rmap
rmap 有反向映射和逆向映射两种中文翻译, 本文用反向映射描述
什么是反向映射?
在讨论反向映射之前,我们先聊聊正向映射。理解了正向映射,反向映射的概念就变得简单易懂了。
正向映射的意思是:在已知虚拟地址和物理地址(或者页号、页面结构体)的情况下,建立起地址映射所需的完整页表。举个例子,当进程分配了一段虚拟内存区域(VMA)时,最初并没有与之对应的物理页面(即没有分配物理地址).只有当程序访问这段虚拟内存时,会触发缺页异常,内核随后为其分配物理页面,并填充所有相关层级的页表条目(即完成地址转换的表).通过正向映射,可以将进程虚拟地址空间中的虚拟页面与物理内存中的页面一一对应起来。
反向映射则相反,是从物理页面的角度出发。在已知某个物理页面的情况下(比如通过物理帧号、页面描述符指针或者物理地址获取到),找到所有映射到该物理页面的虚拟页面.由于一个物理页面可能被多个进程共享,反向映射的任务就是将分散在不同进程地址空间中的所有相关页表条目逐一找出并记录下来。这种映射关系在内核中通过各种宏和机制来实现物理地址和虚拟地址的互相转换。

每一个进程的虚拟页会对应映射唯一的一个物理页, 一个物理页大多数情况下也只会对应一个虚拟页。但是一个物理页也可能会映射到多个虚拟页, 那么多半是这个page被多个进程共享, 如下图所示
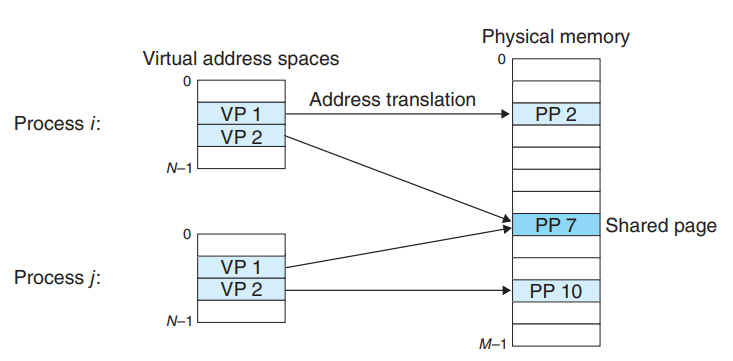
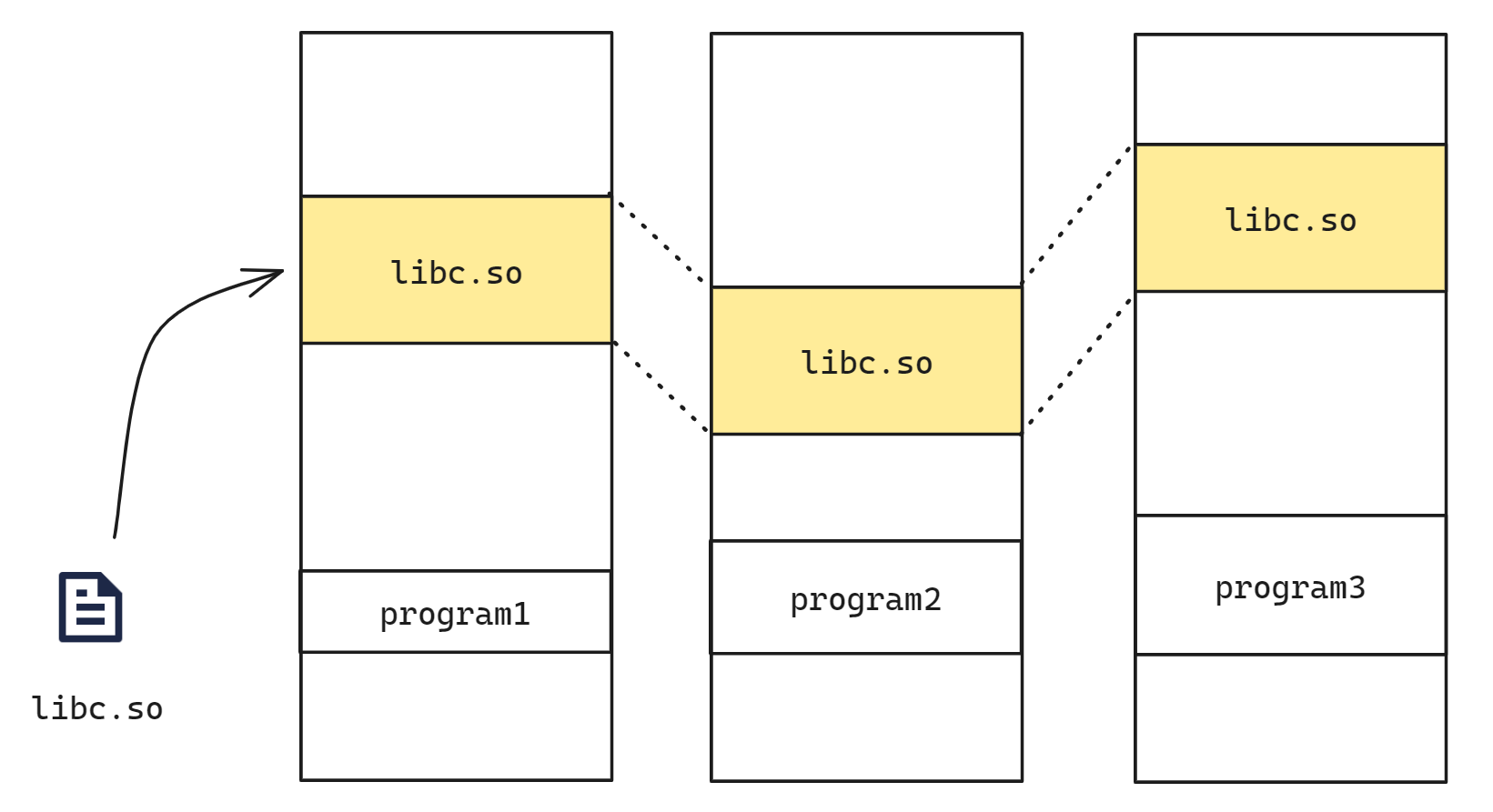
最简单的例子就是采用COW的进程fork,在进程没有写的动作之前,内核是不会分配新的page frame的,因此父子进程共享一个物理页面。另一个例子是动态链接库, 例如 libc. 操作系统只需要装载一次 libc.so, 其余所有程序都可以共享使用。libc.so 只在物理内存中被加载一次, 然后被映射到多个进程的虚拟内存空间
为何需要反向映射?
之所以建立反向映射机制主要是为了方便页面回收。既然一个页面可能会映射到多个进程的地址空间, 那么当我们试图回收一个页面时就需要考虑将其从所有包含它的进程中移除相关页表地址映射
- 如果回收的page frame是位于内核中的各种内存cache中(例如 slab内存分配器),那么这些页面其实是可以直接回收,没有相关的页表操作。
- 如果回收的是用户进程空间的page frame,那么在回收之前,内核需要对该page frame进行unmapping的操作,即找到所有的page table entries,然后进行对应的修改操作。当然,如果页面是dirty的,我们还需要一些必要的磁盘IO操作。
NOTE如果回收时不做操作, 那么原先进程访问此地址时依然采用原先的页表映射, 虽然不会造成 pagefault 但是由于这个页面已经不再属于它了因此可能会读取到一个错误的数据
将原先进程对应的页表项取消映射之后, 如果再次访问当作 pagefault 处理重新换回页面即可
没有反向映射之前?
页表是种单向映射, 即通过虚拟地址查找物理地址很容易,但反之通过物理地址查找虚拟地址则很麻烦。这种问题在共享内存的情况下更加严重。而swap子系统在释放页面时就遇到这个问题, 对于特定页面(物理地址), 要找到映射到它的页表项(PTE), 并修改PTE, 以使其指向交换设备中的该页的位置。
在2.4之前的内核中, 这是件费时的工作, 当时为了找到一个物理页面对应的页表项就需要遍历系统中所有的mm组成的链表,然后再遍历每一个mm的每一个vma看这个vma是否映射了这页,这个过程相当低效,最坏情况不得不遍历完所有的mm然后才能找映射到这个页的所有pte, 如下所示

反向映射的引入
解决这一问题的做法是引入反向映射(reverse mapping)这一概念。聪明的内核开发者很快想到了解决办法, 既然缺少由物理页到虚拟页的反向映射关系, 那么就为每一个内存页(struct page)维护一个数据结构, 其中包含所有映射到该页的PTE, 这样在寻找一个内存页的反向映射时只要扫描这个结构即可, 大大提高了效率
因此为 struct page 增加了一个 pte 字段, 对于非共享页面,只有一个pte entry,因此direct直接指向那个pte entry就OK了。
struct page {
...
union {
struct pte_chain *chain;
pte_addr_t direct;
} pte;
...
};
struct pte_chain {
unsigned long next_and_idx;
pte_addr_t ptes[NRPTE];
} ____cacheline_aligned;如果存在页面共享的情况,那么chain成员则会指向一个struct pte_chain的链表。pte chain 用来把所有mapping到该page的pte entry指针给串起来。这样想要unmap一个page就易如反掌了,沿着这个pte chain就可以找到所有的mappings.一个基本的示意图如下

有了rmap,页面回收算法顿时感觉轻松多了,只要是页面回收算法看中的page frame,总是能够通过try_to_unmap解除和所有进程的关联,从而将其回收到伙伴系统中。
- 如果该页没有共享(page flag设定PG_direct flag),那么page->pte.direct直接命中pte entry,调用try_to_unmap_one来进行unmap的操作。
- 如果映射到了多个虚拟地址空间,那么沿着pte_chain依次调用try_to_unmap_one来进行unmap的操作
这是一个出于直觉的想法,也确实解决了扫描的问题。只要遍历pte_chain就可以找到对应的页表了。在引入第一个版本的rmap之后,Linux的页面回收变得简单、可控了。当然, 它是有代价的
- 每个struct page都增加了一个字段(8字节), 而系统中每个内存页都对应一个struct page结构, 这意味着相当数量的内存被用来维护这个字段。而struct page是重要的内核数据结构, 存放在有限的低端内存中, 增加一个字段浪费了大量的保贵低端内存, 而且, 当物理内存很大时, 这种情况更突出, 这引起了伸缩性(scalability)问题。
并且事实上仅用户空间的页面需要记录这样的指针, 对于内核空间的页面这个字段完全就是浪费内存。
- 其它一些需要操作大量页面的函数慢下来了。fork()系统调用就是一个。由于Linux采取写时复制(COW, Copy On Write)的语义, 意味着新进程共享父进程的页表, 这样, 进程地址空间内的所有页都新增了一个PTE指向它, 因此, 需要为每个页新增一个反向映射, 在copy page table的时候就会伴随大量的pte_chain的操作, 这显著地拖慢了速度。
基于对象的反向映射
这种代价显然是不能容忍的, 于是新提出了基于对象的反向映射(object-based reverse mapping)的解决方案。他的观察是, 前面所述的代价来源于反向映射字段的引入, 而如果存在可以从struct page中获取映射到该页面的所有页表项, 这个字段就不需要了, 自然不需要付出这些代价。他确实找到了一种方法。
Linux的用户态内存页大致分两种使用情况:
- 其中一大部分叫做文件后备页(file-backed page), 顾名思义, 这种内存页的内容关联着后备存储系统中的文件, 比如程序的代码, 比如普通的文本文件, 这种内存页使用时一般通过上述的mmap系统调用映射到地址空间中, 并且, 在内存紧张时, 可以简单地丢弃, 因为可以从后备文件中轻易的恢复。
- 一种叫匿名页(anonymous page), 这是一种普通的内存页, 比如栈或堆内存就属于这种, 这种内存页没有后备文件, 这也是其称为匿名的缘故。
文件页的反向映射映射
对于这些文件映射页面,其struct page中有一个成员mapping指向一个struct address_space, address_space是和文件相关的,它保存了文件page cache相关的信息。一个文件可能会被映射到多个进程的多个VMA中,所有的这些VMA都被挂入到该结构体的 i_mmap 字段指向的树中, 因此我们可以通过 page 找到所有映射了该页的 vma, 如下图所示

那么如何找到该 page 在每个进程中对应的虚拟地址呢? 上图中 page 的另一个字段 page->index 表示的是映射页到文件内的偏移,而vma 的一个字段 vma->vm_pgoff 表示的是该VMA映射到文件内的偏移. 因此,通过vma->vm_pgoff和page->index可以得到该page frame在VMA中的地址偏移,再加上vma->vm_start就可以得到该page frame的虚拟地址。如下图所示

NOTE上图公式只是示例, 实现上还有 page(4k) 和 byte 的转换, 在linux kernel中,函数 vma_address 可以完成这个功能
有了虚拟地址和地址空间(vma->vm_mm),我们就可以通过各级页表找到该page对应的pte entry. 因此可以实现在不引入其他字段的情况下完成从 page 找到所有映射的 vma 并且找到 va 的过程, 然后取消对应进程的页表映射即可
匿名页的反向映射
前文提到, 匿名页没有所谓的后备文件, 但是,匿名页有个特点, 就是它们都是私有的, 而非共享的(比如栈, 椎内存都是独立每个进程的, 非共享的).这意味着, 每一个匿名内存页, 只有一个PTE关联着它, 也就是只有一个vma关联着它。 因此可以复用struct page的mapping字段, 因为对于匿名页, mapping为null, 不指向后备空间, 而是指向关联该内存页的唯一的vma.
但是, 事情并不是如此简单。当进程被fork复制时, 由于COW的语义, 新进程只是复制父进程的页表, 这意味着现在一个匿名页有两个页表指向它了, 这样, 上面的简单复用mapping字段的做法不适用了, 因为一个指针如何表示两个vma呢?
NOTE在 fork 时,父进程的 VMA 会被逐一复制到子进程中, 父子进程的 vma
- 虚拟地址范围相同:父子进程的虚拟地址范围是相同的,因为 fork 后子进程复制了父进程的地址空间布局。
- VMA 数据结构的指针不同:内核中的 VMA 结构体是父子进程独立的实例,它们的地址(指针值)通常不同。
- 物理页相同:匿名页的物理页地址(在物理内存中的实际位置)是相同的,直到写时复制触发为止。
详见 fork
内核的做法就是多加一层.新创建一个struct anon_vma结构, 现在mapping字段是指向它了, 而anon_vma中包含一个链表, 链接起所有的vma.每当进程fork一个子进程, 子进程由于COW机制会复制父进程的vma, 这个新vma就链接到父进程中的anon_vma中。这样, 每次unmap一个内存页时, 通过mapping字段指向的anon_vma, 就可以找到可能关联该页的vma链表, 遍历该链表, 就可以找到所有映射到该匿名页的PTE.

这也有代价, 那就是
- 每个struct vm_area_struct结构多了一个list_head结构字段用以串起所有的vma.
- 需要额外为anon_vma结构分配内存。
但是, 这种方案所需要的内存远小于前面所提的在每个struct page中增加一个反向映射字段来得少, 因此是可以接受的。
NOTE为什么文件页的反向映射使用快速查找树? 而匿名页的反向映射使用链表?
这应该是由于匿名页映射不会很多,而文件页映射会多很多的原因
最终方案: anon_vma_chain
anon_vma结构的提出, 完善了反向映射机制, 一路看来, 无论是效率还是内存使用, 都有了提升, 应该说是很完美的一套解决方案。但现实不断提出难题。但是在一些特殊工作负载(workload)的例子中该方案仍然存在缺陷。
假设父进程有1000个子进程,每个子进程都有一个VMA, 这个VMA中有1000个匿名页面, 这会导致系统拥有一百万个页面映射到同一 anon_vma, 那么对于该链表的遍历操作将会相当的耗时。而且遍历VMA链表会持有anon_vma->lock这个自旋锁, 其他CPU在试获取这把锁的时候,基本会被卡住,这时候整个系统的性能就会非常差。
想象一下,一百万个页面共享这一个anon_vma,对anon_vma->lock自旋锁的竞争那是相当的激烈啊
static int try_to_unmap_anon(struct page *page) {
anon_vma = page_lock_anon_vma(page);
list_for_each_entry(vma, &anon_vma->head, anon_vma_node) {
ret = try_to_unmap_one(page, vma);
}
spin_unlock(&anon_vma->lock);
return ret;
}前面提到 fork 进程时会采用 COW 机制, 父子进程的匿名页是共享的,所以这些page frame指向同一个anon_vma.当然,共享只是短暂的,一旦有write操作就会产生异常,并在异常处理中分配page frame,解除父子进程匿名页面的共享。这时候由于写操作,父子进程原本共享的page frame已经不再共享,然而,这两个page却仍然指向同一个anon_vma, 并且原来的 anon_vma 也并不会将其剔除, 从而导致了对该vma不必要的检查(检查vma是否有效)
于是诞生了最终的解决方案: 又增加一层, 新增了一个结构叫anon_vma_chain:
struct anon_vma_chain {
struct vm_area_struct *vma;
struct anon_vma *anon_vma;
struct list_head same_vma; /* locked by mmap_lock & page_table_lock */
struct rb_node rb; /* locked by anon_vma->rwsem */
};anon_vma_chain 是连接 VMA 和 anon_vma(AV)之间的桥梁, 每个anon_vma_chain(AVC)维护两个关键数据结构
- same_vma: 链表节点,通常把anon_vma_chain添加到vma->anon_vma_chain链表中
- rb: 红黑树节点,通常把anon_vma_chain添加到anon_vma->rb_root的红黑树
AV AVC VMA 三者结构体字段以及相关数据结构关系如下图所示


内核实现
struct page 和反向映射相关的结构体字段如下, 其中关键字段就是 mapping. 虽然定义的 mapping 类型是 struct address_space, 但对于匿名页面其实是 struct anon_vma
struct page {
...
struct address_space *mapping;
...
union {
atomic_t _mapcount;
unsigned int page_type;
};
atomic_t _refcount;
};在函数 folio_get_anon_vma 的实现中可以看到首先读取了一下 folio->mapping 并判断其低位是否为 PAGE_MAPPING_ANON, 如果是则将其视为一个地址强转为 struct anon_vma 类型
#define PAGE_MAPPING_ANON 0x1
#define PAGE_MAPPING_MOVABLE 0x2
#define PAGE_MAPPING_KSM (PAGE_MAPPING_ANON | PAGE_MAPPING_MOVABLE)
#define PAGE_MAPPING_FLAGS (PAGE_MAPPING_ANON | PAGE_MAPPING_MOVABLE)
struct anon_vma *folio_get_anon_vma(struct folio *folio)
{
struct anon_vma *anon_vma = NULL;
unsigned long anon_mapping;
rcu_read_lock();
anon_mapping = (unsigned long)READ_ONCE(folio->mapping);
if ((anon_mapping & PAGE_MAPPING_FLAGS) != PAGE_MAPPING_ANON)
goto out;
if (!folio_mapped(folio))
goto out;
anon_vma = (struct anon_vma *) (anon_mapping - PAGE_MAPPING_ANON);
if (!atomic_inc_not_zero(&anon_vma->refcount)) {
anon_vma = NULL;
goto out;
}
/*
* If this folio is still mapped, then its anon_vma cannot have been
* freed. But if it has been unmapped, we have no security against the
* anon_vma structure being freed and reused (for another anon_vma:
* SLAB_TYPESAFE_BY_RCU guarantees that - so the atomic_inc_not_zero()
* above cannot corrupt).
*/
if (!folio_mapped(folio)) {
rcu_read_unlock();
put_anon_vma(anon_vma);
return NULL;
}
out:
rcu_read_unlock();
return anon_vma;
}使用反向映射最常见的是在回收页面,try_to_unmap是其重要函数
void try_to_unmap(struct folio *folio, enum ttu_flags flags)
{
struct rmap_walk_control rwc = {
.rmap_one = try_to_unmap_one,
.arg = (void *)flags,
.done = folio_not_mapped,
.anon_lock = folio_lock_anon_vma_read,
};
if (flags & TTU_RMAP_LOCKED)
rmap_walk_locked(folio, &rwc);
else
rmap_walk(folio, &rwc);
}针对 folio 的类型分别对应三种
void rmap_walk(struct folio *folio, struct rmap_walk_control *rwc)
{
if (unlikely(folio_test_ksm(folio)))
rmap_walk_ksm(folio, rwc);
else if (folio_test_anon(folio))
rmap_walk_anon(folio, rwc, false);
else
rmap_walk_file(folio, rwc, false);
}static void rmap_walk_anon(struct folio *folio,
struct rmap_walk_control *rwc, bool locked)
{
struct anon_vma *anon_vma;
pgoff_t pgoff_start, pgoff_end;
struct anon_vma_chain *avc;
if (locked) {
anon_vma = folio_anon_vma(folio);
/* anon_vma disappear under us? */
VM_BUG_ON_FOLIO(!anon_vma, folio);
} else {
anon_vma = rmap_walk_anon_lock(folio, rwc);
}
if (!anon_vma)
return;
pgoff_start = folio_pgoff(folio);
pgoff_end = pgoff_start + folio_nr_pages(folio) - 1;
anon_vma_interval_tree_foreach(avc, &anon_vma->rb_root,
pgoff_start, pgoff_end) {
struct vm_area_struct *vma = avc->vma;
unsigned long address = vma_address(&folio->page, vma);
VM_BUG_ON_VMA(address == -EFAULT, vma);
cond_resched();
if (rwc->invalid_vma && rwc->invalid_vma(vma, rwc->arg))
continue;
if (!rwc->rmap_one(folio, vma, address, rwc->arg))
break;
if (rwc->done && rwc->done(folio))
break;
}
if (!locked)
anon_vma_unlock_read(anon_vma);
}