buddy
buddy system 概述
Linux的Buddy内存分配算法是一种用于管理物理内存的分配算法,旨在解决内存分配和释放的碎片问题, 该算法被广泛应用于Linux操作系统中. 内存中有一些是被内核代码占用,还有一些是被特殊用途所保留,那么剩余的空闲内存都会交给内核内存管理系统来进行统一管理和分配
linux早期版本(比如0.11)管理的方式比较简单粗暴,直接用bitmap的思路标记物理页是否被使用,这样做带来最直接的问题:内存碎片化, 而且bitmap也不能直观的快速寻址连续空闲的内存,每次都要从头开始遍历查找
在内核分配内存时,必须记录页帧的已分配或空闲状态,以免两个进程使用同样的内存区域.由于内存分配和释放非常频繁,内核还必须保证相关操作尽快完成.内核可以只分配完整的页帧.将内存划分为更小的部分的工作,则委托给用户空间中的标准库.标准库将来源于内核的页帧拆分为小的区域,并为进程分配内存.
内核中很多时候要求分配连续页.为快速检测内存中的连续区域,内核采用了一种古老而历经检验的技术: 伙伴系统(Buddy system)
系统中的空闲内存块总是两两分组,每组中的两个内存块称作伙伴.伙伴的分配可以是彼此独立的.但如果两个伙伴都是空闲的,内核会将其合并为一个更大的内存块,作为下一层次上某个内存块的伙伴. 众所周知进程的内存分配是以虚拟页 4KB 为最小单位分配的(即使会出现内部碎片)
如下图所示, 大小相等且相邻的两个分组是彼此的Buddy, 当 n=1 时,组的页面数量是2, 此时 Group 1 与 Group 2 互为Buddy, 但Group 1 与 Group 3 由于隔开了,就不是Buddy. 如果 Group1 与 Group 2 都被释放回来后,系统就将会对两个Buddy进行合并,形成一个数量更大的组Group 5, 这也是两个Buddy必须相邻的原因
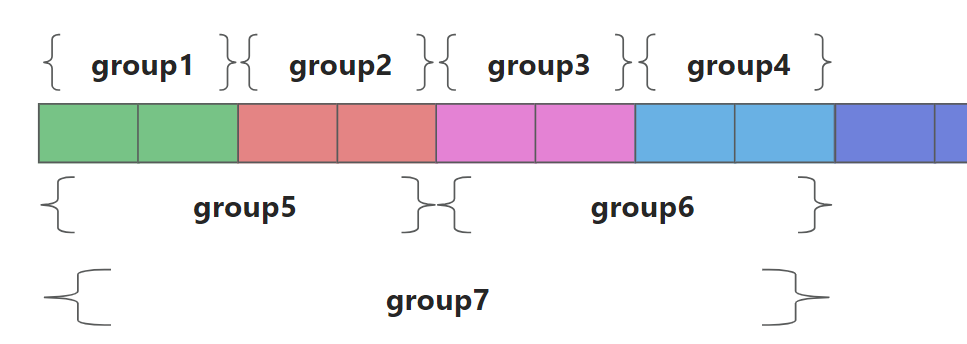
下图展示一个 4 级的 buddy, 的分配和释放过程. 其中最小的 buddy 块为 4KB
- 最初的情况.
- 程序 A 请求内存 3 KB ,阶数 0.
- 没有可用的 0 阶块,因此分割 4 阶块,创建两个 3 阶块.
- 仍然没有可用的 0 阶块,因此第一个 3 阶块被分割,创建两个 2 阶块.
- 仍然没有可用的 0 阶块,因此第一个 2 阶块被分割,创建两个 1 阶块.
- 仍然没有可用的 0 阶块,因此第一个 1 阶块被分割,创建两个 0 阶块.
- 现在有一个 0 阶区块可用,因此它被分配给 A.
- 程序 B 请求内存 6 K,顺序 1.顺序 1 块可用,因此将其分配给 B.
- 程序 C 请求内存 3 K,阶数 0.阶数 0 块可用,因此将其分配给 C.
- 程序 D 请求内存 6 K,顺序 1.
- 没有可用的 1 阶块,因此分割 2 阶块,创建两个 1 阶块.
- 现在有一个 1 阶块可用,因此它被分配给 D.
- 程序 B 释放其内存,释放一阶 1 块.
- 程序D释放其内存.
- 释放一订单 1 块.
- 由于新释放的块的伙伴块也空闲,因此两者被合并为一个2阶块.
- 程序 A 释放其内存,释放一个 0 阶块.
- 程序C释放其内存.
- 释放 1 个 0 阶块.
- 由于新释放的块的伙伴块也空闲,因此两者被合并为一个1阶块.
- 由于新形成的 1 阶区块的伙伴区块也空闲,因此两者合并为一个 2 阶区块.
- 由于新形成的2阶区块的伙伴区块也是空闲的,因此两者被合并为一个3阶区块.
- 由于新形成的 3 阶区块的伙伴区块也空闲,因此两者合并为一个 4 阶区块.
在应用程序释放内存时,内核可以直接检查地址,来判断是否能够创建一组伙伴,并合并为一个更大的内存块放回到伙伴列表中,这刚好是内存块分裂的逆过程.这提高了较大内存块可用的可能性
zone
在Linux的物理内存模型中,一个内存node按照属性被划分为了多个zones,比如ZONE_DMA和ZONE_NORMAL. 虽然内存访问的最小单位是byte或者word,但MMU是以page为单位来查找页表的,page也就成了Linux中内存管理的重要单位.包括换出(swap out)、回收(relcaim)、映射等操作,都是以page为粒度的. 由于虚拟内存和页表转换的设计, 使得在虚拟内存中需要连续的页面在物理内存中不必连续, 但是我们仍然希望可以快速的找到一组连续的可用页面以实现快速的分配和回收
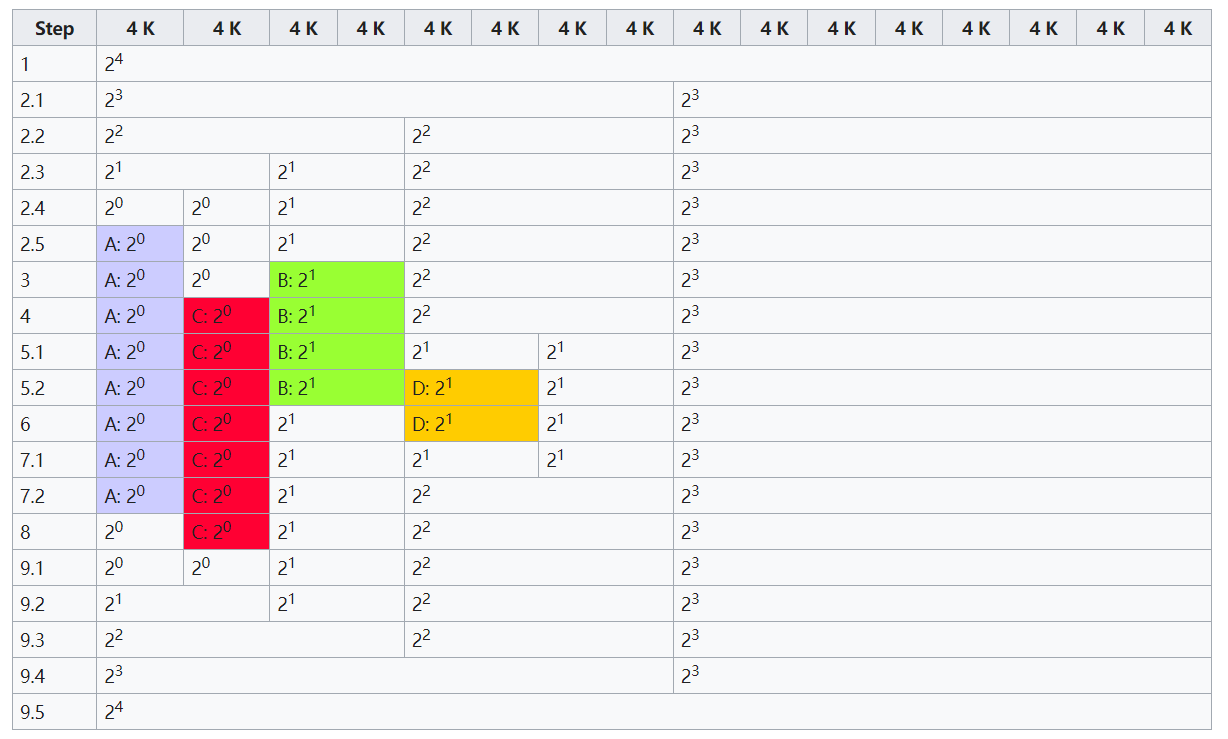
linux 中 buddy 的最大数量为定义在 include/linux/mmzone.h 中的 MAX_ORDER 决定, 默认值为 11, 也就是把所有的空闲页框分组为11个块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续页框的页框块.最大可以申请1024个连续页框,对应4MB大小的连续内存,每个页框块的第一个页框的物理地址是该块大小的整数倍, 如下图所示.
数组 free_area 每个索引 i 存放的就是大小为 2^i 页面数量的分组,这样可以提升Buddy System分配内存时查找分组的效率.
以上图为例, 假设现在要分配一个 9KB 的页面, 首先计算满足条件的 2^i, 所以至少分配一个 16KB 的空间, 也就是 i=2, free_area[2] 没有对应的链表节点, 所以从 i=3 的链表取第一个节点分为两部分, 一部分分配, 一部分存于 i=2 处的链表
值得注意的是上图中 2^3 画成一个大块只是为了说明, 实际上 buddy system 对于物理内存的管理是以 page(4KB) 为单位的, 所以一个大块中存了 8 个 page
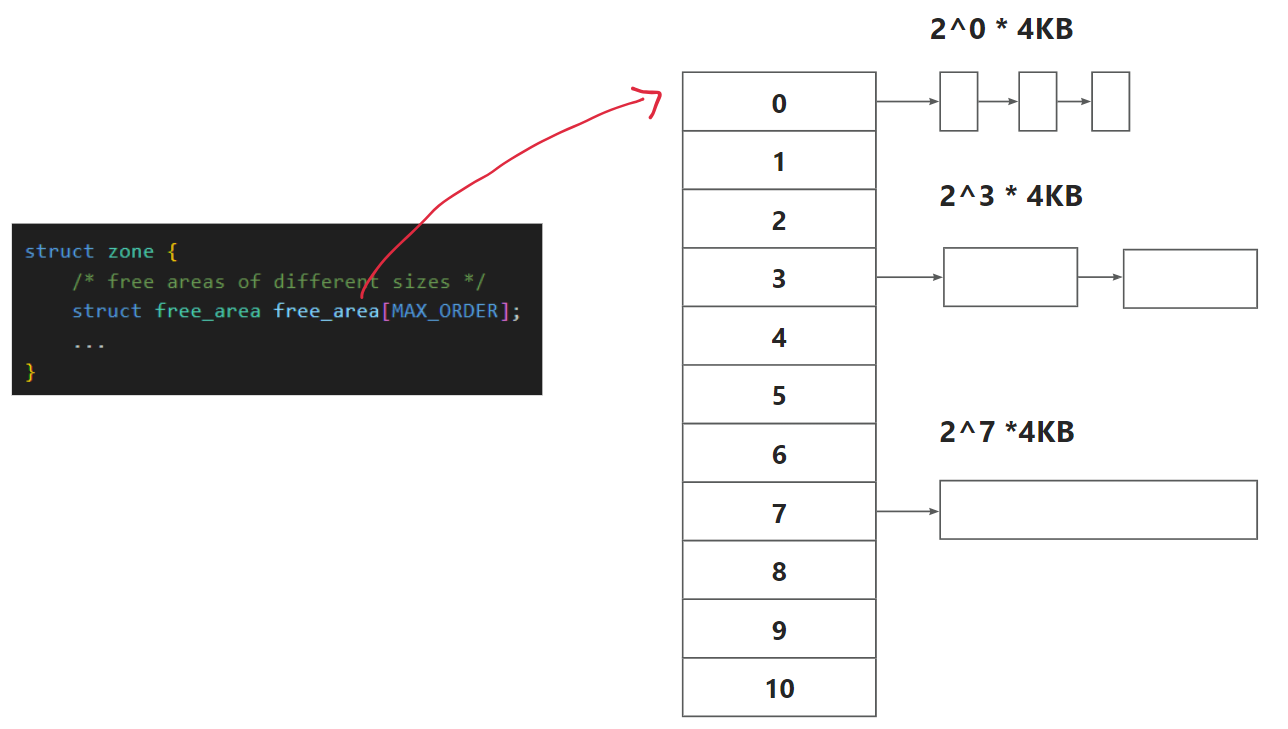
zone 和 free_area 的结构体定义核心部分如下所示. 但需要注意的是每个"free_area"包含不只一个free list,而是一个free list数组(形成二维数组),包含了多种"migrate type",以便将具有相同「迁移类型」的page frame尽可能地分组(同一类型的所有order的free list构成一组"pageblocks")
#define MAX_ORDER 11
struct zone {
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
...
}
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
// 这是一个双向链表, 图中没有画出来
struct list_head {
struct list_head *next, *prev;
};free_area 中的空闲分组按照 MIGRATE_TYPES 进行了分组,每种类型都保存在一个双向链表中. MIGRATE_TYPES (默认为4) 用于记录当前内存块的属性, 是否可移动,
这样的设计是为了使包括 memory compaction 在内的一些操作更加高效
enum migratetype {
MIGRATE_UNMOVABLE, // page frame不可移动
MIGRATE_MOVABLE, // page frame可移动
MIGRATE_RECLAIMABLE, // page frame可回收迁移
MIGRATE_PCPTYPES, /* the number of types on the pcp lists */
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,
#ifdef CONFIG_CMA
/*
* MIGRATE_CMA migration type is designed to mimic the way
* ZONE_MOVABLE works. Only movable pages can be allocated
* from MIGRATE_CMA pageblocks and page allocator never
* implicitly change migration type of MIGRATE_CMA pageblock.
*
* The way to use it is to change migratetype of a range of
* pageblocks to MIGRATE_CMA which can be done by
* __free_pageblock_cma() function.
*/
MIGRATE_CMA,
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE, /* can't allocate from here */
#endif
MIGRATE_TYPES
};所以实际情况上图 free_area 画的并不准确, 准确来说如下图所示
分配内存时还需要很多标记类参数,例如指定目标 zone (是从 DMA 请求内存还是 NORMAL)、分配到的内存是否要全部置零、如果内存不足,是否可以触发内存回收机制等等,这些标记都定义在 include/linux/gfp.h 中
// include/linux/gfp.h
// include/linux/gfp_types.h
#define ___GFP_DMA 0x01u
#define ___GFP_HIGHMEM 0x02u
#define ___GFP_DMA32 0x04u
#define ___GFP_MOVABLE 0x08u
#define ___GFP_RECLAIMABLE 0x10u
#define ___GFP_HIGH 0x20u
#define ___GFP_IO 0x40u
#define ___GFP_FS 0x80u
#define ___GFP_ZERO 0x100u
#define ___GFP_ATOMIC 0x200u
/* 通过位运算将不同的标记组合起来 */
#define GFP_ATOMIC (__GFP_HIGH|__GFP_ATOMIC|__GFP_KSWAPD_RECLAIM)
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
#define GFP_KERNEL_ACCOUNT (GFP_KERNEL | __GFP_ACCOUNT)
#define GFP_NOWAIT (__GFP_KSWAPD_RECLAIM)"MIGRATE_MOVABLE"表示page frame可移动,"MIGRATE_UNMOVABLE"与之相反,而"MIGRATE_CMA"则是专用于CMA区域, 分配的时候会首先按照请求的migrate type从对应的pageblocks中寻找,如果不成功,其他migrate type的pageblocks中也会考虑(类似于Linux内存调节之lowmem reserve中zone之间的fallback),在一定条件下,甚至有可能改变pageblock的migrate type.
本质上讲,buddy算法相对于原始的bitmap,优势在于:
- 按照不同页框个数2^n重新组织了内存,便于快速查找用户所需大小的内存块(free_area数组的寻址时间复杂度是O(1))
- 不停的分配、重组页框,在一定程度上减少了页框碎片
可以查看 /proc/buddyinfo 来获取当前系统中的 buddy 信息
(base) kamilu@LZX:~/klinux$ cat /proc/buddyinfo
Node 0, zone DMA 0 0 0 0 0 0 0 0 0 1 3
Node 0, zone DMA32 3 2 4 1 3 2 2 2 2 2 959
Node 0, zone Normal 832 677 293 101 66 85 37 11 10 1 656
## 另一个机器上
root@kamilu:~# cat /proc/buddyinfo
Node 0, zone DMA 54 21 5 4 2 1 1 3 2 0 0
Node 0, zone DMA32 1386 559 475 83 52 30 13 7 2 8 4上图信息说明:
- 当前计算机只有一个 node, 所以都是 Node 0
- 当前系统中 X86-64 分为三个区, 分区名分别是 DMA DMA32 Normal (可配置)
- 后面每一行有 11 个数字, 每一列依次对应的 buddy 数组中每一个链表头指向的链表的节点内存块个数
从左至右分别为 1 2 4 ... 1024. 即第一行的 3 对应 (3 * PG_SIZE * 1024)KB 大小的 buddy 块
除此之外还可以查看 pagetypeinfo 获取一个更详细的, 每一个 list_head 的 MIGRATE_TYPES 信息
(base) kamilu@LZX:~/klinux$ sudo cat /proc/pagetypeinfo
Page block order: 9
Pages per block: 512
Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10
Node 0, zone DMA, type Unmovable 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type Movable 0 0 0 0 0 0 0 0 0 1 3
Node 0, zone DMA, type Reclaimable 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Unmovable 45 52 117 111 98 65 38 23 6 0 0
Node 0, zone DMA32, type Movable 516 201 219 127 66 23 13 10 6 24 740
Node 0, zone DMA32, type Reclaimable 41 16 29 26 21 2 0 1 1 0 0
Node 0, zone DMA32, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Unmovable 678 299 508 226 85 37 20 19 11 0 0
Node 0, zone Normal, type Movable 1662 126 151 96 55 33 23 20 9 1 0
Node 0, zone Normal, type Reclaimable 0 0 7 3 20 10 1 1 0 0 0
Node 0, zone Normal, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Number of blocks type Unmovable Movable Reclaimable HighAtomic Isolate
Node 0, zone DMA 1 7 0 0 0
Node 0, zone DMA32 25 1941 10 0 0
Node 0, zone Normal 291 1648 108 0 0思考的问题
- 516KB?
选择1: 1024KB; 选择2: 512KB + 4KB
- 大于 4MB怎么办?