inode
在 filesystem 中我们简要介绍了 Unix 文件系统的核心抽象 inode 的概念。我们提到文件系统最核心最重要的工作就是完成从文件名到文件的一个映射: Map<string, File>
- 将文件名映射到索引节点, 我们称为 inode_num, 即
file_path -> inode_num;
- 将 inode 映射到文件, 即
inode_num -> File
这里的 File 也就是 inode, 它应当记录两部分内容, 文件的内容和元数据, 包含的信息主要有:
- 文件类型和权限(mode+premission):文件是目录、普通文件、链接文件,还是特殊设备文件等。
- 文件大小(size in bytes):文件所占字节数。
- 引用计数(nlink):文件被引用的次数,计数为零时inode可以被释放。
- 块指针(block address):文件数据存放的磁盘块编号,可能包括直接块指针、间接块指针、双重间接和三重间接块指针。
除了上述必要的一些 inode 信息外, 还可以选择保存一些其他信息, 比如存储文件的时间戳信息,包括访问时间(access time)、创建时间(creation time)和修改时间(modification time).
考虑到闪存存储介质的写入次数有限,许多只读的现代文件系统在挂载时可以选择不更新访问时间,以减少不必要的磁盘写入.此外,文件系统还会存储文件的所有者信息和所属组的ID,通常以32位整数表示。对于UNIX文件系统,还可能包含设备号等其他元数据,但这些与文件核心操作关系不大。
例如对于一些只读的文件系统, 大量的读还需要修改文件的访问时间, 产生写操作, 因此为了避免不必要的磁盘写入操作可以选择在挂载时选择只读
mount -o ro /dev/mydisk /mnt/mydisk添加
noatime忽略更新 access timemount -o ro,noatime /dev/mydisk /mnt/mydisk
对于上述数据字段大多都可以定长表示, 比如 u32 的 timestamp, u16 的 mode/uid/gid, 而不定长的字段就是 char * 类型的文件名和文件内容. 其中文件内容的数据保存在数据块中, inode 只需要记录访问该数据块的序号即可。而对于文件名的管理可以将其从文件对应的 inode 字段中脱离出来, 我们将目录视为一种特殊的文件, 其文件内容就是目录中的所有文件名, 因此不定长的文件名作为目录的文件内容以数据块的方式记录。因此文件名不存储在inode中,而是存储在目录的inode中
关于目录中文件名的存储方式见后文 directory
ext2 inode
我们先来介绍一下 ext2 的 inode 设计, 可以帮助我们对抽象的 inode 有一个较为清晰结构体字段的认识。虽然目前说这已经是一种过时的设计了, 但是很有意思
完整的 ext2 inode 结构如下, 其中 __le 开头的代表小端存储的数据
struct ext2_inode {
__le16 i_mode; /* 文件模式 */
__le16 i_uid; /* 所有者用户ID的低16位 */
__le32 i_size; /* 以字节为单位的文件大小 */
__le32 i_atime; /* 最后访问时间 */
__le32 i_ctime; /* 创建时间 */
__le32 i_mtime; /* 最后修改时间 */
__le32 i_dtime; /* 删除时间 */
__le16 i_gid; /* 组ID的低16位 */
__le16 i_links_count; /* 链接计数 */
__le32 i_blocks; /* 块计数 */
__le32 i_flags; /* 文件标志 */
union {
struct {
__le32 l_i_reserved1;
} linux1;
struct {
__le32 h_i_translator;
} hurd1;
struct {
__le32 m_i_reserved1;
} masix1;
} osd1; /* 操作系统依赖1 */
__le32 i_block[EXT2_N_BLOCKS]; /* 指向块的指针 */
__le32 i_generation; /* 文件版本(用于NFS) */
__le32 i_file_acl; /* 文件ACL */
__le32 i_dir_acl; /* 目录ACL */
__le32 i_faddr; /* 文件碎片地址 */
union {
struct {
__u8 l_i_frag; /* 碎片编号 */
__u8 l_i_fsize; /* 碎片大小 */
__u16 i_pad1;
__le16 l_i_uid_high; /* 这两个字段 */
__le16 l_i_gid_high; /* 是reserved2[0] */
__u32 l_i_reserved2;
} linux2;
struct {
__u8 h_i_frag; /* 碎片编号 */
__u8 h_i_fsize; /* 碎片大小 */
__le16 h_i_mode_high;
__le16 h_i_uid_high;
__le16 h_i_gid_high;
__le32 h_i_author;
} hurd2;
struct {
__u8 m_i_frag; /* 碎片编号 */
__u8 m_i_fsize; /* 碎片大小 */
__u16 m_pad1;
__u32 m_i_reserved2[2];
} masix2;
} osd2; /* 操作系统依赖2 */
};该字段位于源码中 fs/ext2/ext2.h, linux kernel 也有一个通用的 inode 字段, 但它是为内核使用的, 每一个文件系统应当实现自己的 struct inode
字段含义见 ext2 inode table
其中可以计算得到 sizeof(struct ext2_inode) = 128. inode 简化后的字段如下所示, 其中 mode/uid/timestamps 等元数据字段前文已经介绍过了, 最重要的是这里的 i_block 字段, 这是一个长度为 15 的数组, 前 12 位为直接引用块, 每一个分别对应一个 data block 的 block_number. 后3位分别是1/2/3级间接引用块。间接引用块指向的块全部用来保存 block_number, 在 ext2 时代 block_number 为 32 位, 因此每一个 block 可以保存 256 个 block_number, 二级和三级同理。
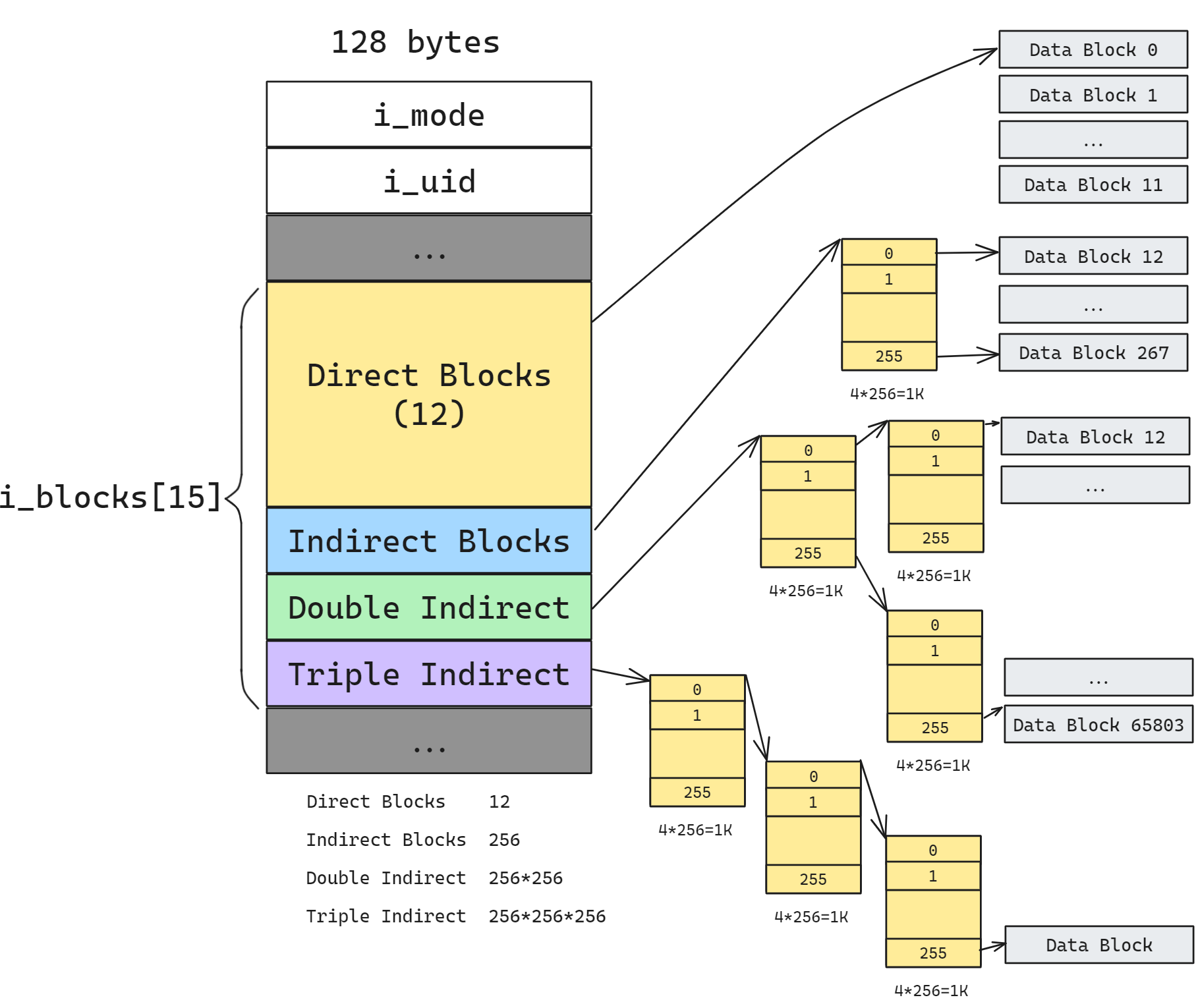
稍微一计算可以得出, 如果全部占满的情况下, 最大的文件大小为 (12 + 256 + 256x256 + 256x256x256)x1KB ~= 16GB. ext2_inode 结构体还有一个字段为 i_blocks 用于记录该文件占用的块个数, 由于各级间接块的下属子块数量是固定的, 因此可以根据块个数判断出来使用了哪些部分, 也可以根据文件大小来计算应该使用几级间接引用块来保存
比如 269, 那么就是 12 + 256 + 1, 即 12 Direct Block + 1 Indirect Block + 1 Double Block 的第一个子块的第一项
同理如果要 seek(1MB) 的位置也可以通过相同的方式找到对应的块
ext2 非常适合小文件(12KB)以内的文件, 因为只需要查找到 inode 即可从中直接读取出所有数据块的 block_number, 然后就可以通过偏移量找到对应的地址了; 如果再大的文件那么就需要访问间接块, 从而会因为多几次间接查找带来一定的开销
从 ext2 的 inode 结构我们可以看出, 文件的追加很容易, 但是插入很麻烦(因为需要整体移动). 文件大小 != 占用磁盘大小, 大多数情况下占用的磁盘大小要比文件大小大(因为会有空余的块). 但是也可能相反, 比如说对于一个稀疏文件, 即 lseek(1MB) + write(1KB)
ext4 inode
在ext4文件系统中,传统的间接块(indirect block)已被废弃,转而使用扩展树(extend tree,其中"extend"在此处可译为"扩展")来提高大文件性能并减少文件碎片。
扩展树通过将连续的物理块视为一段扩展(extent),简化了传统文件系统中使用单次、二次和三次间接块映射的方式。例如,一个文件的200个连续块可以仅通过一条记录 (0, 200) 来表示,而不是在间接块或双重间接块中逐个列出。
其中 ext4_extent 的数据结构如下所示
struct ext4_extent {
__le32 ee_block; /* 文件逻辑块号的第一个块,表示这个扩展的起始块 */
__le16 ee_len; /* 这个扩展覆盖的数据块数量 */
__le16 ee_start_hi; /* 物理块号的高 16 位 */
__le32 ee_start_lo; /* 物理块号的低 32 位 */
};根据 ext4 文档 信息可知, 其中 ee_len 字段用于表示范围覆盖的块数。如果此字段的值为 <= 32768,则认为该块没有被使用。如果字段的值为 > 32768,则数据块正在使用,实际数据块长度为 ee_len - 32768. 因此计算得到扩展块的最大大小为 2^(16-1) x 2^12(4KB) = 128MB, 因此 ext4 中的单个扩展块最多可以映射 128 MiB 的连续空间, 可以看出ext4 对于连续分配的大文件比较友好
ext4 是 ext2 兼容的, 所有 ext2 inode 具有的数据结构成员 ext4 都具备。同样采用 i_block[15] 来保存文件的数据, 但与 ext2 的所采用的间接引用块不同的是, 这60个字节(4*15)用来保存 4 个 ext4_extent 和 1 个 ext4_extent_header
sizeof(ext4_extent) = 12
sizeof(ext4_extent_header) = 12
12x5 = 60
struct ext4_extent_header {
__le16 eh_magic; /* 魔数,用于识别扩展索引的格式 */
__le16 eh_entries; /* 有效的条目数量,表示当前有多少条目在使用 */
__le16 eh_max; /* 存储空间的最大容量,以条目数计 */
__le16 eh_depth; /* 树的深度,表示是否有实际的底层块 */
__le32 eh_generation; /* 扩展索引树的版本号,用于确保一致性 */
};因此一个 inode 中可以直接保存四个 extent 结构。如果有超过 4 个 extent, 此时扩展索引可以形成一个树状结构。
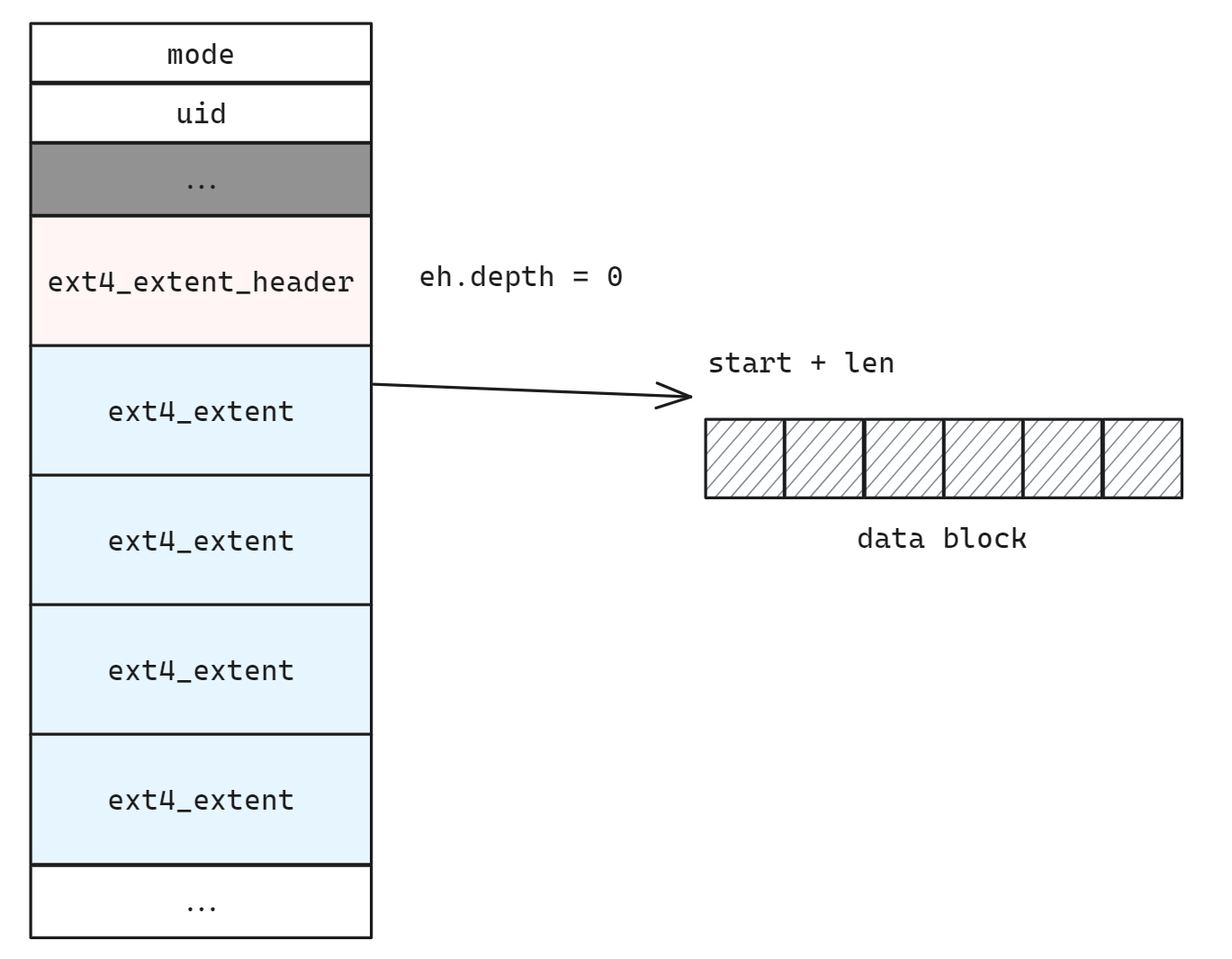
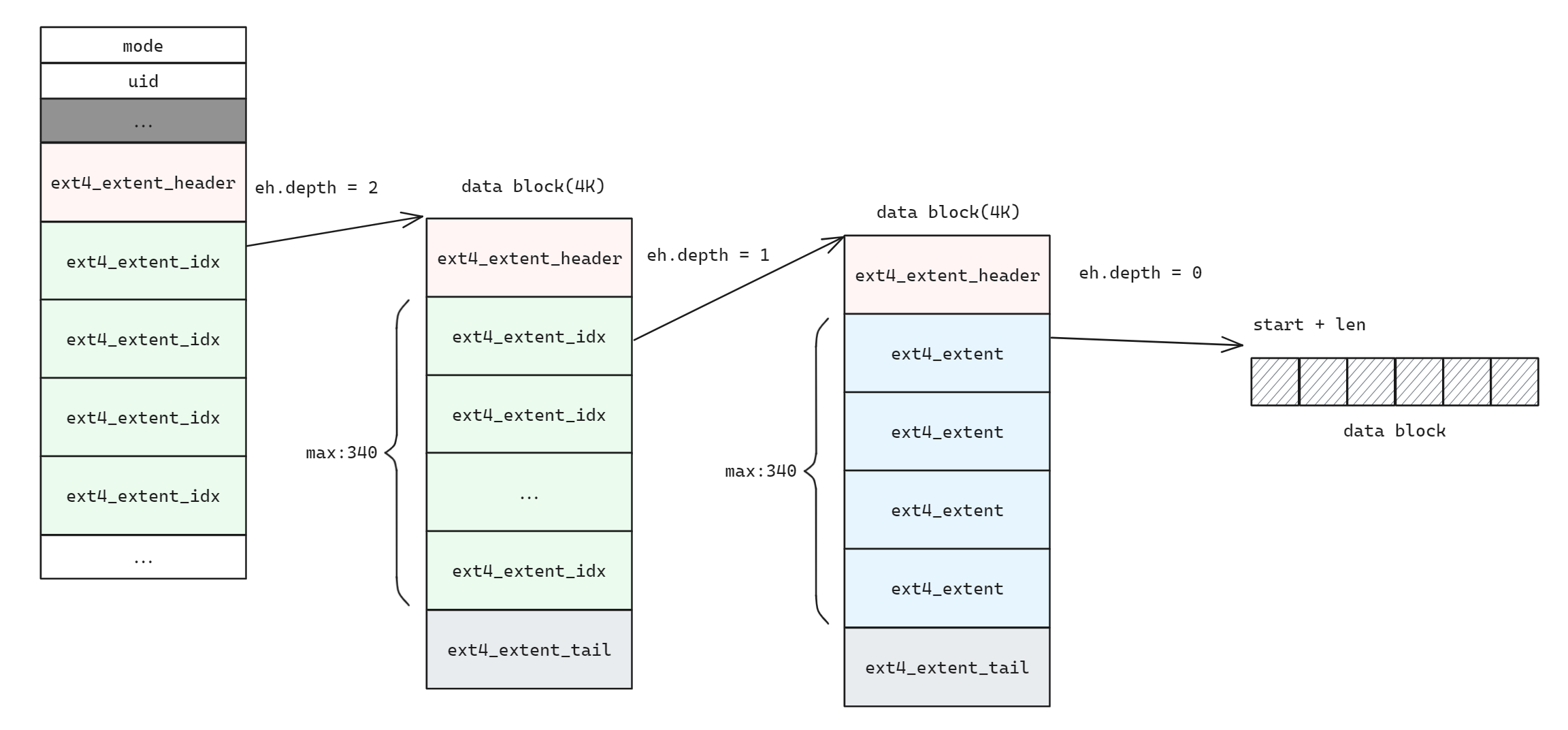
关于 ext4 的更多信息详见 ext4
inode ratio
我们知道文件是以数据块为基本单位划分并保存在磁盘当中, 每个数据块是 4K 大小。在文件系统的简单实现当中我们简单的将整个磁盘的 64 个数据块划分为了 5 个 inode 区域和 56 个数据块区

此时我们考虑一个问题: 虽然磁盘中有很多数据块, 但是由于存在大文件占据很多个数据块, 但是每个文件只消耗 1 个 inode; 如果为每一个数据块都预留一个对应的 inode 空间, 那么可能会产生很大的浪费. 因此文件系统需要根据磁盘的容量来按比例确定需要分配多少空间的留给 inode table. 这个比例就是 inode ratio
文件系统的 inode_num 是一个有限位的无符号整数(ext4中为48位), 而数据块理论来说可以是无限多的(可以无限加磁盘容量), 也不可能真的一一映射
我们可以通过 cat /etc/mke2fs.conf 查看 ext4 的默认 inode ratio 为 16384(16K), 也就是说估算的平均文件体积是 16KB. 如果大多数文件小于这个体积则会优先耗尽 inode 空间而磁盘还有剩余空间, 反之大文件则会优先耗尽磁盘空间而剩余 inode 空间
16K的ratio相当于4:1, 如果总共的数据块有 256K, 那么就应当有 64K 个 inode 的空间, 大概需要占据 64K x 256(B)/4KB = 4096 个数据块用来保存 inode table
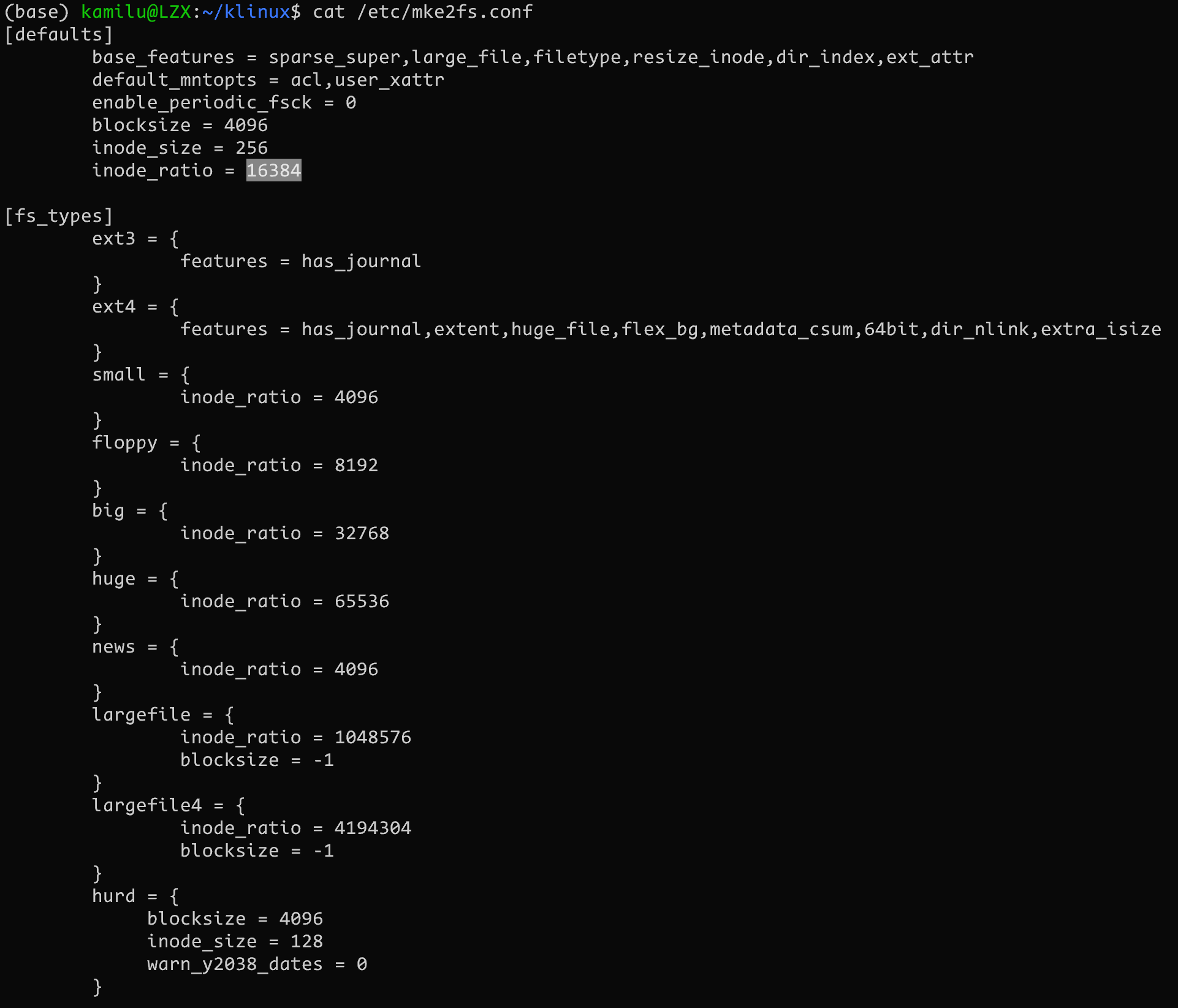
在这段配置文本中,inode_ratio 是用来定义不同文件系统类型或配置的inode与磁盘块之间的比例。每个文件系统类型或配置(如 small, floppy, big, huge, news, largefile, largefile4, hurd 对应从小文件到大文件的适用场景)有不同的inode_ratio值,这取决于它们设计时的预期用途和性能特点。
每个配置项的inode_ratio值都需要根据实际的存储需求和预期的文件大小来设置。
- 较低的
inode_ratio值意味着每个inode占用较少的磁盘空间,从而可以在相同的磁盘空间内存储更多的文件,但每个文件的元数据占用空间会减少。
- 较高的
inode_ratio值意味着每个inode占用更多的磁盘空间,适合存储较少的大文件,因为每个inode可以存储更多的元数据。
可以使用
df -i来查看磁盘和分区的 inode 的使用情况
链接
在文件系统中,链接(Link)是一种文件,它指向另一个文件。链接主要有两种类型:软链接(也称为符号链接,Symbolic Link)和硬链接(Hard Link).它们之间的主要区别如下:
- 软链接(Symbolic Link):
- 软链接是一个特殊的文件,它包含了另一个文件或目录的路径。
- 软链接可以跨文件系统,而硬链接则不能。
- 删除原始文件后,软链接将不再有效,因为软链接只是一个指向原始文件的路径。
- 软链接可以指向文件,也可以指向目录。
- 软链接在文件系统中被当作一个独立的文件存在。
- 硬链接(Hard Link):
- 硬链接直接指向文件的数据位置,它与原始文件共享存储空间。
- 硬链接不能跨文件系统,必须在同一个文件系统中。
- 删除原始文件,硬链接仍然有效,因为它们指向的是同一个数据位置。
- 硬链接不能指向目录,只能指向文件。
- 硬链接在文件系统中不是独立的文件,它们共享相同的索引节点(inode).
- 权限和属性:
- 对于软链接,文件权限和属性通常与链接文件本身的权限和属性相关,而不是它所指向的文件。
- 对于硬链接,文件权限和属性与原始文件相同,因为它们实际上是同一个文件。
- 删除行为:
- 删除软链接不会影响原始文件,但原始文件被删除后,软链接会变成"悬挂的链接"(dangling link).
- 删除硬链接会减少原始文件的链接计数,只有当所有硬链接都被删除后,原始文件才会被删除。
- 创建方式:
- 在Linux系统中,可以使用
ln -s命令创建软链接。
- 创建硬链接通常使用
ln命令,不加任何选项。
- 在Linux系统中,可以使用
- 使用场景:
- 软链接常用于为文件或目录创建一个快捷方式,或者在不同的位置提供对同一文件的访问。
- 硬链接一般用于备份文件,或者在不复制数据的情况下创建文件的另一个名称。