directory
在 inode 中提到, 由于文件名是不定长的, 因此不好直接保存在 inode 当中, 因此文件系统通常选择将文件名存储在其对应的目录下, 将目录视为一种特殊的文件, 其文件内容就是目录中的所有文件名
本文来介绍一下目录对应的数据格式以及查找定位文件的流程
目录项的结构
目录的数据结构是一个链表, 其中每一项都是 ext4_dir_entry_2. ext4 的 dentry 结构体字段如下
这里的 _2 是为了兼容老 ext2 的 ext4_dir_entry
#define EXT4_NAME_LEN 255
// https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout#Directory_Entries
struct ext4_dir_entry_2 {
__le32 inode_idx; /* Inode number: 存储文件的索引节点号 */
__le16 rec_len; /* Directory entry length: 存储目录项的总长度 */
__u8 name_len; /* Name length: 存储文件名的长度 */
__u8 file_type; /* File type: 存储文件类型 */
char name[EXT4_NAME_LEN]; /* File name: 存储文件名,最大长度由EXT4_NAME_LEN定义 */
};
struct ext4_dir_entry_tail {
__le32 det_reserved_zero1; // Inode number, which must be zero.
__le16 det_rec_len; // Length of this directory entry, which must be 12
__u8 det_reserved_zero2; // Length of the file name, which must be zero.
__u8 det_reserved_ft; // File type, which must be 0xDE.
__le32 det_checksum; // Directory leaf block checksum.
};目录的结构如下图所示:

其中 rec_len 字段为整个结构体的长度, 可以计算得到最大长度为 263, 但是并不是所有文件都需要全部的 name[255], name_len 字段表示实际的文件名长度, 如果文件名小于这个长度会直接截断然后 padding 到内存对齐的位置(4 bytes align), 由 rec_len 来确定下一个 dentry 的开头位置。
目录的最后一项以 ext4_dir_entry_tail 结尾, 它的结构体内存分布以与 ext4_dir_entry_2 相似, 但是所有字段都是确定的, 其中 inode_idx == 0 && name_len == 0 && file_type == 0xDE 可以作为目录达到最后一项的判断
可以在 <limit.h> 头文件中查看到文件名和路径的最大长度限制, 在编程中可以使用这两个宏来做一些限制
#include <limit.h>
#define NAME_MAX 255
#define PATH_MAX 4096目录条目不会在文件数据块之间拆分, 也就是说如果该数据块剩余空间不足, 那么 dentry 不会截断存放, 而是需要找到另一个空间足够的数据块保存
目录项的创建
接下来我们看一下目录项创建和销毁的流程, 假设我们执行如下两个命令
touch a
mv a b此时最开始目录中只有 . 和 .. 两个目录项, 由 .. 管理剩余的磁盘空间

当执行 touch 后创建了一个新的文件 "a", 创建 inode 后此时需要在目录中创建一个新的 dentry, 填入文件名 "a", 对应的 inode_num 等字段。然后修改前面 .. 的 rec_len 字段
执行 mv 后并不是直接修改 a 的 dentry, 而是重新创建一个新的 dentry 并删除之前的
文件查找
前文提到文件系统最核心最重要的工作就是完成从文件名到文件的一个映射: Map<string, File>
- 将文件名映射到索引节点, 我们称为 inode_num, 即
file_path -> inode_num;
- 将 inode 映射到文件, 即
inode_num -> File
那么如何从一个文件名找到对应的 inode_num 呢? 整个流程如下所示
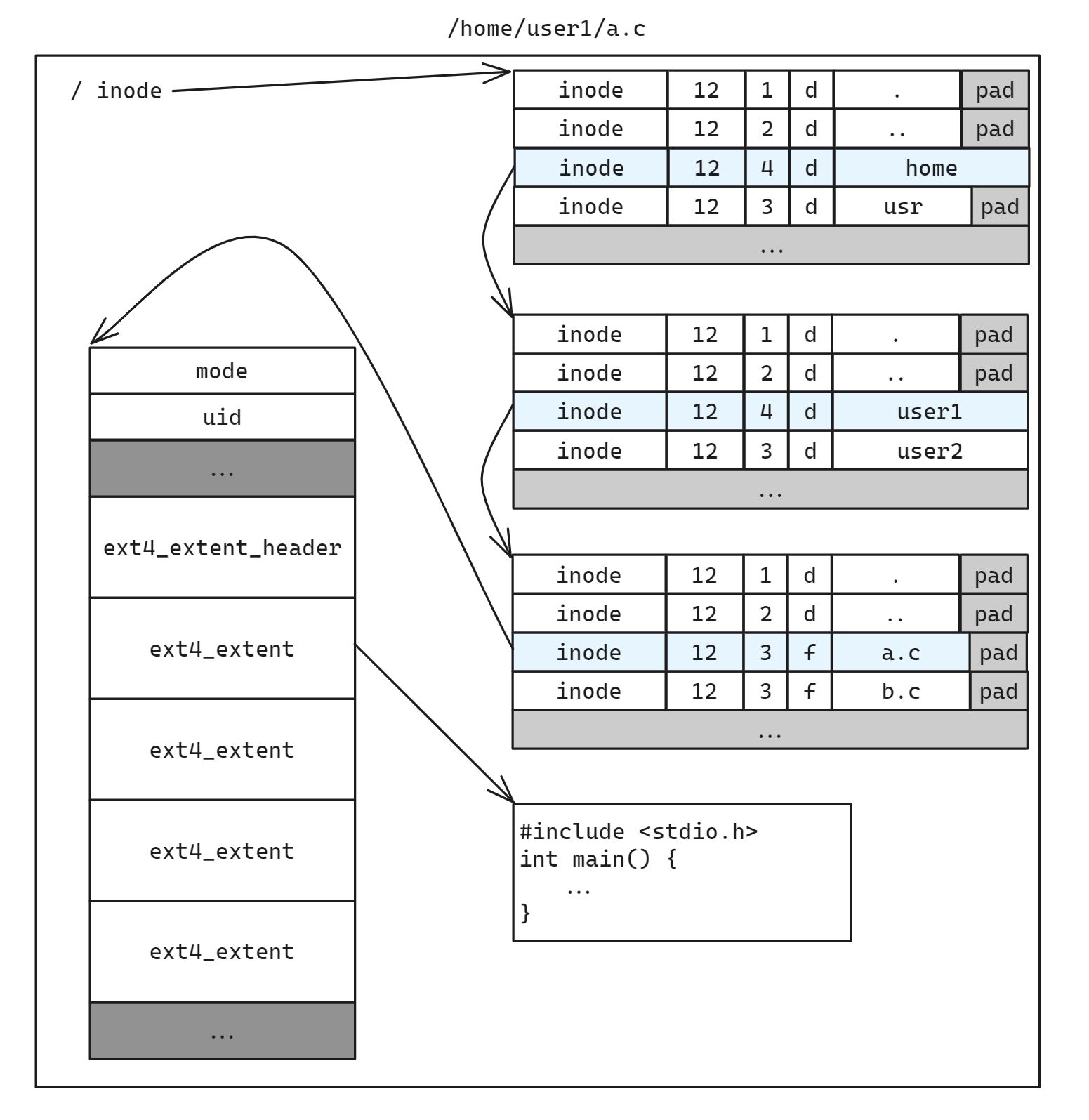
对于文件名 /home/user1/a.c, 首先会按照分隔符 / 解析其文件路径。文件系统已知根目录 / 的 inode_num, 可以通过superblock的信息和地址偏移量计算找到根目录的数据块
这一步在 filesysem 的实现中已经介绍过了
然后遍历所有的目录项, 找到名字为 home 的目录项。通过其 inode_num 再次找到 home 目录的数据块
如此递归的查找下去, 如果未找到目录项则报错返回, 直到找到最后一项 a.c. 其 dentry 的 file_type 类型为普通文件, 所以通过其 inode_num 找到的是其对应的 inode 结构。最后根据该结构的 i_blocks 属性读取到对应的文件数据块所在的内容
上述的情况是假设每一层目录都处于同一个文件系统当中, 如果
/和/home挂载在不同的文件系统, 那么切换路径的时候需要重新通过 superblock 来确定根目录的位置
可以明显看出这种查找的复杂度为 O(MN), M 为目录的深度, N 为目录中项的个数。通常来说 M 不会很大(即不会很深), 因此 N 会成为查找时影响性能的主要原因。N 的查找和文件大小无关, 因为目录中的文件数量/文件名多从而影响查找的性能
目录中的子目录有数量上限, 因为子目录存在对于上级目录的 .. 引用, 而 ext4 inode 中的 i_links_count 字段是一个 16 bit 的长度, 因此每个目录的子目录上限就是 2^16 个。普通文件并不会增加对目录的引用计数。
目录中数据块的不连续性也会导致文件存储效率低下,因为目录项的修改/删除都会导致目录内部的碎片, 所以当目录项需要更多空间时,可能会被迫存放在距离原始块很远的地方。为了避免目录碎片化,可以预先分配目录块,例如通过创建大量空文件来提前占用空间,从而提高文件管理的连续性和效率。
由于大目录中线性查找的性能问题, 在 2002 年开启了使用 HashMap 的提案, 对于大型目录来说可以完成 HashMap<string, inode_num> 的 O(1) 复杂度的查找速度。
目录的体积
目录的大小默认不会自动收缩。如下的命令在 tmp 目录下创建了 1000 个文件, 然后删除它们, 但是发现 tmp 目录的体积仍然是 20480
(base) kamilu@LZX:~/klinux$ mkdir tmp
(base) kamilu@LZX:~/klinux$ ls -l | grep tmp
drwxr-xr-x 2 kamilu kamilu 4096 May 14 23:27 tmp
(base) kamilu@LZX:~/klinux$ mkdir tmp/{1..1000}
(base) kamilu@LZX:~/klinux$ ls -l | grep tmp
drwxr-xr-x 1002 kamilu kamilu 20480 May 14 23:28 tmp
(base) kamilu@LZX:~/klinux$ rm -r tmp/*
(base) kamilu@LZX:~/klinux$ ls -l | grep tmp
drwxr-xr-x 2 kamilu kamilu 20480 May 14 23:28 tmp
(base) kamilu@LZX:~/klinux$ ls tmp
(base) kamilu@LZX:~/klinux$rsync 会在复制文件之前提前将目录创建出来, 可以有效减少大目录下的目录碎片问题
目录 API
和文件系统相关的 API, 包括 open/close/read/write大致如下所示
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int open(const char *pathname, int flags);
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
int close(int fd);
int fstat(int fd, struct stat *statbuf);可以使用 open/fstat 查看一个目录, 但是 read 会返回错误码 EISDIR, 因为目录的格式是文件系统相关的, 并不是 read 适合处理的这种简单字节流, buf/count 参数也不好传参。因此操作系统单独为目录设计了一套 API
#include <sys/types.h>
#include <dirent.h>
DIR *opendir(const char *name);
struct dirent *readdir(DIR *dirp);
int closedir(DIR *dirp);
// 上面的 API 是给用户空间使用的, LIBC 会在底层调用 getdents64 完成对目录的操作
ssize_t getdents64(int fd, void *dirp, size_t count);下面两个结构体是对于 dentry 的一层抽象, 用户使用的是 dirent, 而内核使用的是 linux_dirent64
dirent 中的
d_name字段是 256 而非前面提到的 255 是因为需要以\0结尾
// user api struct
struct dirent {
ino_t d_ino; /* Inode number */
off_t d_off; /* Not an offset; see below */
unsigned short d_reclen; /* Length of this record */
unsigned char d_type; /* Type of file; not supported
by all filesystem types */
char d_name[256]; /* Null-terminated filename */
};
// kernel api struct
struct linux_dirent64 {
ino64_t d_ino; /* 64-bit inode number */
off64_t d_off; /* 64-bit offset to next structure */
unsigned short d_reclen; /* Size of this dirent */
unsigned char d_type; /* File type */
char d_name[]; /* Filename (null-terminated) */
};