进程内存布局
相信对于学习过操作系统的同学来说下图一定并不陌生, 它描述的就是一个进程的地址空间分布。
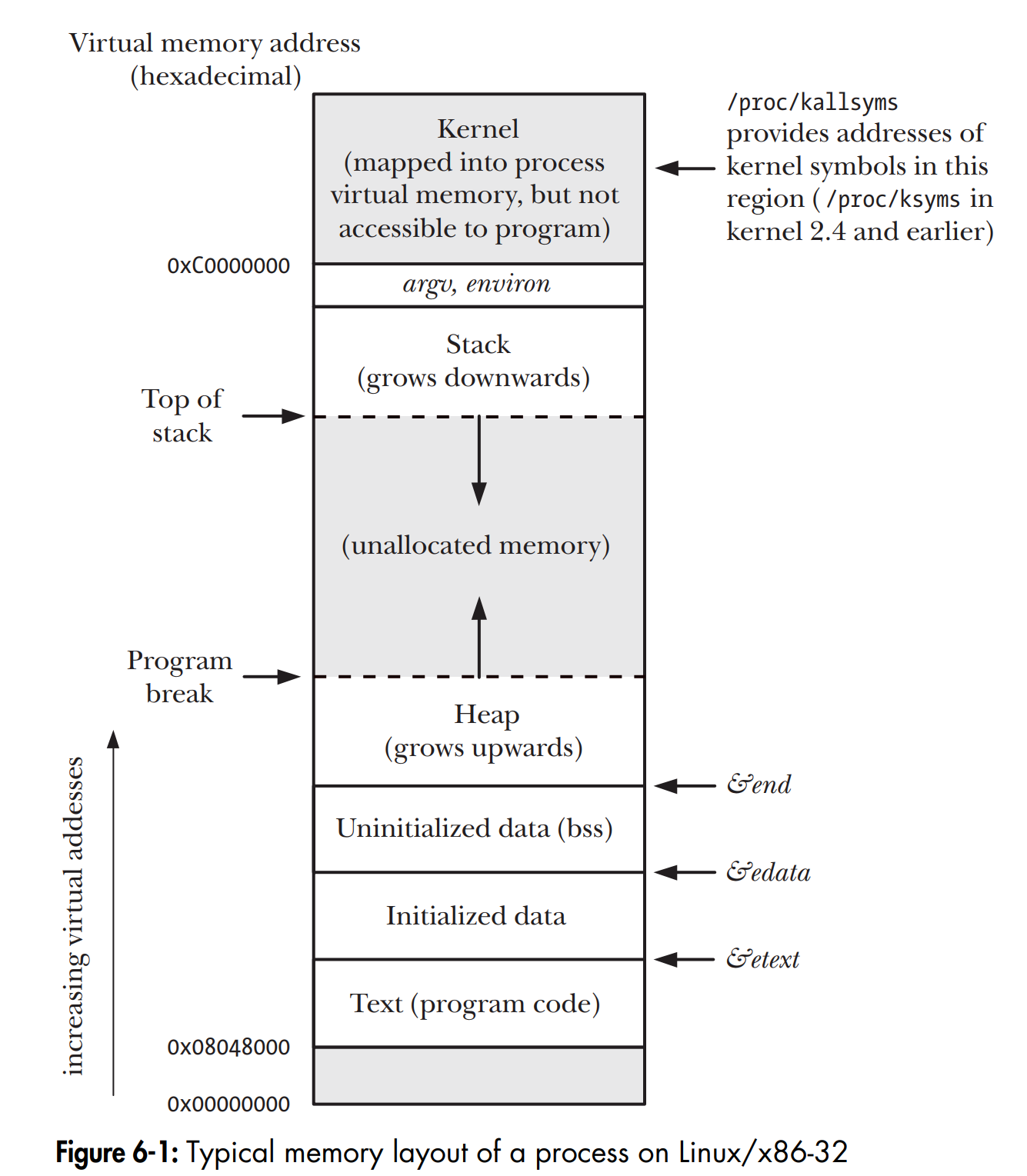
从操作系统的角度来说, 当机器上电之后它所看到的就是一片连续的长度为 N 的物理地址空间, 它需要做的就是以正确的安全的方式管理每一次内存访问。
虚拟地址的设计只是为了从程序员的角度简化地址空间的分布, 在 虚拟地址转换 中我们介绍了从一个虚拟地址转换到物理地址的方式, 如下图左侧所示。如果 TLB 命中则直接得到对应的物理地址; 否则依次遍历四级页表得到物理地址
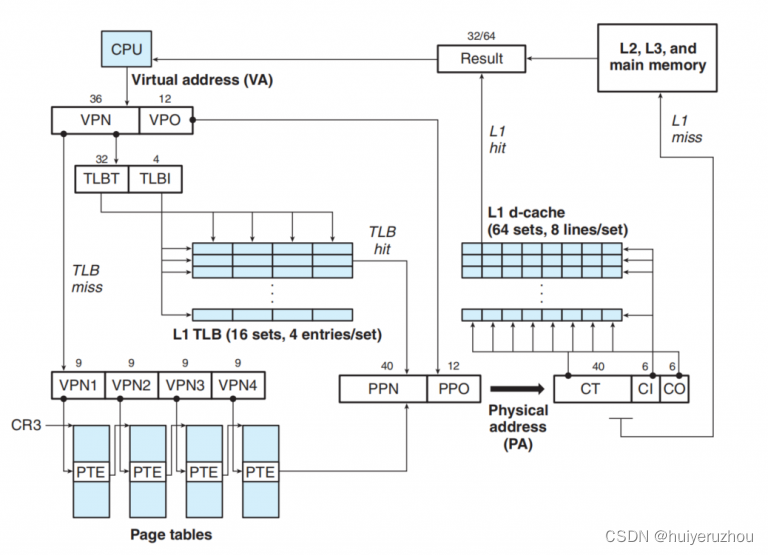
也就是说对于所有运行在 64 位机上的用户态进程, 尽管其交给 CPU 访存的虚拟地址可能相同, 但是通过 MMU 在每一个进程对应的页表转换之后总是可以得到对应的物理地址
那么一个进程的地址空间都有哪些主要内容呢?
进程地址空间
无论对于 32 位还是 64 位机器来说, linux 的进程地址空间分布是相同的, 如下图所示
从低地址到高地址分别是 保留区, 代码段, 数据段, BSS段, 堆, 文件映射与匿名分配区(这部分图中没有显示出来, 暂时略过), 栈。再高地址的区域就是内核区域了。
实际上进程的虚拟地址并不是连续的, 可能会有部分区域中间存在没有映射的地址, 即保留区。不使用该区域不会浪费 RAM,只会浪费地址空间,因为该区域未映射到物理内存, 对这些区域的内存访问会被直接视为错误
在 elf 中我们将会详细介绍 ELF 文件中的
.text.data.bss段等的含义
堆(heap)
堆用于存放进程运行时动态分配的内存段,可动态扩张或缩减。
堆中内容是匿名的,不能按名字直接访问,只能通过指针间接访问。当进程调用 malloc(C)/new(C++) 等函数分配内存时,新分配的内存动态添加到堆上(扩张);当调用 free(C)/delete(C++) 等函数释放内存时,被释放的内存从堆中剔除(缩减) .
分配的堆内存是经过字节对齐的空间,以适合原子操作。堆管理器通过链表管理每个申请的内存,由于堆申请和释放是无序的,最终会产生内存碎片。堆内存一般由应用程序分配释放,回收的内存可供重新使用。若程序员不释放,程序结束时操作系统可能会自动回收。
堆的末端由break指针标识,当堆管理器需要更多内存时,可通过系统调用 brk() 和 sbrk() 来移动break指针以扩张堆,一般由系统自动调用。
栈(stack)
栈又称堆栈,由编译器自动分配释放.堆栈主要有三个用途:
- 为函数内部声明的非静态局部变量(C语言中称"自动变量")提供存储空间。
- 记录函数调用过程相关的维护性信息,称为栈帧(Stack Frame)或过程活动记录(Procedure Activation Record).它包括函数返回地址,不适合装入寄存器的函数参数及一些寄存器值的保存。除递归调用外,堆栈并非必需。因为编译时可获知局部变量,参数和返回地址所需空间,并将其分配于BSS段。临时存储区,用于暂存长算术表达式部分计算结果或alloca()函数分配的栈内内存。
- 持续地重用栈空间有助于使活跃的栈内存保持在CPU缓存中,从而加速访问。进程中的每个线程都有属于自己的栈。向栈中不断压入数据时,若超出其容量就会耗尽栈对应的内存区域,从而触发一个页错误。此时若栈的大小低于堆栈最大值RLIMIT_STACK(通常是8M),则栈会动态增长,程序继续运行。映射的栈区扩展到所需大小后,不再收缩。
Linux中 ulimit -s 命令可查看和设置堆栈最大值,当程序使用的堆栈超过该值时, 发生栈溢出(Stack Overflow),程序收到一个段错误(Segmentation Fault).注意,调高堆栈容量可能会增加内存开销和启动时间。
栈既可向下增长(向内存低地址)也可向上增长, 这依赖于具体的实现。本文所述栈向下增长。
栈的大小在运行时由内核动态调整。
栈和堆的区别
首先需要明确一点的是, 无论是堆还是栈都是系统设计的产物, 本质上都是内存区域, 只不过按照程序中的不同用途划分了不同的区域以完成相应的功能。
- 管理方式:栈由编译器自动管理;堆由程序员控制,使用方便,但易产生内存泄露。
- 生长方向:栈向低地址扩展(即"向下生长"),是连续的内存区域;堆向高地址扩展(即"向上生长"),是不连续的内存区域。这是由于系统用链表来存储空闲内存地址,自然不连续,而链表从低地址向高地址遍历。
- 空间大小:栈顶地址和栈的最大容量由系统预先规定(通常默认2M或10M);堆的大小则受限于计算机系统中有效的虚拟内存,32位Linux系统中堆内存可达2.9G空间。
- 存储内容:栈在函数调用时,首先压入主调函数中下条指令(函数调用语句的下条可执行语句)的地址,然后是函数实参,然后是被调函数的局部变量。本次调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的指令地址,程序由该点继续运行下条可执行语句。堆通常在头部用一个字节存放其大小,堆用于存储生存期与函数调用无关的数据,具体内容由程序员安排。
- 分配方式:栈可静态分配或动态分配。静态分配由编译器完成,如局部变量的分配。动态分配由alloca函数在栈上申请空间,用完后自动释放。堆只能动态分配且手工释放。
- 分配效率:栈由计算机底层提供支持:分配专门的寄存器存放栈地址,压栈出栈由专门的指令执行,因此效率较高。堆由函数库提供,机制复杂,效率比栈低得多.
- 分配后系统响应:只要栈剩余空间大于所申请空间,系统将为程序提供内存,否则报告异常提示栈溢出。
操作系统为堆维护一个记录空闲内存地址的链表。当系统收到程序的内存分配申请时,会遍历该链表寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点空间分配给程序。若无足够大小的空间(可能由于内存碎片太多),有可能调用系统功能去增加程序数据段的内存空间,以便有机会分到足够大小的内存,然后进行返回。,大多数系统会在该内存空间首地址处记录本次分配的内存大小,供后续的释放函数(如free/delete)正确释放本内存空间。
此外,由于找到的堆结点大小不一定正好等于申请的大小,系统会自动将多余的部分重新放入空闲链表中。
- 碎片问题:栈不会存在碎片问题,因为栈是先进后出的队列,内存块弹出栈之前,在其上面的后进的栈内容已弹出。而频繁申请释放操作会造成堆内存空间的不连续,从而造成大量碎片,使程序效率降低。
可见,堆容易造成内存碎片;由于没有专门的系统支持,效率很低;由于可能引发用户态和内核态切换,内存申请的代价更为昂贵。所以栈在程序中应用最广泛,函数调用也利用栈来完成,调用过程中的参数、返回地址、栈基指针和局部变量等都采用栈的方式存放.所以,建议尽量使用栈,仅在分配大量或大块内存空间时使用堆。
使用栈和堆时应避免越界发生,否则可能程序崩溃或破坏程序堆、栈结构,产生意想不到的后果。
现在我们已经知道了一个进程的虚拟地址划分, 那么整个系统的物理内存的地址划分又是怎么样的呢? 内核地址空间又是怎么映射到物理内存的呢?
有趣的起始地址
上图中画出了 x86-32 中的进程虚拟地址空间的分布
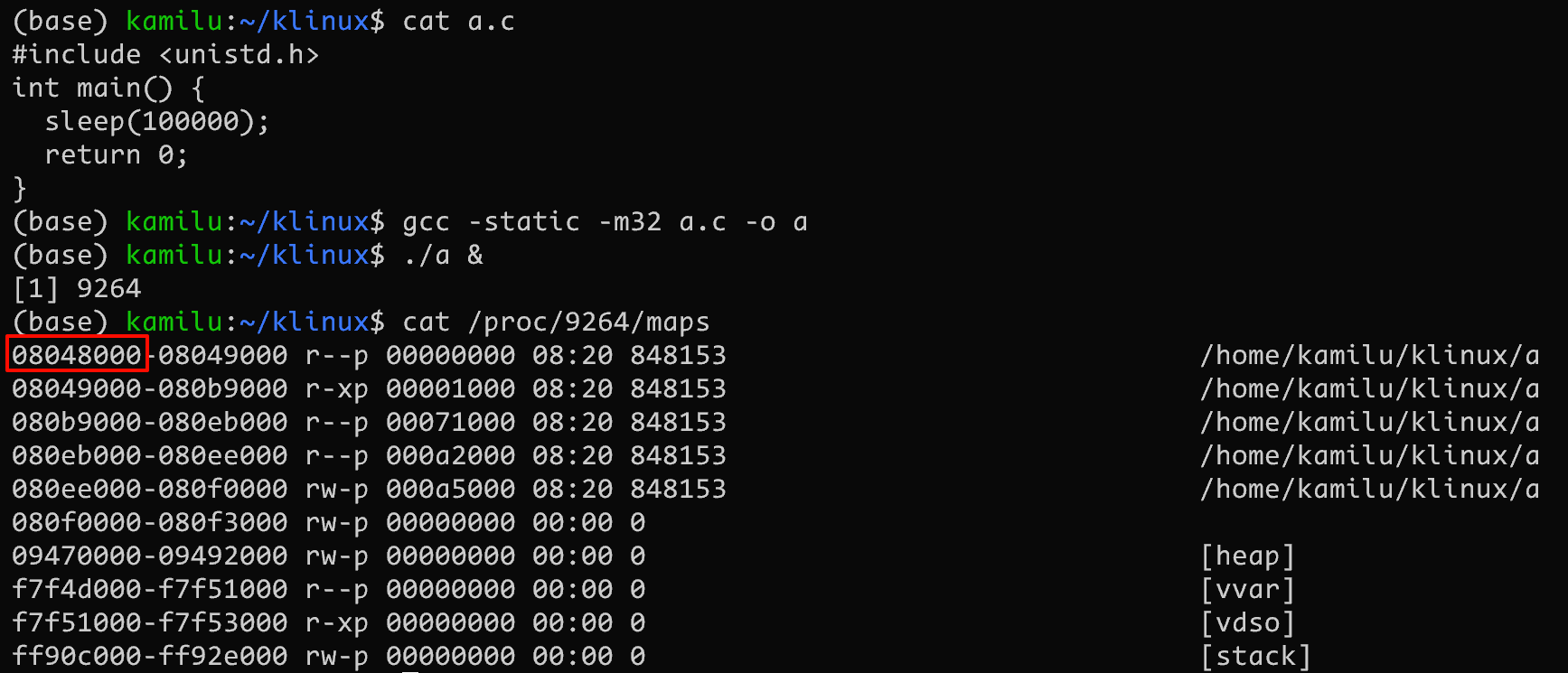
好奇的读者可能会注意到一个奇怪的地址 0x08048000, 这个数字有什么含义么? 为什么是从这个地址开始? 没错这个好奇的读者就是我
将一个程序编译为 32 位再查看其内存映射即可看到这个值
同时相似的是 x86-64 的进程虚拟地址空间也有一个奇怪的起始地址 0x400000
编译采用 -staic 即可观察到
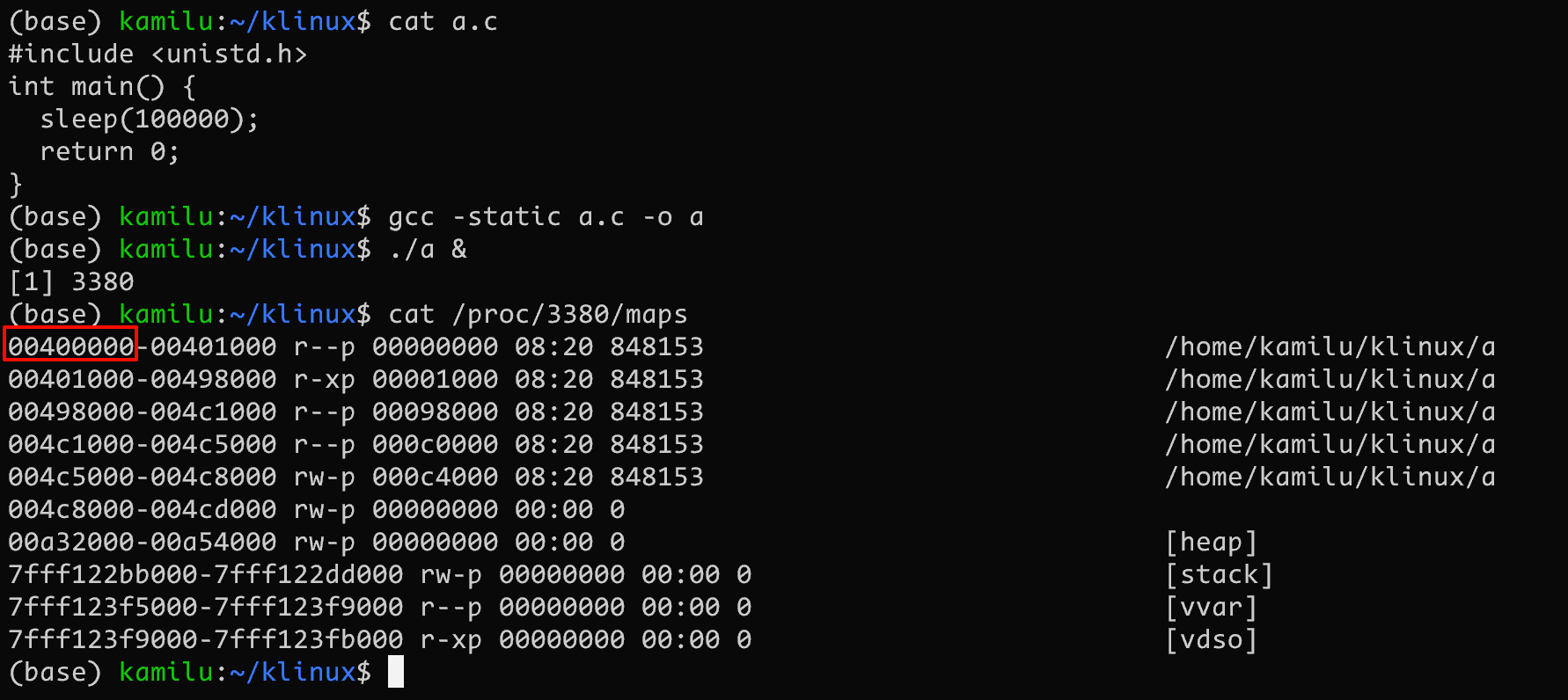
这两个地址属于历史问题, 无论是对于 32/64 位程序, 其实都可以自由的选择从任何一个起始地址开始装载 .text, 只要在运行前的最后一步将 pc 指针修改为该位置即可。那么为什么不从 0 开始还要留出一片未使用的地址呢?
首先将虚拟地址空间的低地址部分作为保留区, 也就是说任何对它的引用都是非法的, 这样可以天然的捕捉使用空指针和小整型值指针引用内存的异常情况。
保留区并不是一个单一的内存区域,而是对地址空间中受到操作系统保护而禁止用户进程访问的地址区域的总称.
大多数操作系统中,极小的地址通常都是不允许访问的,如NULL.
C语言将无效指针赋值为0也是出于这种考虑,因为 0 地址上正常情况下不会存放有效的可访问数据。
其次从 0x08048000 开始, 只是因为该地址是 x86-32 上 ELF 文本段的默认位置, 为什么 ELF 默认为 0x08048000? 可能是因为从 System V i386 ABI 借用了该地址。0x08048000 大小大约是 128MB, i386 System V ABI 为堆栈保留了这个区域。目前很难找到仅限 32 位的 x86 机器,并且发行版正在逐步停止对它们的支持。
0x400000 也只是因为原先机器内存很小, win95以前的I旧版程序基本上只能运行在这个4MB范围内,而如果一个程序能够从4MB这个位置开始执行,那么它基本上是一个新时代程序, 当时的程序员选择了0x400000(4MB)这个具有纪念意义的位置。但是这其实只是一种选择,并非必须
最后, 不使用该区域其实并不会浪费 RAM, 因为该区域未映射到物理内存. 从非 0 地址开始只会浪费进程的虚拟地址空间, 但就一个独占完整虚拟地址空间的程序来说, 浪费也就浪费
可以查阅 ld 手册搜索得到 0x400000 只是一个由历史原因保留下来的默认值, 没有特殊含义
info ld Scripts
IA32
32 位部分已经有些老旧, 但是会有利于对于 64 位地址空间的理解
以IA-32处理器为例,其虚拟地址为32位,因此其虚拟地址空间的范围为 [0-0xffffffff], x86-32系统中Linux将地址空间按3:1比例划分,其中用户空间(user space)占3GB,内核空间(kernel space)占1GB.
注意到此时内核只有 1GB 的地址空间, 但是物理内存的地址空间可能很大。操作系统内核需要将物理页面映射到内核空间才能访问它们.这是因为操作系统中的内核与用户态应用程序一样,通常运行在虚拟地址空间中。内核需要通过页表将物理内存地址映射到虚拟地址,这样内核才能通过虚拟地址来访问物理内存
操作系统不是万能的, 在开启了 MMU 的 CPU 上无法通过一个物理地址直接访存, 无论用户态还是内核态都需要虚拟地址
那么 IA32 如何用 1GB 的内核地址空间映射大于 1GB 的地址范围呢?
32 位 Linux 中的进程虚拟地址与物理内存空间的对应如下所示
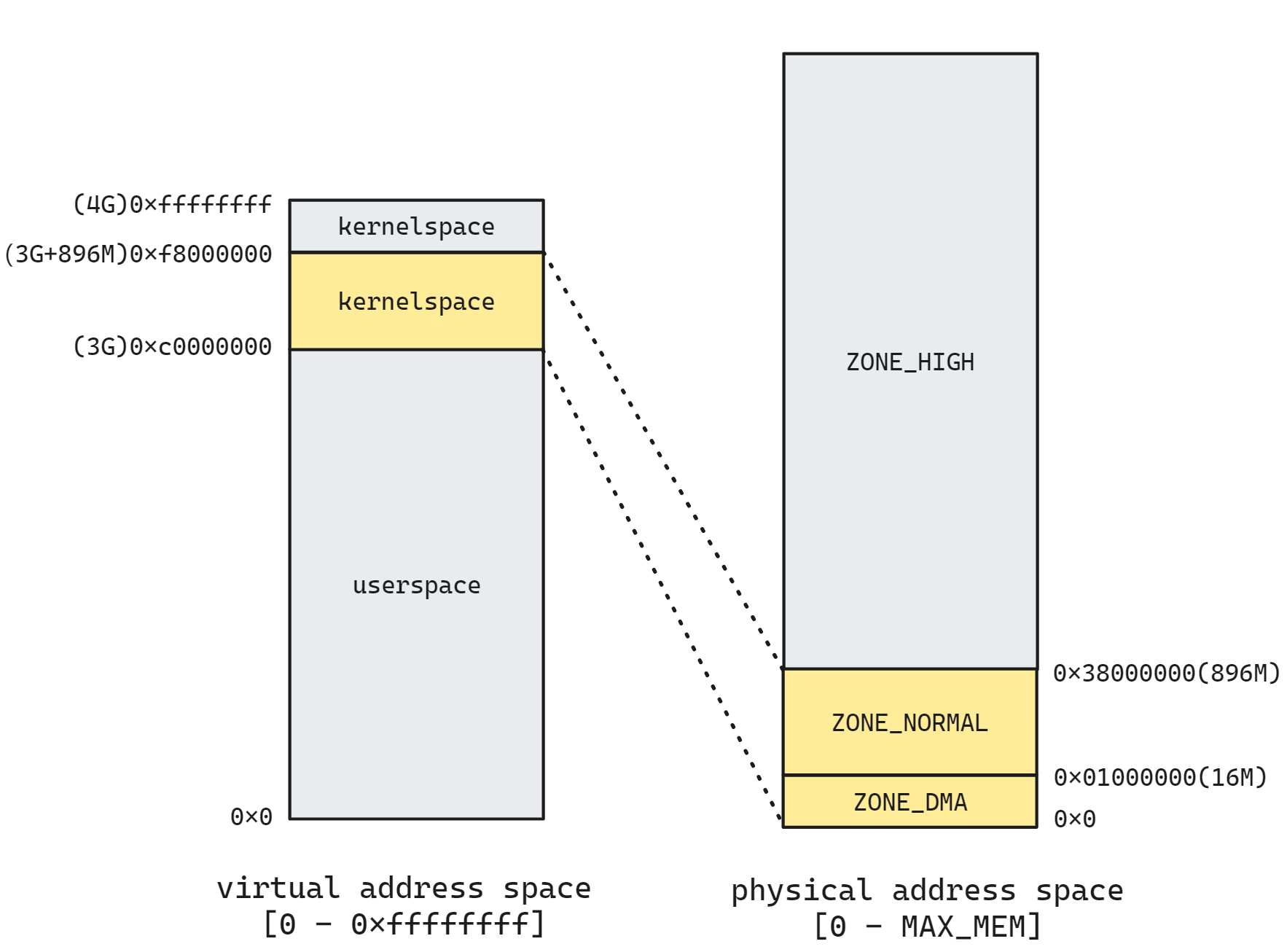
首先我们注意到两边的地址长度可能不相等. 左侧代表虚拟地址空间, 右侧代表物理地址空间。对于 32 位机器来说, 可以寻址的虚拟地址空间一共只有 32 位(4GB), 这是确定的。但实际的物理内存可能比 4GB 大, 也可能比 4GB 小, 这取决于具体的机器内存配置。
其次我们注意到内核空间分为两部分进行映射, 并出现了一个奇怪的地址 896MB. 从 [0xc0000000-0xf8000000] 的地址空间被映射到物理内存的最低地址位置, 而且映射了两个部分 ZONE_DMA 和 ZONE_NORMAL. 剩余的 [0xf8000000-0xffffffff] 和 3GB 的用户虚拟地址空间被映射到其余的更高位 ZONE_HIGH, 那么这些都是什么意思呢? 又为什么要这么映射呢?
直接映射区(896M)
我们先来看内核空间中黄色的映射, 这部分映射被称为直接映射区。所谓的直接映射区指的是这一块空间是连续的,和物理内存是非常简单的映射关系,其实就是虚拟内存地址减去 3G,就得到物理内存的位置。
#define PAGE_OFFSET 0x0c0000000 // 3GB
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
#define __pa(x) __phys_addr((unsigned long)(x))
#define __phys_addr(x) __phys_addr_nodebug(x)
#define __phys_addr_nodebug(x) ((x) - PAGE_OFFSET)
__pa(vaddr); // 返回与虚拟地址 vaddr 相关的物理地址;
__va(paddr); // 则计算出对应于物理地址 paddr 的虚拟地址。上述代码可以看出, 对于内核直接映射区的虚拟地址来说, va->pa 的过程就是地址 - 3GB 就可以得到对应的物理地址。
在系统启动的时, 操作系统一定是最先被加载到内存中的(不考虑固件的启动代码), 因此内核同样作为一个 ELF 文件其代码/数据段/BSS段会被优先加载到低地址区域, 如果还有剩余内存空间再分配给用户空间使用
0-896MB 的地址空间并不是由内核全部占据, 其中 [0-16MB] 映射的区域叫做 ZONE_DMA, [16-896] 映射的区域叫做 ZONE_NORMAL
zone 内存管理中很重要的一个概念, 它将属性相同的页面归到一个 zone 中。对 zone 的划分与硬件相关, 对不同的处理器架构是可能不一样的。详见 zone
一些使用 DMA 的外设并没有像 CPU 那样的 32 位地址总线,比如只有 16 位总线,就只能访问 64 KB 的空间,24 位总线就只能访问 16 MB 的空间.如果给 DMA 分配的内存地址超出了这个范围,设备就没法(寻址)访问了。为此,Linux 将低 16MB 的空间单独划成了 ZONE_DMA.
剩余的部分即 [16MB-896MB] 的区域映射为 ZONE_NORMAL, 这是内核始终可以访问的普通内存区域, 内核作为一个 ELF 程序其内代码段,数据段,BSS段都会被映射到这里。如果碰到系统调用创建进程,会创建 task_struct 这样的实例,内核的进程管理代码会将实例创建在 [3G-3G+896MB] 的虚拟空间中, 对应被放在物理内存的 [0-896M] 里面,相应的页表也会被创建。
前面我们提到 内核需要通过页表将物理内存地址映射到虚拟地址,这样内核才能通过虚拟地址来访问物理内存, [0-896MB] 的区域(即 ZONE_DMA + ZONE_NORMAL) 是专属于内核使用的区域, 如果要访问进程的物理内存, 那么就需要从虚拟地址的 [0xf8000000-0xffffffff] 地址空间范围内找一段相应大小空闲的逻辑地址空间, 借用这段逻辑地址空间,建立映射到想访问的那段物理内存(即填充内核PTE页面表), 用完后归还。这样别人也可以借用这段地址空间访问其他物理内存,实现了使用有限的地址空间,访问所有所有物理内存
相当于用 128MB 的地址空间临时去映射所有其他的物理内存, 即
ZONE_HIGHMEM区域
下图是一个详细的 x86-32 的进程地址映射图:
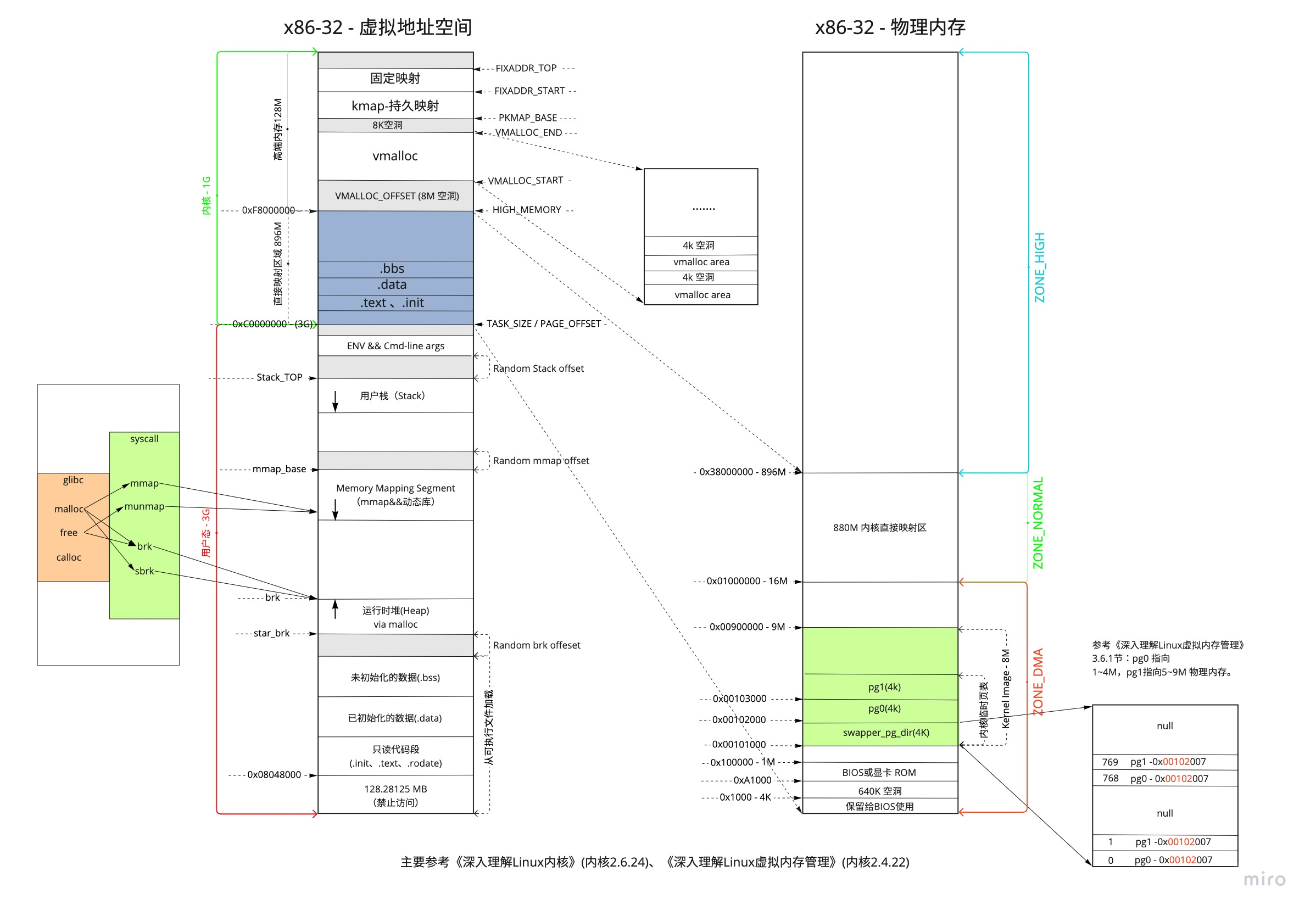
总的来说, 32位系统下,虚拟地址空间只有4G,而内核占用高1G(3G~4G).内核这1G虚拟地址空间,其中低896M采用直接映射,保留1G-896M=128M地址空间用于动态映射。所以超出896M(896M~4GB)的物理地址空间(ZONE_HIGHMEM),通过动态映射到内核高128M的虚拟地址(3G+896M)~4GB的方式,供内核访问。
X86_64
对于 64 位系统来说情况就简单很多了, 虽然 64 位系统的虚拟地址空间有 2^48 = 256 TB, 但是面对64位系统所具备的16EB的地址范围,根本就用不完
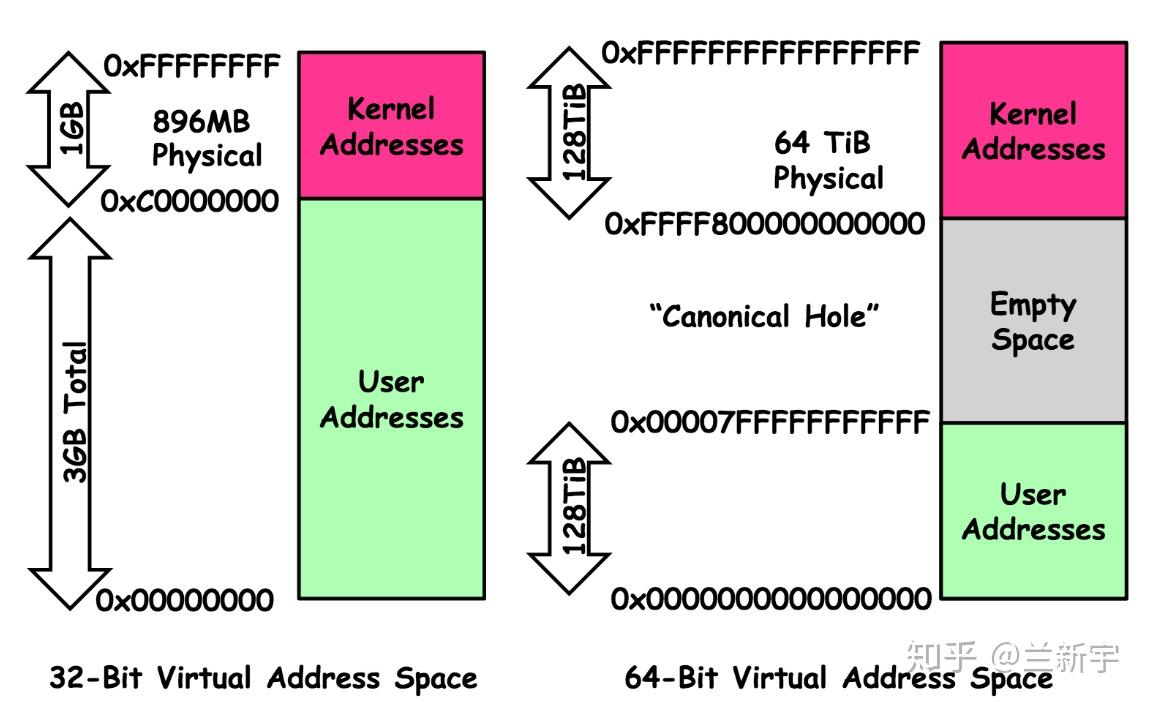
Linux 选择按照1:1的比例划分,内核空间和用户空间各占128TB, 即最低的 [0-128TB] 为用户空间, 最高的 128TB 为内核空间, 用户虚拟空间和内核虚拟空间不再是挨着的,但同32位系统一样,还是一个占据底部,一个占据顶部,所以这时user space和kernel space之间偌大的区域就空出来了。
但这段空闲区域也不是一点用都没有,它可以辅助进行地址有效性的检测.如果某个虚拟地址落在这段空闲区域,那就是既不在user space,也不在kernel space,肯定是非法访问了。使用48位虚拟地址,则kernel space的高16位都为1,如果一个试图访问kernel space的虚拟地址的高16位不全为1,则可以判断这个访问也是非法的。同理,user space的高16位都为0.这种高位空闲地址被称为canonical.
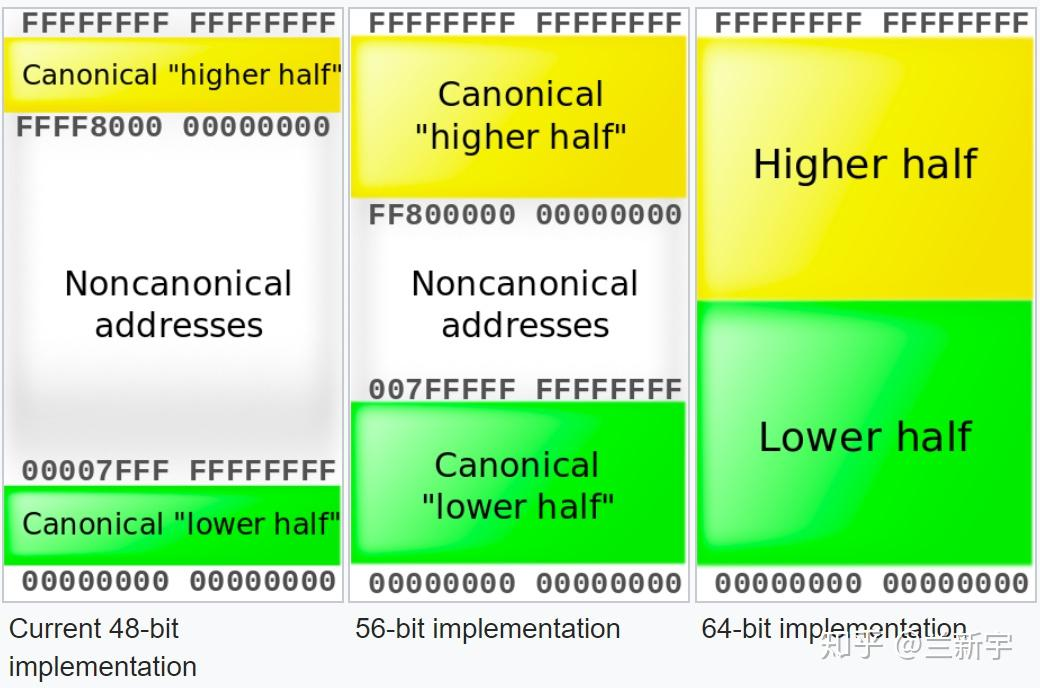
简单来说就是快速的根据一个虚拟地址的操作判断是否合法, 如果不合法直接报错, 当然如果没有问题也并不一定说明内存访问一定是合法的,还需要根据页面标志位 R/W/X 来进一步判断
x86-64 的内存布局如下
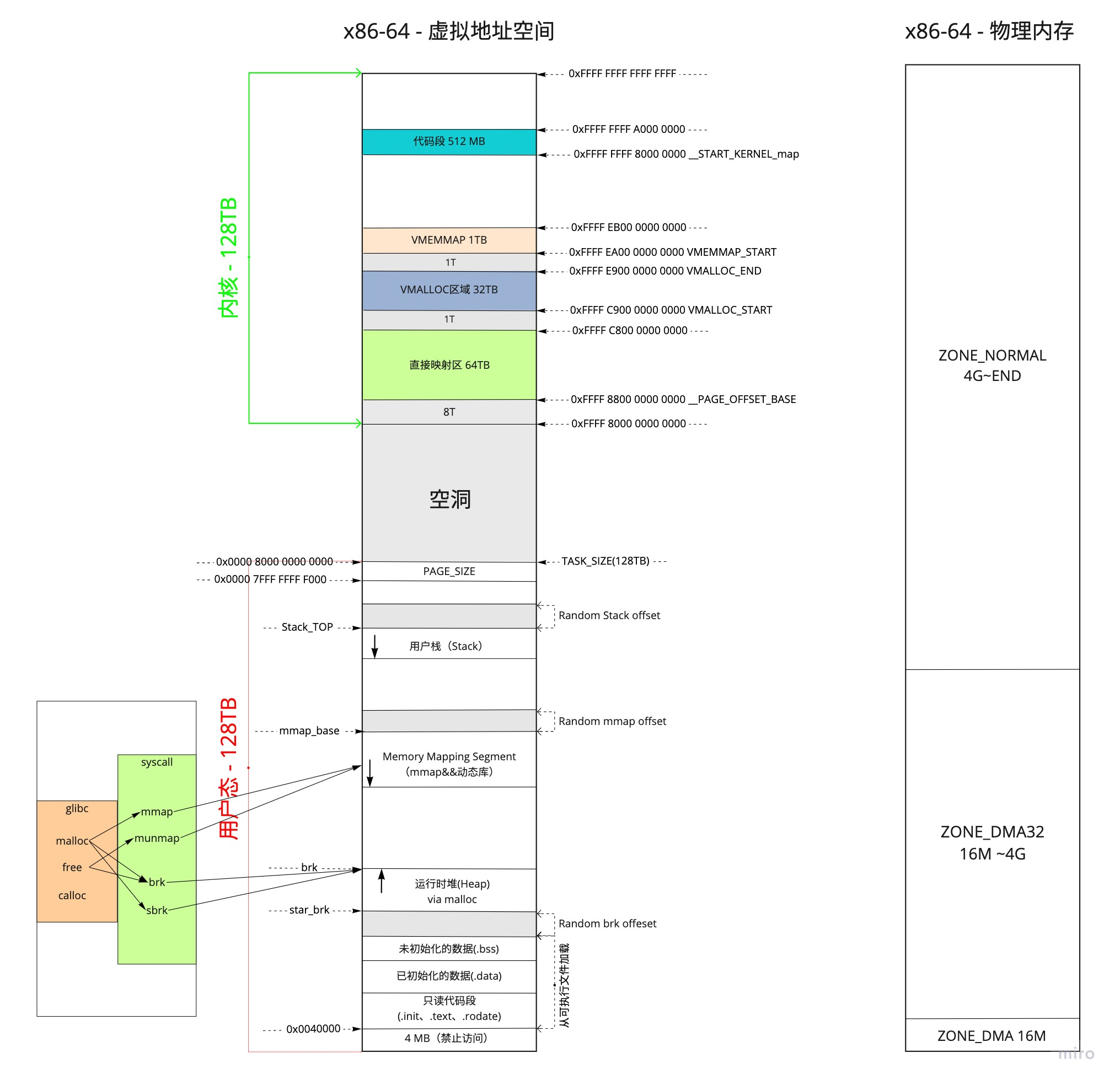
在64位系统中,内核空间的映射变的简单了,因为这时内核的虚拟地址空间已经足够大了,直接映射物理内存,不再需要ZONE_HIGHMEM那种动态映射机制了。
direct mapping
内核地址从 0xffff800000000000 开始, 开始有 8T 的空档区域
内核中有两段映射物理内存的区域, 直接映射区地址连续,和物理地址空间是简单的线性映射关系
direct mapping 的范围是 [ffff880000000000 - ffffc7ffffffffff] (=64 TB), 地址空间 64 TB, 这部分用于映射用户进程的物理内存
其中起始地址 ffff880000000000 也被称为内核页面偏移量(PAGE_OFFSET), 这块区域把所有物理内存线性映射到PAGE_OFFSET虚拟地址。64 TB 对于绝大多数的机器的内存容量都是足够的
PAGE_OFFSET的值可能是固定的 0xffff880000000000,或者KASLR使能后的随机地址page_offset_base
kernel text mapping
kernel text mapping 的区域是 [ffffffff80000000 - ffffffffa0000000] (=512 MB)
ffffffff80000000 地址也被称为 __START_KERNEL_map, 开始的 512M 用于存放内核代码段、全局变量、BSS 等.这里对应到物理内存开始的位置,减去 __START_KERNEL_map 就能得到物理内存的地址
所以对于内核代码段, 内核代码段物理地址 + __START_KERNEL_map = 内核代码段虚拟地址
512 MB 对于内核来说是足足够用了
__pa和__va
我们来结合 64 位内核中的宏来了解一下物理地址和虚拟地址的转换, 这两块映射区域之间的内核虚拟地址转换为物理地址可以直接借助于__pa(x)函数,无需通过页表转换获得。
对于 direct mapping 的区域来说, 其映射的物理内存地址和虚拟内存地址就差一个 PAGE_OFFSET, 线性映射
#define PAGE_OFFSET ((unsigned long)__PAGE_OFFSET)
#define __PAGE_OFFSET _AC(0xffff880000000000, UL)
#define __pa(x) ((unsigned long)(x-PAGE_OFFSET))
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))对于 kernel text mapping 来说, 其地址映射在 __START_KERNEL_map 之上, 因此
#define __START_KERNEL_map _AC(0xffffffff80000000, UL)
#define __pa(x) ((unsigned long)(x - __START_KERNEL_map + phys_base))
#define __va(x) ((void*)(unsigned long)(x + __START_KERNEL_map - phys_base))其中 phys_base 是内核的初始映射地址, 默认是 0, 如果开启 KASLR 那么就会选择一个随即地址作为起始偏移量避免被攻击
因此可以看到内核中的代码逻辑如下
#define __PAGE_OFFSET_BASE_L4 _AC(0xffff888000000000, UL)
#define __START_KERNEL_map _AC(0xffffffff80000000, UL)
#define PAGE_OFFSET __PAGE_OFFSET_BASE_L4
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
#define __pa(x) __phys_addr((unsigned long)(x))
#define __phys_addr(x) __phys_addr_nodebug(x)
static __always_inline unsigned long __phys_addr_nodebug(unsigned long x)
{
unsigned long y = x - __START_KERNEL_map;
/* use the carry flag to determine if x was < __START_KERNEL_map */
x = y + ((x > y) ? phys_base : (__START_KERNEL_map - PAGE_OFFSET));
return x;
}
__pa(vaddr); // 返回与虚拟地址 vaddr 相关的物理地址;
__va(paddr); // 则计算出对应于物理地址 paddr 的虚拟地址。函数的返回值对应两种映射情况
- x>y: 对应 x 在 __START_KERNEL_map 之下, 即 direct mapping 区域, 值为 x - __START_KERNEL_map + phys_base
- x<=y: 对应 x 在 __START_KERNEL_map 之上, 即 kernel text mapping 区域, 值为 x - PAGE_OFFSET
API 演示
例如对于如下内核驱动
#include <linux/module.h>
#include <linux/kernel.h>
#include <asm/page.h>
#include <asm/pgtable_types.h>
static int __init pa_va_init(void)
{
unsigned long kernel_phys_address;
unsigned long direct_phys_address;
kernel_phys_address = __pa(0xffffffff81000000);
printk(" kernel_text_start_phys_address = 0x%lx\n", kernel_phys_address);
direct_phys_address = __pa(0xffff88006cadc000 );
printk(" direct_phys_address = 0x%lx\n", direct_phys_address);
return -1;
}
static void __exit pa_va_exit(void)
{
}
module_init(pa_va_init);
module_exit(pa_va_exit);
MODULE_LICENSE("GPL");
可以看到结果分别为 -PAGE_OFFSET 和 -__START_KERNEL_map
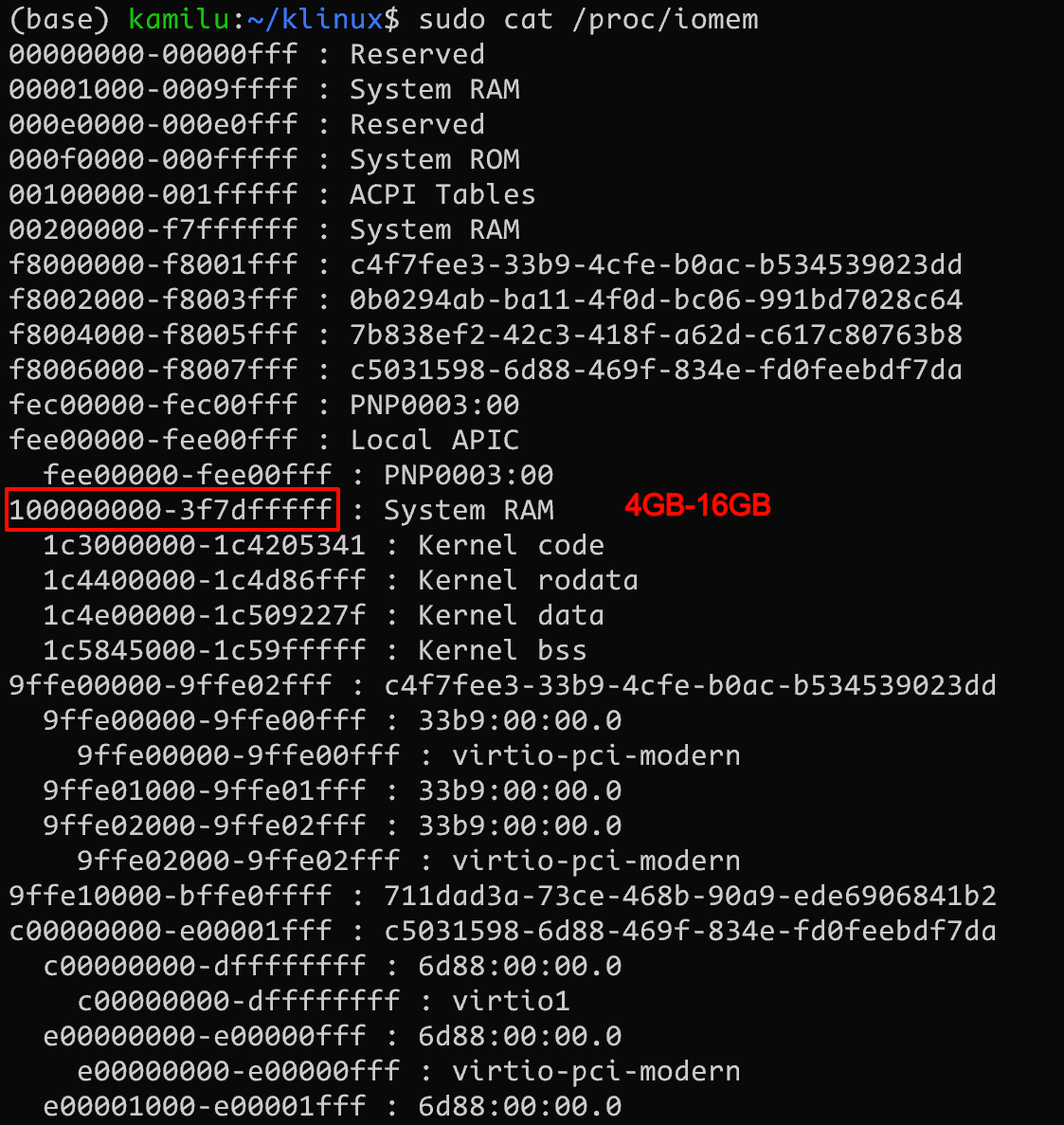
可以查看 /proc/iomem, 该文件记录了物理地址的映射内容, 如下图所示。可以看到当前系统内存位 16GB, [4GB-16GB] 就是系统内存映射的范围
有关 /proc/iomem 的相关阅读: mmio
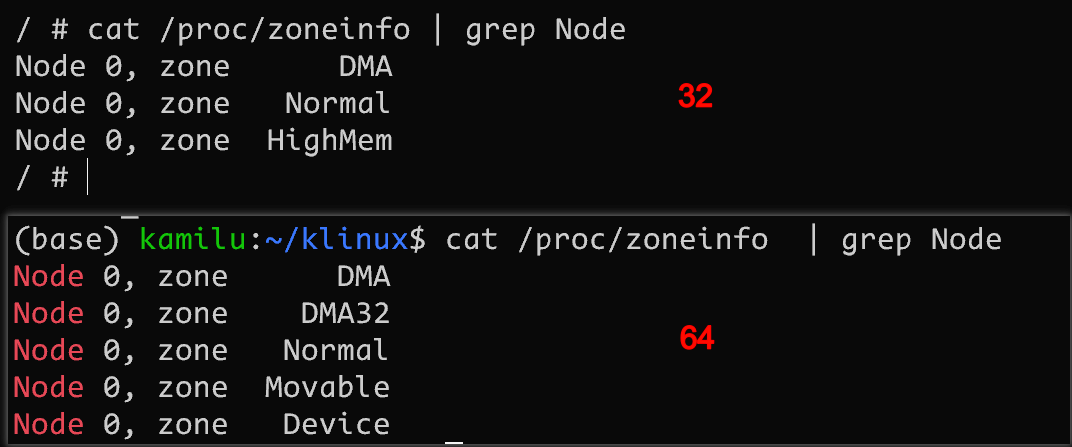
前文 32 位中我们提到有 3 个zone区域, 分别是 ZONE_DMA ZONE_NORMAL 和 ZONE_HIGHMEM. 其中 ZONE_DMA 是为旧设备兼容而创建的, 而 ZONE_HIGHMEM 只是因为内核空间不足不得已的一种做法。
到了 64 位系统,外设的寻址能力增强,因此又加入了一个 ZONE_DMA32,空间大小为 16MB 到 4GB.
因为历史原因,
ZONE_DMA还是叫原来的名字,但准确讲它应该叫ZONE_DMA24.除此之外系统中还有
ZONE_MOVABLEZONE_DEVICE区域, 详见 zone
为什么要有内核地址?
每一个进程的虚拟地址空间都有内核区域, 它们实际映射的都是同一块物理地址, 所有进程的内核虚空间是共享的, 即物理内存的最低地址的位置。
32/64 位
ARM公司宣称64位的ARMv8是兼容32位的ARM应用的,所有的32位应用都可以不经修改就在ARMv8上运行。那32位应用的虚拟地址在64位内核上是怎么分布的呢?事实上,64位内核上的所有进程都是一个64位进程。要运行32位的应用程序, Linux内核仍然从64位init进程创建一个进程, 但将用户地址空间限制为4GB.通过这种方式, 我们可以让64位Linux内核同时支持32位和64位应用程序。