slab分配器
产生背景
在Linux中,伙伴分配器(buddy allocator)是以页为单位管理和分配内存。但在内核中的需求却以字节为单位(在内核中面临频繁的结构体内存分配问题, 例如 struct inodem struct task_struct).假如我们需要动态申请一个内核结构体(占 20 字节),若仍然分配一页内存,这将严重浪费内存
既然 buddy system 采用的 4KB 太大, 那我们能不能考虑以更小的尺寸(比如64/128/256B)去组织,形成一个二级分配系统呢? 假设一个object的大小是96字节,如果使用这样的二级分配器,申请时将从128字节的free list开始查找,没有则继续寻找更高order的free list. 这个思路有两个比较明显的缺点
- 这将在每个被使用到的128字节内存块中留下32字节难以使用的"碎片",造成内存资源的浪费。
- 一个object在释放后将归还到128字节的free list上,根据buddy的规则,可能被合并为更高order的内存块,如果这个object马上又要使用,则需要再次从free list上分配
除此之外, 对于频繁的分配/回收的内存段, 我们期望可以缓存和复用相同的objects,加快分配和释放的速度。
历史与简介
slab 分配器专为小内存分配而生, 基于伙伴分配器的大内存进一步细分成小内存分配。换句话说,slab 分配器仍然从 Buddy 分配器中申请内存,之后自己对申请来的内存细分管理。
slab 由Sun公司的一个雇员Jeff Bonwick在Solaris 2.4中设计并实现, 由于他公开了其方法,因而后来被Linux所借鉴,用于实现内核中更小粒度的内存分配。
除了提供小内存外,slab 分配器的第二个任务是维护常用对象的缓存.对于内核中使用的许多结构,初始化对象所需的时间可等于或超过为其分配空间的成本。当创建一个新的slab 时,许多对象将被打包到其中并使用构造函数(如果有)进行初始化。释放对象后,它会保持其初始化状态,这样可以快速分配对象
slab 分配器的最后一项任务是提高CPU硬件缓存的利用率. 如果将对象包装到 slab 中后仍有剩余空间,则将剩余空间用于为 slab 着色。slab 着色是一种尝试使不同 slab 中的对象使用CPU硬件缓存中不同行的方案。通过将对象放置在 slab 中的不同起始偏移处,对象可能会在CPU缓存中使用不同的行,从而有助于确保来自同一 slab 缓存的对象不太可能相互刷新。通过这种方案,原本被浪费掉的空间可以实现一项新功能
slab 有很多相关的概念和内容比较容易搞混, 这里做一下区分
- 本文讨论是 slab allocator, 这是一个用于紧密管理小内存分配器的概念。slab allocator 有三个主流的实现 SLOB SLAB SLUB
- SLOB 是最早出现的, 非常紧凑但不够高效/性能不好, 现在只能在嵌入式系统中看到;
- SLAB 是 Solaris 的实现, 高缓存效率但是比较浪费内存, 并且它不断地在做一些检查和计算以确保缓存的有效性, 对于拥有大量核心的超级计算机上会浪费大量的 CPU 周期去跟踪计算内存;
- SLUB 是当前 Linux 默认采用的分配器实现
- SLAB/SLUB 的内部实现中也有叫做 slab 的字段, 需要注意区分
目前 SLAB 已经被弃用 Linux 的 SLAB 分配器已正式弃用?的回答
下文中 slab allocator 指 slab 分配器, SLUB 指 SLUB 算法(一种 slab allocator 的实现), slab 指 SLUB 中的字段
下文讨论 SLAB 以及当前 Linux 使用的 slab allocator: SLUB, slab allocator 主要解决了如下的几个核心问题
- 解决buddy按照页的颗粒度分配小内存的碎片问题
- 缓存部分常用的数据结构(包括但不限于inode、dir_entry、task_struct等),减少操作系统分配、回收对象时调整内存的时间开销
- 通过着色更好地利用cpu硬件的高速缓存cache,允许不同缓存中的对象占用相同的缓存行,从而提高缓存的利用率并获得更好的性能
SLAB & SLUB
在slab分配器中,每一类objects拥有一个"cache"(比如inode_cache, dentry_cache, 具有相同的 sizeof).之所以叫做"cache",是因为每分配一个object,都从包含若干空闲的同类objects的区域获取,释放时也直接回到这个区域,这样可以缓存和复用相同的objects,加快分配和释放的速度
object从"cache"获取内存,"cache"的内存从buddy分配器来。也就是说slab allocator层直接面向程序的分配需求,相当于是前端,而buddy系统则成为slab allocator的后端, 如下图所示
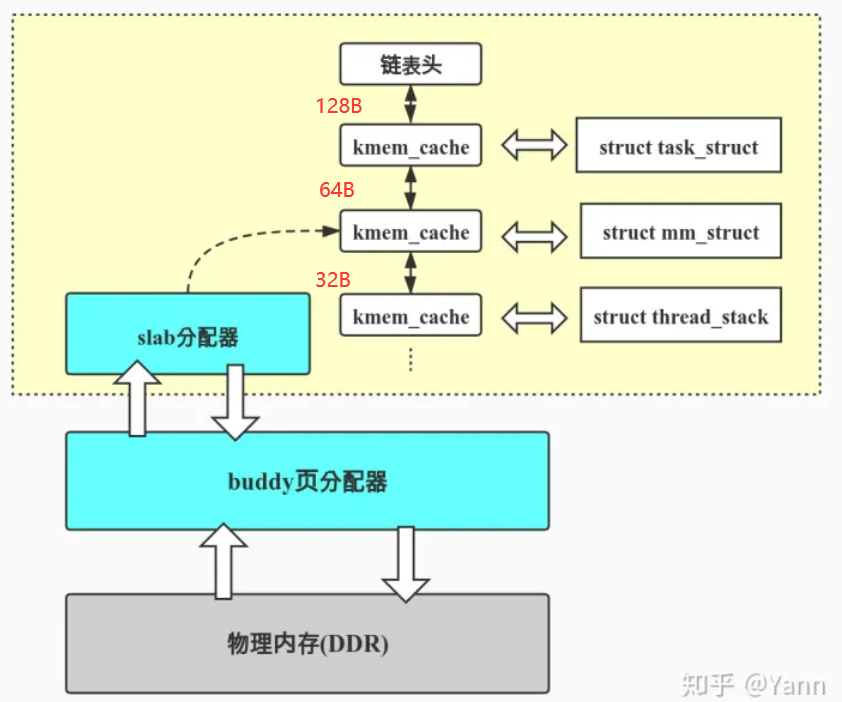
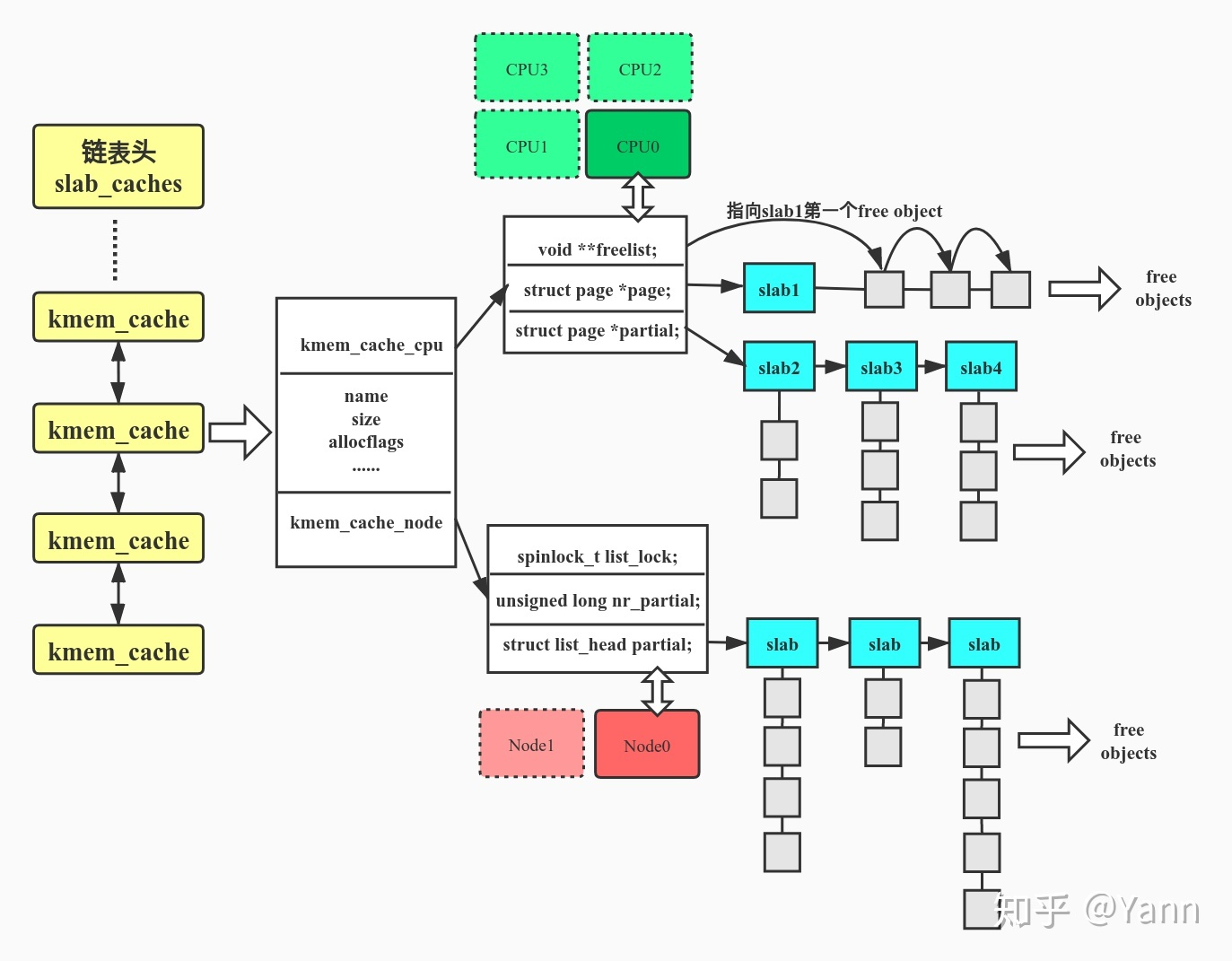
其中 kmem_cache 即上文提到的 "cache" , 是一个定义在 include/linux/slub_def.h 的结构体 kmem_cache. 这个结构体字段很多, 但我们比较关系的是两个字段 cpu_slab 以及 node
struct kmem_cache {
struct kmem_cache_cpu *cpu_slab;
const char *name; /* Name (only for display!) */
struct kmem_cache_node *node[MAX_NUMNODES];
};
struct kmem_cache_cpu {
/*指向下面page指向的slab中的第一个free object*/
void **freelist;
/* Globally unique transaction id */
unsigned long tid;
/*指向当前正在使用的slab*/
struct page *page;
/*本地slab缓存池中的partial slab链表*/
struct page *partial;
};
struct kmem_cache_node {
#ifdef CONFIG_SLAB
/*kmem_cache_node数据结构的自旋锁,可能涉及到多核访问*/
raw_spinlock_t list_lock;
struct list_head slabs_partial; /* partial list first, better asm code */
struct list_head slabs_full;
struct list_head slabs_free;
unsigned long total_slabs; /* length of all slab lists */
unsigned long free_slabs; /* length of free slab list only */
unsigned long free_objects;
unsigned int free_limit;
unsigned int colour_next; /* Per-node cache coloring */
struct array_cache *shared; /* shared per node */
struct alien_cache **alien; /* on other nodes */
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
#endif
#ifdef CONFIG_SLUB
/*kmem_cache_node数据结构的自旋锁,可能涉及到多核访问*/
spinlock_t list_lock;
/*node中slab的数量*/
unsigned long nr_partial;
struct list_head partial;
#endif
};SLAB 和 SLUB 的差别就在于 CONFIG_SLAB 与 CONFIG_SLUB 的选择, 对应结构体 kmem_cache_node 中 SLAB 具有 slabs_free(全空), slabs_partial(部分空), slabs_full(全满), 但是 SLUB 只有 partial(部分空).
SLUB内存分配器是在SLAB的基础上进行了改进和简化。SLUB设计的目标是进一步减少内存分配和回收的开销,因此它仅使用了一个链表_即partial链表,而去除了SLAB中的slab_full链表。
下图是 kmem_cache 结构体展开的设计架构图, 下面具体介绍一下每一部分的内容。
分配与回收
下面的介绍为 SLAB 分配算法, 所以有 partial 和 full, SLUB 就是把 slabs_full 去掉的简化
其中 cpu_slab 为当前 CPU 正在使用的 slab, 该 slab 包含一个 void **freelist, 等分为了一个个小的 object. 用于当前内存地址的分配/回收
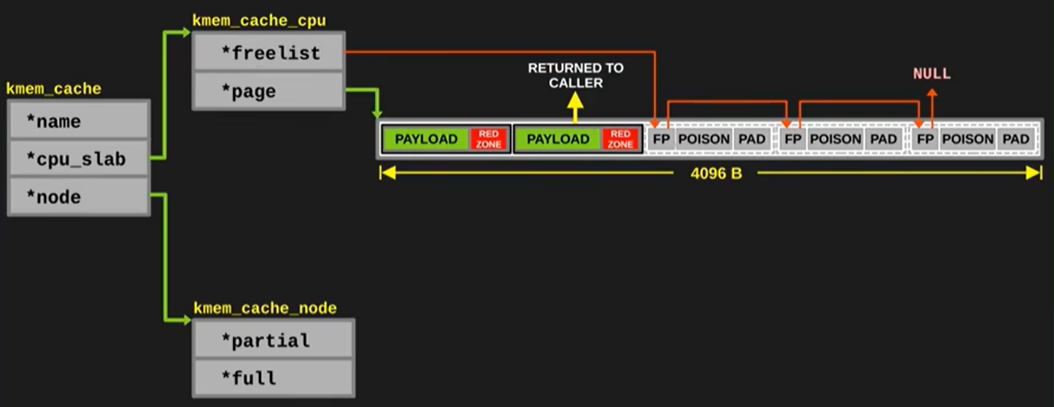
后续内存块更新之后, 需要维护 cpu_slab 中的 free_list 指针, 以便可以迅速找到第一个可用的内存块
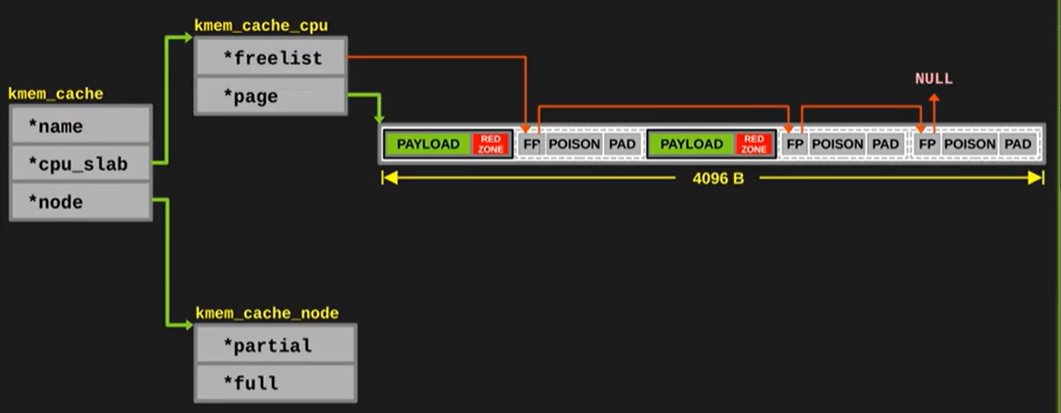
如果分配了很多个内存块, 那么当前 cpu 的 slab 满, 将 slab 移动到 slab_full 中
这一部分链表的转移需要 spinlock 自旋锁, 因为多核 CPU
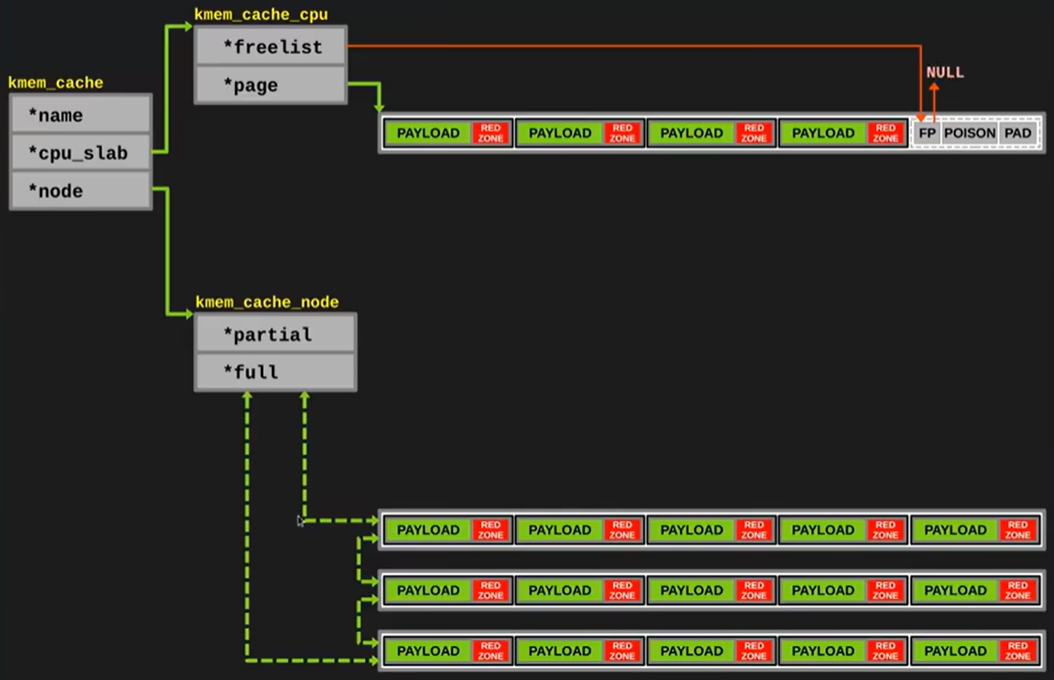
如果此时 slabs_full 当中的某一个 slab 的内存块需要被释放, 则释放当前内存块并将 slab 转移至 slabs_partial 中
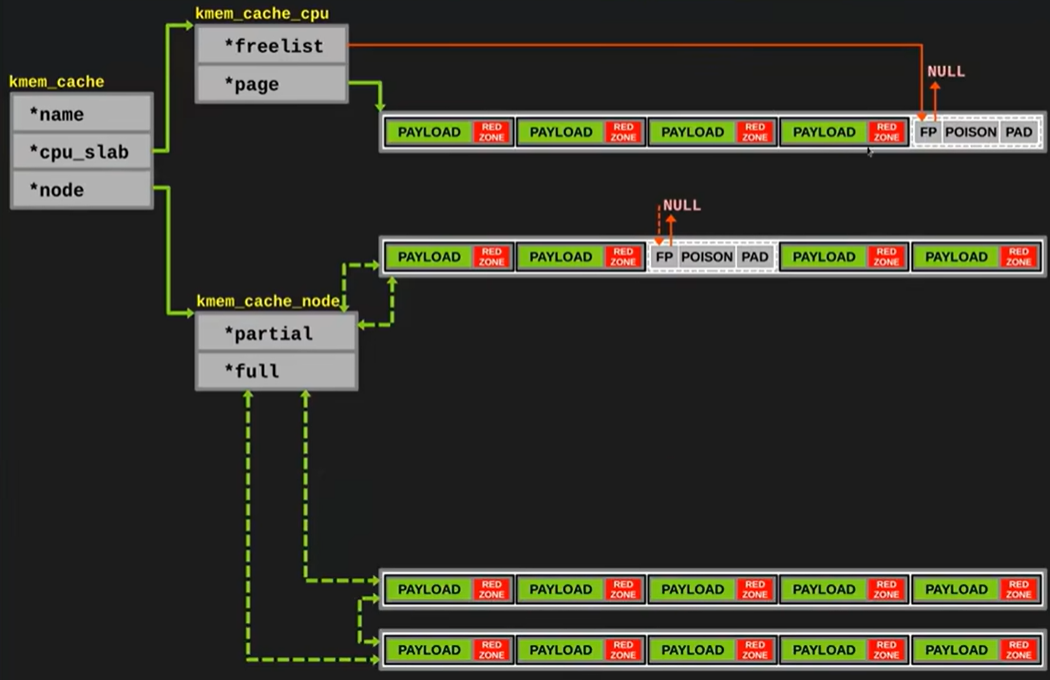
当 cpu 中的 slab 的每一个 object 全部分配了之后, 将该 slab 转移至 slabs_full
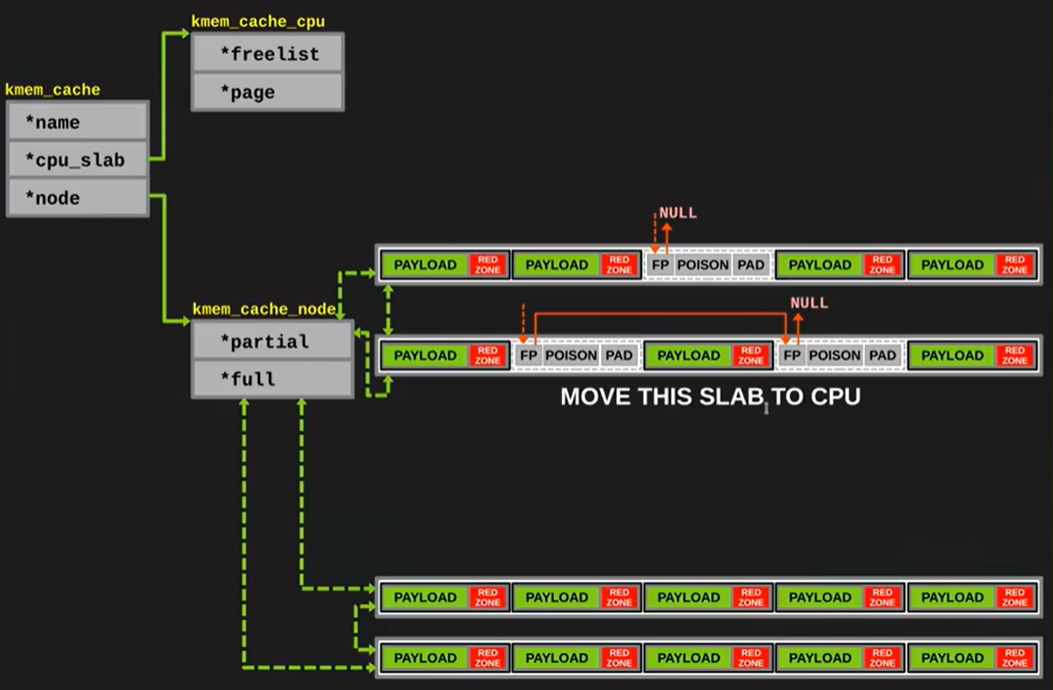
- 如果当前 slabs_partial 不为空(下图的情况), 则将一个 partial 的 slab 移动到 cpu 中继续分配
- 如果当前 slabs_partial 为空, 则向 buddy 申请一个新的 page 用于分配
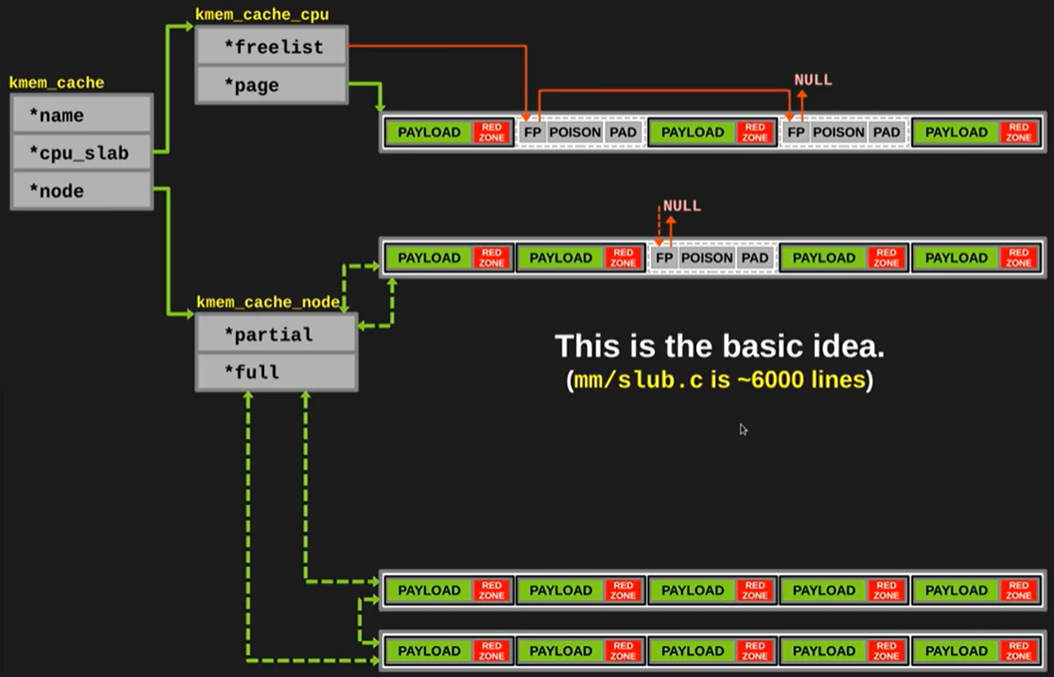
移动之后如下图所示
API使用
/*分配一块给某个数据结构使用的缓存描述符
name:对象的名字 size:对象的实际大小 align:对齐要求,通常填0,创建是自动选择。 flags:可选标志位 ctor: 构造函数 */
struct kmem_cache *kmem_cache_create(const char *name, size_t size, size_t align, unsigned long flags, void (*ctor)(void*));
/*销毁kmem_cache_create分配的kmem_cache*/
int kmem_cache_destroy( struct kmem_cache *cachep);
/*从kmem_cache中分配一个object flags参数:GFP_KERNEL为常用的可睡眠的,GFP_ATOMIC从不睡眠 GFP_NOFS等等等*/
void* kmem_cache_alloc(struct kmem_cache* cachep, gfp_t flags);
/*释放object,把它返还给原先的slab*/
void kmem_cache_free(struct kmem_cache* cachep, void* objp);