atomic
原子操作(atomic operation)指的是由多步操作组成的一个操作.如果该操作不能原子地执行,则要么执行完所有步骤,要么一步也不执行,不可能只执行所有步骤的一个子集。
现代操作系统中,一般都提供了原子操作来实现一些同步操作,所谓原子操作,也就是一个独立而不可分割的操作。在单核环境中,一般的意义下原子操作中线程不会被切换,线程切换要么在原子操作之前,要么在原子操作完成之后。更广泛的意义下原子操作是指一系列必须整体完成的操作步骤,如果任何一步操作没有完成,那么所有完成的步骤都必须回滚,这样就可以保证要么所有操作步骤都未完成,要么所有操作步骤都被完成。
但需要注意的是,单核系统(UP)同样需要原子操作,只不过多核系统(SMP)要比单核系统中的原子操作面临更多的问题
单核原子读/写
在单核系统中,如果CPU仅仅是从内存中读取(read/load)一个变量的值,或者仅仅是往内存中写入(write/store)一个变量的值,都是不可打断,也不可分割的.Linux中实现原子性的读一个变量与原子性的写一个变量的函数分别是 atomic_read() 和 atomic_set().
#define atomic_read(v) READ_ONCE((v)->counter)
#define atomic_set(v,i) WRITE_ONCE(((v)->counter), (i))READ_ONCE() 和 WRITE_ONCE() 取代了以前的 ACCESS_ONCE(),它们的实现很简单,以32位的变量操作为例
#define __READ_ONCE(x) (*(const volatile __unqual_scalar_typeof(x) *)&(x))
#define __WRITE_ONCE(x, val) (*(volatile typeof(x) *)&(x) = (val);)实现见 rwonce.h
可以看到这两个宏就是简单的直接赋值,并没有借助什么特殊的指令。那为什么要使用这两个宏呢? 主要是为了避免编译器的优化. volatile 可以让编译器生成的代码,每次都从内存重新读取变量的值,而不是用寄存器中暂存的值。因为在多线程环境中,不会被当前线程修改的变量,可能会被其他的线程修改,从内存读才可靠, 需要避免编译器把它当成一个普通的变量,做出错误的优化。还有一部分原因是,这两个宏可以作为标记,提醒编程人员这里面是一个多核/多线程共享的变量,必要的时候应该加互斥锁来保护
volatile并不是线程安全的保证,它不能替代互斥锁或其他线程同步机制, 它可以确保每次都从内存重新读取变量的值
register用于建议编译器将变量存储在寄存器中而不是内存中, 但编译器并不保证一定会将变量存储在寄存器中(可能会因为具体代码或者目标平台的寄存器资源不足而 spill 到内存)
单核原子修改
如果CPU不是简单地读/写一个变量,而是需要修改一个变量的值,那么它首先需要将变量的值从内存读取到寄存器中(read),然后修改寄存器中变量的值(modify),最后将修改后的值写回到该变量所在的内存位置(write),这一过程被称为 RMW(Read-Modifiy-Write).
RMW操作有可能被中断所打断,因而不是原子的.那如何保证RMW操作的原子性呢? 最简单的方法就是关闭中断. 在 io 中我们介绍了中断的本质是处理器对外开放的实时受控接口, 当设备发送中断请求的时候由中断控制器向 CPU 发送中断信号, 此时该引脚被激活, CPU 接受到中断信号并跳转到中断向量表对应项执行。关中断之后就不会再响应该信号了。

因此想要给变量加上一个常数的原子操作atomic_add(),就可以这样实现:
void atomic_add(int i, atomic_t *v) {
unsigned long flags;
raw_local_irq_save(flags); // 关中断
v->counter += i;
raw_local_irq_restore(flags); // 恢复中断
}但是开关中断的开销有点大, 我们期望 CPU 可以提供锁的机制完成原子操作
SMP的原子读/写
在SMP系统中,多个CPU通过共享的总线和内存相连接,如果它们同时申请访问内存,那么总线就会从硬件上进行仲裁,以确定接下来哪一个CPU可以使用总线,然后将总线授权给它,并且允许该CPU完成一次原子的load操作或者store操作。在完成每一次操作之后,就会重复这个周期:对总线进行仲裁,并授权给另一个CPU.每次只能有一个CPU使用总线.
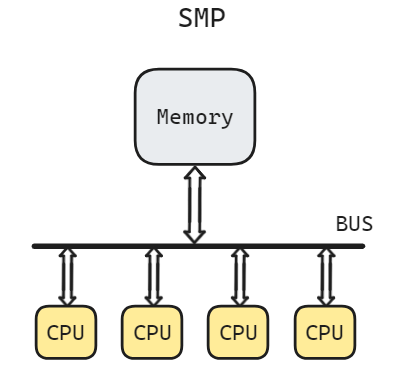
Linux中,atomic_read()函数和atomic_set()函数在SMP中的实现和在单核(UP)中的实现完全一样,本身就是原子的,不需要借助其他任何特殊的手段或者指令
SMP的原子RMW
而SMP系统中的一个CPU如果想实现RMW操作, 这个情况就会复杂很多了
假设我们要给一个多核共享变量的值加1, 按照 RMW 的
- 将变量的值从内存读取到寄存器中(read)
- 修改寄存器中变量的值(modify)
- 最后将修改后的值写回到该变量所在的内存位置(write)
在多核之间的实际执行流程可能有很多种排列组合
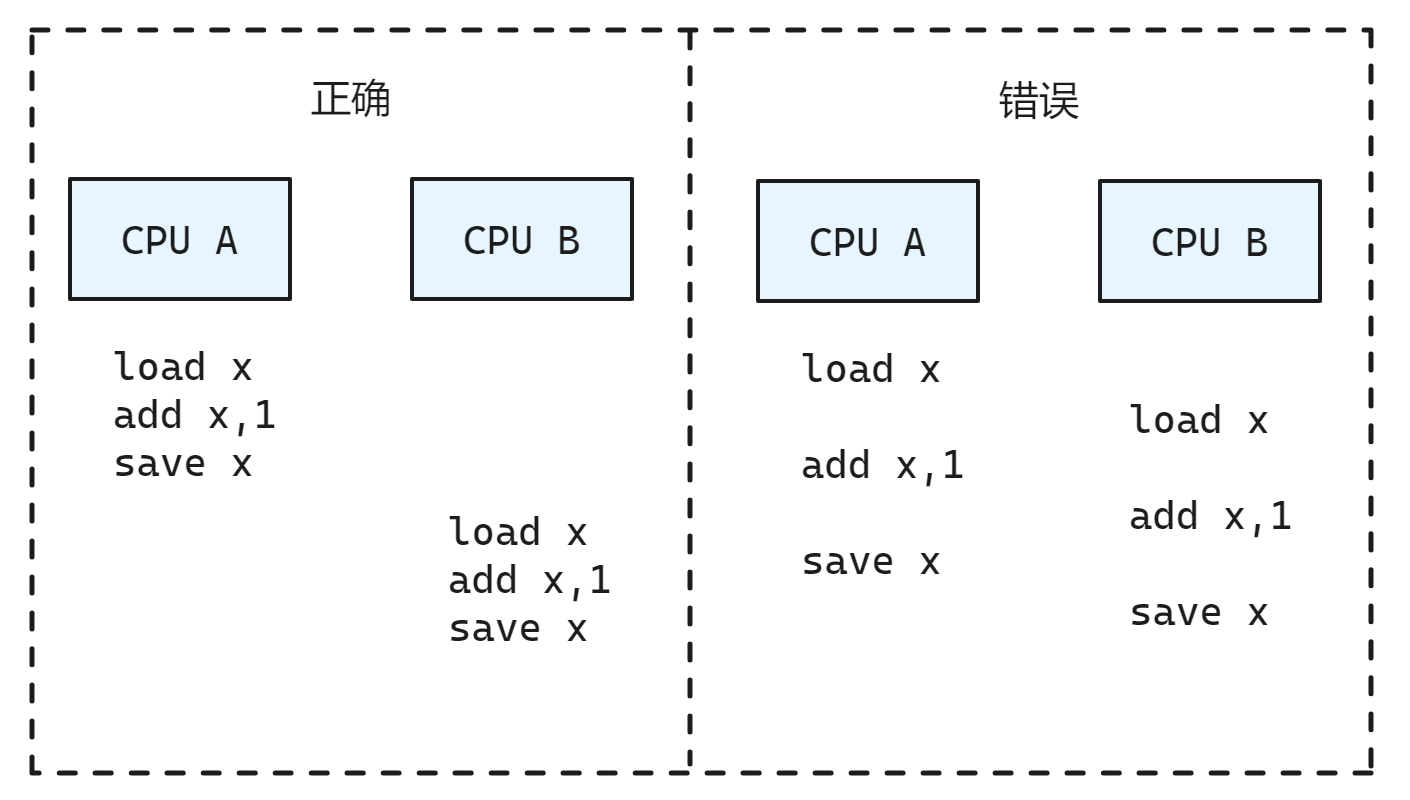
可见,CPU A和CPU B对共享变量的访问出现了竞态(race condition),中间执行的代码路径形成了交织(interleave),造成最后的结果可能不一致。我们需要保证在SMP系统中,单个CPU的RMW操作也是原子的。对此,不同架构的处理器给出了不同的解决方法
X86: 锁总线/锁缓存
x86处理器常用的做法是给总线上锁(bus lock),以获得在一定的时间窗口内对总线独占的授权,就好像是一个CPU在告诉总线说"在我完成之前,别让其他CPU来读写内存的数据"
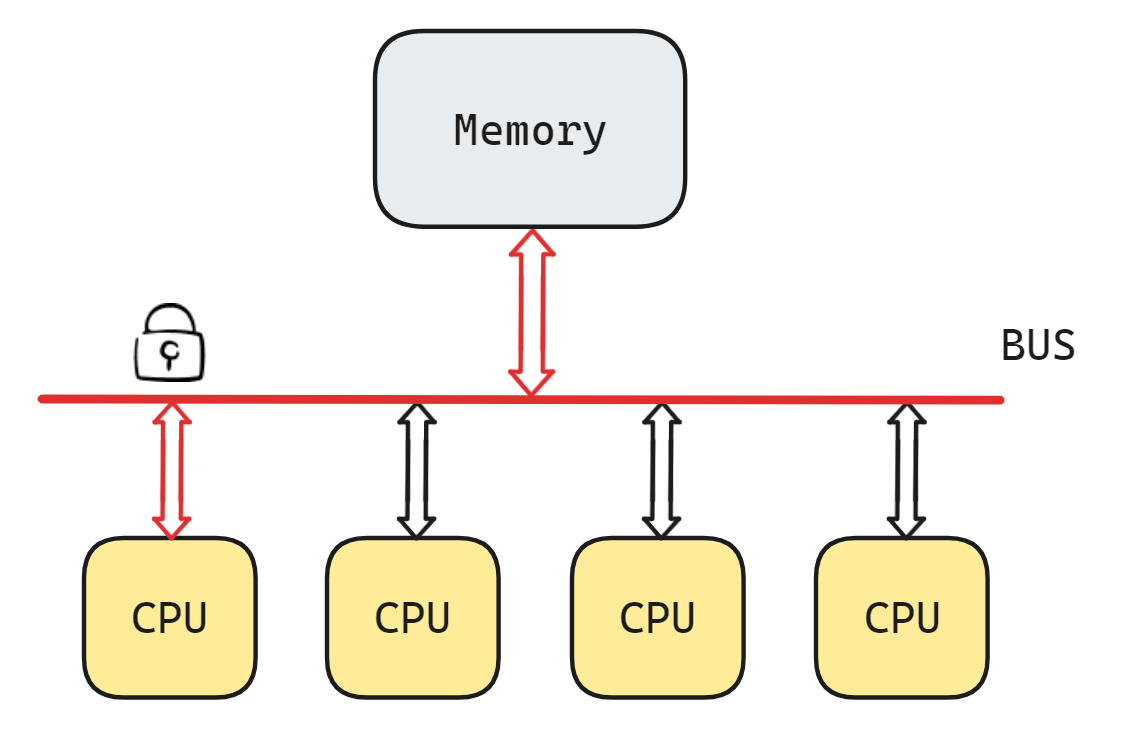
有一些指令,比如 XCHG(原子的交换寄存器&寄存器/寄存器&存储器) ,在执行时会被硬件自动/隐式地加上 LOCK# 信号以实现总线的锁定。软件也可以显示地在指令前面加上一个名为"lock"的前缀来达到相同的效果,锁总线的时间等于指令执行的时间。不过,并非所有的指令都可以加"lock"前缀,允许添加的指令包括CMPXCHG, 用于算术运算的ADD, SUB, INC, DEC,以及用于位运算的BTS, BTC等。
例如 Linux中atomic_add()在x86上的实现:
#define LOCK_PREFIX_HERE \
".pushsection .smp_locks,\"a\"\n" \
".balign 4\n" \
".long 671f - .\n" /* offset */ \
".popsection\n" \
"671:"
#define LOCK_PREFIX LOCK_PREFIX_HERE "\n\tlock; "
static __always_inline void arch_atomic_add(int i, atomic_t *v)
{
asm volatile(LOCK_PREFIX "addl %1,%0"
: "+m" (v->counter)
: "ir" (i) : "memory");
}除了和I/O紧密相关的(比如MMIO),大部分的内存都是可以被cache的,对于特性为Cacheable的内存,和CPU打交道的是缓存在它自己的cache中的内存数据.所以,虽然使用的是"lock"指令前缀,但此时总线和内存都不会被上锁,bus lock实际成了cache lock.
cacheable 的内存在 虚拟内存 的 页表格式 中介绍, 其 page flag 的
PCD位为 1 表示可以被 cache
那如果RMW操作的数据不是自然对齐的呢?不是自然对齐也没有关系,只要操作的数据是在一条cache line里面,cache lock就足以保证原子性。
那再进一步,如果RMW操作的数据跨越了2个cache line,连cache line都没有对齐呢?
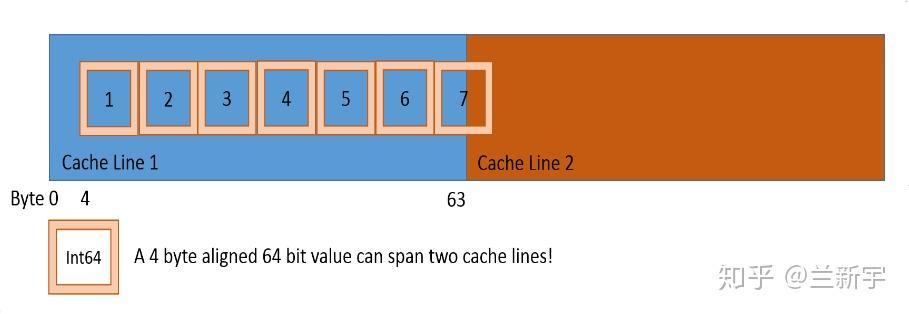
那么这就不是一次cache line操作可以完成的了,cache lock就不够了,只能是bus lock.这种跨越cache line的访问被称为"split access",此时的bus lock对应地被称为 split lock
因此只要没有设置Alignment Check的硬件检测,那么加上"lock"指令前缀后,不管是非自然对齐的,还是非cache line对齐的RMW操作,通通都可以保证原子性。如果在 cacheline 中的数据只需要 cache lock 就可以保证原子性了, 对于非对齐的数据访问需要 bus lock, 对性能影响很大(使用一次split lock会消耗大约1000个时钟周期),是应该尽量避免的。
对于上面那个例子,如果CPU A和CPU B同时调用 atomic_add() 去给共享变量的值加1,那么只有一个CPU能成功地执行"lock add"这条指令,假设A成功了,B失败了,那么A随后会将该变量的值设为6,其cache line为modified状态,B对应的包含该变量的cache line则为invalid状态。
接下来B将运行刚才没有获准执行的这条"lock add"指令,由于此时它的cache line是invalid状态,根据硬件维护的cache一致性协议,B中cache line中变量的值将变为6,并回到shared状态,B的"lock add"也将基于新的值(6)来做加1运算,所以最终结果就是7,不会因为竞态而出现结果的不一致。
缓存一致性协议部分见 cache-co
ARM: LL/SC
以上讨论的是Linux基于x86的RMW原子操作的实现,那基于ARM的又该如何实现呢?
在ARMv8.1之前,为实现RMW的原子操作采用的方法主要是 LL/SC (Load-Link/Store-Conditional).ARMv7中实现LL/SC的指令是 LDREX/STREX,其实就是比基础的LDR和STR指令多了一个"EX","EX"表示exclusive(独占).具体说来就是,当用LDREX指令从内存某个地址取出数据放到寄存器后,一个硬件的monitor会将此地址标记为exclusive.
假设CPU A先进行load操作,并标记了变量v所在的内存地址为exclusive,在CPU A进行下一步的store操作之前,CPU B也进行了对变量v的load操作,那么这个内存地址的exclusive就成了CPU B标记的了。
之后CPU A使用STREX进行store操作,它会测试store的目标地址的exclusive是不是自己标记的(是否为自己独占),结果不是,那么store失败.接下来CPU B也执行STREX,因为exclusive是自己标记的,所以可以store成功,exclusive标记也同步失效。此时CPU A会再次尝试一轮LL/SC的操作,直到store成功。
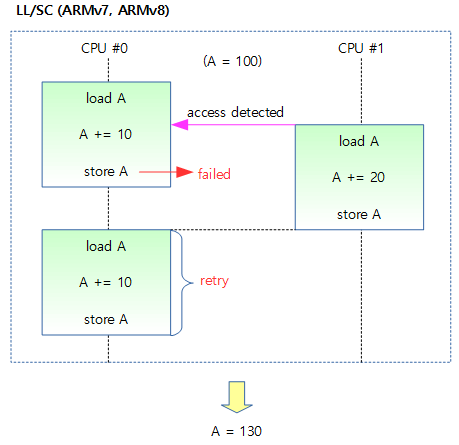
重试一次还好,如果CPU之间竞争比较激烈,可能导致重试的次数较多,所以从2014年的ARMv8.1开始,ARM推出了用于原子操作的LSE(Large System Extension)指令集扩展,新增的指令包括CAS, SWP和LD<OP>, ST<OP>等,其中<OP>可以是ADD, CLR, EOR, SET等来解决这个问题
现在 arm 的实现 就比较优雅了
#define ATOMIC_OP(op, asm_op) \
static __always_inline void \
__lse_atomic_##op(int i, atomic_t *v) \
{ \
asm volatile( \
__LSE_PREAMBLE \
" " #asm_op " %w[i], %[v]\n" \
: [v] "+Q" (v->counter) \
: [i] "r" (i)); \
}
// ATOMIC_OP(andnot, stclr)
// ATOMIC_OP(or, stset)
// ATOMIC_OP(xor, steor)
// ATOMIC_OP(add, stadd)