rdma
DMA和RDMA概念
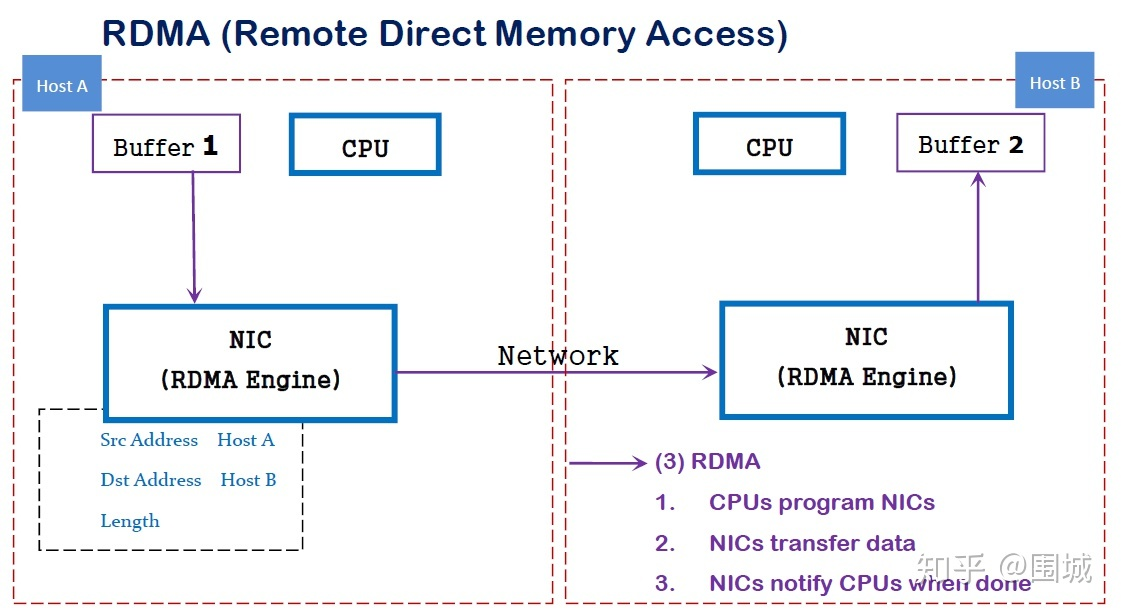
DMA(直接内存访问)是一种能力,允许在计算机主板上的设备直接把数据发送到内存中去,数据搬运不需要CPU的参与
传统内存访问需要通过CPU进行数据copy来移动数据,通过CPU将内存中的Buffer1移动到Buffer2中.DMA模式:可以同DMA Engine之间通过硬件将数据从Buffer1移动到Buffer2,而不需要操作系统CPU的参与,大大降低了CPU Copy的开销

RMDA
RDMA是一种概念,在两个或者多个计算机进行通讯的时候使用DMA, 从一个主机的内存直接访问另一个主机的内存
数据发生多次拷贝,中间的处理过程都需要CPU参与,如果不绕过操作系统内核对于CPU来说就是持续的开销
RDMA是一种host-offload, host-bypass技术,允许应用程序(包括存储)在它们的内存空间之间直接做数据传输.具有RDMA引擎的以太网卡(RNIC)--而不是host--负责管理源和目标之间的可靠连接.使用RNIC的应用程序之间使用专注的QP和CQ进行通讯
RDMA 直接绕过内核,让数据在应用层传递到网络接口.可以将数据从应用层直接
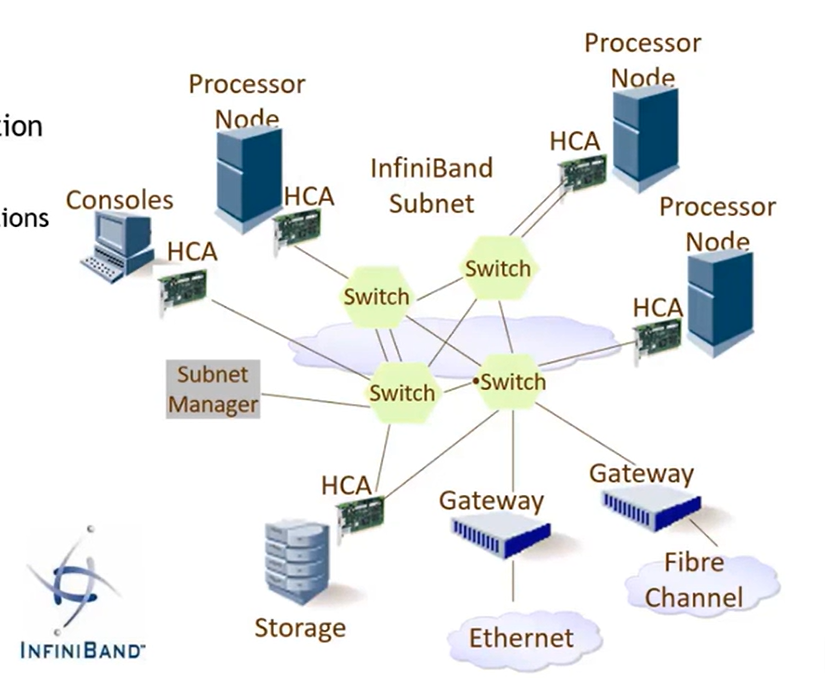
INFINIBAND TRADE ASSOCIATION (IBTA) 制定IB标准, openfabrics 开发IB 软件
硬件和软件配合为应用提供加速服务
Host Channel Adapter(HCA) 主机通道适配器,这里的通道指的是网络中的两个主机节点借助HCA IB网卡来建立主机通道,提供传输服务
SDN网络,不需要广播,网络扩展性非常好
子网管理器SDN控制器提供管理服务 48000 ioid
低延迟 高带宽 传输卸载,这里的卸载指的是从一个主机发送数据到另外一个主机,在传输的控制部分不需要CPU去执行控制协议栈,所有的控制传输服务都是由HCA配合交换网络完成的
infiniband 最大特点是它是一个SDN(software define networking 软件定义网络)
子网管理器构成了软件定义网络的控制面,控制面发送子网的所有配置到各个交换机到各个端口.
在设备上电之后,子网管理器会给所有的给所有的端口分配二层地址,之后的通信都是由二层地址在子网端口之间进行通信. 因为子网管理器在SDN中具有全局的视角,所以它可以轻易的进行一个子网的路由计算,计算两点之间的路由,并且把对应的路由表下发到对应的交换机
所有的路由寻址都是由SDN来控制的,这样使得网络的路由拓扑收敛性特别好,任何一个交换机,任何一个路由或者交换机离线或者上线,就会进行一次路由表的更新,可扩展性和易维护性很好
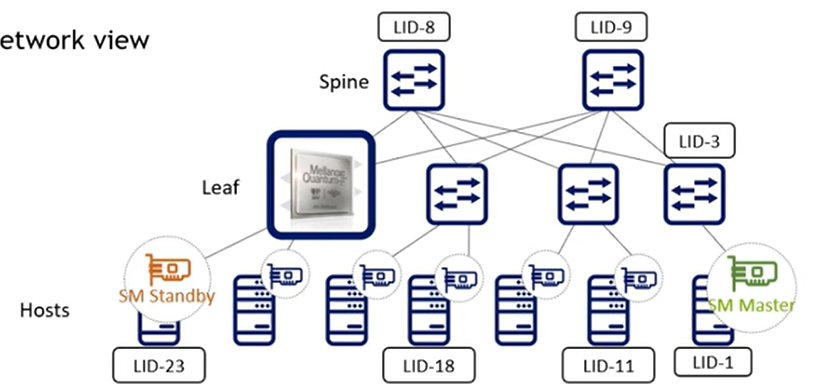
Infiniband使用的是基于信用的二层流控(credit based link layer flow control)

当一跳的交换机端口要往下一跳的端口发送数据之前,它会首先查询下一条是否存在buffer来接收数据,如果有才会传输
他会先在控制链路上和下一跳进行沟通,否则如果没有buffer也发就会造成丢包,造成性能的损失
相比于尽力而为,量力而行,只要物理层是可靠的,二层之上可以实现无损网络
在无损网络之上,我们就可以利用infiniband获得很好的传输服务
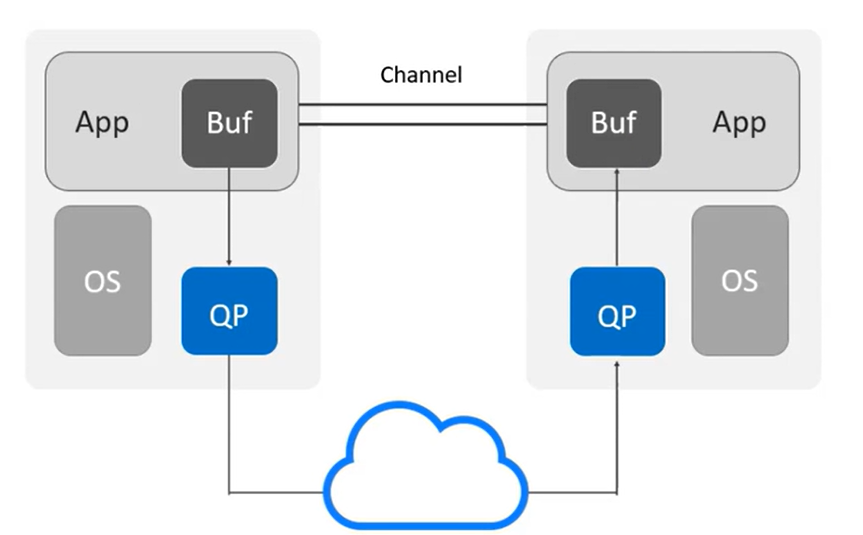
如果一个应用想要从另外一个节点的伙伴应用获取数据,IB可以通过HCA管理QP在两个节点之间建立虚拟通道,可以使发起应用的数据获取到想要得到的数据,否则就需要调用OS的传输协议栈,经过多次的传输拷贝才能从网络发送过来,infiniband提供了更好的传输服务
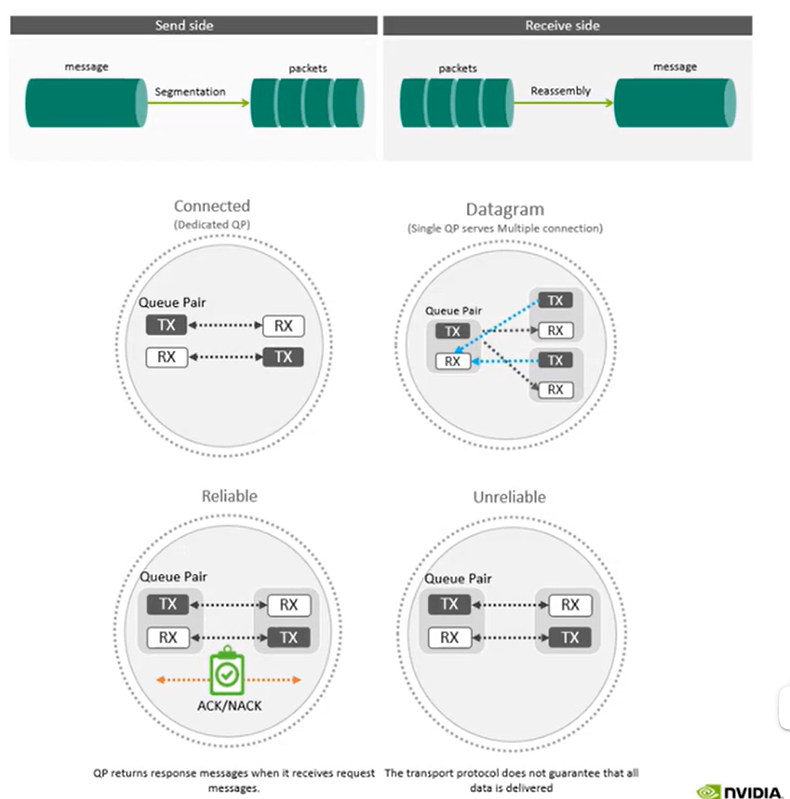
传输层需要提供的一个服务是把一段发送的message进行切分,假如发送2G的数据,传输层会由HCA将数据切分成package(mtu 最大传输单元 4k),发送到对面再由对面的HCA组装package成message写入到应用中去,整个的过程都是由网卡来卸载的,不需要CPU去做消息切分,发送,整合,复制
QP(queue pair)可以建立不同模式的队列对,面向连接的,不面向连接的
面向连接指的是一个QP会和另外一个节点的QP组成关联,读写是一对一的
datagram不面向连接都需要指定具体是发送给哪一个QP,建立一对多
可靠的,不可靠的
可靠的发送ACK,保证传输层的可靠/否则NACK发起重传,都不需要CPU干预,实现高质量的传输和直接的内存访问
不可靠,只管发,appication来决定,重传也是application决定重传
这种传输服务使能了RDMA直接访问内存的机制,access而不只是收发
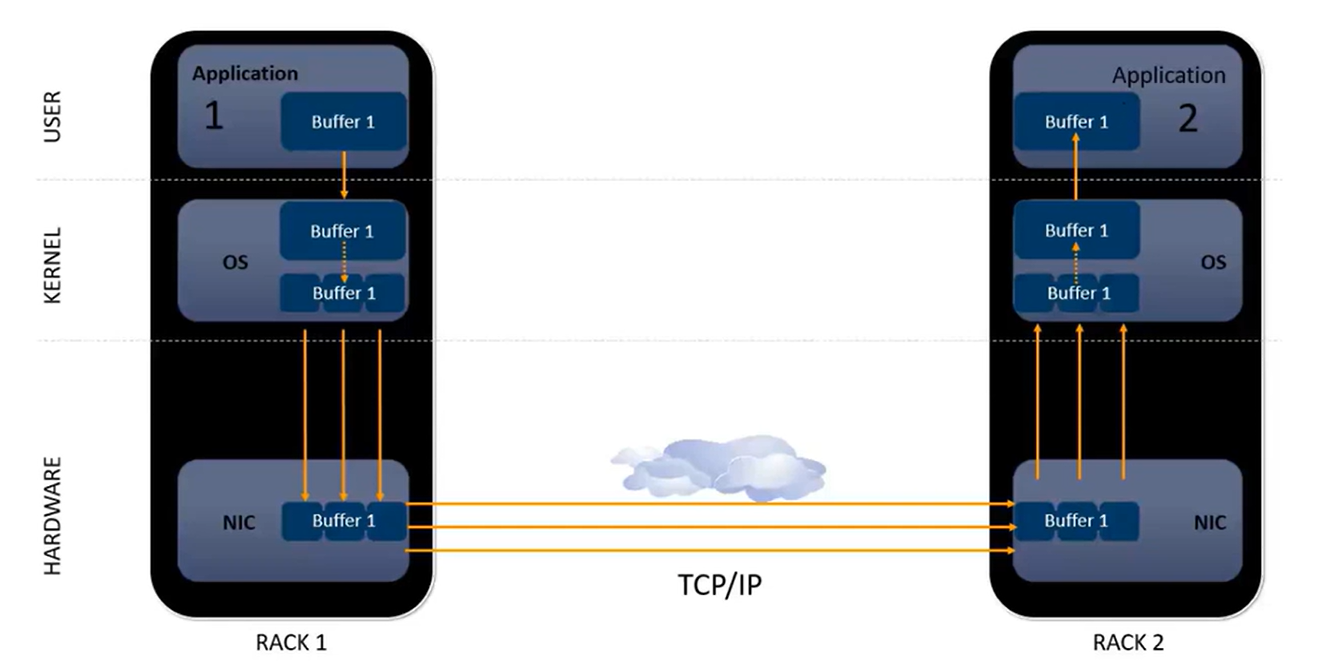
用户数据复制到kernel协议栈,kernel协议栈找到一块可用的网卡,网卡把数据传输到对方,又要用CPU,复制到协议栈,耗时耗费CPU资源
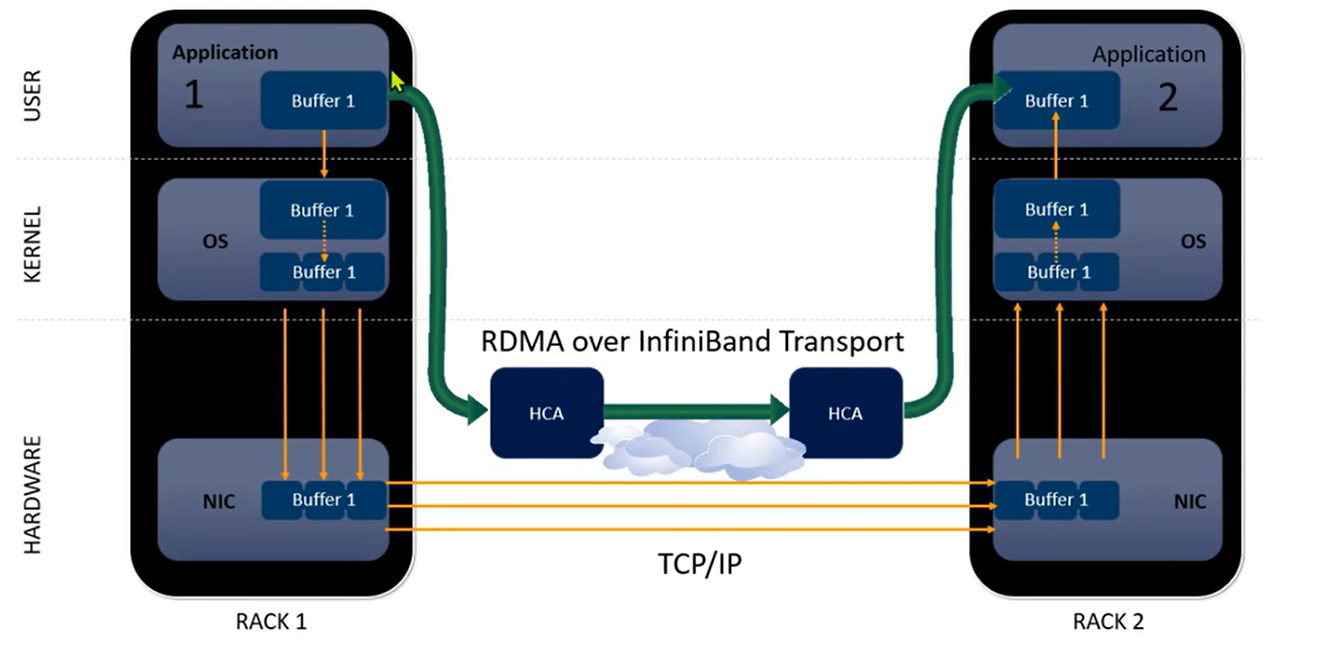
相比于IB,CPU不感知,kernel bypass,最低的延迟
PEER TO PEER COMMUNICATION
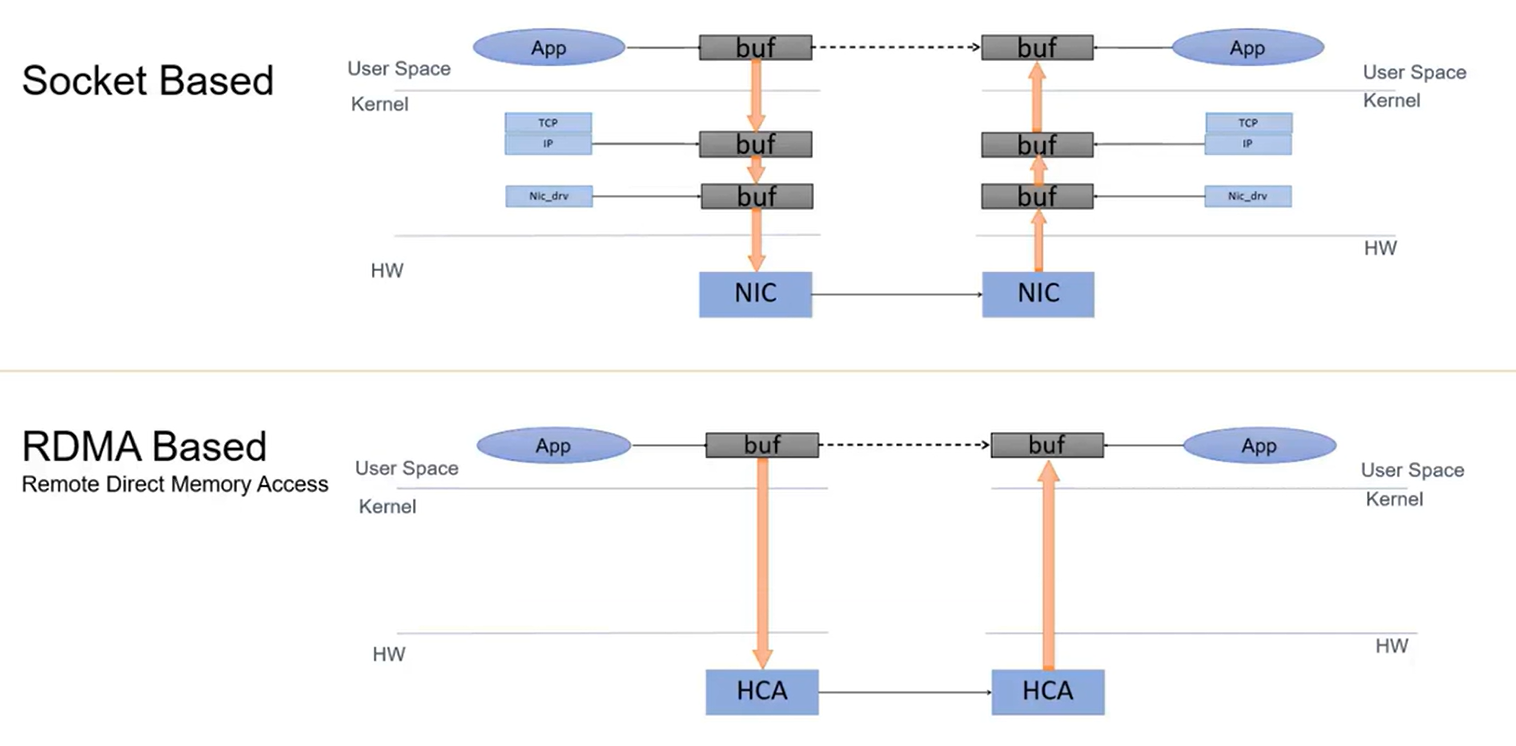
应用运行在用户态,每当他需要去和远端的用户通信的时候,他不得不调用另外一个CPU进程,这个进程运行在内核态,他按照网络的协议栈进行处理判断去调用另外一个进程,硬件的driver,这个driver再去进行
占用内存,耗费时间,CPU资源也被分到了内核协议栈这里,使得没有办法完全投入到应用中去
相比之下RDMA CPU资源沉浸在计算,通信的开销由HCA卸载
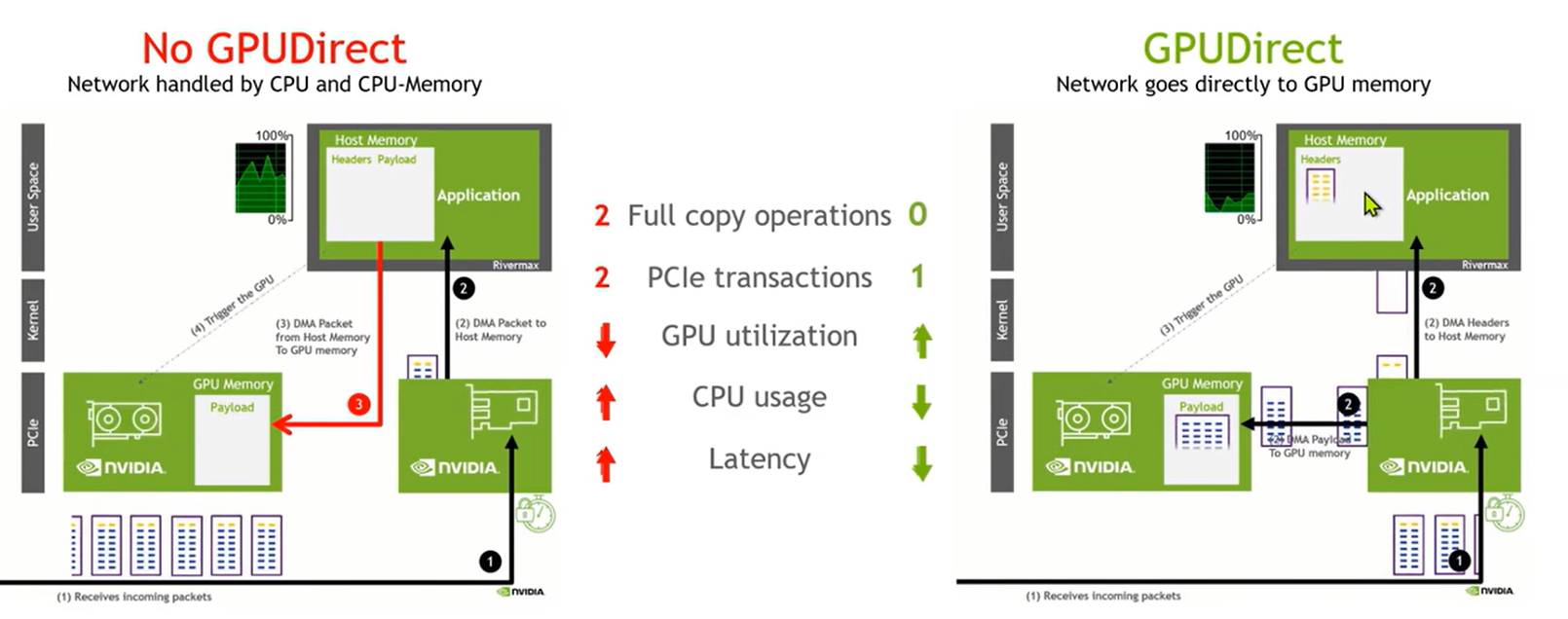
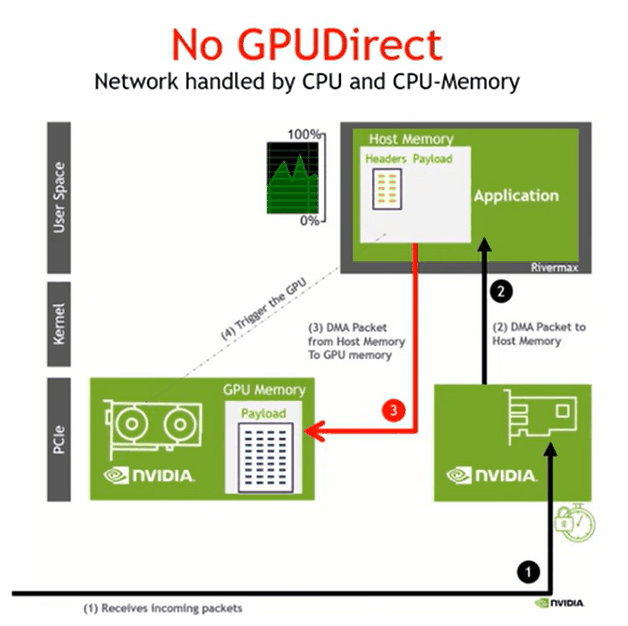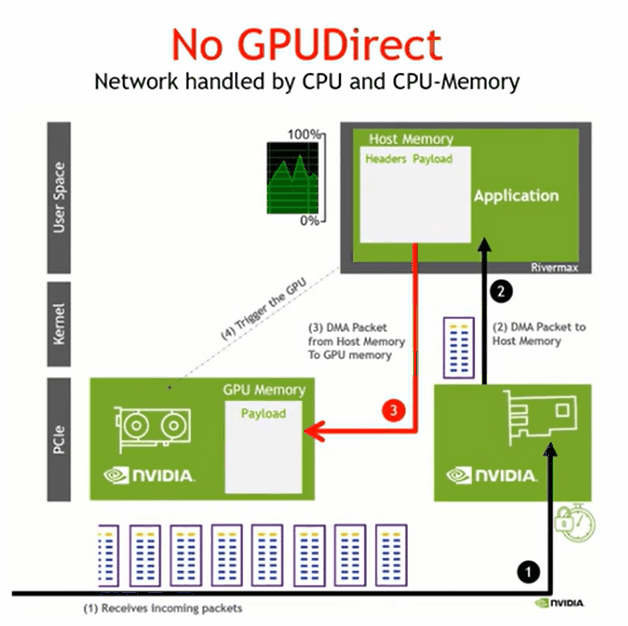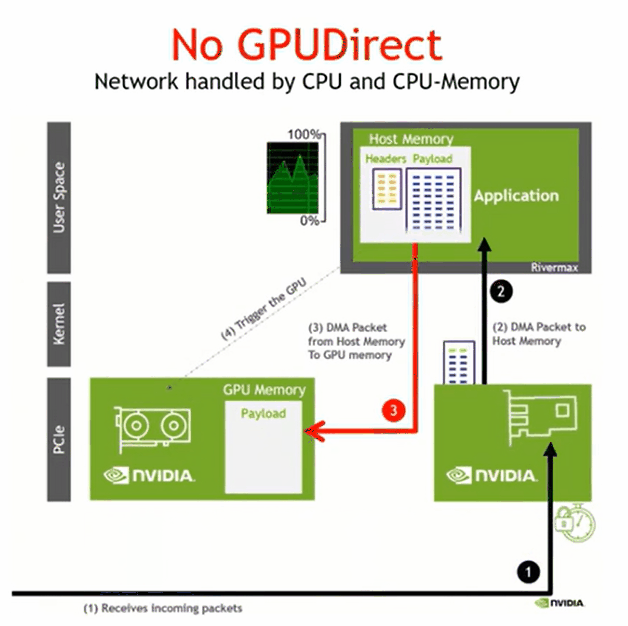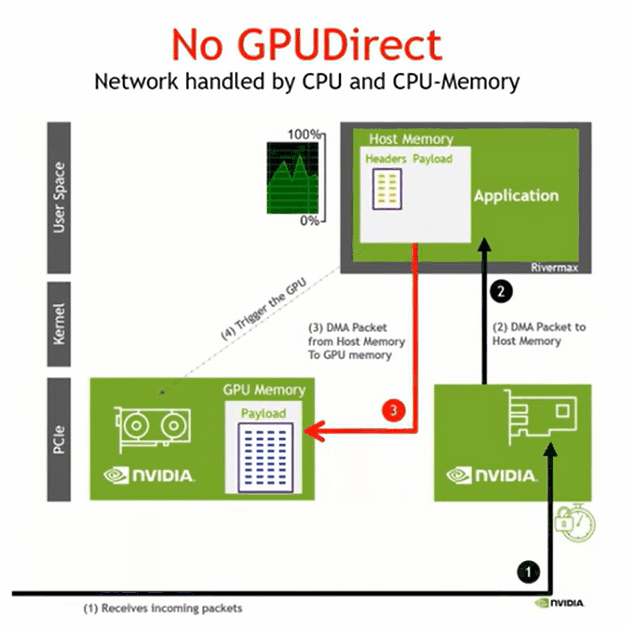
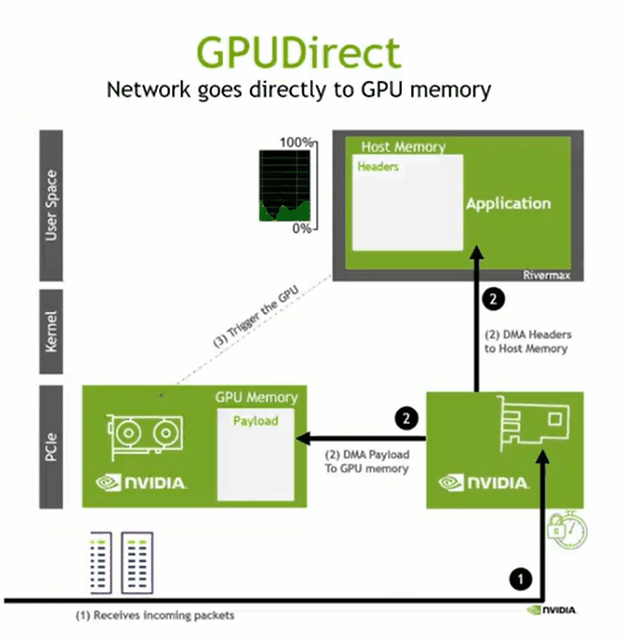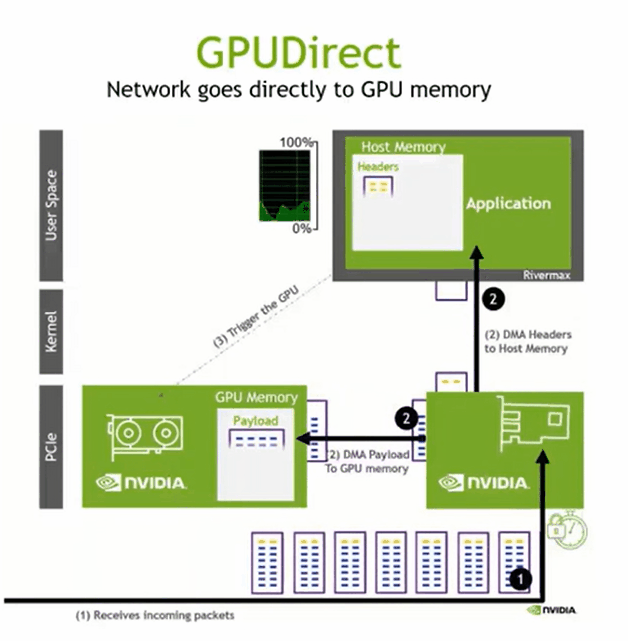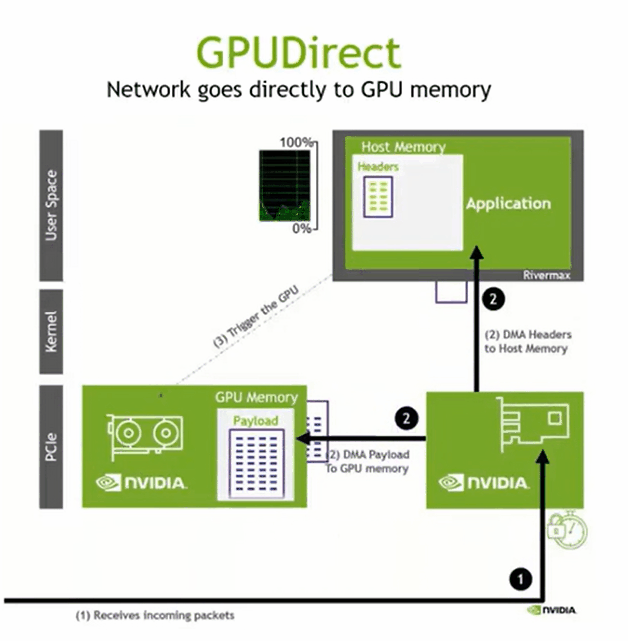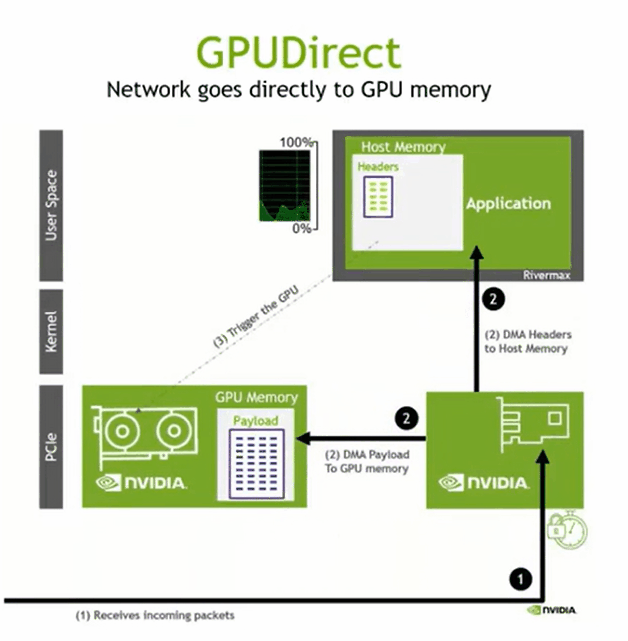
GPUDIRECT RDMA
数据 -> host memory -> host to device copy
将数据写到GPU memory,host memory 得到写入完成的通知即可,全部完成启动下一阶段的并行计算
 |  |
|---|
MPI
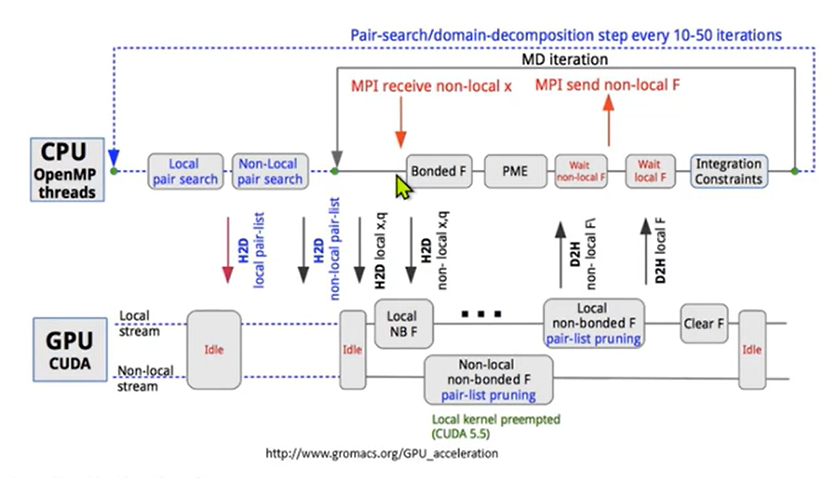
MPI是高性能计算常用的实现方式,它的全名叫做 Message Passing Interface
在MPI超级计算中,所有的MPI进程齐头并进的做计算,它计算出来的数据需要发送给伙伴节点,去支持伙伴节点的计算
以及当它自己计算到某些节点的时候,也要得到伙伴节点的数据才可以进行下一步的计算,这种时候就需要MPI运行时提供 tag matching 的服务
这种服务需要分两块buffer管理
软件上需要实现,如果我已经在请求接收远端的某些buffer,那么我需要注册一个tag,如果还没有算到并且数据已经到了那么就临时的放在一个buffer中.目前这种匹配机制可以完全由infinband网卡进行卸载
也就是说网卡接收到一个数据之后,他回去检查该数据是否存在匹配的receive,如果存在则网卡直接将数据送给应用.反之,如果没有发现对应的tag,他会直接放到软件的buffer中去
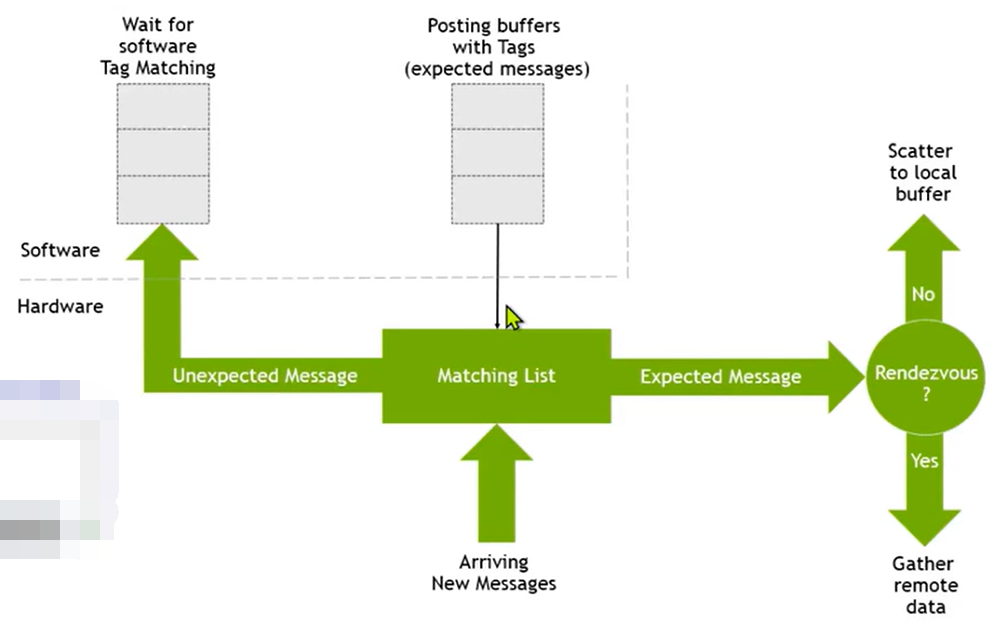
另外一种高级的卸载是,如果我的伙伴通知数据已经计算完毕并且提供了发送了 Rendezvous 的消息头, 则网卡在接收到该信息之后会根据该消息头直接去远端的伙伴节点读取数据并写入指定应用中,以上过程都不需要CPU参与
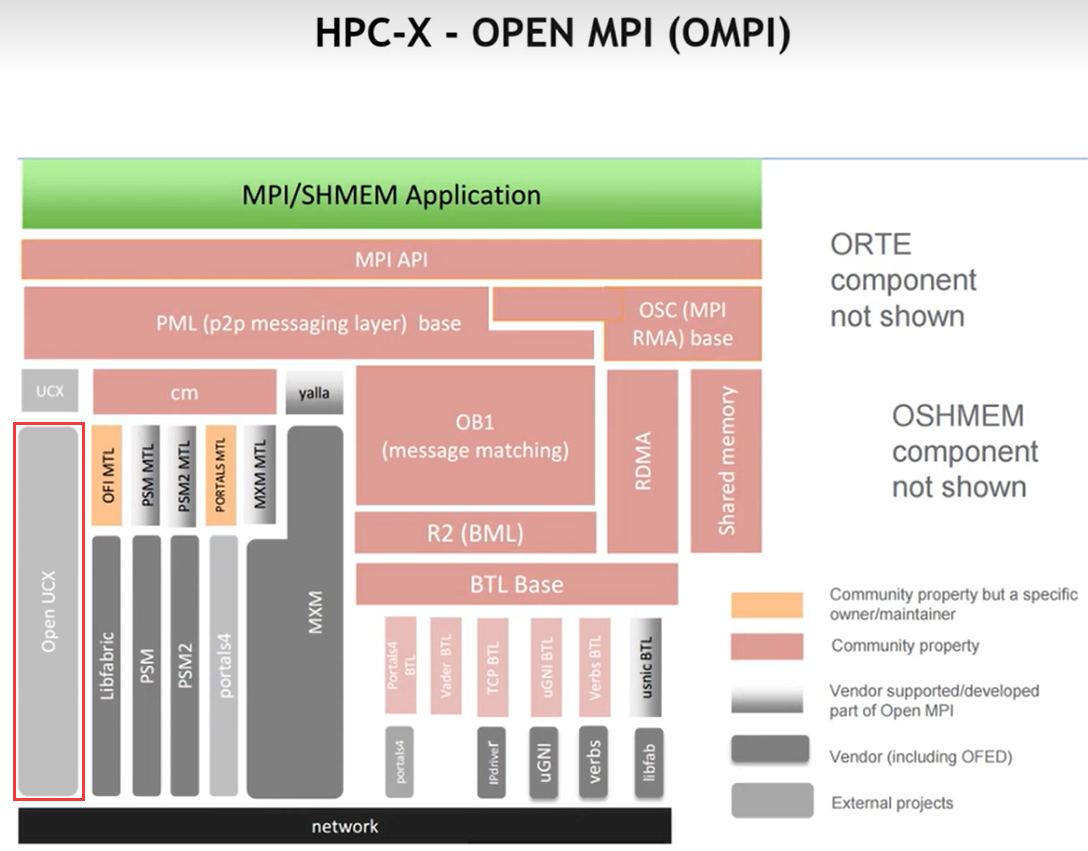
例如在 OpenMPI 通信库中,在infiniband的网络之上调用 OpenUCX 进行点对点的RDMA传输,这种传输可以再去控制可靠的,不可靠的,面向连接的,不面向连接,都可以通过不同的UCX配置
tag matching ,GPU RDMA都可以在UCX中配置
在UCX之上有OpenMPI,由OpenMPI去构建点对点的 PML (p2p messageing layer), 再去支持上层的MPI,API