NUMA
相关阅读: 多处理器
CPU 术语
大多数CPU都是在二维平面上构建的。CPU还必须添加集成内存控制器。对于每个CPU核心,有四个内存总线(上,下,左,右)的简单解决方案允许完全可用的带宽,但仅此而已。CPU在很长一段时间内都停滞在4核状态。当芯片变成3D时,在上面和下面添加痕迹允许直接总线穿过对角线相反的CPU.在卡上放置一个四核CPU,然后连接到总线,这是合乎逻辑的下一步。
如今每个处理器都包含许多核心,这些核心都有一个共享的片上缓存和片外内存,并且在服务器内不同内存部分的内存访问成本是可变的。提高数据访问效率是当前CPU设计的主要目标之一, 因此每个CPU核都被赋予了一个较小的一级缓存(32 KB)和一个较大的二级缓存(256 KB).各个核心随后共享几个MB的3级缓存,其大小随着时间的推移而大幅增长。
为了避免缓存丢失(请求不在缓存中的数据),需要花费大量的研究时间来寻找合适的CPU缓存数量,缓存结构和相应的算法。详见 缓存一致性
一个 CPU 有如下的一些术语: socket core ucore threads
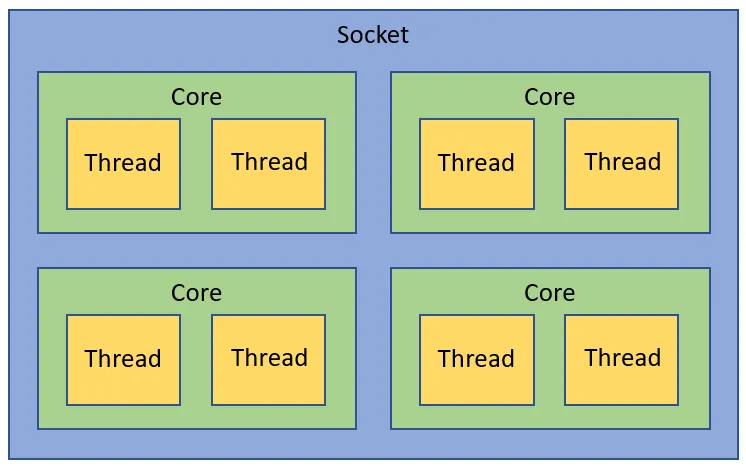
- Socket: 一个Socket对应一个物理CPU. 这个词大概是从CPU在主板上的物理连接方式上来的,可以理解为 Socket 就是主板上的 CPU 插槽。处理器通过主板的Socket来插到主板上。尤其是有了多核(Multi-core)系统以后,Multi-socket系统被用来指明系统到底存在多少个物理CPU.
- Core: CPU的运算核心. x86的核包含了CPU运算的基本部件,如逻辑运算单元(ALU), 浮点运算单元(FPU), L1和L2缓存。一个Socket里可以有多个Core.如今的多核时代,即使是单个socket的系统, 由于每个socket也有多个core, 所以逻辑上也是SMP系统。
但是,一个物理CPU的系统不存在非本地内存,因此相当于UMA系统。
- Uncore: Intel x86物理CPU里没有放在Core里的部件都被叫做Uncore.Uncore里集成了过去x86 UMA架构时代北桥芯片的基本功能。在Nehalem时代,内存控制器被集成到CPU里,叫做iMC(Integrated Memory Controller). 而PCIe Root Complex还做为独立部件在IO Hub芯片里。到了SandyBridge时代,PCIe Root Complex也被集成到了CPU里。现今的Uncore部分,除了iMC,PCIe Root Complex,还有QPI(QuickPath Interconnect)控制器, L3缓存,CBox(负责缓存一致性),及其它外设控制器。
- Threads: 这里特指CPU的多线程技术。在Intel x86架构下,CPU的多线程技术被称作超线程(Hyper-Threading)技术。Intel的超线程技术在一个处理器Core内部引入了额外的硬件设计模拟了两个逻辑处理器(Logical Processor), 每个逻辑处理器都有独立的处理器状态,但共享Core内部的计算资源,如ALU,FPU,L1,L2缓存。这样在最小的硬件投入下提高了CPU在多线程软件工作负载下的性能,提高了硬件使用效率。x86的超线程技术出现早于NUMA架构。
因此, 一个CPU Socket里可以由多个CPU Core和一个Uncore部分组成。每个CPU Core内部又可以由两个CPU Thread组成。每个CPU thread都是一个操作系统可见的逻辑CPU.对大多数操作系统来说,一个八核HT(Hyper-Threading)打开的CPU会被识别为16个CPU
如下图所示
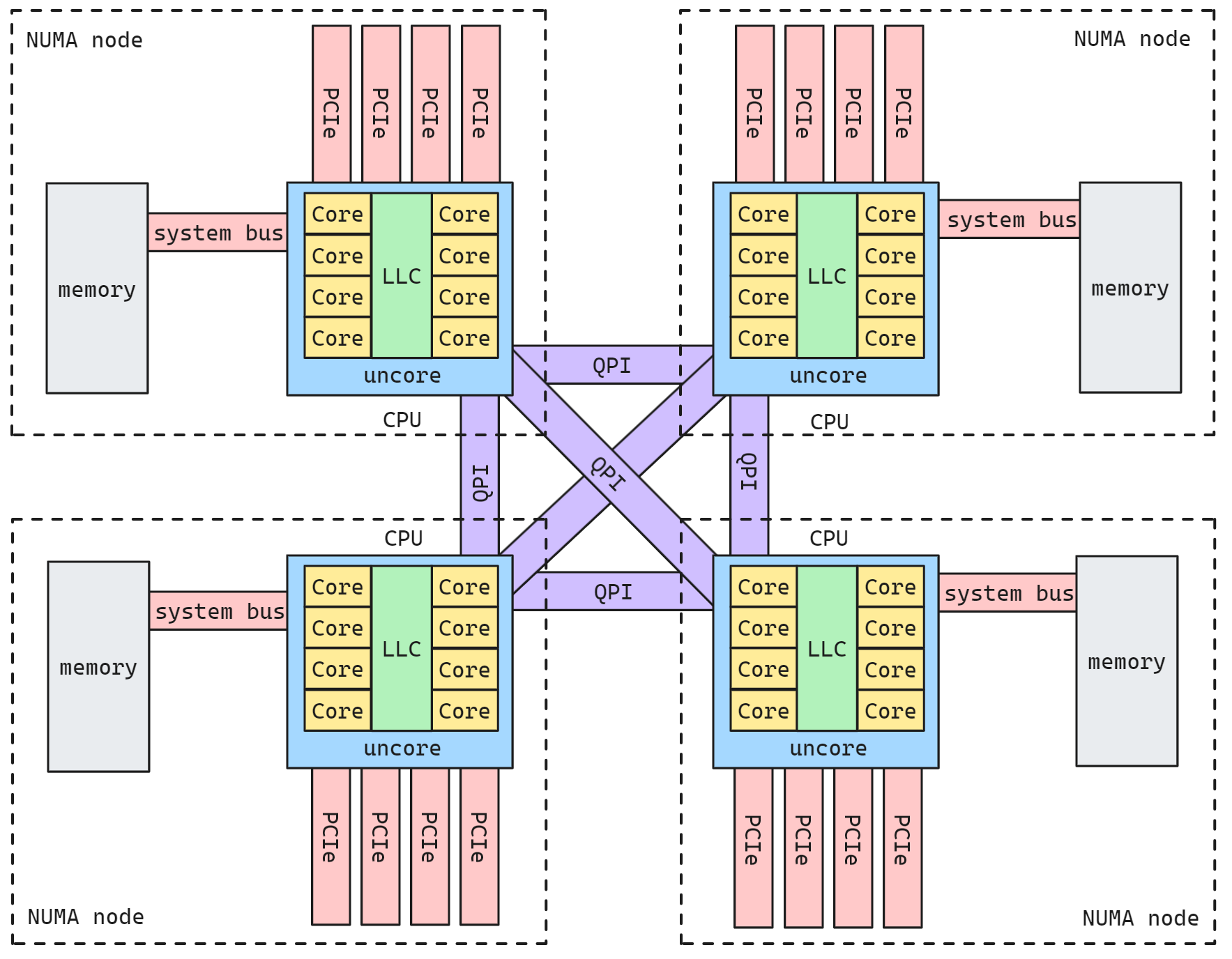
QPI(QuickPath Interconnect)是英特尔(Intel)处理器架构中使用的一种高速互联技术。它用于处理器与其他组件(如内存,I/O设备和其他处理器)之间的通信。
LLC(Last-Level Cache):LLC 是处理器架构中的最后一级缓存。在多级缓存结构中,处理器通常具有多个级别的缓存,而最后一级缓存(通常是共享的)被称为 LLC.LLC 位于处理器核心和主存之间,用于存储频繁访问的数据,以加快处理器对数据的访问速度。
NUMA系统
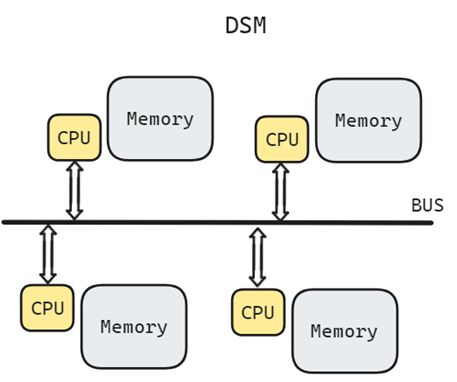
NUMA体系结构中多了Node的概念,这个概念其实是用来解决core的分组的问题。每个node有自己的内部CPU,总线和内存,同时还可以访问其他node内的内存,NUMA的最大的优势就是可以方便的增加CPU的数量。NUMA系统中,内存的划分是根据物理内存模块和内存控制器的布局来确定的
在Intel x86平台上:
- 本地内存指 CPU 可以经过Uncore部件里的iMC访问到的内存。
- 远程内存(Remote Memory),则需要经过QPI的链路到该内存所在的CPU的iMC来访问。
与本地内存一样,所谓本地IO资源,就是CPU可以经过Uncore部件里的PCIe Root Complex直接访问到的IO资源。如果是非本地IO资源,则需要经过QPI链路到该IO资源所属的CPU,再通过该CPU PCIe Root Complex访问。如果同一个NUMA Node内的CPU和内存和另外一个NUMA Node的IO资源发生互操作,因为要跨越QPI链路, 会存在额外的访问延迟问题
曾经在Intel IvyBridge的NUMA平台上做的内存访问性能测试显示,远程内存访问的延时时本地内存的一倍。
一个NUMA Node内部是由一个物理CPU和它所有的本地内存, 本地IO资源组成的。通常一个 Socket 有一个 Node,也有可能一个 Socket 有多个 Node.
root@kamilu:~$ sudo apt install numactl
root@kamilu:~$ numactl -H
available: 3 nodes (0-2)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 24 25 26 27 28 29 30 31 32 33 34 35
node 0 size: 31819 MB
node 0 free: 10283 MB
node 1 cpus: 12 13 14 15 16 17 18 19 20 21 22 23 36 37 38 39 40 41 42 43 44 45 46 47
node 1 size: 32193 MB
node 1 free: 26965 MB
node 2 cpus:
node 2 size: 16384 MB
node 2 free: 16375 MB
node distances:
node 0 1 2
0: 10 21 24
1: 21 10 14
2: 24 14 10可以使用 numactl 来控制运行该程序的 CPU 和内存节点, 例如指定程序的内存只能使用 NUMA 节点 1 的内存,而 CPU 则绑定在 NUMA 节点 0 上可以使用
numactl --membind=1 --cpunodebind=0 ./a与 --membind 参数严格地限制内存分配在指定的节点上不同, 当使用 --preferred 参数时,操作系统将优先尝试在指定的 NUMA 节点上分配内存,但如果该节点的内存不足,它会在其他节点上分配内存.
numactl --preferred=1 ./my_programNUMA互联
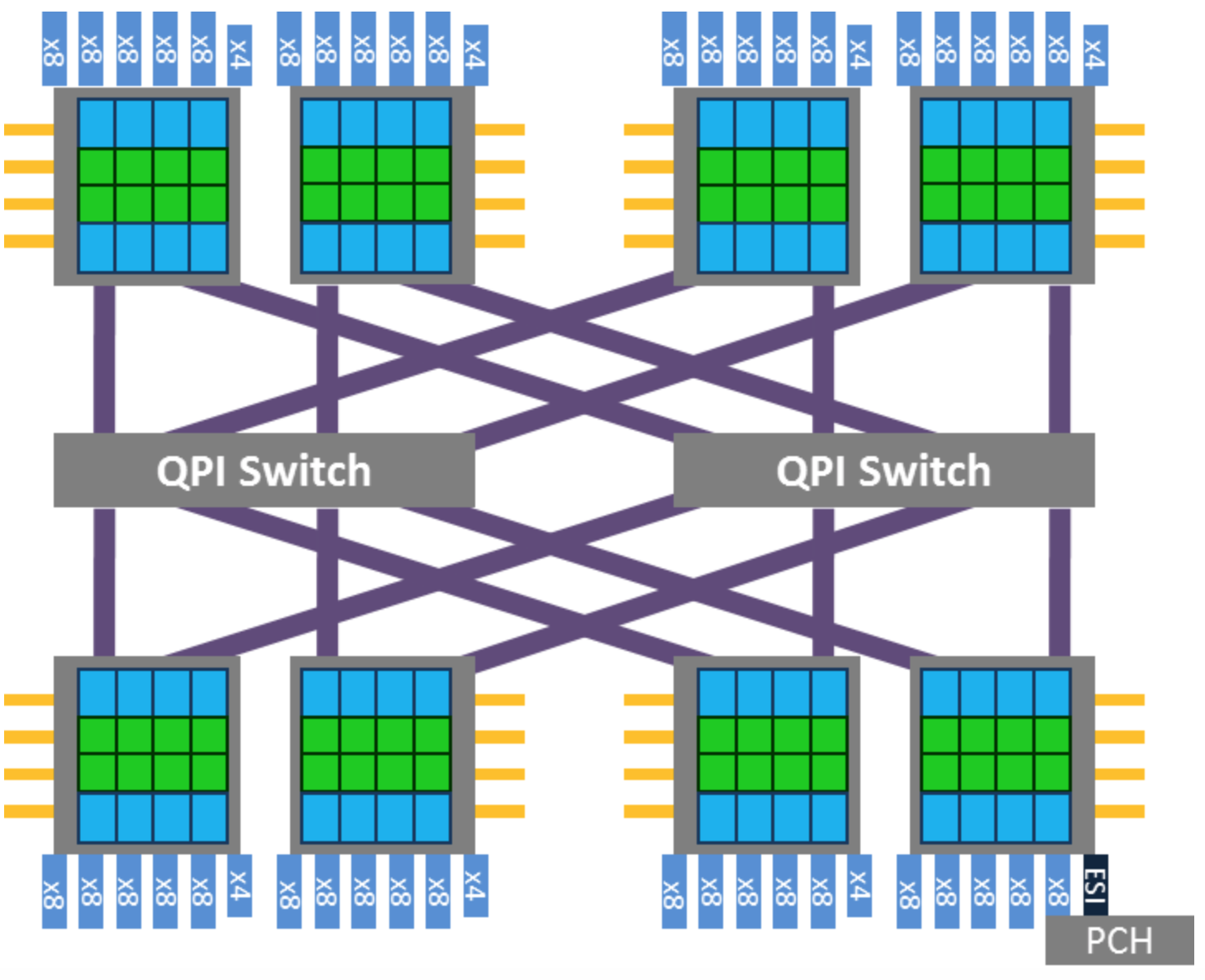
在Intel x86上,NUMA Node之间的互联是通过 QPI(QuickPath Interconnect) Link的。CPU的Uncore部分有QPI的控制器来控制CPU到QPI的数据访问, 下图就是一个利用 QPI Switch 互联的 8 NUMA Node 的 x86 系统
NUMA亲和性
NUMA Affinity(亲和性)是和NUMA Hierarchy(层级结构)直接相关的。对系统软件来说, 以下两个概念至关重要
- CPU NUMA Affinity
CPU NUMA的亲和性是指从CPU角度看,哪些内存访问更快,有更低的延迟。如前所述, 和该CPU直接相连的本地内存是更快的。操作系统如果可以根据任务所在CPU去分配本地内存, 就是基于CPU NUMA亲和性的考虑。因此,CPU NUMA亲和性就是要尽量让任务运行在本地的NUMA Node里。
- Device NUMA Affinity
设备NUMA亲和性是指从PCIe外设的角度看,如果和CPU和内存相关的IO活动都发生在外设所属的NUMA Node, 将会有更低延迟。这里有两种设备NUMA亲和性的问题
- DMA Buffer NUMA Affinity
大部分PCIe设备支持DMA功能的。也就是说,设备可以直接把数据写入到位于内存中的DMA缓冲区。显然,如果DMA缓冲区在PCIe外设所属的NUMA Node里分配,那么将会有最低的延迟。否则,外设的DMA操作要跨越QPI链接去读写另外一个NUMA Node里的DMA缓冲区。因此,操作系统如果可以根据PCIe设备所属的NUMA node分配DMA缓冲区, 将会有最好的DMA操作的性能。
- Interrupt NUMA Affinity
当设备完成DMA操作后,它会发送一个中断信号给CPU,通知CPU需要处理相关的中断处理例程(ISR),这个例程负责读写DMA缓冲区的数据。ISR在某些情况下会触发下半部机制(SoftIRQ),以便进入与协议栈(如网络,存储)相关的代码路径,以传输数据。对大部分操作系统来说,硬件中断(HardIRQ)和下半部机制的代码在同一个CPU上发生。因此,如果操作系统能够将设备的硬件中断绑定到与操作系统自身所属的NUMA节点相对应的处理器上,那么中断处理函数和协议栈代码对DMA缓冲区的读写操作将会具有更低的延迟。这样做可以减少处理器间的通信延迟,提高系统性能。
- DMA Buffer NUMA Affinity
中断处理例程(Interrupt Service Routine, ISR)用于响应硬件中断事件,尽快地处理中断并进行必要的操作。当一个设备或外部事件触发了一个硬件中断,CPU会中断当前执行的任务,并跳转到相应的ISR来处理中断
半部机制(SoftIRQ)是一种延迟处理机制,用于处理与中断相关的一些非关键,耗时较长的任务。SoftIRQ不是由硬件中断触发,而是在上下文切换,网络数据包处理,定时器等事件发生时,由内核调度执行的
Firmware接口
由于NUMA的亲和性对应用的性能非常重要,那么硬件平台就需要给操作系统提供接口机制来感知硬件的NUMA层级结构。在x86平台,ACPI规范提供了以下接口来让操作系统来检测系统的NUMA层级结构。
ACPI(Advanced Configuration and Power Interface)是一种开放标准,旨在为操作系统和硬件之间提供统一的接口,以实现高级配置和电源管理功能, 包括ACPI表, 系统电源管理, 系统配置和资源管理, 事件处理, 系统配置表和命名空间。ACPI规范的广泛应用使得不同的操作系统和硬件厂商能够以一致的方式进行交互,提高了系统的兼容性和可移植性
ACPI 5.0a规范的第17章是有关NUMA的章节。ACPI规范里,NUMA Node被第9章定义的Module Device所描述。ACPI规范里用Proximity Domain(接近性域)对NUMA Node做了抽象,两者的概念大多时候等同。
- SRAT(System Resource Affinity Table) 系统资源关联表, 用于优化资源分配和调度
主要描述了系统boot时的CPU和内存都属于哪个Proximity Domain(NUMA Node). 这个表格里的信息时静态的,
如果是启动后热插拔,需要用OSPM的_PXM方法去获得相关信息。
- SLIT(System Locality Information Table) 系统局部性信息表, 用于优化任务调度和资源分配
提供CPU和内存之间的位置远近信息.在SRAT表格里,只能告诉给定的CPU和内存是否在一个NUMA Node. 对某个CPU来说,不在本NUMA Node里的内存,即远程内存们是否都是一样的访问延迟取决于NUMA的拓扑有多复杂(QPI的跳数). 总之,对于不能简单用远近来描述的NUMA系统(QPI存在0,1,2等不同跳数), 需要SLIT表格给出进一步的说明。
也是静态表格,热插拔需要使用OSPM的_SLI方法。
- DSDT(Differentiated System Description Table) 不同化系统描述表, 用于正确识别和管理硬件和设备
从 Device NUMA角度看,这个表格给出了系统boot时的外设都属于哪个Proximity Domain(NUMA Node).
node 初始化
下面我们结合 linux 代码来看一下上面提到的 numa node 初始化的过程, 从几条启动日志开始说起
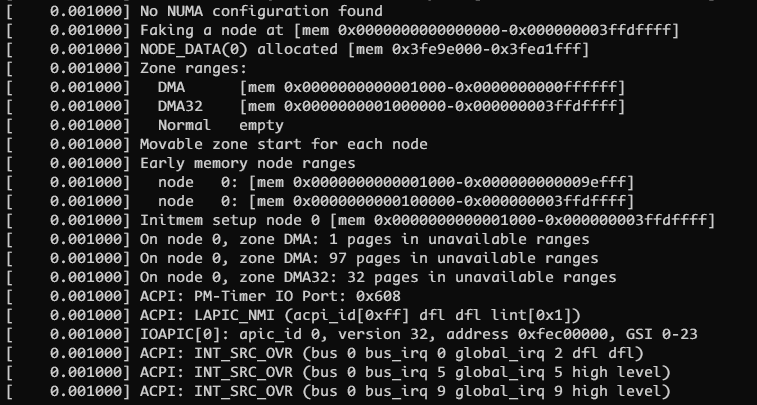
通过第一条日志顺藤摸瓜可以找到如下的函数
/**
* dummy_numa_init - Fallback dummy NUMA init
*
* Used if there's no underlying NUMA architecture, NUMA initialization
* fails, or NUMA is disabled on the command line.
*
* Must online at least one node and add memory blocks that cover all
* allowed memory. This function must not fail.
*/
// arch/x86/mm/numa.c
static int __init dummy_numa_init(void)
{
printk(KERN_INFO "%s\n",
numa_off ? "NUMA turned off" : "No NUMA configuration found");
/* max_pfn是e820探测到的最大物理内存页,其初始化是max_pfn = e820__end_of_ram_pfn() */
printk(KERN_INFO "Faking a node at [mem %#018Lx-%#018Lx]\n",
0LLU, PFN_PHYS(max_pfn) - 1);
/* 一个nodemask_t是 位图, 最多支持MAX_NUMNODES个node
* 这里将node 0置位
*/
node_set(0, numa_nodes_parsed);
/* 将node 0的起始和结束地址记录起来 */
numa_add_memblk(0, 0, PFN_PHYS(max_pfn));
return 0;
}
int __init numa_add_memblk(int nid, u64 start, u64 end)
{
return numa_add_memblk_to(nid, start, end, &numa_meminfo);
}
// arch/x86/mm/numa_internal.h
struct numa_meminfo {
int nr_blks;
struct numa_memblk blk[NR_NODE_MEMBLKS];
};
struct numa_memblk {
u64 start;
u64 end;
int nid;
};代码和注释写的很清晰, 当没有 NUMA 架构或者 NUMA 架构被禁止的时候, Linux为了适配两者,将 UMA "假装"成一种NUMA架构,也就只有一个node 0节点,该节点包括所有物理内存。numa_nodes_parsed 为 NUMA 节点的位图, 每一个bit代表一个node,node_set是将一个node设置为"在线".
numa_add_memblk 就是将一个 node 加入到 numa_meminfo, 并设置内存地址的范围。numa_meminfo, numa_memblk 的结构体也比较清晰
PFN_PHYS(max_pfn) 宏用于获取探测到的最大物理内存页的范围
numa_add_memblk_to 逻辑也比较简单, 就是先做一些配置上的判断, 然后结构体对应元素赋值
static int __init numa_add_memblk_to(int nid, u64 start, u64 end,
struct numa_meminfo *mi)
{
/* ignore zero length blks */
if (start == end)
return 0;
/* whine about and ignore invalid blks */
if (start > end || nid < 0 || nid >= MAX_NUMNODES) {
pr_warn("Warning: invalid memblk node %d [mem %#010Lx-%#010Lx]\n",
nid, start, end - 1);
return 0;
}
if (mi->nr_blks >= NR_NODE_MEMBLKS) {
pr_err("too many memblk ranges\n");
return -EINVAL;
}
mi->blk[mi->nr_blks].start = start;
mi->blk[mi->nr_blks].end = end;
mi->blk[mi->nr_blks].nid = nid;
mi->nr_blks++;
return 0;
}整个系统的函数调用栈如下, numa_init 中也可以看出, 无论是否有 NUMA, 区别只是对所传递的函数指针的调用的差别而已。当没有 numa 时进入 dummy_numa_init 完成初始化
// arch/x86/kernel/setup.c | setup_arch
// arch/x86/mm/numa_64.c | initmem_init
// arch/x86/mm/numa.c | x86_numa_init
// arch/x86/mm/numa.c | numa_init
void __init x86_numa_init(void)
{
if (!numa_off) {
#ifdef CONFIG_ACPI_NUMA
if (!numa_init(x86_acpi_numa_init))
return;
#endif
#ifdef CONFIG_AMD_NUMA
if (!numa_init(amd_numa_init))
return;
#endif
}
numa_init(dummy_numa_init);
}NUMA 启动
如果以前文 调试内核 中的参数启动那么就是一个非常简单的系统, 如果以一个比较复杂的参数启动 qemu
taskset -c 0-15 $(QEMU) -name guest=vm0 \
-machine pc \
-m 64G \
-overcommit mem-lock=off \
-smp 16 \
-object memory-backend-ram,size=16G,host-nodes=0,policy=bind,prealloc=no,id=m0 \
-object memory-backend-ram,size=16G,host-nodes=1,policy=bind,prealloc=no,id=m1 \
-object memory-backend-ram,size=16G,host-nodes=2,policy=bind,prealloc=no,id=m2 \
-object memory-backend-ram,size=16G,host-nodes=3,policy=bind,prealloc=no,id=m3 \
-numa node,nodeid=0,memdev=m0,cpus=0-7 \
-numa node,nodeid=1,memdev=m1,cpus=8-15 \
-numa node,nodeid=2,memdev=m2 \
-numa node,nodeid=3,memdev=m3 \
-numa dist,src=0,dst=0,val=10 \
-numa dist,src=0,dst=1,val=21 \
-numa dist,src=0,dst=2,val=24 \
-numa dist,src=0,dst=3,val=24 \
-numa dist,src=1,dst=0,val=21 \
-numa dist,src=1,dst=1,val=10 \
-numa dist,src=1,dst=2,val=14 \
-numa dist,src=1,dst=3,val=14 \
-numa dist,src=2,dst=0,val=24 \
-numa dist,src=2,dst=1,val=14 \
-numa dist,src=2,dst=2,val=10 \
-numa dist,src=2,dst=3,val=16 \
-numa dist,src=3,dst=0,val=24 \
-numa dist,src=3,dst=1,val=14 \
-numa dist,src=3,dst=2,val=16 \
-numa dist,src=3,dst=3,val=10 \
-uuid 9bc02bdb-58b3-4bb0-b00e-313bdae0ac81 \
-device ich9-usb-ehci1,id=usb,bus=pci.0,addr=0x5.0x7 \
-device virtio-serial-pci,id=virtio-serial0,bus=pci.0,addr=0x6 \
-drive file=$(DISK),format=raw,id=drive-ide0-0-0,if=none \
-device ide-hd,bus=ide.0,unit=0,drive=drive-ide0-0-0,id=ide0-0-0,bootindex=1 \
-drive if=none,id=drive-ide0-0-1,readonly=on \
-device ide-cd,bus=ide.0,unit=1,drive=drive-ide0-0-1,id=ide0-0-1 \
-device virtio-balloon-pci,id=balloon0,bus=pci.0,addr=0x7 \
-netdev user,id=ndev.0,hostfwd=tcp::5555-:22 \
-device e1000,netdev=ndev.0 \
-nographic \
-kernel $(BZIMAGE) \
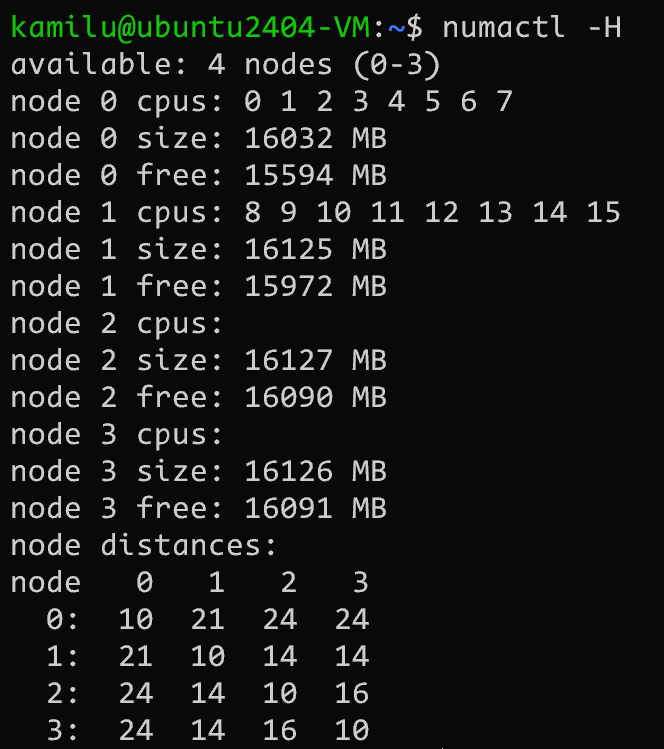
-append "root=/dev/sda2 console=ttyS0 quiet nokaslr"NOTE上述参数表示创建了 4 个 numa node, 每个 node 16 GB 内存, 2 个 node 有 cpu.
分配了 16 个物理机的 CPU 核心, 分配个 qemu, 2 个有 cpu 的 node 每个分到 8 个核心
手动定义了节点之间的 numa distance
我们可以得到如下所示的 numa 架构
当有 numa 架构时(CONFIG_ACPI_NUMA)则会进入 x86_acpi_numa_init 处理
void __init x86_numa_init(void)
{
if (!numa_off) {
#ifdef CONFIG_ACPI_NUMA
if (!numa_init(x86_acpi_numa_init))
return;
#endif
#ifdef CONFIG_AMD_NUMA
if (!numa_init(amd_numa_init))
return;
#endif
}
numa_init(dummy_numa_init);
}numa_init 中首先为每一个 numa node 分配一个编号, 然后将一个记录全局 numa distance 信息的数组清空, 调用函数指针初始化
static int numa_distance_cnt;
static u8 *numa_distance;
static int __init numa_init(int (*init_func)(void))
{
int i;
int ret;
// 为每一个 node 分配一个编号 0 1 ...
for (i = 0; i < MAX_LOCAL_APIC; i++)
set_apicid_to_node(i, NUMA_NO_NODE);
// ...
// 设置 numa_distance[] -> 0
numa_reset_distance();
ret = init_func();
if (ret < 0)
return ret;
// ...
}我们重点关注一下这些节点是如何识别 id 并且如何计算距离的, 其中确定距离的函数 numa_set_distance 调用如下
NOTE上文我们介绍了 SRAT SLIT 的初始化, 这里就是 SLIT 对于 numa node 距离的初始化
// x86_acpi_numa_init [arch/x86/mm/srat.c]
// └─acpi_numa_init [drivers/acpi/numa/srat.c]
// └─acpi_table_parse [drivers/acpi/tables.c]
// └─acpi_parse_slit [drivers/acpi/numa/srat.c]
// └─acpi_numa_slit_init [drivers/acpi/numa/srat.c]
void __init acpi_numa_slit_init(struct acpi_table_slit *slit)
{
int i, j;
for (i = 0; i < slit->locality_count; i++) {
const int from_node = pxm_to_node(i);
if (from_node == NUMA_NO_NODE)
continue;
for (j = 0; j < slit->locality_count; j++) {
const int to_node = pxm_to_node(j);
if (to_node == NUMA_NO_NODE)
continue;
numa_set_distance(from_node, to_node,
slit->entry[slit->locality_count * i + j]);
}
}
}其中这里的 slit->entry 数组就是我们通过 qemu 传入的参数, 这个参数会在内核启动过程中获取到
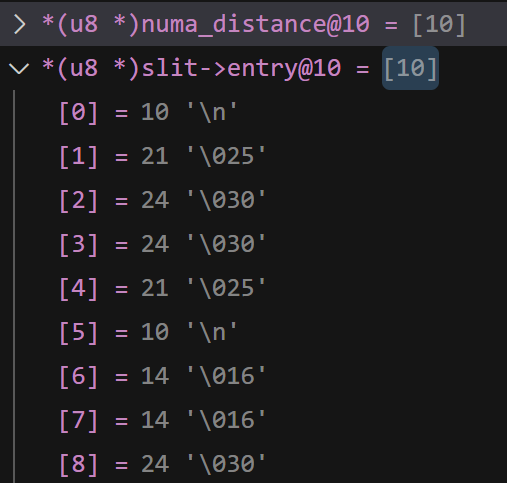
如果没有提供 distance 参数就会调用 numa_alloc_distance 默认初始化
void __init numa_set_distance(int from, int to, int distance)
{
if (!numa_distance && numa_alloc_distance() < 0)
return;
numa_distance[from * numa_distance_cnt + to] = distance;
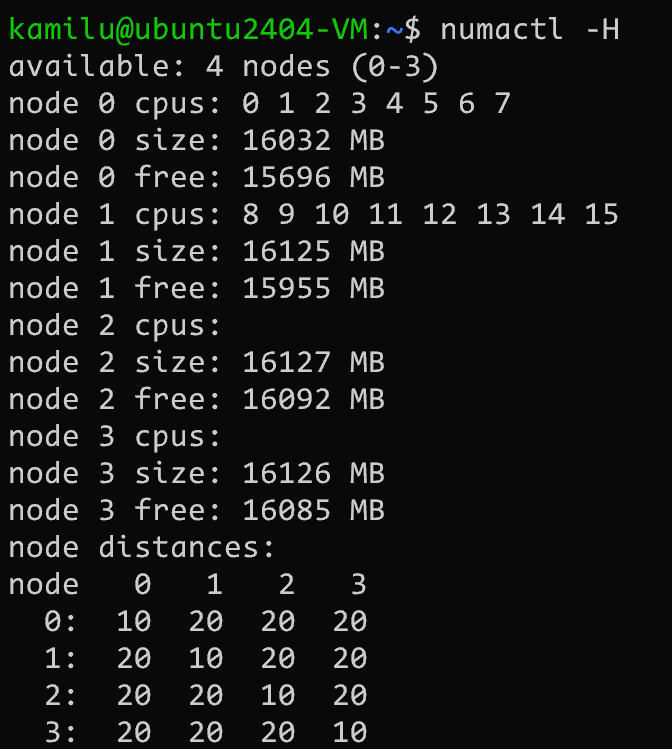
}numa_alloc_distance 中只是简单的初始化了这个数组(一维数组模拟二维数组), 将同节点之间的距离设置为 10, 不同节点距离为 20
10/20 是 ACPI 标准规定
#define LOCAL_DISTANCE 10
#define REMOTE_DISTANCE 20
static int __init numa_alloc_distance(void)
{
numa_distance = __va(phys);
numa_distance_cnt = cnt;
/* fill with the default distances */
for (i = 0; i < cnt; i++)
for (j = 0; j < cnt; j++)
numa_distance[i * cnt + j] = i == j ?
LOCAL_DISTANCE : REMOTE_DISTANCE;
printk(KERN_DEBUG "NUMA: Initialized distance table, cnt=%d\n", cnt);
return 0;
}
pglist_data
Node是内存管理最顶层的结构,在NUMA架构下,CPU平均划分为多个Node,每个Node有自己的内存控制器及内存插槽。CPU访问自己Node上的内存时速度快,而访问其他CPU所关联Node的内存的速度比较慢。而UMA则被当做只有一个Node的NUMA系统。
内核中使用 struct pglist_data 来描述一个Node节点,我们看下主要的一些变量,
/*
* On NUMA machines, each NUMA node would have a pg_data_t to describe
* it's memory layout. On UMA machines there is a single pglist_data which
* describes the whole memory.
*/
typedef struct pglist_data {
//当前节点中包含的zone数组,如ZONE_DMA,ZONE_DMA32,ZONE_NORMAL
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
//当前节点中不同内存域zone的数量
int nr_zones;
...
unsigned long node_start_pfn; //当前节点的页帧的起始值
unsigned long node_present_pages; //当前节点可使用的page数量
unsigned long node_spanned_pages; //包含空洞内存的内存总长度
int node_id; //节点编号
wait_queue_head_t kswapd_wait; //kswapd进程的等待队列
wait_queue_head_t pfmemalloc_wait; //直接内存回收过程中的进程等待队列
struct task_struct *kswapd; //指向该结点的kswapd进程的task_struct
int kswapd_order; //kswap回收页面大小
enum zone_type kswapd_classzone_idx; //kswap扫描的内存域范围
...
//每个节点的保留内存
unsigned long totalreserve_pages;
//zone reclaim becomes active if more unmapped pages exist.
unsigned long min_unmapped_pages;
//当前node中可回收slab页面阈值,超过该值才会回收该node内存
unsigned long min_slab_pages;
...
/* Fields commonly accessed by the page reclaim scanner */
//LRU链表管理结构
struct lruvec lruvec;
...
} pg_data_t;pglist_data 的结构体字段可以分为三个部分:
- 内存管理域,比如包括的zone类型,以及该Node管理的内存范围等。
- kswap内存回收相关
- LRU链表相关
swap 和 LRU 我们在其他部分进行详细介绍, 这里不做展开
zone
在 Linux 内核中,内存分为不同的 ZONE(内存区),用于管理和分配物理内存。每个物理内存节点(NUMA 节点)都有一组 ZONE.
| ZONE 类型 | 用途 | 范围 | 特点 |
|---|---|---|---|
| ZONE_DMA | 提供适用于早期 DMA 设备的内存。 | 0 - 16 MB | 为低地址物理内存保留,现代系统较少使用,保留兼容性。 |
| ZONE_DMA32(如果存在) | 为 32 位设备提供可直接访问的内存。 | 0 - 4 GB | 支持需要 32 位地址的设备,常见于 x86_64 等 64 位架构。 |
| ZONE_NORMAL | 提供可直接映射到内核虚拟地址空间的内存。 | 16MB~896MB | 用于核心数据结构(如页表、内核栈),内核直接管理和访问。 |
| ZONE_HIGHMEM(仅 32 位架构) | 管理超出内核直接映射范围的高端内存(仅 32 位架构). | 4 GB 以上 | 需要页表映射访问,在 64 位架构中由 ZONE_NORMAL 管理,无需此 ZONE. |
| ZONE_MOVABLE | 分配可移动内存(如用户空间内存、页面缓存). | 动态调整 | 支持内存热插拔和页迁移,提高内存管理灵活性,适用于 NUMA 和大规模服务器。 |
| ZONE_DEVICE(如果存在) | 管理特殊设备内存(如 PMEM、GPU 内存). | 依硬件特定 | 支持新型硬件(如 CXL 和 HMM),不可用于普通分配器,适合设备专用内存。 |
因此在x86_64的机器上, 去掉 32 位相关的 ZONE 后主要有以下几种Zone类型:
$ cat /proc/zoneinfo | grep -w zone
Node 0, zone DMA
Node 0, zone DMA32
Node 0, zone Normal
Node 0, zone Movable
Node 0, zone Device内存域Zone用 struct zone 描述
struct zone {
/* Read-mostly fields */
//每个zone的min、low、high水位值
unsigned long watermark[NR_WMARK];
unsigned long nr_reserved_highatomic;
//每个zone的预留内存,有些进程只能使用某些低地址的zone空间,但是在极端情况下
//有些进程本来是可以使用高地址zone,但是可能此时系统内存刚好被占用,就会去
//使用这些低地址zone的内存,导致后续一些进程即使高地址zone还有空闲内存,但还是
//无法获得内存。因此需要为每个zone预留一部分内存,保证跨zone内存分配有上限
//预留的值可通过/proc/sys/vm/lowmem_reserve_ratio设置
long lowmem_reserve[MAX_NR_ZONES];
int node;
struct pglist_data *zone_pgdat; //指向所属node节点
struct per_cpu_pageset __percpu *pageset; //每CPU保留一些页面,避免自旋锁冲突
unsigned long zone_start_pfn; //该内存域起始页帧地址
unsigned long managed_pages; //该zone中被伙伴系统管理的页面数量
unsigned long spanned_pages; //该zone包含的总页数,包含空洞
unsigned long present_pages; //该zone包含的总页数,不包含空洞
//内存域名字,如"DMA", "NROMAL"
const char *name;
...
//页面使用状态的信息,用于伙伴系统的,每个元素对应不同阶page大小
//目前系统上有11种不同大小的页面,从2^0 - 2^10,即4k-4M大小的页面
struct free_area free_area[MAX_ORDER];
/* zone flags, see below */
unsigned long flags;
...
} ____cacheline_internodealigned_in_smp;- 第一部分为zone的水位值watermark,包括MIN、LOW、HIGH三个水位, 用于内存回收压力的判断
- 第二部分就是内存域的描述,比如管理的内存范围以及page数量
- 第三部分就是free_area,用于管理伙伴系统上11个不同大小的page页面
查看系统当前各个node的ZONE管理区
cat /proc/zoneinfo |grep -E "zone| free|managed"watermark(水位线)
系统内存的每个node上都有不同的zone,每个zone的内存都有对应的水位线,当内存使用达到某个阈值时就会触发相应动作,比如直接回收内存,或者启动kswap进行回收内存。我们可以通过查看 /proc/zoneinfo 来确认每个zone的min、low、high水位值。
~$ cat /proc/zoneinfo | grep -E "Node|min|low|high "
Node 1, zone Normal
min 15328
low 147442
high 279556
Node 3, zone Normal
min 1916
low 18429
high 34942水位线的值由 /proc/sys/vm/min_free_kbytes 参数控制
int __meminit init_per_zone_wmark_min(void)
{
unsigned long lowmem_kbytes;
int new_min_free_kbytes;
//获取系统空闲内存值,扣除每个zone的high水位值后的总和
lowmem_kbytes = nr_free_buffer_pages() * (PAGE_SIZE >> 10);
//根据上述公式计算new_min_free_kbytes值
new_min_free_kbytes = int_sqrt(lowmem_kbytes * 16);
if (new_min_free_kbytes > user_min_free_kbytes) {
min_free_kbytes = new_min_free_kbytes;
//最小128k
if (min_free_kbytes < 128)
min_free_kbytes = 128;
//最大65M,但是这只是系统初始化的值,可以通过proc接口设置范围外的值
if (min_free_kbytes > 65536)
min_free_kbytes = 65536;
} else {
pr_warn("min_free_kbytes is not updated to %d because user defined value %d is preferred\n",
new_min_free_kbytes, user_min_free_kbytes);
}
//设置每个zone的min low high水位值
setup_per_zone_wmarks();
refresh_zone_stat_thresholds();
//设置每个zone为其他zone的保留内存
setup_per_zone_lowmem_reserve();
setup_per_zone_inactive_ratio();
return 0;
}libnuma
- default:仅在本地节点分配,即程序运行节点
- bind:仅在指定节点上分配
- interleavel:在所有节点交叉分配
- preferred:先在指定节点上分配,失败则可在其他节点上分配
参考
- 十年后数据库还是不敢拥抱NUMA: 好文