路由
本文我们会讨论路由相关的问题,我们将会解决一个核心问题:两台都连接到互联网的机器是如何找到彼此的?
在正式开始之前我们需要创建一个简化的互联网模型,以帮助我们正式定义路由问题。如果我有很多台机器,应当以何种方式将它们互连起来呢?
一种简单的方式是使用单条链路连接所有机器,或者在每两台机器之间建立连接,它们分别被称为单链路网络拓扑和全网状网络拓扑,但是很显然这两种方式都有明显的缺点
- 单链路网络拓扑每个机器可用的带宽有限,只有一个链路,所有五台机器都需要共享这条链路上的带宽
- 全网状网络拓扑扩展性很差,每当有一台新计算机加入网络,我们就必须在它和世界上所有其他计算机之间创建新的连接。
为了创建更复杂的网络拓扑结构,我们很自然的引入了路由器的概念
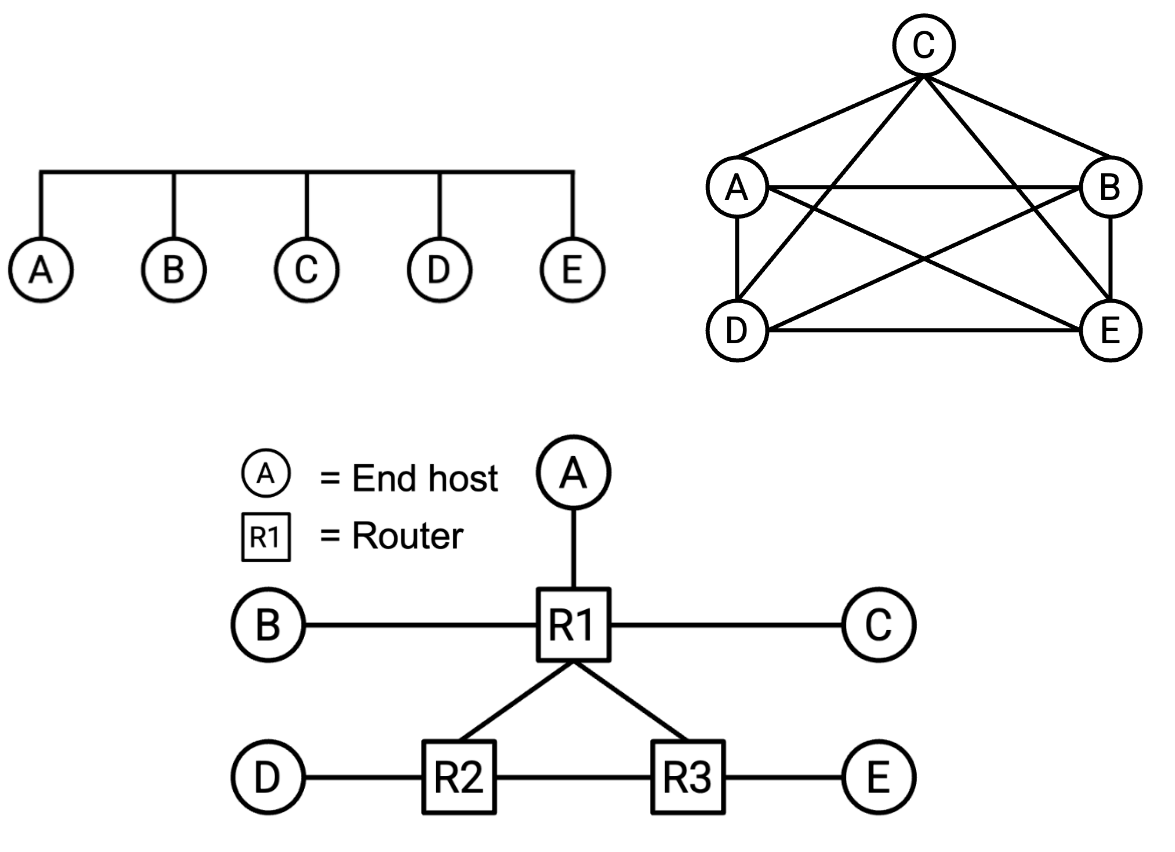
我们将每台机器归类为以下两种类型之一:主机和路由器。终端主机是指连接到互联网以发送和接收数据的计算机,路由器是连接到互联网的设备,负责接收和转发中间数据包。在你日常使用互联网时,你可能需要向谷歌服务器发送数据包来进行搜索,但你可能不需要直接向你的家用路由器或数据中心发送消息。这些路由器会帮助你将数据包转发给谷歌,但它们并不是数据包的最终目的地。
NOTE
根据网络设计,路由器可能成为合法的目的地,但本文中我们将忽略路由器作为目的地的情况。不过,需要注意的是,路由器也可能成为发件人,并发送自己的数据包。
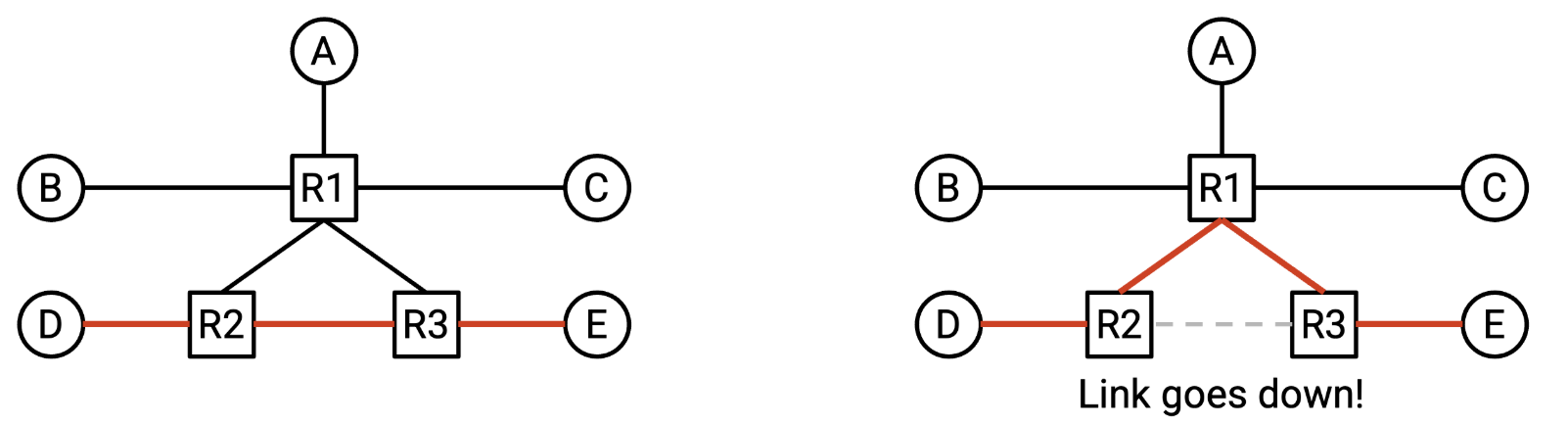
有了路由器,我们可以很自然的创建更复杂的网络拓扑结构,这种拓扑结构也更具容错性。即使某条链路发生故障,数据包也可以通过网络中的其他路径到达目的地。
什么是路由?
假设机器 A 和机器 B 都连接到互联网。机器 A 想向机器 B 发送一条消息,但这两台机器并非直接相连。机器 A 如何知道应该将消息发送到哪里,才能最终到达机器 B?消息在网络中会经过哪条路径才能到达机器 B?
设计一个好的路由协议实际上是一个相当困难的过程,因为网络拓扑结构瞬息万变。例如,链路可能会在不可预测的时间发生故障,新的主机随时可能接入/断开了网络。如果网络发生变化,我们需要及时更新图,然后计算新图中的路径来解决路由问题。
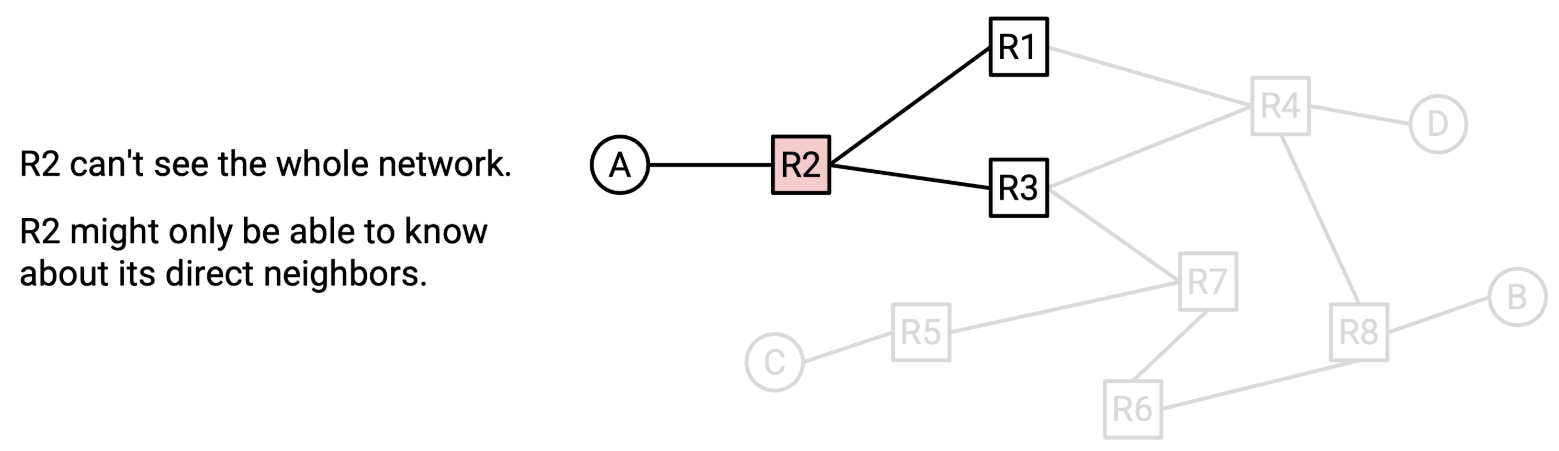
路由的另一个难点在于,路由器本身并不具备对整个网络的全局概览。例如,如果网络中某处的链路发生故障,所有路由器无法自动获知。我们需要通过路由协议,将新的网络拓扑信息传递给所有路由器。路由器R2仅能感知到和自己相连的R1/R3,这导致路由协议通常是分布式协议,需要所有路由器计算出的答案共同构成路由问题的全局答案。
域内路由和域间路由
由于互联网的规模庞大,我们不可能设计一个单一的巨型路由协议。相反,我们将利用互联网是由众多网络组成的网络这一特性。
互联网由许多本地网络构成。每个本地网络都实现了自己的路由协议,用于定义如何在该本地网络内部发送数据包。然后,我们可以将所有这些本地网络连接起来,并实现一个跨所有本地网络的路由协议,用于定义如何在不同的本地网络之间发送数据包。
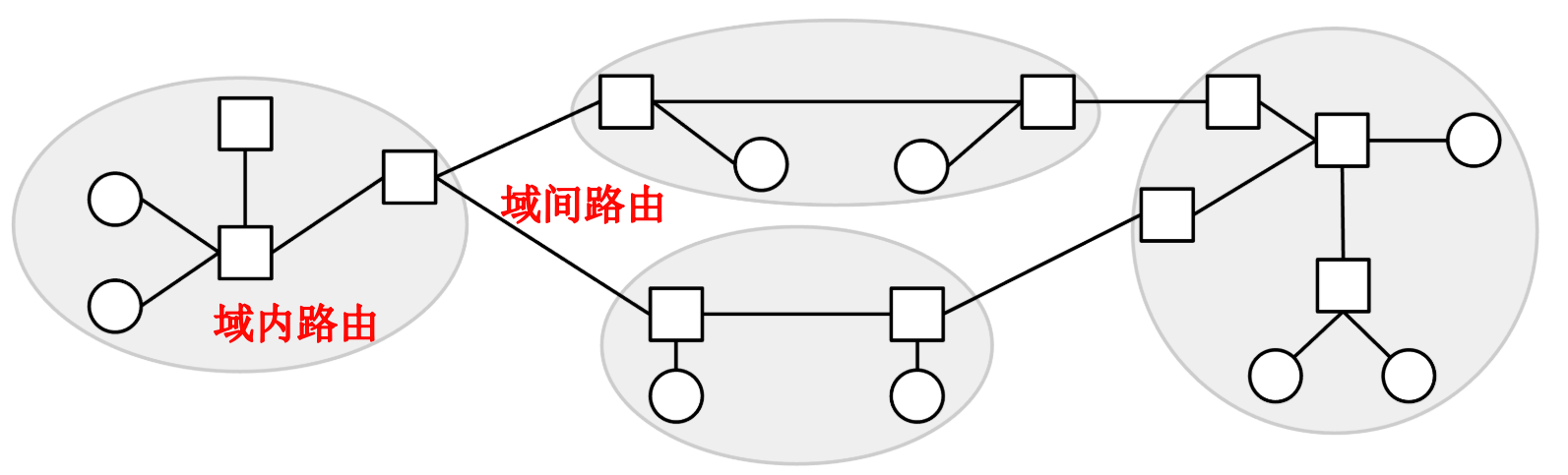
域内路由
本地网络并非完全相同。例如,它们的规模可能不同:有些网络可能拥有比其他网络更多的设备。或者,这些设备可能分布在更大的物理区域(例如整个学校校园)或更小的区域(例如您的家中)。网络在所需带宽、允许的故障率、可用支持人员数量、基础设施的年限、用于建设和维护的资金等方面也可能存在差异。
由于每个网络都有其自身的结构和需求,不同的本地网络可能会选择使用不同的路由协议。一种数据包路由策略在一个网络上可能有效,但在另一个网络上则可能无效。因此各个本地网络应当为其网络内的数据包选择路由策略。每个运营商都可以选择最适合自己的协议。
用于在本地网络内路由数据包的协议称为域内路由协议,或内部网关协议 (IGP) 。实际应用案例包括 OSPF(开放最短路径优先)和 IS-IS(中间系统到中间系统)。
稍后会详细介绍每种协议
域间路由
相比之下,用于跨不同网络路由数据包的协议被称为域间路由协议,或外部网关协议(EGP) 。为了支持跨不同本地网络发送数据包,每个网络都需要同意使用相同的协议来彼此路由数据包。如果不同的网络使用不同的域间协议,就无法保证整个互联网能够以一致的方式连接。例如,如果一个运营商只实现了协议 X,而另一个运营商只实现了协议 Y,那么这两个本地网络将如何交换消息就不得而知了。
由于每个网络都必须同意使用相同的域间协议,因此互联网上大规模实施的域间路由协议只有一种,即 BGP(边界网关协议)。
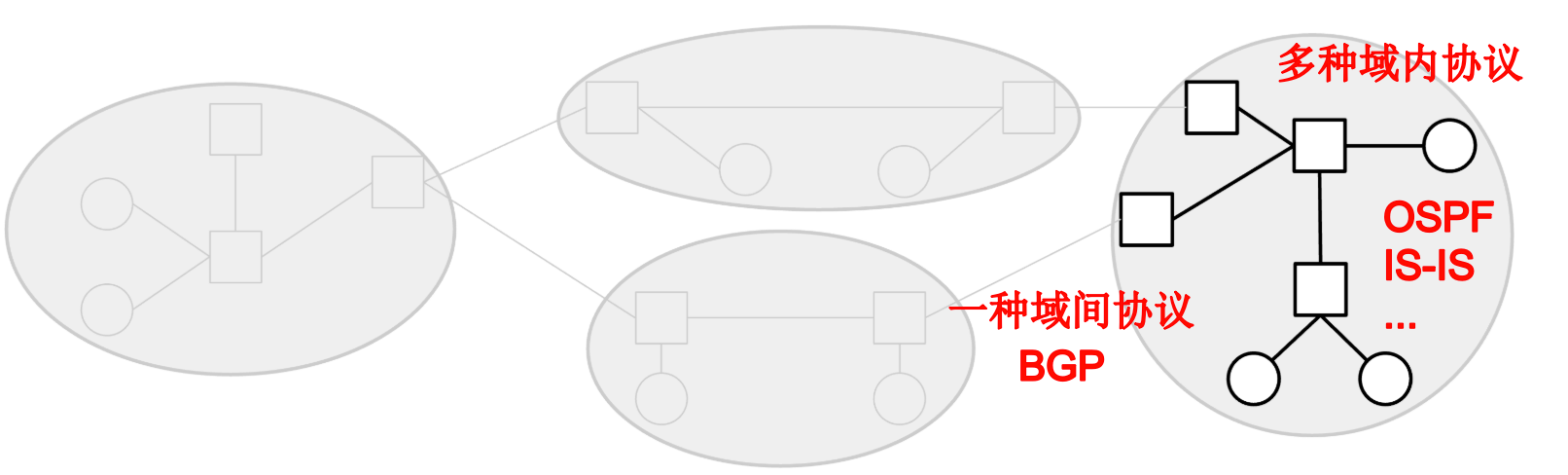
值得一提的是,域内路由和域间路由的模型便于读者理解互联网设备如何互连起来,但在实践中,二者之间的界限并不总是那么清晰。例如,BGP 除了用于不同网络之间之外,有时也会用于局域网内部。
路由表
在我们的网络模型中,每个路由器都有一定数量的出链路,将其连接到相邻的路由器和主机。换句话说,在底层图中,每个路由器节点都有一定数量的邻居节点,这些邻居节点通过一条边与该路由器相连。
当路由器收到一个数据包,其元数据中包含最终目的地信息时,路由器需要决定将数据包转发到哪个相邻的路由器或主机。数据包将被转发到的下一个中间路由器称为下一跳
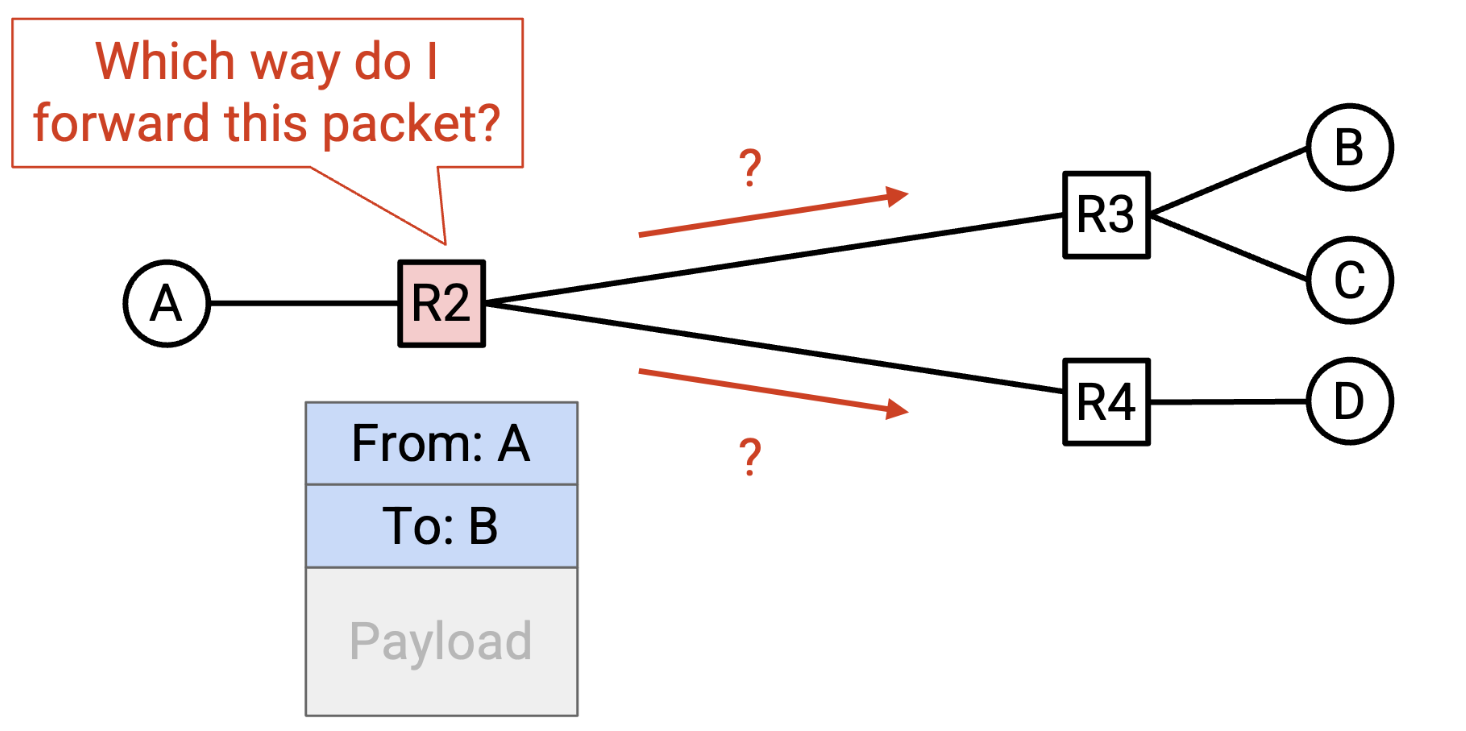
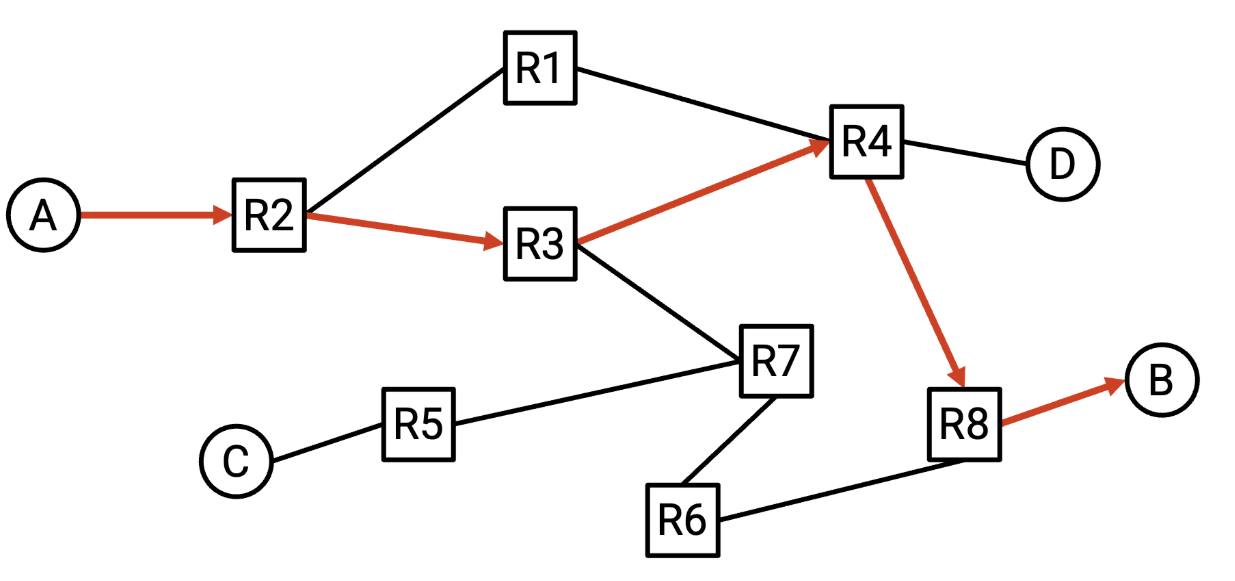
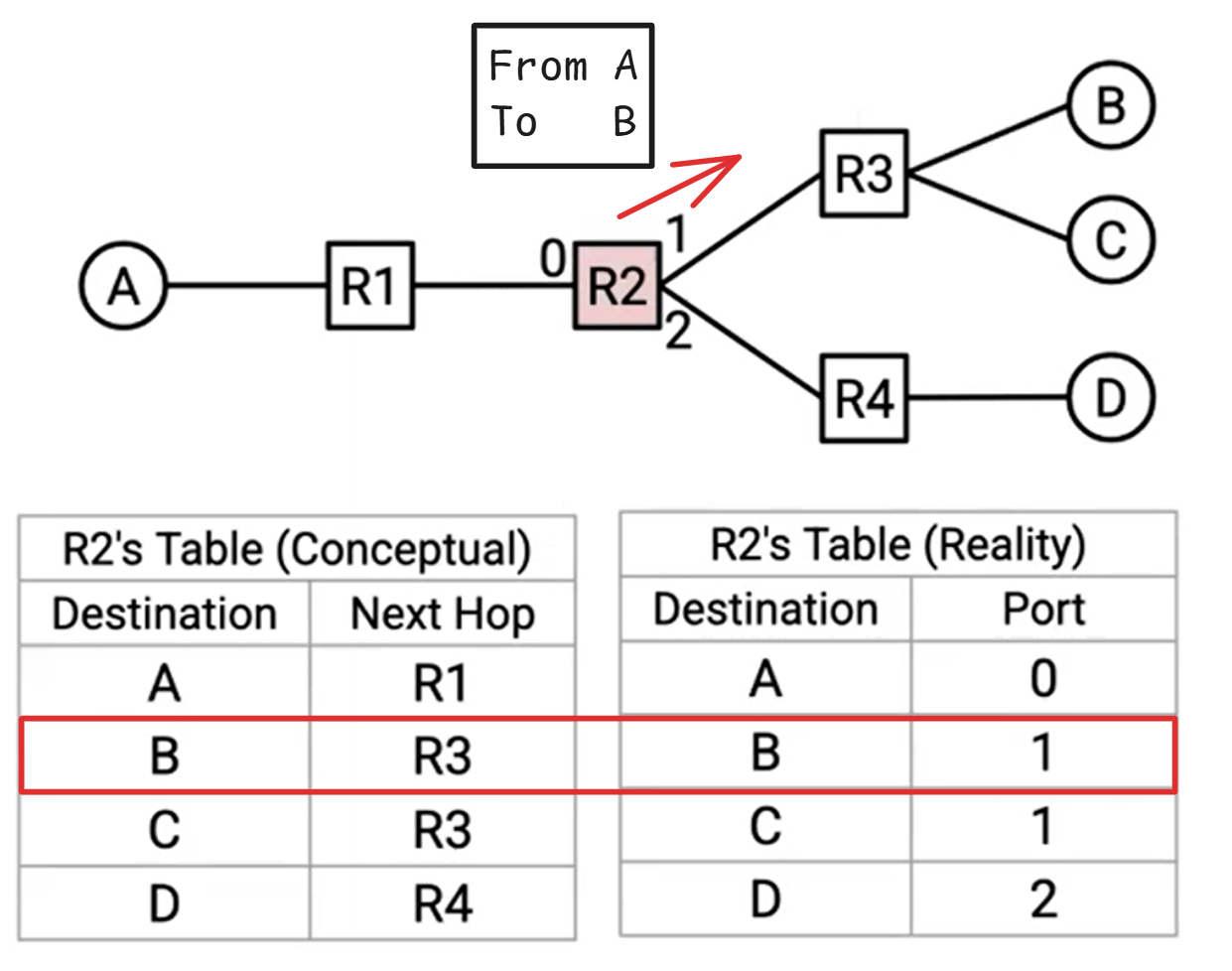
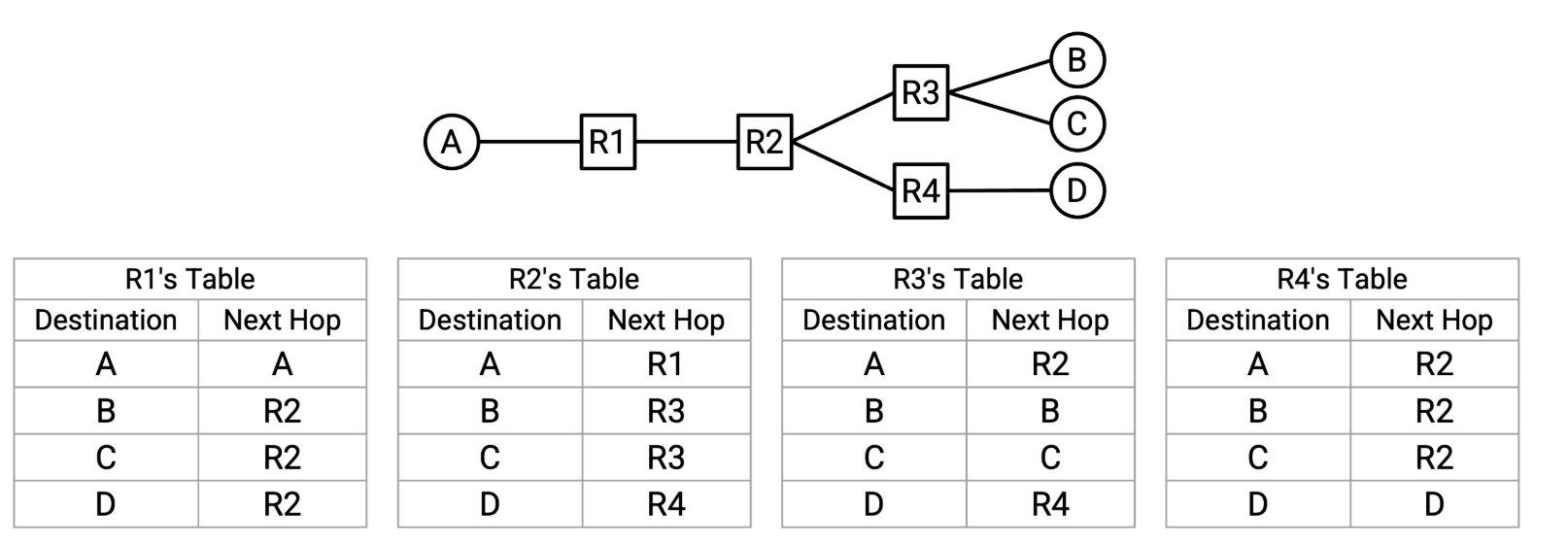
例如,考虑以下网络。如果 R2 收到一个最终目的地为 B 的数据包,那么自然的下一跳是 R3。如果 R2 收到的数据包的最终目的地是 A,那么自然的下一跳就是 R1。对于每个可能的最终目的地,我们可以写下对应的下一跳,以便将数据包转发到更靠近该目的地的位置。这个结果称为路由表。
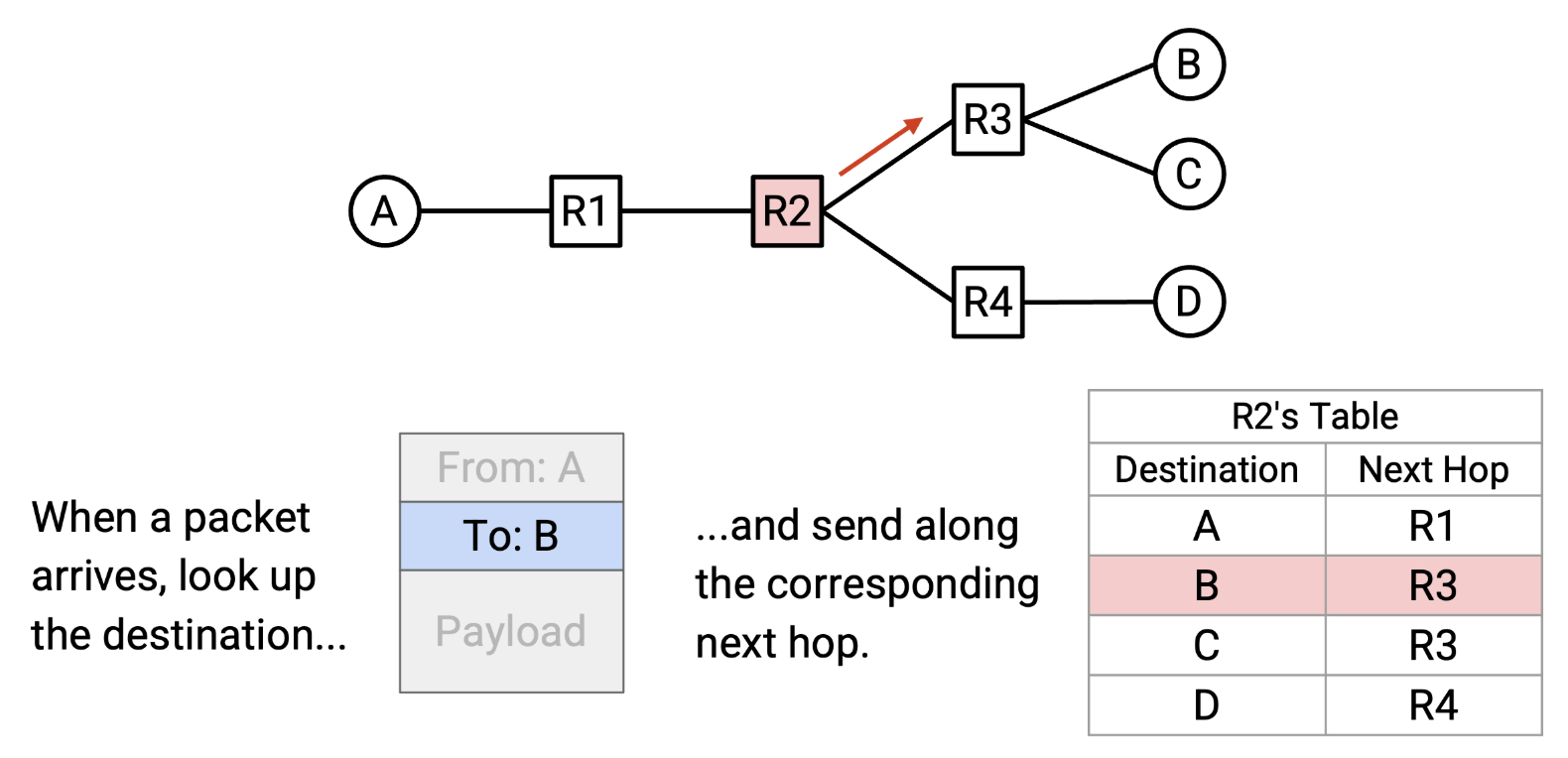
请注意,在目标地址到下一跳的映射中,一个下一跳可以被多次使用。例如,在 R2 的转发表中,发往 B 的数据包和发往 C 的数据包都会被转发到 R3。
路由表可以理解为是一个键值对,如下图所示。一个从A发往B的数据包经过R2时,R2会查询它本地的路由表,发现对于目的地B的数据包应该发往R3路由器。在真实的物理世界中,路由器通常不会将目的地映射到下一跳,而是映射到物理端口 ,每个物理端口对应一条链路。在物理世界中,你可以把这想象成路由器有多条出线,每条出线都连接到另一个路由器。路由器不会在转发表中记录相邻路由器,而是记录数据包应该通过哪条出线发送。它反映了路由器实际上并不关心相邻路由器的身份。路由器唯一需要做的决定就是将数据包沿着其中一条线路发送出去,而不管这条线路连接的是哪个路由器
路由与转发
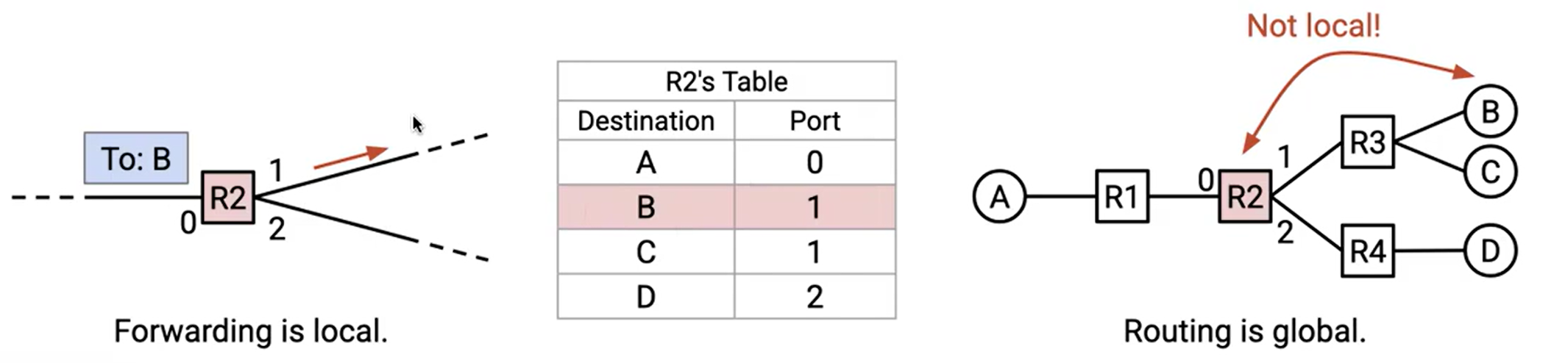
既然我们已经介绍了路由表的概念,我们就需要区分创建转发表的过程和使用转发表的过程。
路由(Routing)是指路由器之间相互通信,以确定如何填充其转发表的过程,它是创建转发表的过程。
转发(Forwarding)是指接收到数据包后,在表中查找其合适的下一跳,并将数据包发送到合适的邻居的过程,它是使用转发表的过程。
转发与路由并不相同。转发数据包时,路由器使用现有的转发表,而无需了解该表是如何生成的。它是一个本地过程。路由器转发数据包时,无需了解完整的网络拓扑结构。路由器也不关心数据包转发到下一跳后的去向。路由器只需要知道到达的数据包以及自身的转发表。
相比之下,路由是一个全局过程。为了填充转发表,我们需要了解一些关于网络全局拓扑结构的信息。
路由算法
到目前为止,我们将路由问题定义为:当路由器收到一个数据包时,路由器如何知道将数据包转发到哪里,才能最终到达目的地?
我们需要通过算法找到一组路由状态,路由状态可以理解为每个路由器用来转发其接收到的数据包的一组规则。我们希望找到一组有效的路由状态,考虑全局路由状态,它由所有路由器中的所有转发表的集合组成
仅仅查看局部路由状态(例如单个路由器的转发表)无法判断路由状态是否有效,因为它可能是错误的
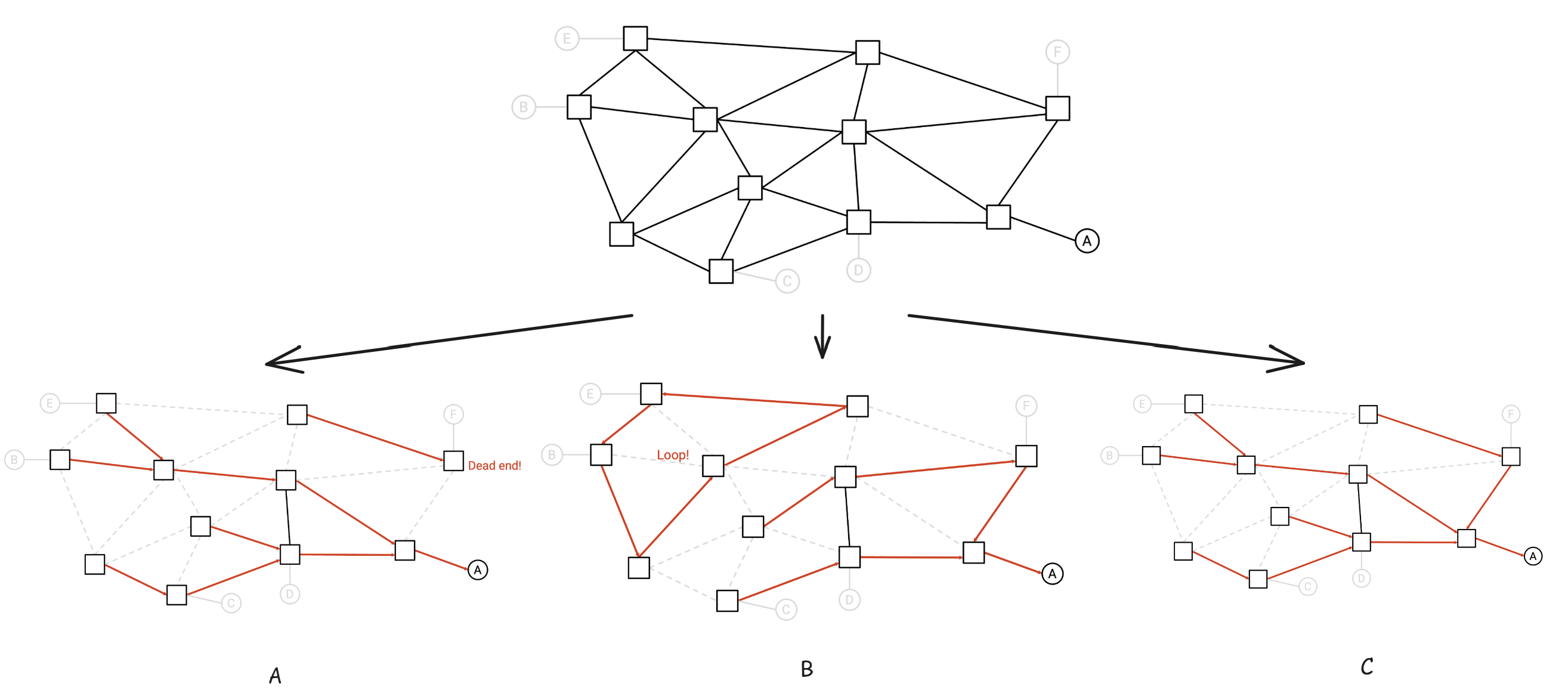
然而找到这样一组有效的规则本质上是图计算中生成树相关的过程,例如下图A不符合,我们希望生成树中所有边都联通;下图B不符合,因为不希望数据包陷入环路
然而找到这样一组路由状态还远远不够,目前仅能确保路由中不存在环路和死路。如果我们希望找到一组最佳的路由状态,即希望找到能够使数据包沿成本最低的路径到达目的地的路由的最小成本路由。
最小成本路由的计算相当复杂,因为链路实际上具有不同的成本。这些成本可能取决于链路建设成本、传播延迟、链路物理距离、可靠性、带宽等因素。假设有一条 400 Gbps 的链路,传播延迟为 20 毫秒;还有一条 10 Gbps 的链路,传播延迟为 5 毫秒,哪条链路的成本更低?这取决于我们优化的目标是带宽、传播延迟、两者兼顾,还是其他完全不同的目标
本文我们暂时将成本量化为一个数字,且我们假设成本是对称的。即从 A 到 B 的成本与从 B 到 A 的成本相同。
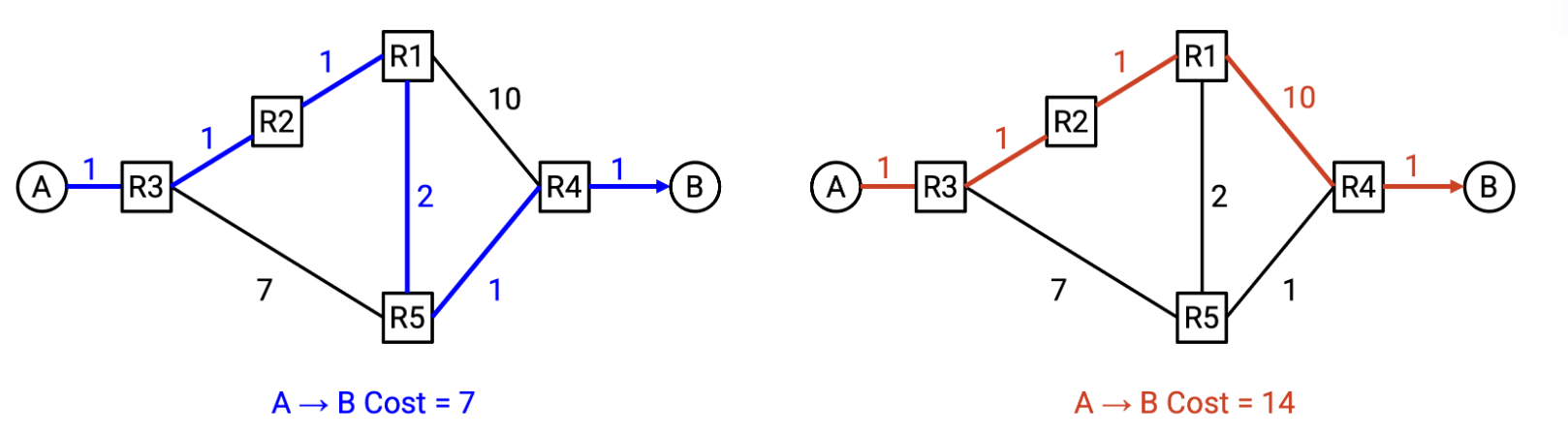
路由算法分为三种,下面我们将分别介绍它们
- 距离矢量路由
- 链路状态路由
- 路径矢量路由
距离矢量协议
距离矢量协议在互联网和 ARPANET(互联网的前身)上有着悠久的历史。典型的距离矢量协议是路由信息协议(RIP)