, 比如符号的名字, 段的名字。字符串的长度往往是不确定的, 那么对于一个不定长的字符串, 用固定的结构来表示它比较困难。ELF 的做法是把字符串集中起来保存在段中, 符号表的符号名字保存在字符串表中(.strtab), 所有段的名字保存在段表字符串表(.shstrtab)中
这一点和ext文件系统的inode对于文件名的管理方式有些类似
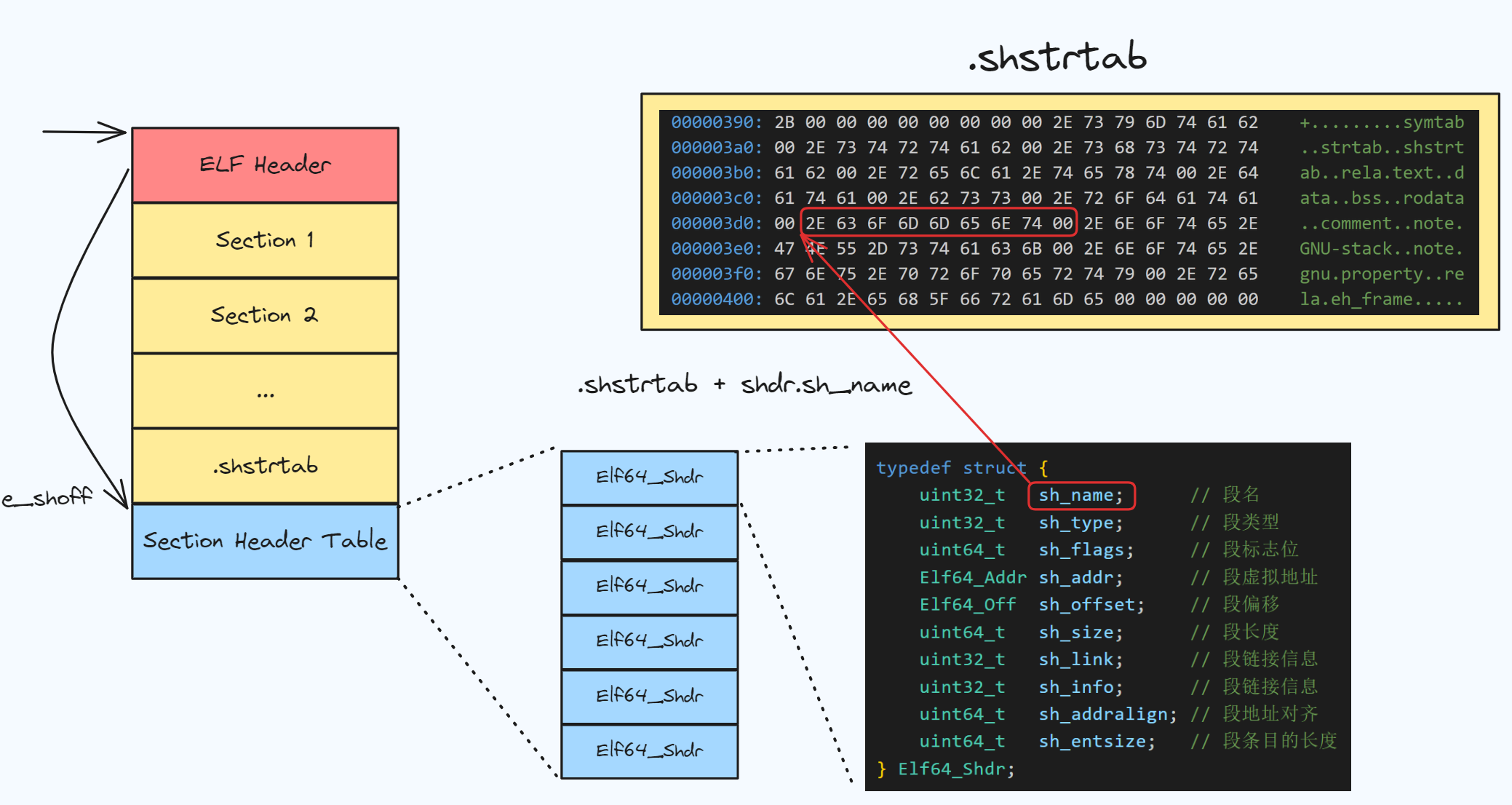
我们注意到上文中 Elf64_Shdr 结构体的字段 sh_name 的含义是段名, 但是类型是 uint32_t 而非 char*, 这是因为段本身并不记录其名字, 段的名字在 .shstrtab (段表字符串表)中统一记录, sh_name 只是一个索引值。采用这种方式就可以固定下来 Elf64_Shdr 结构体的大小
0x410 之后是段表, 0x398 开始是 .shstrtab(段表字符串表), 记录了每一个段的名字
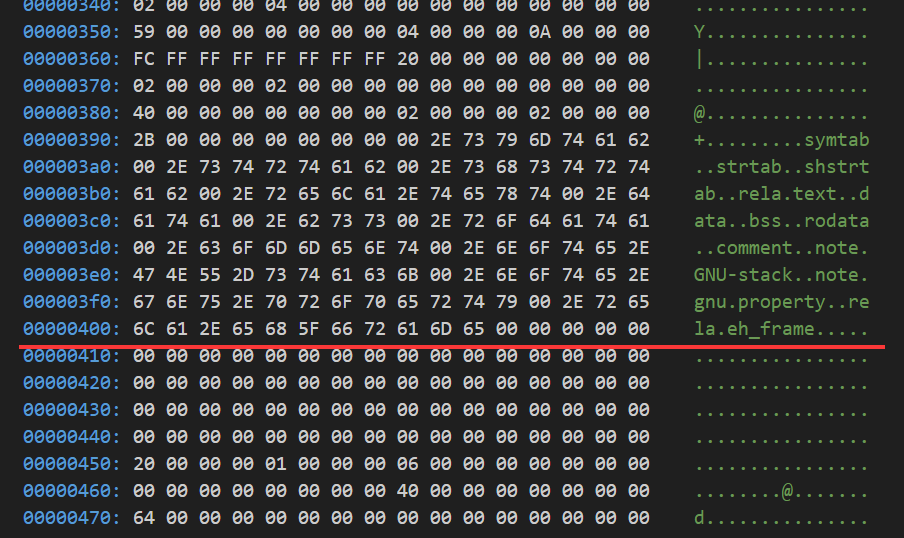
因此找到每一个段名字的方法如下, 首先找到 shstrtab, 然后利用每一个段 shdr 中的 sh_name 作为偏移量计算地址
程序头(program header)
ELF可执行文件中有一个专门的数据结构叫做程序头表(Program Header Table)用来保存"Segment"的信息。因为ELF目标文件不需要被装载,所以它没有程序头表,而ELF的可执行文件和共享库文件都有。跟段表结构一样,程序头表也是一个 Elf64_Phdr 结构体数组,它的结构体如下:
typedef struct {
Elf64_Word p_type; /* 段类型 */
Elf64_Word p_flags; /* 段标志 */
Elf64_Off p_offset; /* 段在文件中的偏移量 */
Elf64_Addr p_vaddr; /* 段的虚拟地址 */
Elf64_Addr p_paddr; /* 段的物理地址 */
Elf64_Xword p_filesz; /* 段在文件中的大小 */
Elf64_Xword p_memsz; /* 段在内存中的大小 */
Elf64_Xword p_align; /* 段对齐方式 */
} Elf64_Phdr;program header 在可重定位文件中不存在, 仅存在于已经完成链接的可执行文件, 可以使用
-l选项查看, 其中还多出来了 .init .plt .plt.got 等等一些段, 这些是与运行时和动态链接相关的段, 我们暂不做介绍
其中只有 PT_LOAD 的段需要被装载, 装载时需要根据段本身的一些属性由内核分配内存区域, 例如对齐方式, 段标志
- R(只读): 对应只读数据段
- RE(可读可执行): 对应代码段
- RW(可读可写): 对应数据段
PT_INTERP 的段为动态链接的解释器段, 可以通过读取其 p_offset 指向的字符串获取到动态链接器的路径(通常是 /lib64/ld-linux-x86-64.so.2)
其他特殊段
还可以使用 objcopy 将一张图片添加到 .o 文件中
$ objcopy -I binary -O elf64-x86-64 a.jpg SimpleSection.o
$ objdump -ht SimpleSection.o
SimpleSection.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .data 00009261 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, DATA
SYMBOL TABLE:
0000000000000000 g .data 0000000000000000 _binary_a_jpg_start
0000000000009261 g .data 0000000000000000 _binary_a_jpg_end
0000000000009261 g *ABS* 0000000000000000 _binary_a_jpg_size其中 _binary_a_jpg_start _binary_a_jpg_end _binary_a_jpg_size 分别表示起始地址, 结束地址, 大小, 我们可以在程序中直接声明并使用它们, 例如打印出图像数据的前10个字节:
#include <stdio.h>
extern char _binary_a_jpg_start;
extern char _binary_a_jpg_end;
extern int _binary_a_jpg_size;
int main() {
for (int i = 0; i < 10; i++) {
printf("%02x ", _binary_a_jpg_start[i]);
}
printf("\n");
return 0;
}这种将图片直接打入目标文件是一种方式,不过会导致文件变大
自定义段
int printf(const char *format, ...);
int global_init_var = 84;
int global_uninit_var;
__attribute__((section("FOO"))) int global_foo_var = 42;
__attribute__((section("BAR"))) void foo() {
}
void func1(int i) {
printf("%d\n",i);
}
int main(void) {
static int static_var = 85;
static int static_var2;
int a = 1;
int b;
func1(static_var + static_var2 + a + b);
}可以看到新增了两个段
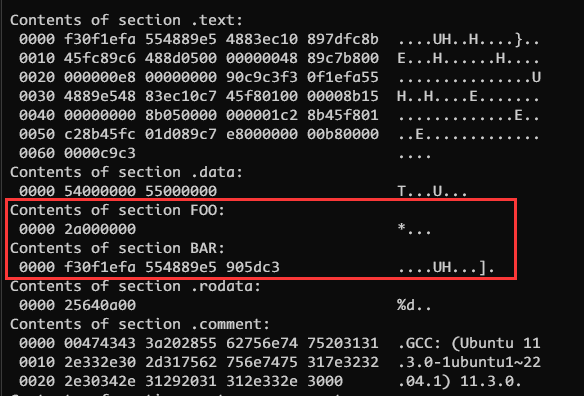
__attribute__((section("name")))是GCC和Clang编译器的扩展,它不是C标准的一部分,因此不是所有的编译器都支持它。在MSVC编译器中,可以使用
#pragma section指令来将变量或函数放置在自定义段中 (#pragma section指令是MSVC编译器的扩展) .例如:#pragma section("FOO", read, write) int global_foo_var = 42; #pragma section("BAR", execute) void foo() { // ... }
其他说明
当然 GCC 编译器提供了关于 ELF 的众多选项
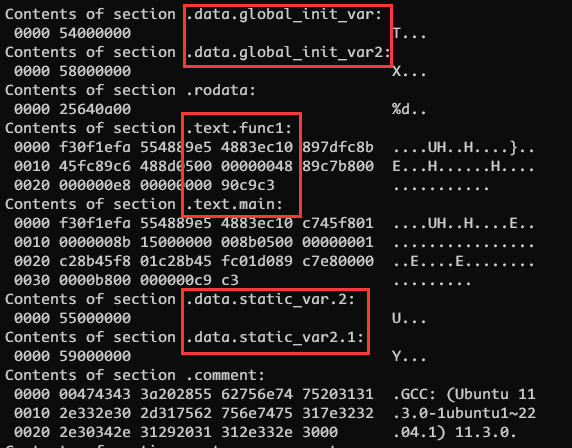
-fdata-sections 和 -ffunction-sections 是GCC编译器的选项,用于将数据和函数放置在单独的段中。
当使用这些选项时,GCC会将每个全局变量和函数放置在单独的段中,而不是将它们放置在默认的。data和。text段中.这样做的好处是可以将不同的数据和函数放置在不同的段中,从而使得目标文件更加灵活。例如,您可以将只读数据放置在只读段中,将可写数据放置在可写段中,将可执行代码放置在可执行段中。
gcc -c -fdata-sections -ffunction-sections file.c在将目标文件链接到可执行文件时,您需要使用 -Wl , --gc-sections 选项来删除未使用的段。这将从目标文件中删除未使用的段,从而减少可执行文件的大小。例如:
gcc -Wl,--gc-sections file.o -o program请注意,使用 -fdata-sections 和 -ffunction-sections 选项可能会增加目标文件的大小,并在链接时增加一些开销。然而,通过将数据和函数放置在单独的段中,可以使得目标文件更加灵活,并且可以优化可执行文件的大小和性能。
不难发现 ELF 中 .text .data 已经分开了