net-arch
为降低复杂度并提高灵活性,大型软件系统一般采用分层的思路进行设计.
电商平台是一个典型的例子,后端可能分成数据库层、缓存层、业务逻辑层、接入层等等.每个层只专注于本层的处理逻辑,复杂性大大降低;各个层互相配合,共同完成复杂的业务处理.
OSI 和 TCP/IP 模型
网络通信也是一个非常庞大的系统工程,网络协议势必也需要采用分层设计思想.为此,国际标准化组织提出了开放式系统互联模型( open system interconnection model ),简称 OSI模型 .
OSI模型是一种概念模型,用于指导通信系统设计,并实现标准化.该模型将通信系统中的数据流划分为七个层. 但是目前使用最广泛的通信协议是 TCP/IP 系列协议. TCP/IP模型中的层次结构相对较简单,减少了设计和实现的复杂性
物理层
假设,计算机网络现在还没有被发明出来,作为计算机科学家的你,想在两台主机间传输数据,该怎么办呢?
这时,你可能会想到,用一根电缆将两台主机连接起来: 物理课大家都学过,电压可以分为 低电平 和 高电平 .因此,我们可以通过控制电平高低,来达到传输信息的目的: 主机①控制电缆电平的高低, 主机②检测电平的高低,主机间数据传输便实现了!
用数学语言进一步抽象:以低电平表示 0 ,高电平表示 1 .这样就得到一个理想化的信道:
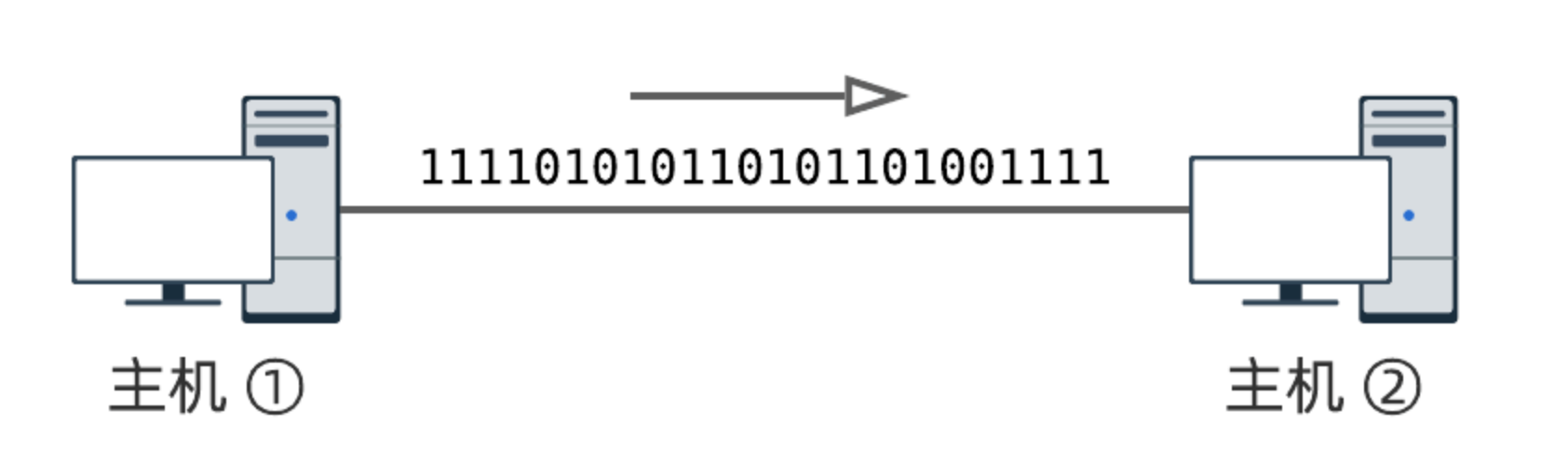
至此,我们是否得到一个可靠的比特流信道,万事具备了呢? 理论上是这样的,但现实世界往往要比理想化的模型更复杂一些.
收发控制
信道是无穷无尽的,状态要么为 0 ,要么为 1 ,没有一种表示空闲的特殊状态; 举个例子,主机①向主机②发送比特序列 101101001101 ,如下图(从右往左读).最后一个比特是 1 ,对应的电平是高电平.发送完毕后,主机①停止控制电缆电平,所以仍保持着高电平状态:
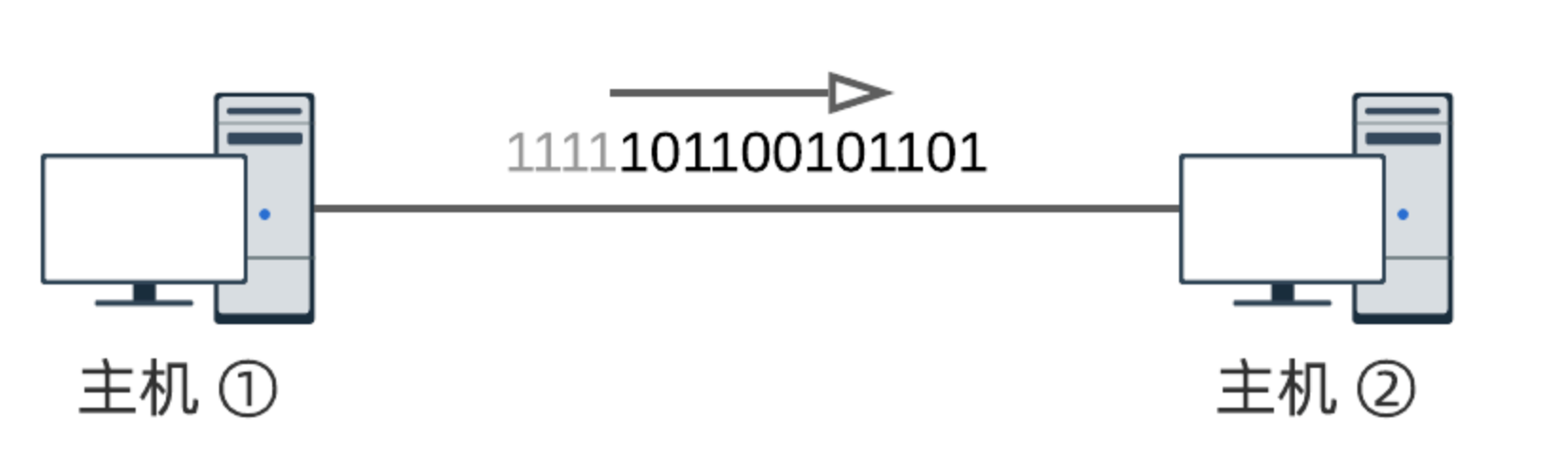
换句话讲,信道看起来仍按照既定节拍,源源不断地发送比特 1 (灰色部分), 主机②如何检测比特流结尾呢?
我们可以定义一些特殊的比特序列,用于标识开头和结尾.例如, 101010 表示开头, 010101 表示结尾:
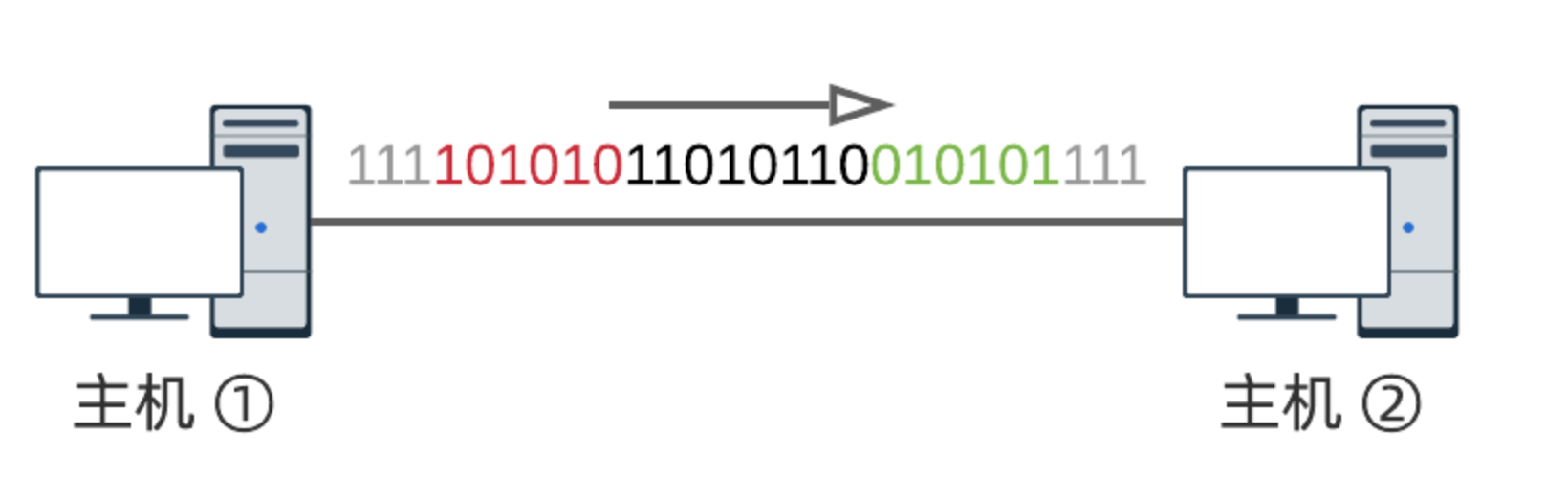
- 主机①首先发送 101010 (绿色),告诉主机②,它开始发数据了;
- 主机①接着发送数据 01101011 (黑色部分);
- 主机①最后发送 010101 (红色),告诉主机②,数据发送完毕;
冲突仲裁
如果两台服务器同时向信道发送数据,会发生什么事情呢?
一边发 0 ,一边发 1 ,那信道到底应该是 0 还是 1 呢? 肯定冲突了嘛!有什么办法可以解决冲突吗?
- 引入一根新电缆,组成双电缆结构,每根电缆只负责一个方向的传输.这样一来,两个方向的传输保持独立,互不干扰,可以同时进行.这样的传输模式在通讯领域称为 全双工模式 .
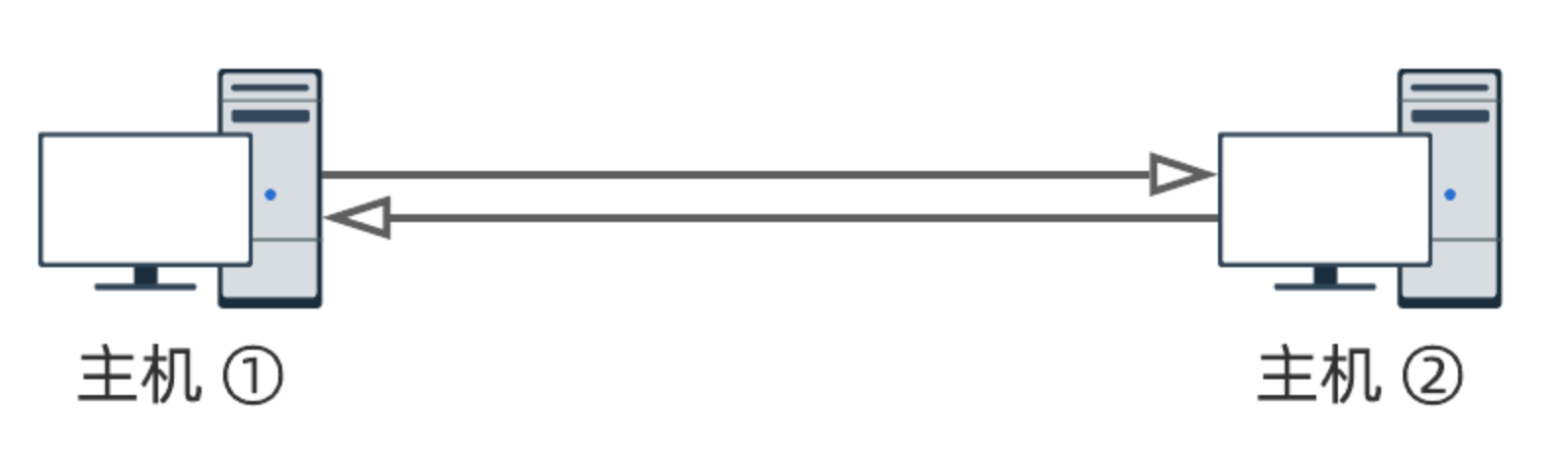
- 在硬件层面实现一种仲裁机制:当检测到多台主机同时传输数据时,及时叫停,并协商哪一方先发.这样一来,信道同样支持双向通讯,但不可同时进行.这种传输模式则称为 半双工模式 .
- 单工 ( simplex ),只支持单向通讯,即从其中一端发往另一端,反之不行;
- 半双工 ( half duplex ),支持双向通讯,但不可同时进行;
- 全双工 ( full duplex ),支持双向通讯,而且可以同时进行;
数据链路层
以两台主机为例讨论了一个理想化的物理层模型. 现在,我们将问题进一步延伸:多台主机如何实现两两通讯呢?我们以三台主机为例进行讨论:
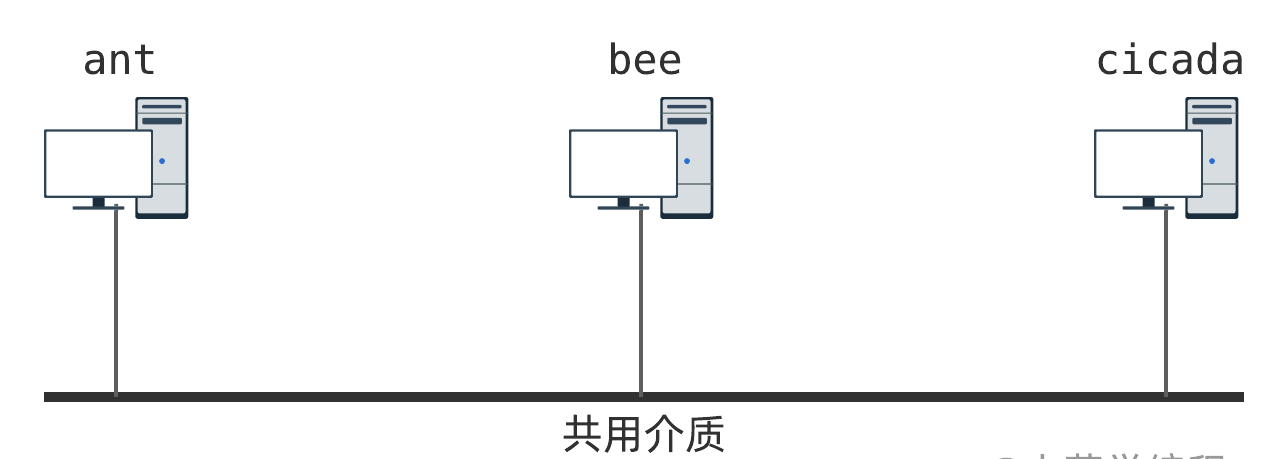
如上图,有 3 台主机,名字分别是: ant 、 bee 以及 cicada . 为了实现主机间通讯,我们将三者连接到一根共用导线.每台主机都可以改变导线电平,也可以检测导线电平. 与此同时,假设在硬件层面,多方通讯冲突仲裁机制已经实现并且可用.
主机寻址
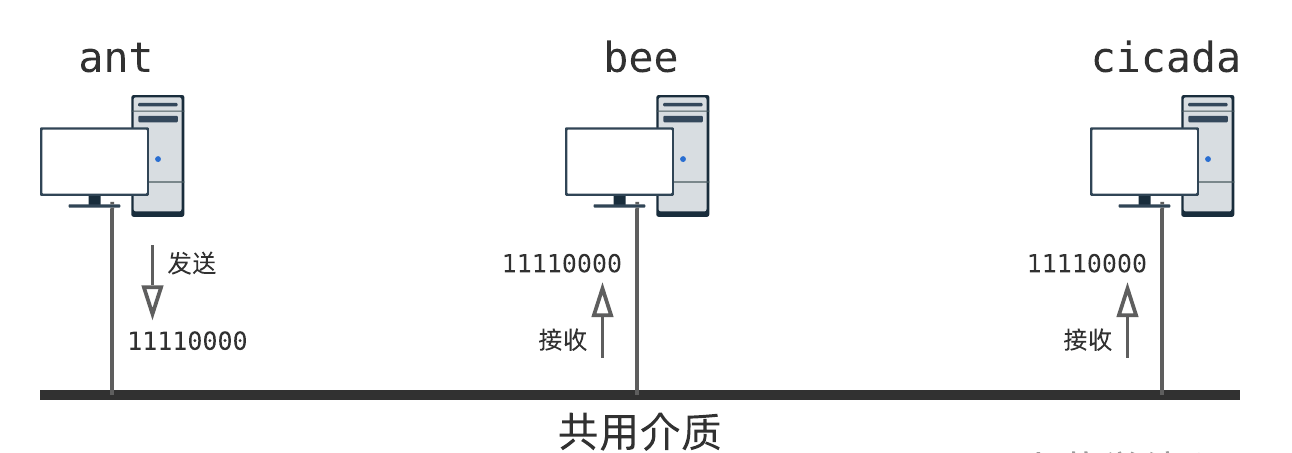
假设, ant 向 bee 发送一个数据 11110000 .由于导线是共享的,所有主机都可以检测到电平信号.换句话讲, bee 和 cicada 都会收到这个数据 11110000 ,而 cicada 本不应该接收这个数据!另一方面, bee 收到数据后,也不知道数据到底是谁发给它的
为此,我们需要引入一些比特,用来标识数据的 来源 以及 目的地 .例子中只有 3 台主机,两个比特就足以唯一确定一台主机
| 机器 | 比特 |
|---|---|
| ant | 00 |
| bee | 01 |
| cicada | 10 |
那么,发送数据时,再加上两个比特用于表示来源主机,两个比特表示目标主机,问题不就解决了吗?
如图,主机下方的灰色比特唯一标识一台主机:
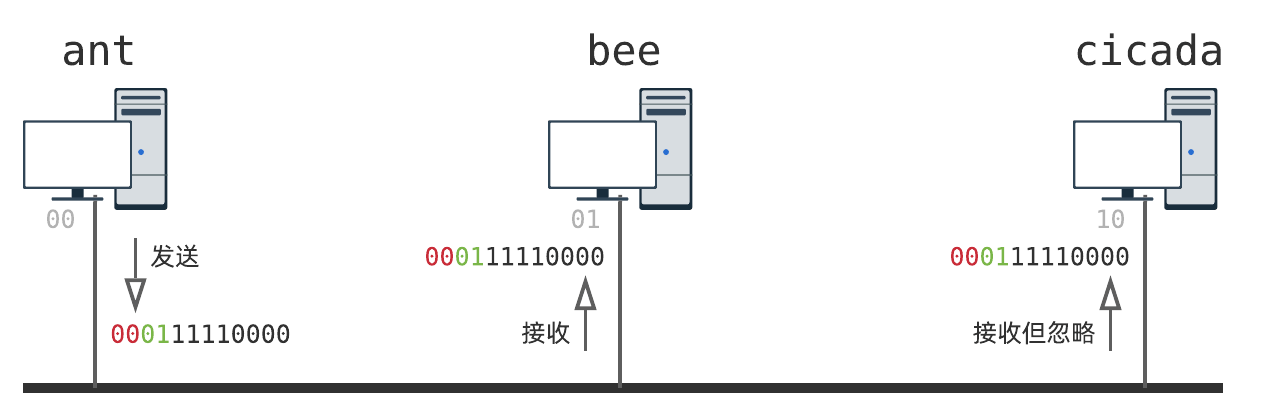
ant 发送数据时,在最前面加上两个比特(红色)用于标识来源机器, 00 表示 ant ;另外两个比特(绿色)用于标识目标机器, 01 表示 bee .
当 bee 收到数据后,检查前两个比特(红色),值为 00 ,便知道它是 ant 发出来的;检查紧接着的两个比特(绿色),值为 01 ,与自己匹配上,便愉快地收下了.相反, cicada 收到数据后,发现 01 和自己 10 匹配不上,便丢弃这个数据.
新引入比特所起的作用,在计算机网络中称为 寻址 . 这两个比特也就称为 地址 ,其中,红色为源地址,绿色为目的地址. 引入寻址机制后,我们完美地解答了数据从哪来,到哪去的困惑.
信道复用
信道只有一个,但是通讯需求是无穷无尽的: 传输研究数值、文件打印、即时通讯,不一而足. 如何解决这个矛盾呢?套路还是一样的: 引入新的比特标识数据类型.
假设,总的通讯需求就上面这 3 个.那么, 2 个额外的比特即可解决问题
| 类型 | 比特 |
|---|---|
| 研究数据 | 00 |
| 文件打印 | 01 |
| 即时通讯 | 10 |
举个例子,假设 ant 向 bee 上报研究数据并打印一个文件:
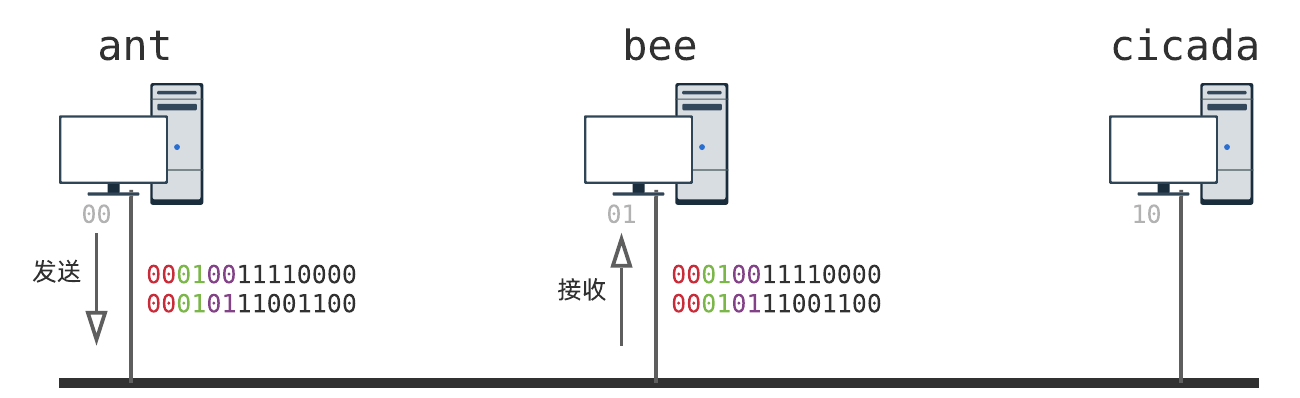
bee 接收到数据后,根据紫色比特,决定数据如何处理.通过新引入的紫色比特,我们在同个信道上实现了不同的通讯!
接下来,从理论的视角来审视这个场景:
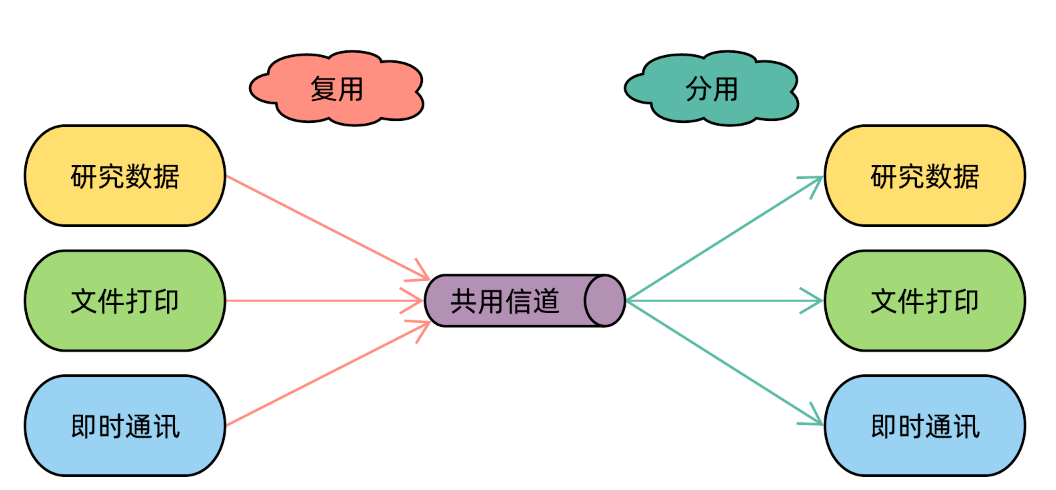
信道只有一个,却要承载多样的通讯任务.在发送端,通过加入紫色比特,将不同的数据通过一个共用信道发送出去,这个过程叫做 复用 ( Multiplexing );在接收端,从共用信道上接收数据,然后检查紫色比特决定数据如何处理,这个过程叫做 分用 ( Demultiplexing ).
在接下来的章节,我们将看到 复用分用 的思想贯彻计算机网络的始终.
到目前为止,我们引入了 3 种不同的比特,分别是 源地址 、 目的地址 以及 数据类型 . 对于这些比特的位数以及含义的约定,便构成 网络协议 .
至此,我们解决了多台共用信道主机间的通讯问题,这相当于网络分层结构中的 数据链路层 .数据链路层负责为上层提供链路通讯能力,主要作用是: 寻址, 数据复用/分用
以太网帧
数据链路层有一个非常重要的协议: 以太网协议. 使用以太网协议进行通信的主机间,必须通过某种介质直接相连.通信介质可以是真实的物理设备,如网线、网卡等;也可以是通过虚拟化技术实现的虚拟设备.
在以太网中,数据通信的基本单位是 以太网帧 ( frame ),由 头部 ( header )、数据 ( data )以及 校验和 ( checksum )三部分构成:

头部包含 3 个字段,依次是:
- 目的地址 ,长度是 6 字节,用于标记数据由哪台机器接收;
- 源地址 ,长度也是 6 字节,用于标记数据由哪台机器发送;
- 类型 ,长度是 2 字节,用于标记数据该如何处理,
0x0800表示该帧数据是一个 IP 包(后续章节介绍).
注意到以太网帧中目的地址放在最前面, 这是为了方便接收方收到一个以太网帧后,最先处理目的地址字段.如果发现该帧不是发给自己的,后面的字段以及数据就不需要处理了.基础网络协议影响方方面面,设计时处理效率也是一个非常重要的考量.
数据 可以是任何需要发送的信息,长度可变, 46 至 1500 字节均可. 上层协议报文,例如 IP 包,可以作为数据封装在以太网帧中,在数据链路层中传输.因此,数据还有另一个更形象的称谓,即 负荷 ( payload )
由于物理信号可能受到环境的干扰,网络设备传输的比特流可能会出错.一个以太网帧从一台主机传输到另一台主机的过程中,也可能因各种因素而出错. 我们可以用诸如 循环冗余校验 ( CRC )算法,为以太网帧计算校验和.如果以太网帧在传输的过程出错,校验和将发生改变. 以太网帧最后面有一个 4 字节字段,用于保存校验和.发送者负责为每个以太网帧计算校验和,并将计算结果填写在校验和字段中;接收者接到以太网帧后,重新计算校验和并与校验和字段进行对比;如果两个校验和不一致,说明该帧在传输时出错了.
网卡
参与以太网通讯的实体,由以太网地址唯一标识.以太网地址也叫做 MAC 地址(medium access control address)
以太网地址在不同场景,称谓也不一样,常用叫法包括 以太网地址/MAC 地址/硬件地址/物理地址/网卡地址
在以太网中,每台主机都需要安装一个物理设备并通过网线连接到一起, 这个设备就是 网卡 ( NIC ),网络接口卡 ( network interface card )的简称.有些文献也将网卡称为 网络接口控制器 ( network interface controller ).
从物理的层面看,网卡负责将比特流转换成电信号发送出去; 反过来,也负责将检测到的电信号转换成比特流并接收.
从软件的层面看,发送数据时,内核协议栈负责封装以太网帧(填充 目的地址 , 源地址 , 类型 和 数据 并计算 校验和),并调用网卡驱动发送; 接收数据时,负责验证 目的地址 、 校验和 并取出数据部分,交由上层协议栈处理.
每块网卡出厂时,都预先分配了一个全球唯一的 MAC地址 ,并烧进硬件. 不管后来网卡身处何处,接入哪个网络,MAC 地址均不变. MAC 地址主要由设备制造商分配,因此通常称为烧录地址,或以太网硬件地址、硬件地址或物理地址.每个地址都可以存储在接口硬件中,例如其只读存储器,也可以通过固件机制存储.但是,许多网络接口都支持更改其 MAC 地址.
MAC 地址由 6 个字节组成( 48 位),可以唯一标识 2^48 ,即网络设备(比如网卡). MAC 地址 6 个字节可以划分成两部分,如下图
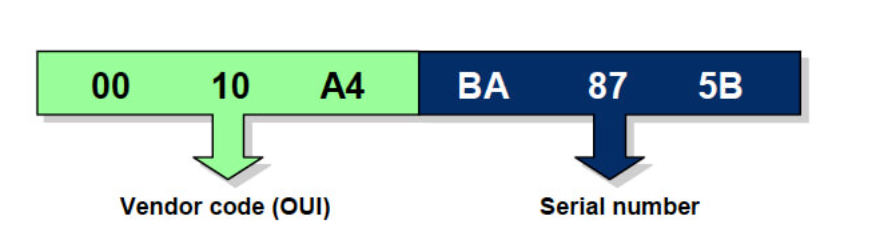
- 3 字节长的 厂商代码 ( OUI ),由国际组织分配给不同的网络设备商;
- 3 字节长的 序列号 ( SN ),由厂商分配给它生产的网络设备;
Linux 上有不少工具命令可以查看系统当前接入的网卡以及每张网卡的详细信息
$ ifconfig
enp0s3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.2.15 netmask 255.255.255.0 broadcast 10.0.2.255
inet6 fe80::a00:27ff:fe49:50dd prefixlen 64 scopeid 0x20<link>
ether 08:00:27:49:50:dd txqueuelen 1000 (Ethernet)
RX packets 3702 bytes 4881568 (4.8 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 538 bytes 42999 (42.9 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
enp0s8: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.56.2 netmask 255.255.255.0 broadcast 192.168.56.255
inet6 fe80::a00:27ff:fe56:831c prefixlen 64 scopeid 0x20<link>
ether 08:00:27:56:83:1c txqueuelen 1000 (Ethernet)
RX packets 4183 bytes 1809871 (1.8 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 2674 bytes 350013 (350.0 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 679 bytes 1510416 (1.5 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 679 bytes 1510416 (1.5 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0例子中,系统总共有 3 块已启用网卡,名字分别是 enp0s3 、 enp0s8 以及 lo .其中 lo 是环回网卡,用于本机通讯. ether 08:00:27:49:50:dd 表明,网卡 enp0s3 的物理地址是 08:00:27:49:50:dd
ip 命令也可以查看系统网卡信息,默认显示所有网卡. ip 命令是一个比较新的命令,功能非常强大.它除了可以用于管理网络设备,还可以用于管理路由表,策略路由以及各种隧道.因此,推荐重点学习掌握 ip 命令的用法
如果程序中需要用到网卡地址, 有个方法是执行 ip 命令输出网卡详情,然后从输出信息中截取网卡地址
$ ip link show dev enp0s3 | grep 'link/ether' | awk '{print $2}'
08:00:27:49:50:dd更优雅的办法是通过套接字编程,直接向操作系统获取.Linux 套接字支持通过 ioctl 系统调用获取网络设备信息,大致步骤如下
#include <net/if.h>
#include <stdio.h>
#include <string.h>
#include <sys/ioctl.h>
#include <sys/socket.h>
void mac_ntoa(unsigned char *n, char *a) {
// traverse 6 bytes one by one
sprintf(a, "%02x:%02x:%02x:%02x:%02x:%02x", n[0], n[1], n[2], n[3], n[4], n[5]);
}
int main(int argc, char *argv[]) {
if (argc < 2) {
fprintf(stderr, "no iface given\n");
return 1;
}
// create a socket, any type is ok
int s = socket(AF_INET, SOCK_STREAM, 0);
if (-1 == s) {
perror("Fail to create socket");
return 2;
}
// fill iface name to struct ifreq
struct ifreq ifr;
strncpy(ifr.ifr_name, argv[1], 15);
// call ioctl to get hardware address
int ret = ioctl(s, SIOCGIFHWADDR, &ifr);
if (-1 == ret) {
perror("Fail to get mac address");
return 3;
}
// convert to readable format
char mac[18];
mac_ntoa((unsigned char *)ifr.ifr_hwaddr.sa_data, mac);
// output result
printf("IFace: %s\n", ifr.ifr_name);
printf("MAC: %s\n", mac);
return 0;
}大致步骤如下
- 创建一个套接字,任意类型均可;
- 准备 ifreq 结构体,用于保存网卡设备信息;
- 将待查询网卡名填充到 ifreq 结构体;
- 调用 ioctl 系统调用,向套接字发起 SIOCGIFHWADDR 请求,获取物理地址;
- 如无错漏,内核将被查询网卡的物理地址填充在 ifreq 结构体 ifr_hwaddr 字段中;
集线器和交换机
集线器 位于 物理层,而 交换机 位于 数据链路层
采用以太网进行通信的主机,需要通过网线之类的介质连接到一起.那么,如何将多根网线连接在一起呢?
最简单的方式是将所有网线接到一个 集线器 ( hub )上,如下图:
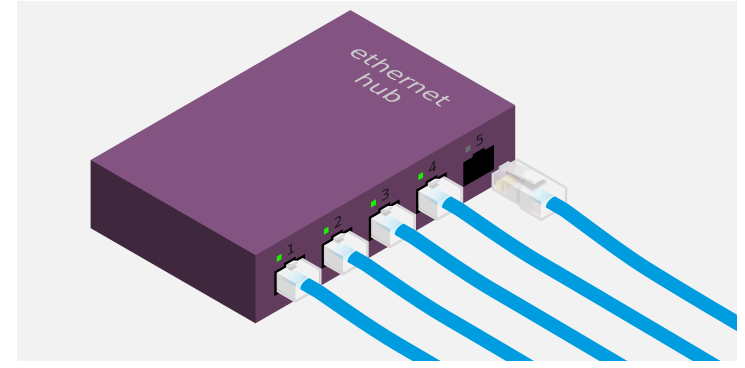
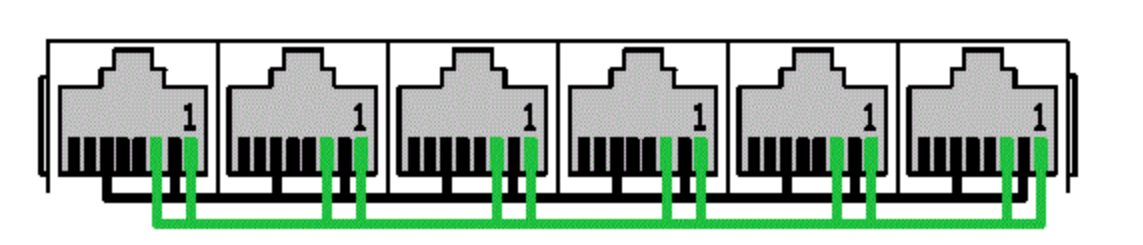
集线器内部构造很简单,可以理解成只是把所有网线连接起来而已.换句话讲,集线器充当了 共用导线 的功能. 这样一来,从某个端口发送出去的电信号,将被传送到所有其他端口
换句话讲,从一台主机发送出来的数据,将被传送到所有其他主机上. 以 A 往 B 发送数据为例:
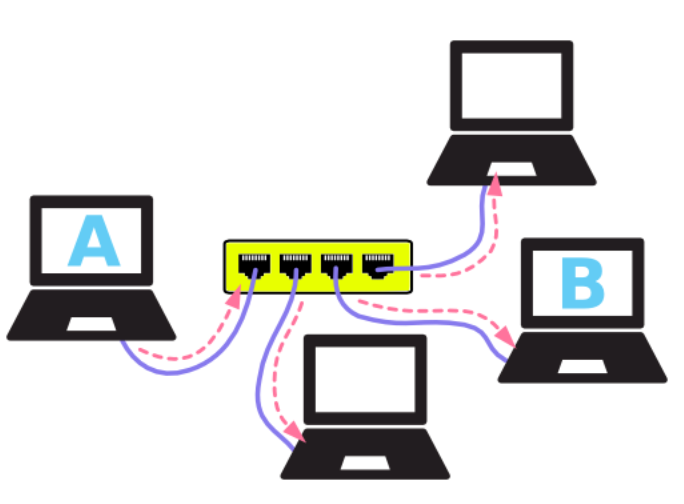
看起来就像 A 发起了 广播 ,其他所有主机都可以收到这个数据. 由于数据帧中包含 目的地址 ,最终只有 B 接收并处理这个数据. 因此并无大碍,至少是可以正常工作的.
尽管如此,集线器还是存在一些缺陷,主要体现在两方面:
- 所有主机(端口)共享带宽;
- 所有主机(端口)处于同一 冲突域 (一台主机发送,其他只能等待);
这两方面缺陷严重制约着集线器的传输效率,在接入端口数较多的情况下更是如此
为了解决集线器工作效率低下的尴尬,我们需要设计一种更高级的网络设备.新设备根据以太网帧的目的 MAC 地址,将它精准地转发到正确端口:
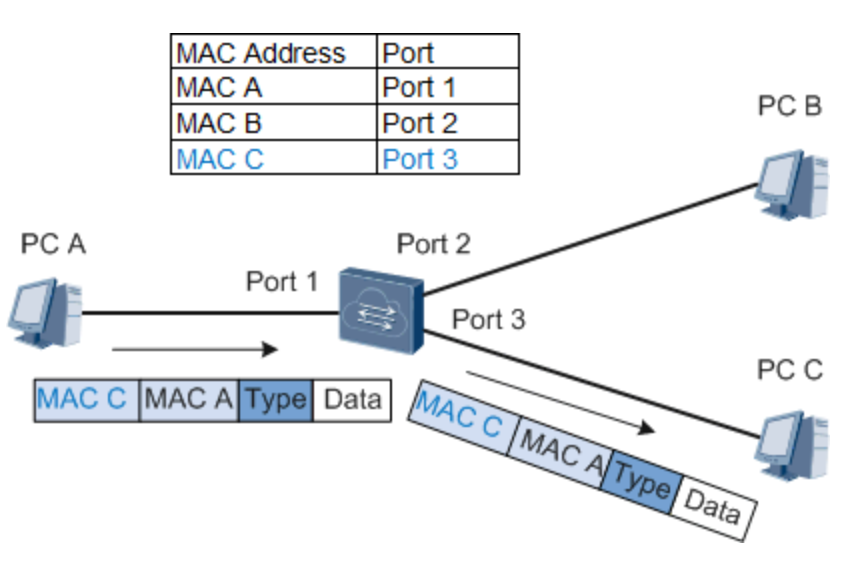
这里 端口 ( port )指的是转发设备的插口,也可叫做网口.
如上图,中间节点是转发设备,它在内部维护着一张主机 MAC 地址与对应端口的映射表,现与 3 台主机相连.这样一来, 当转发设备接到主机 A 发给主机 C 的数据后,根据目的 MAC 地址搜索映射表,便可将数据准确地转发到对应的端口 3 .
现在,传输模式变得更有针对性了. 数据帧被精准转发到正确的端口,其他端口不再收到多余的数据. 不仅如此,主机 A 与 B 通讯的同时,其他计算机也可通讯,互不干扰.转发设备每个端口是一个独立的冲突域,带宽也是独立的. 集线器的缺陷全部避免了!
能够根据以太网帧目的地址转发数据的网络设备就是 以太网交换机 ( ethernet switch ). 交换机可以完美地解决集线器的缺点,但新问题又来了,映射表如何获得呢?
最原始的方式是:维护一张静态映射表.当新设备接入,向映射表添加一条记录;当设备移除,从映射表删除对应记录.然而,纯手工操作方式多少有些烦躁. 好在计算机领域可以实现各种花样的自动化, 通过算法自动学习映射表.我们先来看看大致思路
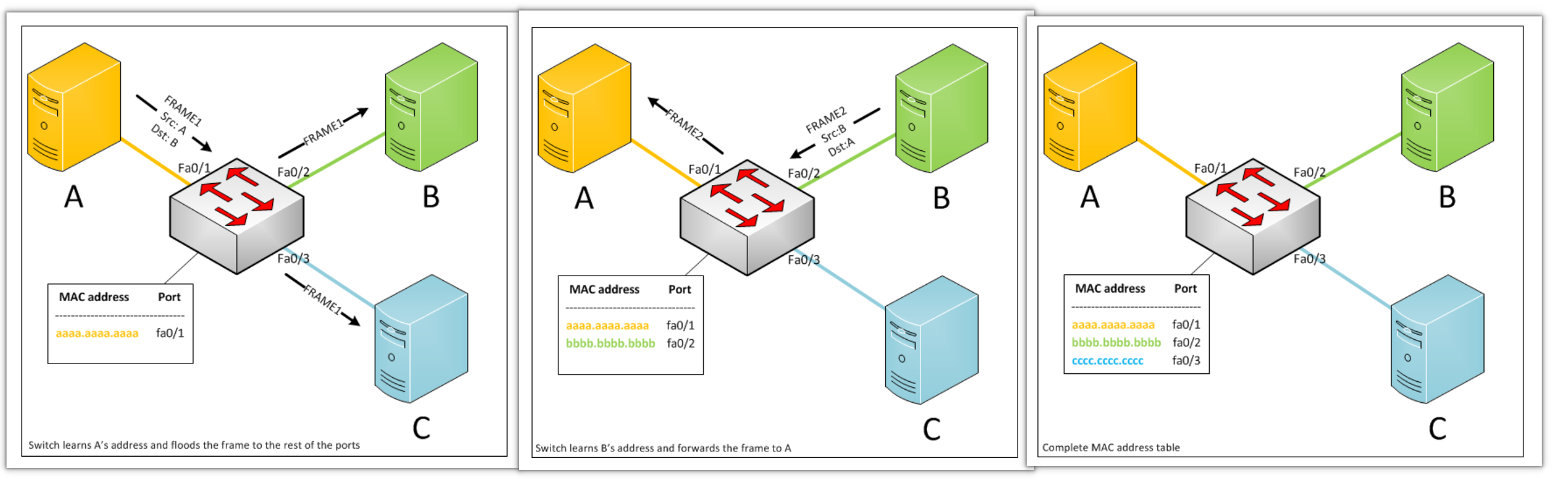
初始状态下,映射表是空的.现在,主机 A 向 B 发送一个数据帧 FRAME1 .因为映射表中没有地址 B 的记录,交换机便将数据帧广播到其他所有端口.
由于交换机是从 Fa0/1 端口收到数据帧的,便知道 A 连接 Fa0/1 端口,而数据帧的源地址就是 A 的地址!此时,交换机可以将 A 的地址和端口 Fa0/1 作为一条记录加入映射表.交换机学习到 A 的地址!
接着,主机 B 向 A 回复一个数据帧 FRAME2 .由于映射表中已经存在地址 A 的记录了,因此交换机将数据帧精准转发到端口 Fa0/1 .同理,交换机学习到主机 B 的地址 Fa0/2.
当主机 C 开始发送数据时,交换机同样学到其地址,学习过程完成!
通过以太网通信的主机,可以用 集线器 或者 交换机 连接起来.无论集线器还是交换机,端口数量都是有限的.普通交换机一般有 4 口, 8 口、 16 口或 24 口,最多也有 48 口的. 现在问题来了:当主机数量超过端口数后,该怎么办呢? 我们可以将多台以太网设备连接起来,组成更大的网络:
组建以太网一般采用什么拓扑结构?需要考虑哪些因素呢?开始讨论之前,我们先来认识一下冲突域的概念.
我们知道,集线器是一种很低级的物理层设备,本质可以理解成共用导线.因此,连接在集线器上的主机,不能同时通信.如下图,当主机①与主机③正在通信时,其他主机是无法通信的
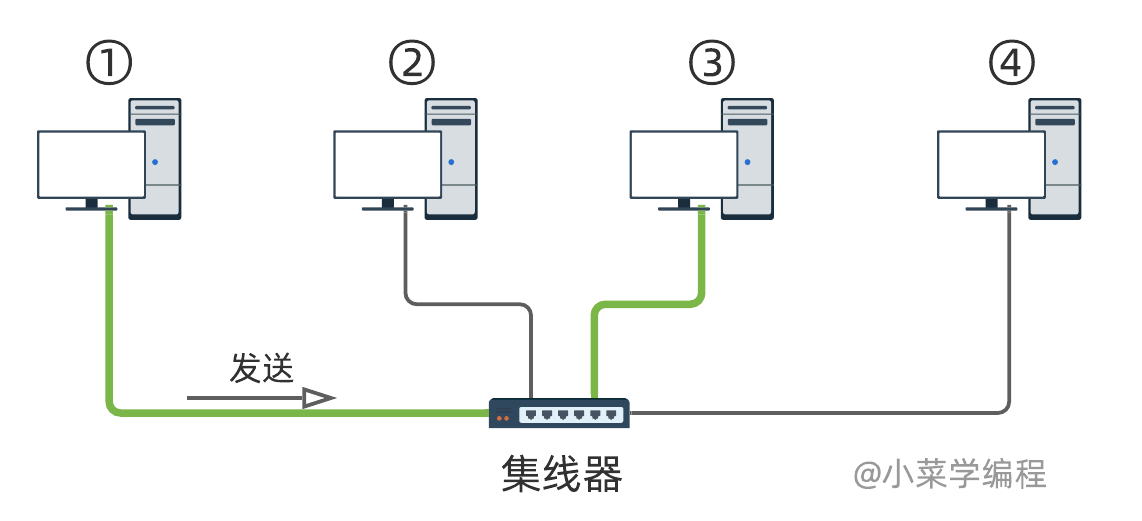
如果一个以太网区域内,多台主机由于冲突而无法同时通信,这个区域构成一个 冲突域 ( collision domain ).很显然,连接在同个集线器下的所有主机处于同一冲突域,它们的通信效率是非常低下的
交换机就不一样了,它工作在数据链路层,根据目的 MAC 地址转发以太网帧.由于交换机端口内部不会共用导线,因此不同端口可以同时通信.如下图,就算主机①和主机③正在通信,但并不影响其他端口上的主机, 交换机每个端口都是一个独立的冲突域:
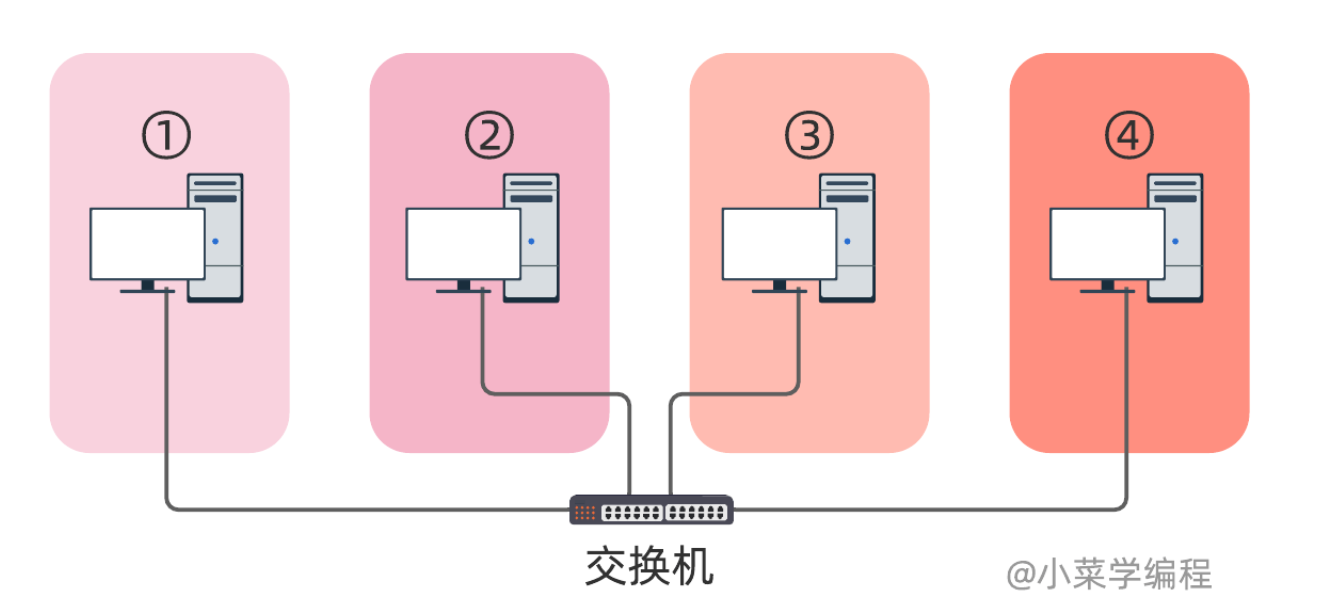
由于集线器无法隔离冲突域,因此现在已经很少用了,更不用说通过连接多个集线器来组网
级联是连接多台以太网交换机的传统方法,只需用网线将交换机端口连接起来.以两台交换机为例
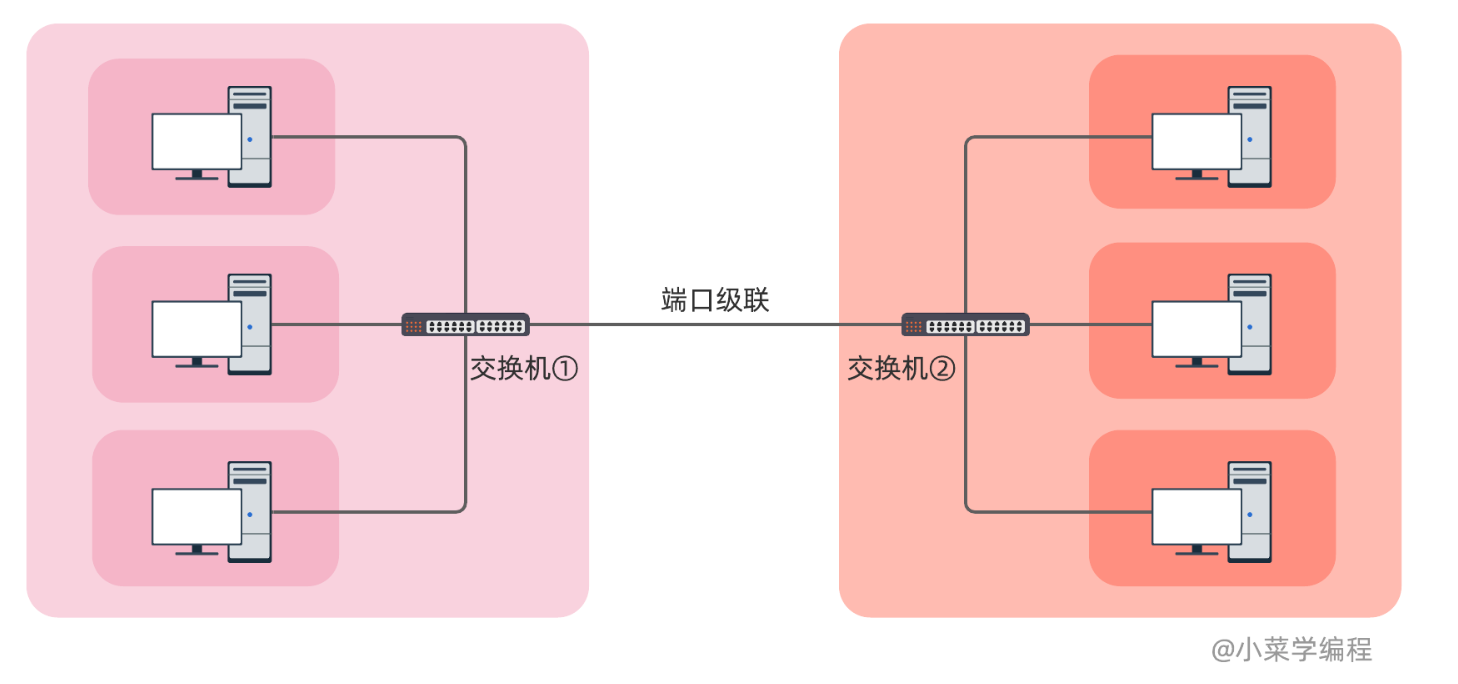
图中的两台交换机,各有一个端口通过网线连接起来.这样一来,左边主机与右边主机通信,都需要通过中间的这根网线,共享带宽.因此,在左边主机看来,右边主机都在一个冲突域内,左右两边通信效率较差. 尽管如此,同个交换机下的不同主机,冲突域是独立,因而通信效率比较高.
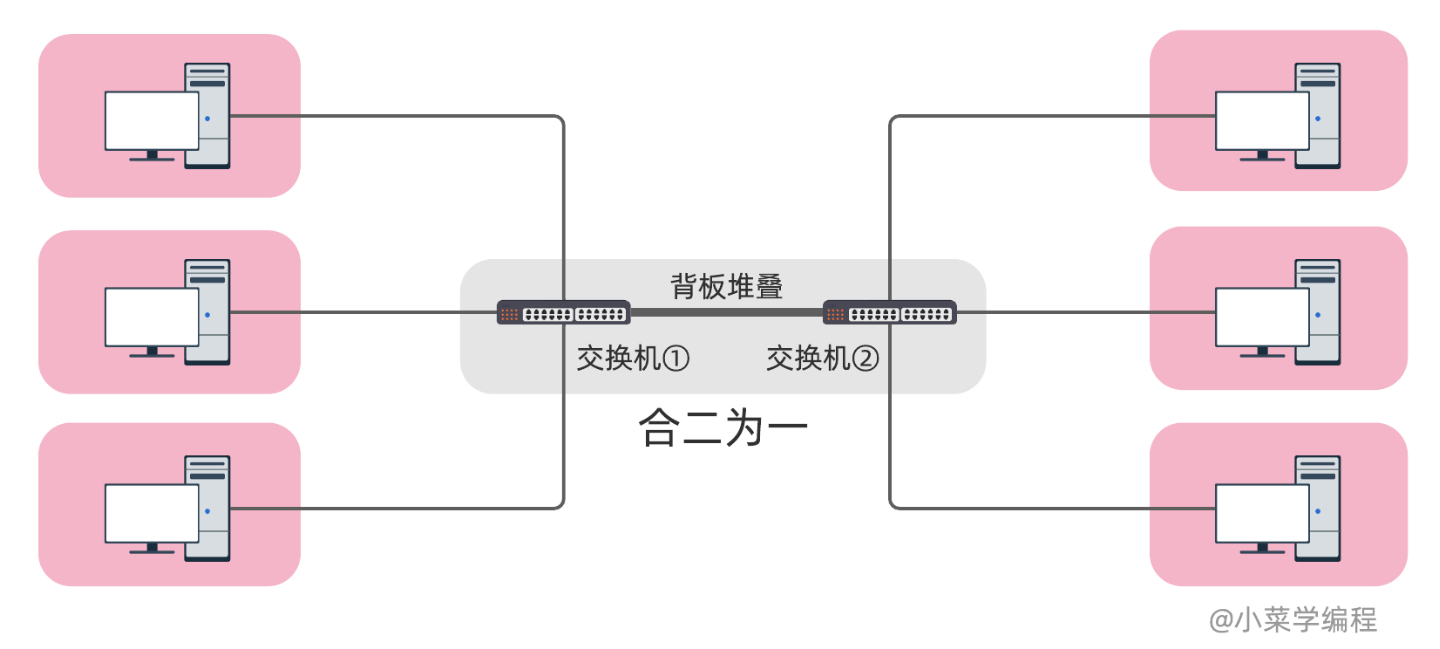
由于左右两边的主机通信都要经过中间的网线,这根小水管应该最先面临瓶颈.那么,如何提高左右两边的通信带宽呢?一根网线不够用,那就两根嘛,分别插两个端口. 有些交换机还支持堆叠,堆叠一般通过专门的堆叠口和堆叠线进行:
MTU
不同的以太网接入设备,一帧能传输的数据量是有差异的.
普通的以太网卡,一帧最多能够传输 1500 字节的数据;而某些虚拟设备,传输能力要打些折扣.此外,链路层除了以太网还有其他协议,这些协议中数据帧传输能力也有差异.
如果待发送的数据超过帧的最大承载能力,就需要先对数据进行分片,然后再通过若干个帧进行传输.
下面是一个典型例子,待发送的数据总共 4000 字节,假设以太网设备一帧最多只能承载 1500 字节.很明显,数据需要划分成 3 片,再通过 3 个帧进行发送:
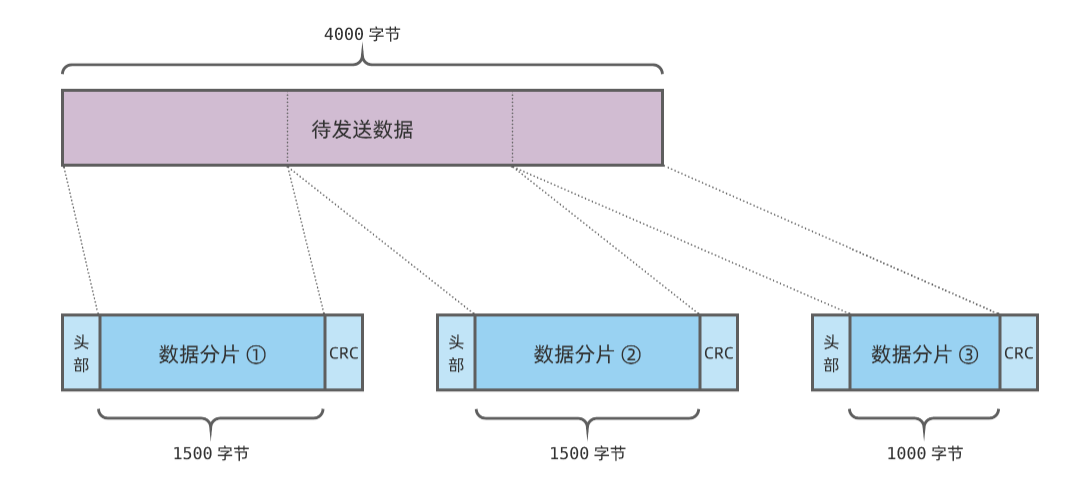
换句话讲,我们需要知道接入设备一帧最多能发送多少数据.这个参数在网络领域被称为 最大传输单元 ( maximum transmission unit ),简称 MTU .MTU 描述链路层能够传输的最大数据单元.
默认的网卡 MTU 为 1500
$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 00:15:5d:b3:89:36 brd ff:ff:ff:ff:ff:ff可以用 ip 命令,来修改 eth0 的 MTU , 以修改 eth0 网卡 MTU 为例
ip link set eth0 mtu 68不同的接入设备,支持的 MTU 范围不一样.如果我们将 MTU 设置得太小,设备将报错:
ip link set eth0 mtu 40
Error: mtu less than device minimum.40 是一个数据包的最小长度, 在 tcp 中会介绍
- 待发送以太网帧数据长度大于发送设备 MTU ,则无法发送; 如果数据量大于 MTU ,则无法通过单个以太网帧发送出去,只能以 MTU 为单位对数据进行分片,再封装成若干个帧进行发送
- 待接收以太网帧数据长度大于接收设备 MTU ,则无法接收;
MTU的值通常为1500字节,主要是出于以下几个原因:
- 标准化和互操作性:在互联网早期,1500字节被广泛采用,因为这是以太网(Ethernet)的标准帧大小.以太网是最常见的局域网(LAN)技术,将其帧大小标准化为1500字节,可以确保设备之间的兼容性和互操作性.
- 效率和平衡:1500字节的MTU值在性能和开销之间提供了一个良好的平衡.较大的帧可以减少每个数据包的开销(如帧头和尾),从而提高效率.然而,如果帧太大,数据包在传输过程中出现错误的概率也会增加,需要重新传输的代价也会更高.1500字节被认为是一个合理的折中点,既能提高传输效率,又能保持较低的错误率.
- 历史原因:以太网标准(如IEEE 802.3)最初规定的MTU值为1500字节,后来这一值被沿用并成为了其他网络技术和协议(如IP)的默认标准.随着时间的推移,这一值被广泛接受和应用,成为网络设备和操作系统的默认配置.
- 网络设备的限制:许多网络设备,如路由器和交换机,默认支持的最大MTU值为1500字节.在这样的设备上,如果数据包超过这个大小,可能会被分片(Fragmentation),增加了复杂性和潜在的延迟.因此,默认使用1500字节可以避免这些问题.
尽管1500字节是默认标准,但在某些特定应用或网络环境中,可能需要调整MTU值.例如,Jumbo Frames技术允许以太网帧的MTU值达到9000字节,用于高性能计算和数据中心环境,以进一步提高传输效率.然而,这种调整需要网络中的所有设备都支持更大的MTU值,才能避免分片问题.
网络层
数据链路层 解决了同一网络内多台主机间的通信问题,同一以太网内的主机通过以太网帧进行通信. 那么,以太网是否能够用来进行全球组网呢?
随着接入以太网的主机不断增加,交换机一定遇到瓶颈.试想,如果全世界的主机都接入,需要制造一台多大的交换机!这根本就无法实现!
级联交换机的组网技术确实可以扩展以太网络规模,但远远达不到组建全球网络的水平.制约以太网规模的主要瓶颈有两个:
- 广播风暴;
- MAC 地址表规模;
交换机转发数据帧时,如果发现目的 MAC 地址不认识,就采取广播策略.这意味着与陌生节点第一次通信时,数据帧需要广播到所有节点.这便是 广播风暴 ,网络规模越大,广播流量越恐怖.
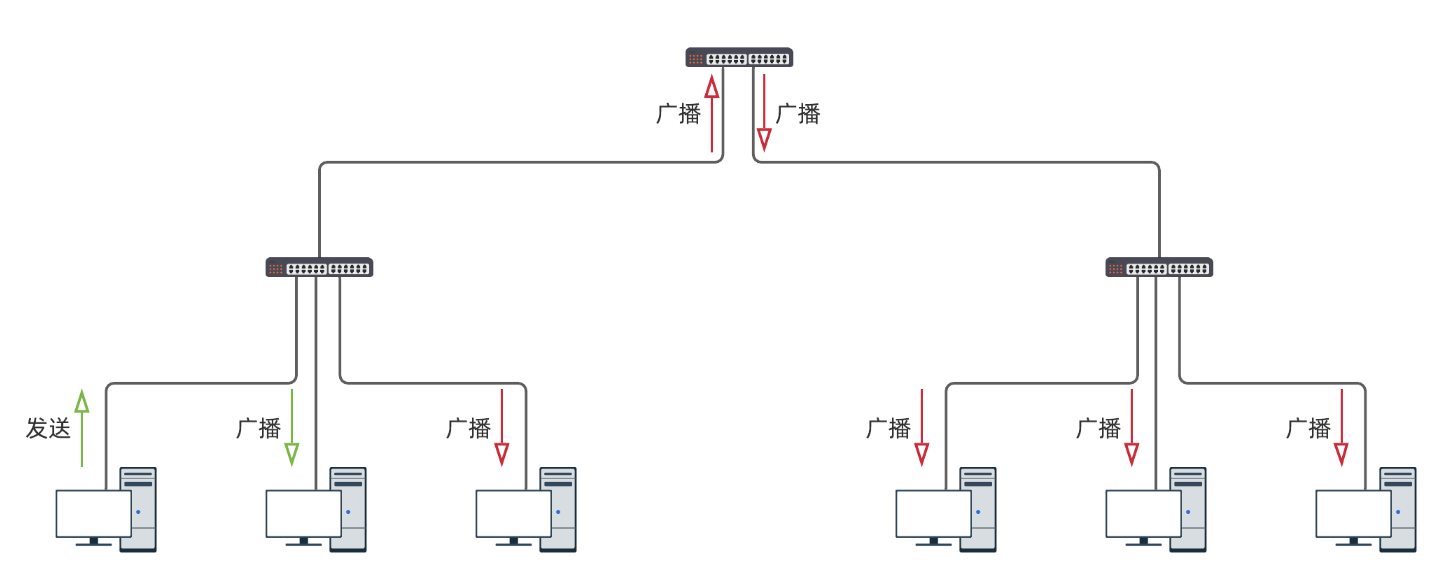
如果采用以太网进行全球组网,每台交换机都需要为所有主机都维护一条转发配置,这该消耗多少内存! 从工程角度上看,几乎没有实现的可能性.
为解决上述诸多问题,我们需要找到新的技术方案,以达到以下目标:
- 引入新寻址机制,地址按网络拓扑分配,同个网络下地址是连续的;
- 引入更高效的转发机制,杜绝广播风暴;
计算机网络协议正是一个非常庞大的体系,势必也能从分层设计思想中获益. 假设此时有两个不同的以太网, 我们可以在中间用一个特殊的转发设备连接起来
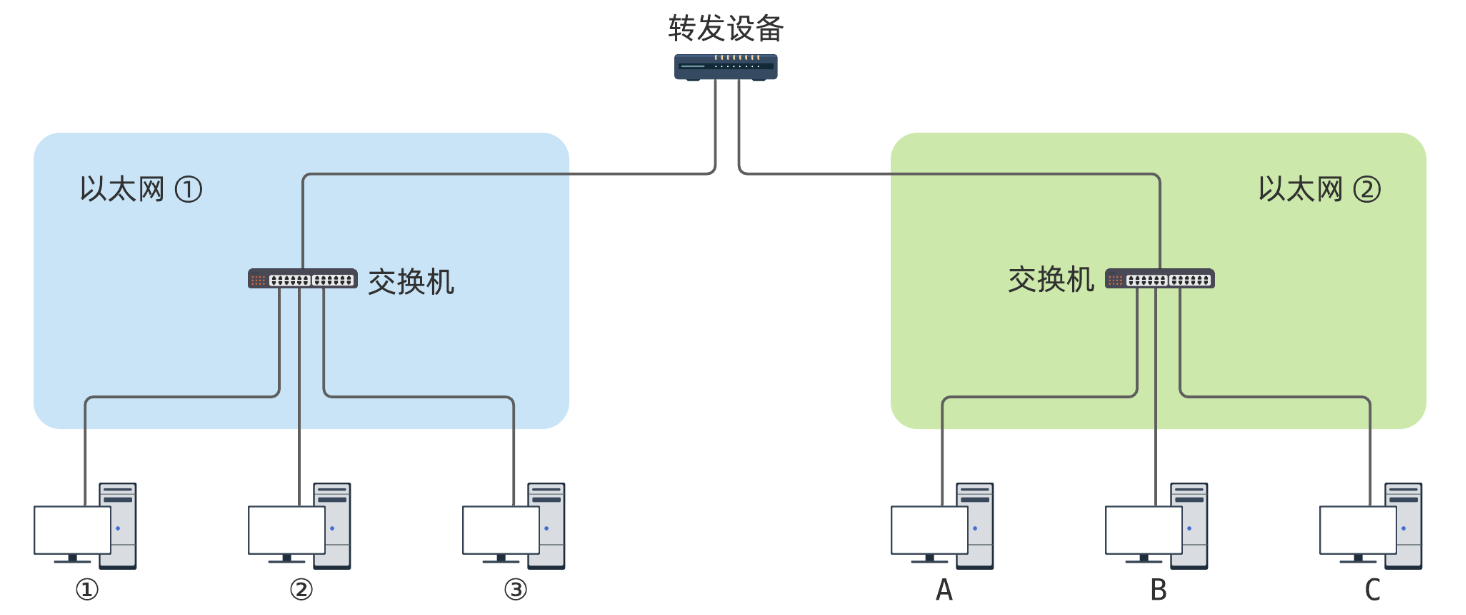
由于前面讨论的诸多局限性,我们不希望中间的转发设备 R 参与以太网帧转发.这样一来,以太网 ① 中的主机,无法直接通过以太网与以太网 ② 中的主机进行通信.图中主机通信可以分为两种不同情况:
- 以太网内通信,例如 ① 与 ② ,又如 A 与 B,亦如 ① 与转发设备;
- 以太网间通信,例如 ① 与 A;
网内通信,数据链路层中的以太网协议就能很好胜任,但跨网通信又该如何实现呢?
之前的网内通信我们使用的是 MAC 地址, 由交换机维护路由表, 确定应该向哪一个端口发送数据, 这是数据链路层的网络通信.
主机 ① 与转发设备是可以直接通信的;转发设备与主机 A 也是可以直接通信的.因此,我们只需在数据链路层之上,设计新的 网络层 ,专注于跨网通讯.跨网通信可以分解成若干次网内通信,而网内通信直接复用数据链路层能力即可!
因此可以在数据链路层的 MAC 地址基础上设计新的通信地址, 我们为每台参与网络层通信的主机分配一个唯一的地址, 称为网络层地址; 在网络层转发数据的中间节点,称为 网络层路由
网络层传输单元称为 包 ( packet ),结构可参考数据链路层,包含 地址 、数据 以及 类型 等字段.网络层包承载在数据链路层帧之上,也就是说数据链路层帧的 数据负载 就是一个网络层包.
网络层路由维护路由表 ,规定了目的地址与下一跳的对应关系.路由表看起来与数据链路层 MAC地址表 颇为相似,但更加高级:
- 支持 地址段 ,一条记录配置某一段地址的下一跳,有效降低路由表规模;
- 支持 高级学习算法 ,例如选择一条跳数最少的路径;
路由原理
单个以太网的规模是非常有限的,但我们可以用网络层设备 路由器 ,将多个以太网组织成更大的网络.大网络内的所有主机,都可以通过网络层协议: IP协议 ,进行通信.
为了彻底理解网络层、IP协议以及路由器的工作原理,我们构建一个极简网络拓扑,深入研究
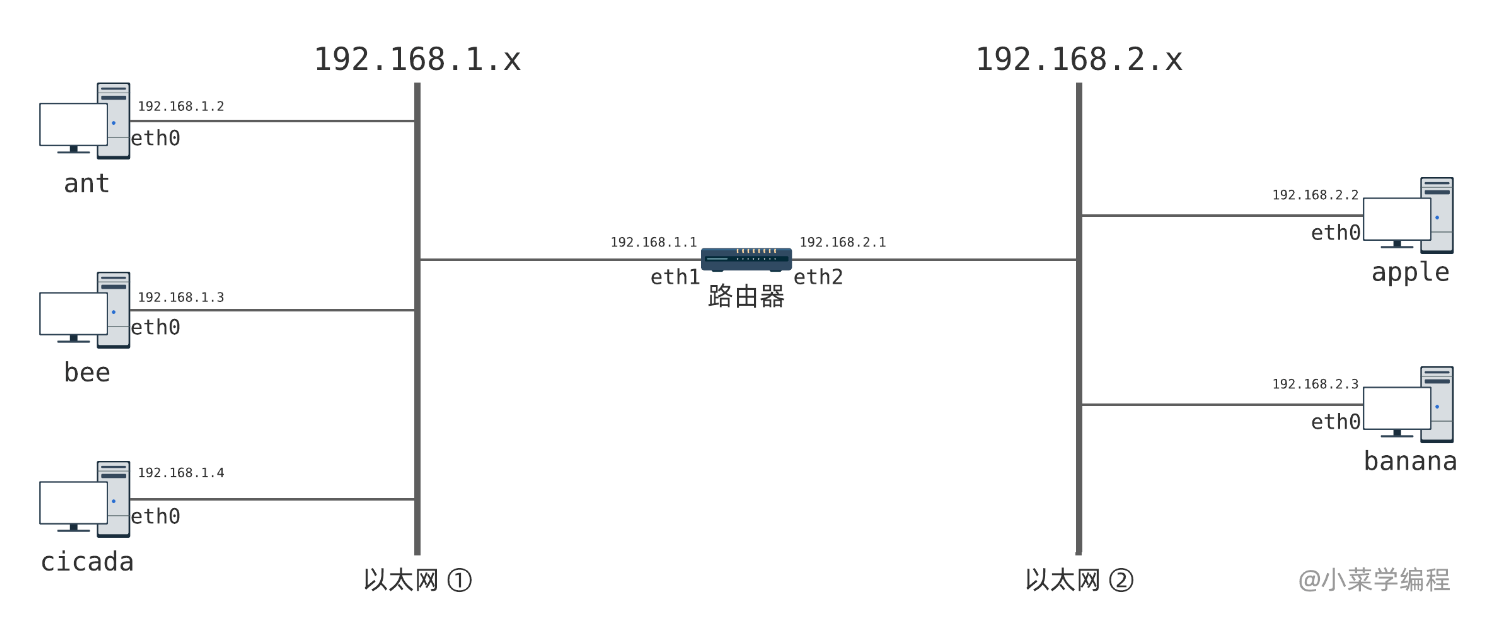
图中没有画出交换机, 但实际上主机是先和交换机相连, 然后交换机再和路由器相连, 只不过交换机并不是一个通信实体, 它只用来维护内部的路由表实现转发, 所以图中省略
图中有两个以太网络,分别是以太网①和以太网②.以太网①中有三台主机,分别是 ant 、bee 和 cicada ;以太网②中有两台主机,apple 和 banana ;中间的路由器,同时接入这两个以太网. 我们为每一个以太网内部的主机分配相似的地址, 这种做法可以利用子网掩码有效降低路由表规模
下文子网掩码中会再次提到
我们给以太网①中的通信实体,分配一个 192.168.1.x 段的 IP 地址:
| 通信实体 | 网卡 | MAC地址 | IP |
|---|---|---|---|
| 路由器 | eth1 | MAC-X | 192.168.1.1 |
| ant | eth0 | MAC-ant | 192.168.1.2 |
| bee | eth0 | MAC-bee | 192.168.1.3 |
| cicada | eth0 | MAC-cicada | 192.168.1.4 |
同样,给以太网②中的通信实体,分配一个 192.168.2.x 段的IP地址:
| 通信实体 | 网卡 | MAC地址 | IP |
|---|---|---|---|
| 路由器 | eth2 | MAC-Y | 192.168.2.1 |
| apple | eth0 | MAC-apple | 192.168.2.2 |
| banana | eth0 | MAC-banana | 192.168.2.3 |
注意, 路由器对于不同以太网使用不同的网卡, 具有不同的 MAC 地址
每个通信实体还需要配置路由表, 路由表决定一个通信实体对于不同的 IP 地址向哪里发送数据, 我们以 ant 的路由表为例, 可以使用 route -n 查看
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
192.168.2.0 192.168.1.1 255.255.255.0 UG 0 0 0 eth0route 命令输出两条路由规则,每条占一行,分别有目的地、网关、子网掩码、标志位以及出口设备等好几列.其中,目的地结合子网掩码确定目的网段,例如 192.168.1.0/255.255.255.0 表示 192.168.1.x 这个网段.
第一条路由记录的意思是,去往 192.168.1.x 网段的 IP 包,都可以通过 eth0 直接发送出去.网关 0.0.0.0 表示 IP 包无须通过任何路由中介进行转发,也就是说 192.168.1.x 网段是一个本地网段,可以直接通信.
第二条路由记录的意思是,去往 192.168.2.x 网段的 IP 包,需要先发给 192.168.1.1 ,由它负责转发;而网关 192.168.1.1 可以通过 eth0 网卡直接通信.
很显然,主机 ant 上的这两条路由,特征显著不同:
- 第一条属于 直接路由 ,目的网段是本地网,可以通过网卡直接发送出去,属于 本地网通信 场景;
- 第二条属于 间接路由 ,目的网段是其他网络,需要通过路由转发,属于 网际通信 场景;
对于本地网, 网关为空,即0.0.0.0;标志位不带G
对于其他网络, 网关非空;标志位带G
本地网通信
对于接入同一个以太网络的两台主机, 比如下图的 1 和 3,它们的 IP 地址也在同一段,这样与主机直接连接的网络称为 本地网 .同一网络内的主机可以直接通信,无须借助第三方
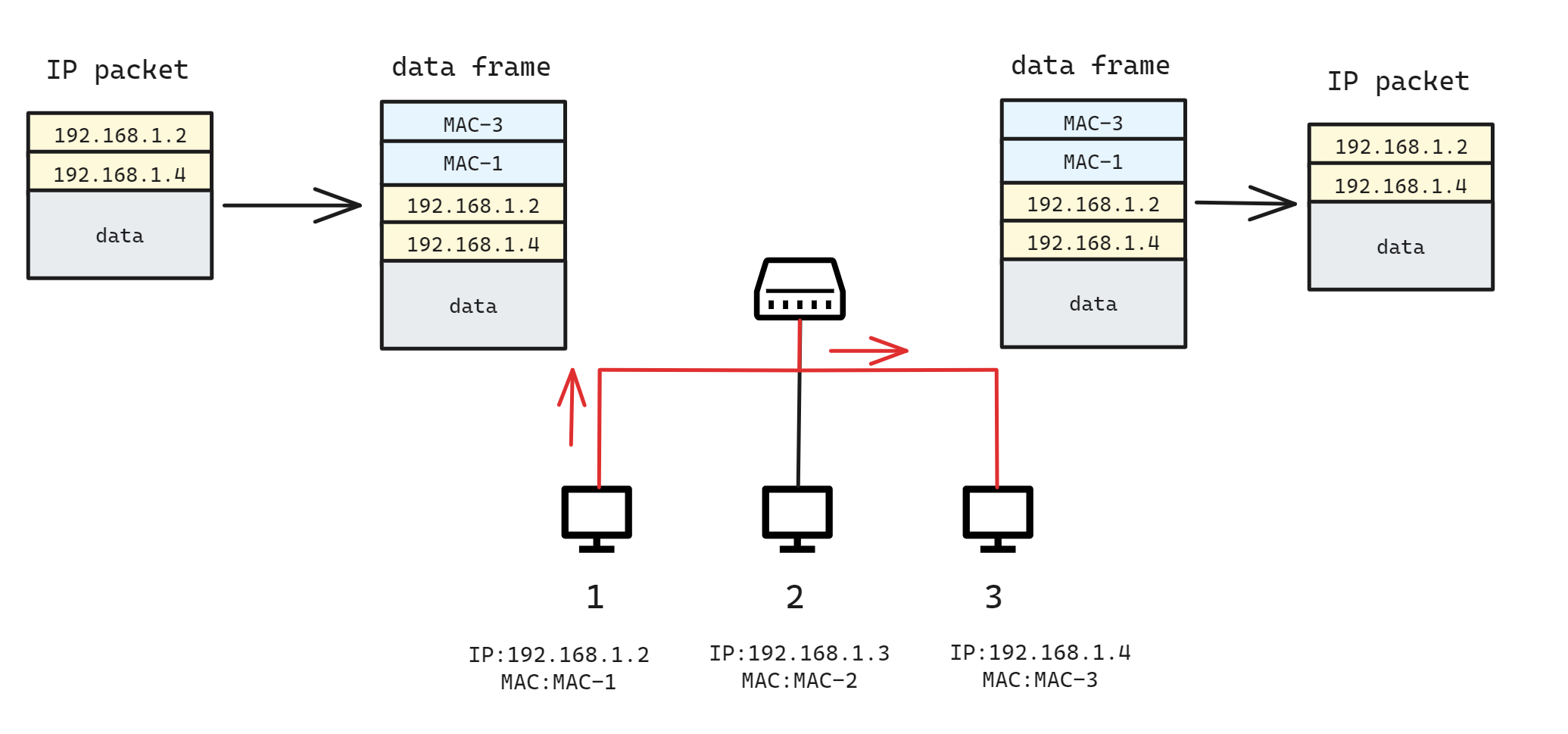
假设主机 1 通过 IP 协议向主机 3 发送数据,数据封装成 IP 包,其中:
- 源地址 是 1 的 IP 地址,即:
192.168.1.2
- 目的地址 是 3 的 IP 地址,即:
192.168.1.4
IP 包封装好后,主机查询路由表:去往 192.168.1.x 网段的 IP 包,可以直接从 eth0 网卡发出去.这表明:目标网络就是 eth0 网卡接入的本地网络,该 IP 包可以通过以太网帧直接发给目标主机.
每一个主机(通信实体)内部都有自己的路由表, 并不是查询路由器的路由表
接着,主机将 IP 包封装到以太网帧(frame)中,从 eth0 网卡发送出去,其中:
- 源地址 是 1 主机 eth0 网卡的 MAC 地址,即: MAC-1
- 目的地址 是 3 主机 eth0 网卡的 MAC 地址, MAC-3
那么,主机 1 怎么知道 192.168.1.4 这台主机 3 的 MAC 地址呢?实际上,主机 1 内部需要维护一张 MAC 地址的映射表,记录本地网主机 IP 到 MAC 地址的映射关系
| IP | MAC地址 | 备注 |
|---|---|---|
| 192.168.1.1 | MAC-X | 路由器 |
| 192.168.1.3 | MAC-2 | 2 |
| 192.168.1.4 | MAC-3 | 3 |
至于这个映射表是如何获得的,谜底将在 ARP 协议一章揭晓
网际通信
网内通信只需要主机和交换机就可以了, 但是对于 IP 地址也不在同一段的通信就需要借助 路由器 来实现了, 称为网际通信
以下面的拓扑为例,假设主机 ① (192.168.1.2)通过网络层包向主机 A (192.168.2.2)发送数据 hello ,步骤大致如下:
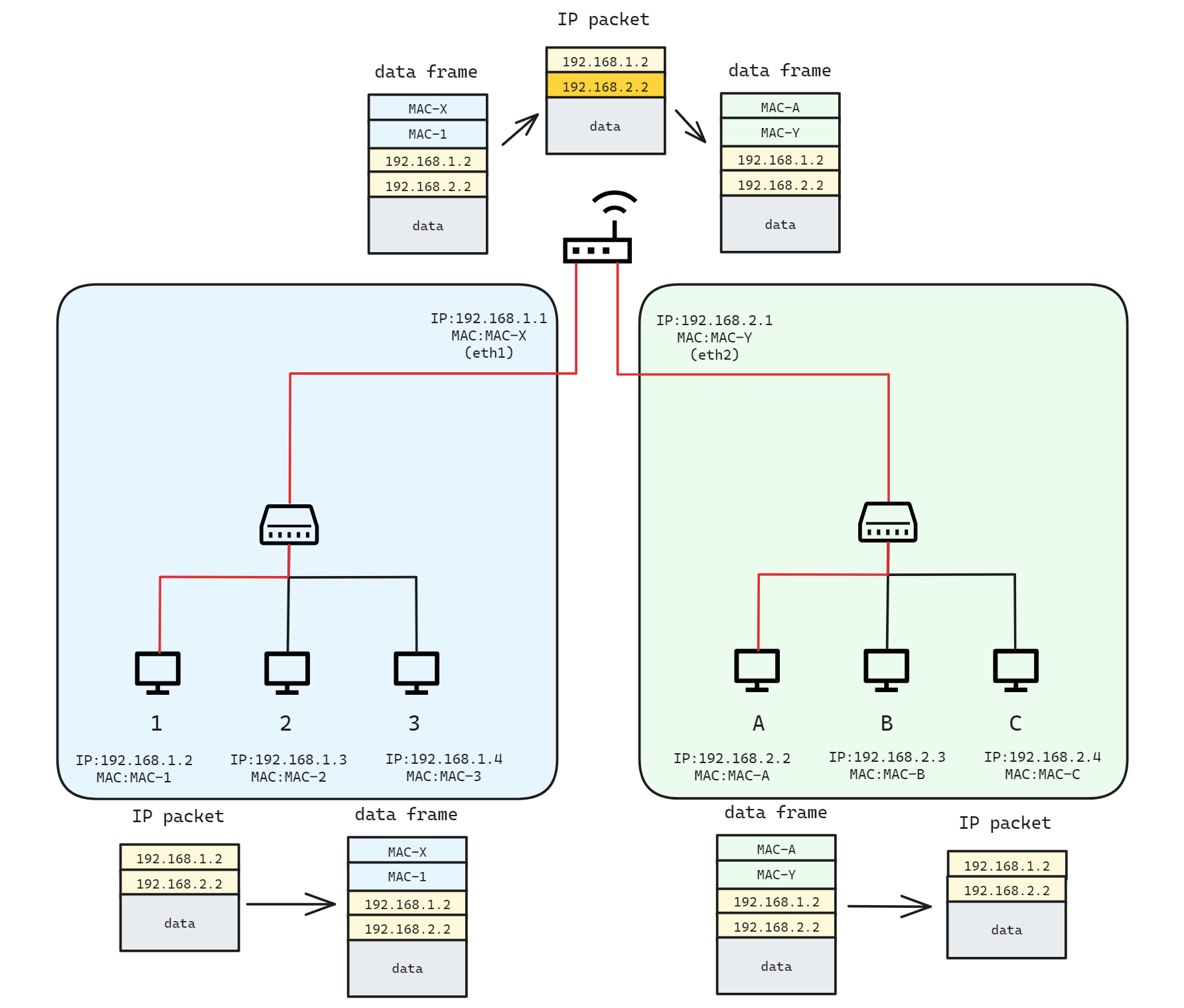
- 主机 ① 将数据封装到一个网络包中,包源地址是主机 ① 的网络层地址(192.168.1.2),目的地址是主机 A 的网络层地址(192.168.2.2);
- IP 包封装好后,主机查询路由表:
$ route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0 192.168.2.0 192.168.1.1 255.255.255.0 UG 0 0 0 eth0去往 192.168.2.x 网段的 IP 包,需要先发给路由器 192.168.1.1 ,由它负责转发.由于路由器 192.168.1.1 位于本地网,主机可以将 IP 包搭载在以太网帧中,通过 eth0 网卡发给它.
- 主机 ① 可以通过链路层协议与路由器通信,因此只需将网络层包作为数据封装在链路层帧中发给R,帧源地址是主机 ① 的链路层地址(MAC-1),目的地址是路由器的链路层地址(MAC-X);
- 当路由器接到以太网帧后,从中取出 IP 包,发现它是发往 192.168.2.2 的.路由器同样查询路由表,发现: 192.168.2.x 是个直连的本地网络,可以通过 eth2 网卡直接通信
- 路由器从内部映射表中查到 192.168.2.2 对应的 MAC 地址,并将 IP 封装在以太网帧中从 eth2 网卡发出去, 帧源地址是路由器的链路层地址(MAC-Y),目的地址是主机 A 的链路层地址(MAC-A);
- 主机 A 收到该帧,从中取出网络包,检查包源地址知道它是主机 ① 发来的,进而取出其中的数据;
IP 地址
IP 是 互联网协议 ( internet protocol ) 的简称,是 TCP/IP 协议栈中的网络层协议.IP 协议在发展的过程中,衍生出 IPv4 和 IPv6 两个不同版本.其中,历史版本 IPv4 目前仍广泛使用;后继版本 IPv6 世界各地正在积极部署.
IP 协议的通信单元是 IP 包 ( packet ),同样分为 IPv4 和 IPv6 两个版本, 一个 IPv4 包的结构如下图所示
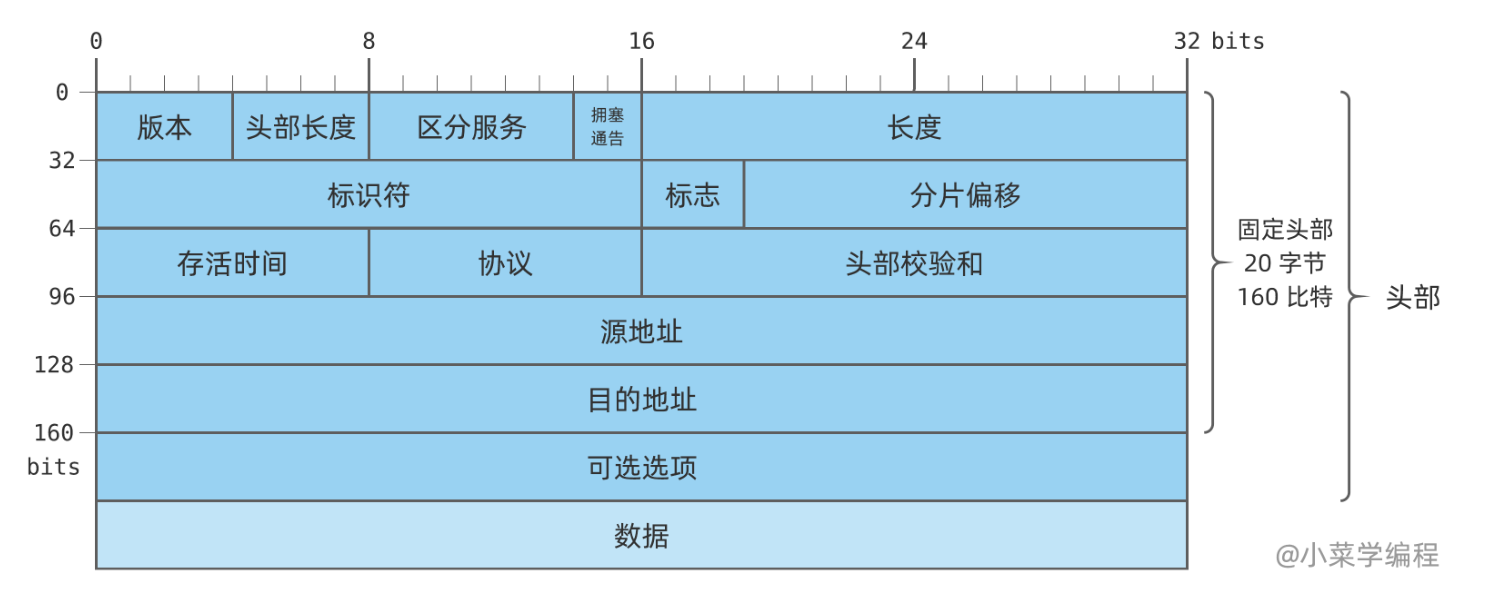
IP 包也分为 头部 ( header ) 和 数据 ( data )两大部分
- 版本: 头部第一个字段是 版本 ( version ),它占用 4 个比特,位于 IP 包的最前面,也就是第一个字节的高 4 位.采用 IP 协议通信的双方,使用的版本必须一致.对于 IPv4 ,该字段的值必须是 4 .
- 头部长度: 由于 IP 头部可能包含数量不一的 可选选项 ,因此需要一个字段来记录头部大小,进而确定数据的偏移量,这就是 头部长度. 占用 4 个比特,它用来说明头部由多少个 32 位字组成. IP 头部的最大长度为 4*15=60 字节, 最小为 20 字节
- 区分服务: 区分服务 ( differentiated services ,DS )占 6 比特,一般情况下不使用.只有使用区分服务时,这个字段才起作用,例如:需要实时数据流的 VoIP .
- 显式拥塞通告: 显式拥塞通告( explicit congestion notification ,ECN ),允许在不丢包的同时通知对方网络拥塞的发生.
- 全长: 全长 ( total length )字段占 16 位,它定义了 IP 包的总长度,包括头部和数据,单位为字节.这个字段最大值是 65525,因此理论上最大的 IP 可以达到 65535 字节.
当 IP 包长度大于下层数据链路协议 MTU 时,IP 包就必须被 分片 (拆分成多个包).
- 标识符: 标识符 ( identification )字段占 16 比特,用来唯一标识一个包的所有分片.因为 IP 包不一定都能按时到达,在重组时需要知道分片所属的 IP 包,标识符字段就是一个 IP 包的 ID .它一般由全局自增计数器生成,每发一个包,计数器就自动加一.
- 标识: 标识 ( flags )字段占 3 比特,包含几个用于控制和识别分片的标志位:
- 第 0 位,保留,必须为 0 ;
- 第 1 位,禁止分片( don't fragment ,DF ),该位为 0 才允许分片;
- 第 2 位,更多分片( more fragment ,MF ),该位为 1 表示后面还有分片,为 0 表示已经是最后一个分片;
- 分片偏移: 分片偏移 ( fragment offset )字段占 13 比特,表示一个分片相对于原始 IP 包开头的偏移量,以 8 字节为单位.
- 存活时间: 存活时间 ( time to live ,TTL )字段占 8 比特,避免 IP 包因陷入路由环路而永远存在.存活时间以秒为单位,但在具体实现中成了一个跳数计数器:IP 包每经过一个路由器,TTL 都被减一,直到 TTL 为零时则被丢弃.
- 协议: 协议 ( protocol )字段占 8 比特,表示 IP 包数据类型.通常情况下,IP 包数据承载着一个上层协议报文,常见的有下面这些:
字段值 协议名 1 ICMP 2 IGMP 6 TCP 17 UDP 89 OSPF 132 SCTP 这也是一个非常典型的 复用/分用 字段:不同的上层协议报文,都可以利用 IP 协议提供的能力,互联网主机间进行传输
- 头部校验和: 头部校验和 ( header checksum )字段占 16 比特,与以太网帧校验和字段类似,用于对报文进行查错.
注意到,该字段只对 IP 头部查错,而不关心数据部分.这是因为 IP 包数据一般用来承载上层协议报文,例如 UDP 和 TCP ,而它们的报文都有自己的校验和字段.
每一跳路由收到 IP 包后,都要重新计算头部校验和并与该字段对比,不一致则将其丢弃.路由转发 IP 包前,也要重新计算并填写该字段,因为头部中的一些字段可能发生变化, 每次转发,TTL 字段都要减一.
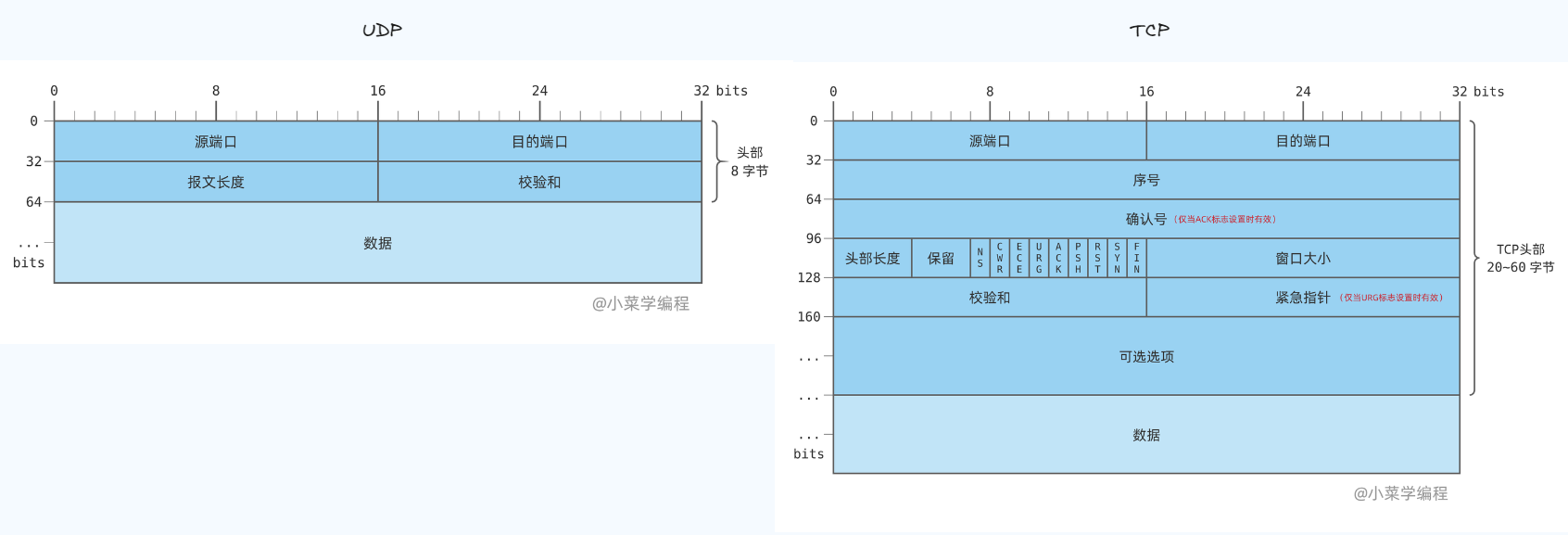
每个使用 IP 协议进行通信的实体,都需要分配一个地址,这就是我们所熟知的 IP 地址. IP 地址由 4 个字节组成,共 32 位,理论上可以表示 2^32, 即超过 42 亿台主机.这个数字虽然很大,如果为地球上每个人都分配一个,也还不够
我们可以用若干个 ASCII 数字字符来表示一个十进制数,每个数之间额外插入一个英文句点,进一步增强可读性,这就是我们常用的 点分十进制表示法
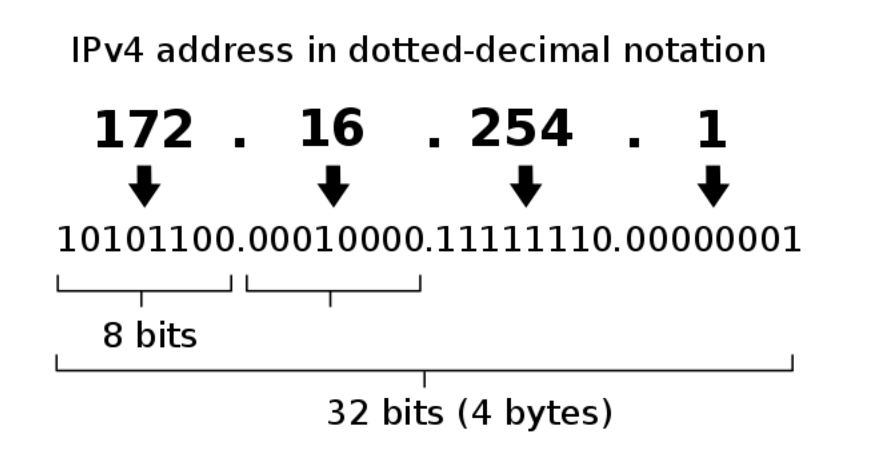
同一个网络中的主机,IP 地址都有相同的前缀, 左边网络的主机,IP 地址前缀都是 192.168.1 ;右边网络的主机,IP 地址前缀都是 192.168.2.
根据这个特性,一个 IP 地址可以分为两部分
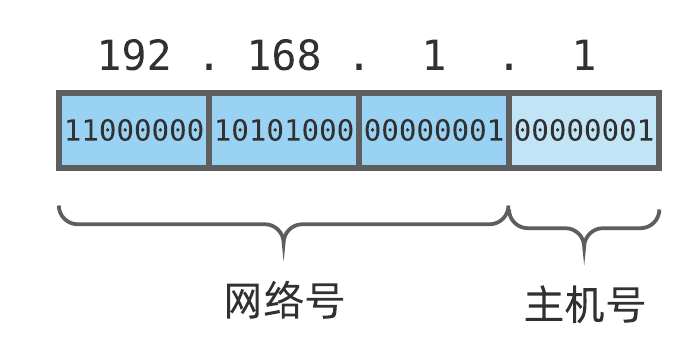
- 网络号 ,即公共前缀部分,用于表示一个网络;
- 主机号 ,即剩余部分,用于表示该网络内的一台主机;
这个例子中,IP 地址前 3 个字节( 24 位 )为网络号,最后一个字节( 8 位 )为主机号.主机号长度为 8 比特的网络,理论上可以接入 256 台主机.实际上,每个网络都有两个特殊的地址,不能分配
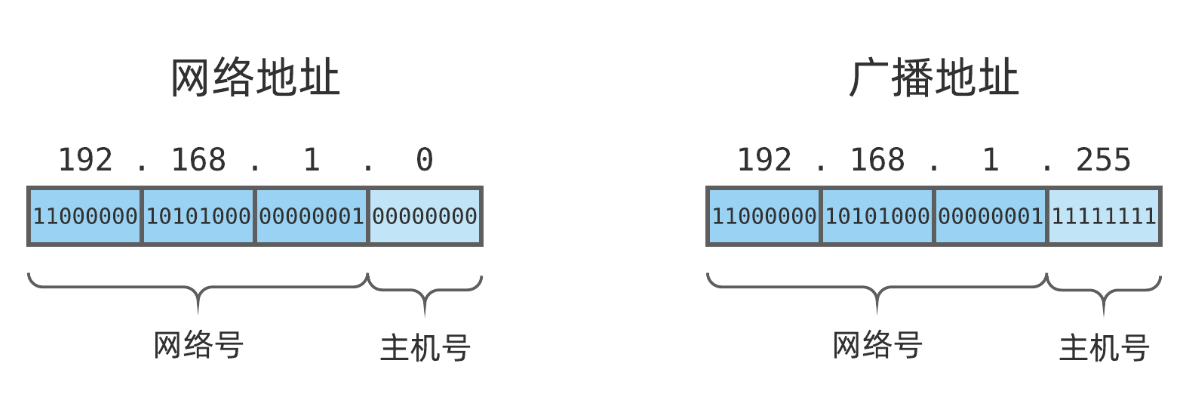
- 主机号比特全为 0 ,是网络的起始地址,用于表示网络本身,一般称为 网络地址 ;
- 主机号比特全为 1 ,是网络的结束地址,用于向网络内的所有主机进行广播,一般称为 广播地址 ;
因此,一个主机号长度为 n 比特的网络,最多可以接入 2^n - 2 台主机
那么,是不是所有的 IP 地址,网络号都是 3 字节,主机号都是 1 字节呢? 答案肯定是否定的.不同的网络,规模有大有小.因此,网络号和主机号的长度,需要根据网络规模来确定.试想,如果主机号总是 1 字节,当一个网络内的主机超过 254 台时,该怎么办呢?
在网络技术兴起的早期,科学家们将 IP 地址划分为若干类(根据 IP 地址分类确定网络号长度,是互联网初期的做法,早已不用了.尽管如此,诸如 A 类、B 类、C 类这样的术语,仍沿用至今.我们能理解其中的意思即可):
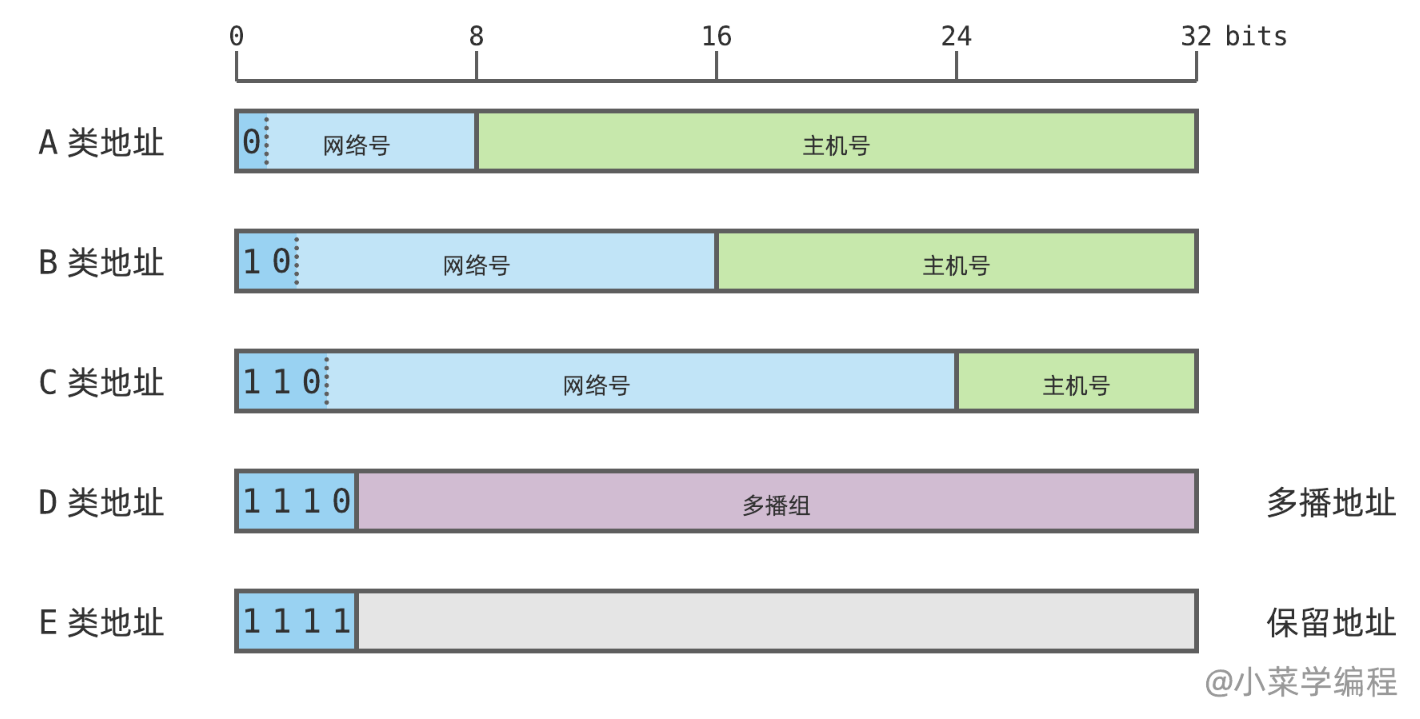
- A 类地址第一位总是为 0 ,网络号总是 1 字节,主机号总是 3 字节,一般分配给 大型网络
0.0.0.0~127.255.255.255, 每个网络支持的主机数超过 1600 万
- B 类地址前两位总是 10 ,网络号总是 2 字节,主机号总是 2 字节,一般分配给 中型网络
128.0.0.0~191.255.255.255, 每个网络支持的主机数超过 6.5 万;
- C 类地址前三位总是 110 ,网络号总是 3 字节,主机号总是 1 字节,一般分配给 小型网络
192.0.0.0~223.255.255.255每个网络支持的主机数为 254
- D 类地址前四位总是 1110 ,用于 多播通信,
24.0.0.0~239.255.255.255
- E 类地址前四位总是 1111 ,保留未用
240.0.0.0~255.255.255.255
我们常见大部分地址比如 192.168.xxx 都属于 C 类地址
还有一个比较常见的 A 类地址 127.0.0.1 代表本机地址
子网掩码
IP 地址分门别类后,除去特殊的 D 、 E 两类,只有 3 种规格,灵活性仍然非常有限:
- A 类地址,用于大型网络,网络主机数可达 1600 万以上;
- B 类地址,用于中型网络,网络主机数可达 65000 以上;
- C 类地址,用于小型网络,网络主机数只有 254 ;
主机和网络设备怎么通过 IP 地址来划分网络号和主机号呢? 我们可以用一个掩码,来记录 IP 地址中的网络号部分
掩码位数与 IP 地址一样也是 32 位,1 表示该位属于网络号,0 表示该位属于主机号.
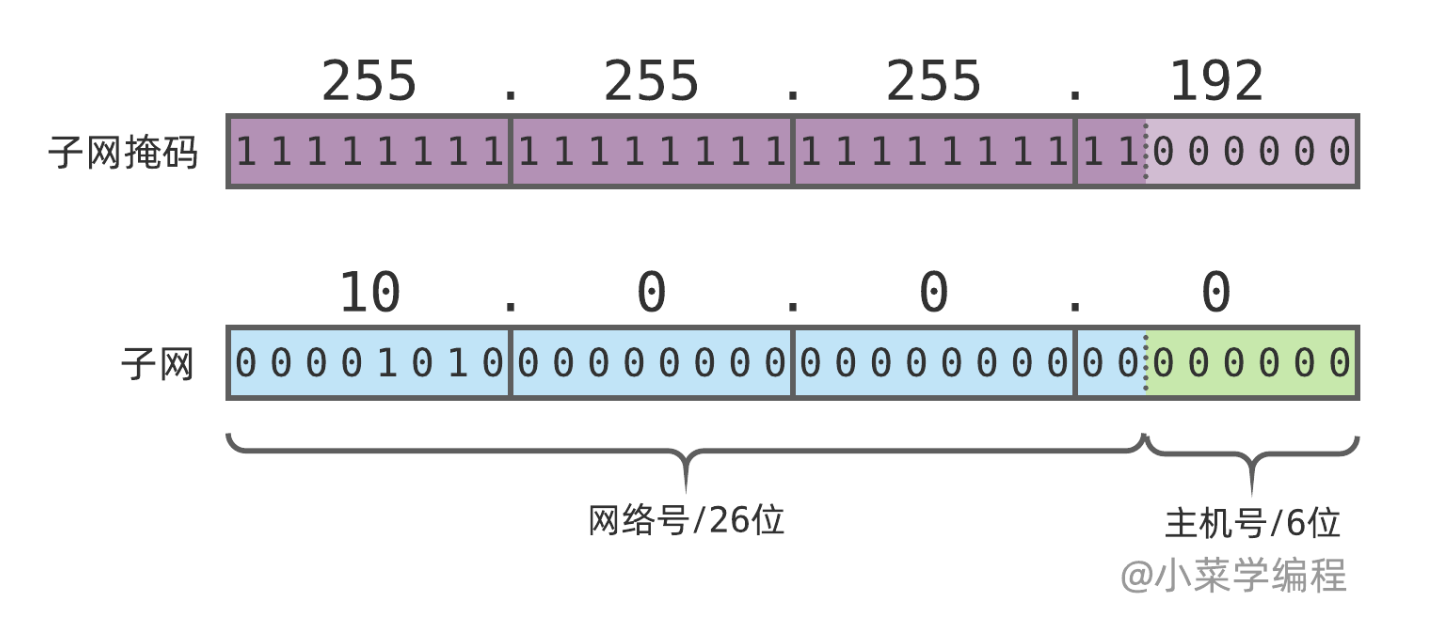
这就是所谓的 子网掩码 ,它也可以用 点分十进制表示法 来表示,用来描述 IP 地址的网络号部分.因此,子网 10.0.0.x 可以表示成 10.0.0.0/255.255.255.0 ;A 类网络 10.x.x.x 可以表示成 10.0.0.0/255.0.0.0 .
实际上,描述网络号还有更简洁的方法:在 IP 地址后面加上斜杆和网络号的位数.例如:
10.0.0.0/255.255.255.0可以表示成10.0.0.0/24;
10.0.0.0/255.0.0.0可以表示成10.0.0.0/8;
第二种表示法其实更容易理解,因此也更为常用.试想,为确定 10.0.0.0/255.255.255.192 的网络号,需要先将子网掩码换算出二进制形式,再数一下 1 的位数,未免太繁琐了, 10.0.0.0/26 则明明白白告诉我们,这个地址网络号长度为 26 位
通过子网掩码,我们既能对大型网络进行划分,也能对若干小型网络进行合并,使其组成更大的网络.
假设我们有两个 C 类网段,192.168.0.0/24 和 192.168.1.0/24 ,但我们想组建一个可以容纳 500 台主机的网络,而不是两个只能容纳 250 台主机的网络,该怎么办呢?
我们观察这两个网络,网络号的前 23 位都是一样的,只有最后一位不一样.因此,我们可以将网络号的最后一位挪出来,成为新网络主机号的一部分
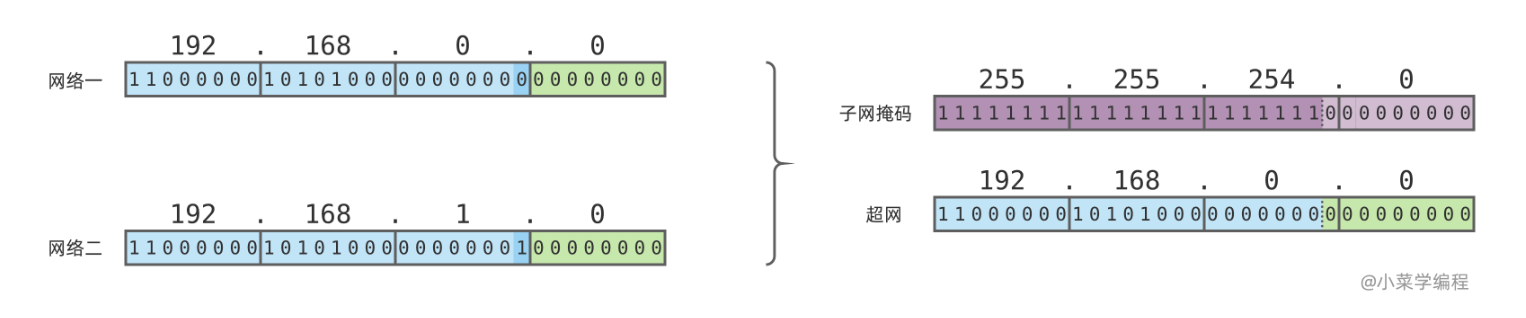
因此可以合并为 192.168.0.0/23, 新网络的网络号长度少了 1 位;共 23 位;主机号多了 1 位,共 9 位,可以容纳 510 台主机