multicore
多核处理器的背景
提高处理器性能通常的办法是提高主频, 每秒钟算的次数变多了自然性能就提高了,早期intel的奔腾系列和AMD的K5 K6系列都在做提升频率的军备竞赛,并且由AMD K7化身的速龙处理器在2000年抢先intel一步率先突破 1GHz 大关。
由于时钟速度受到流水线中最长、最慢阶段的限制,所以有一种做法是将比较长比较慢的流水线逻辑门进行细分,从而将流水线转换为具有更多短阶段的更深的超流水线
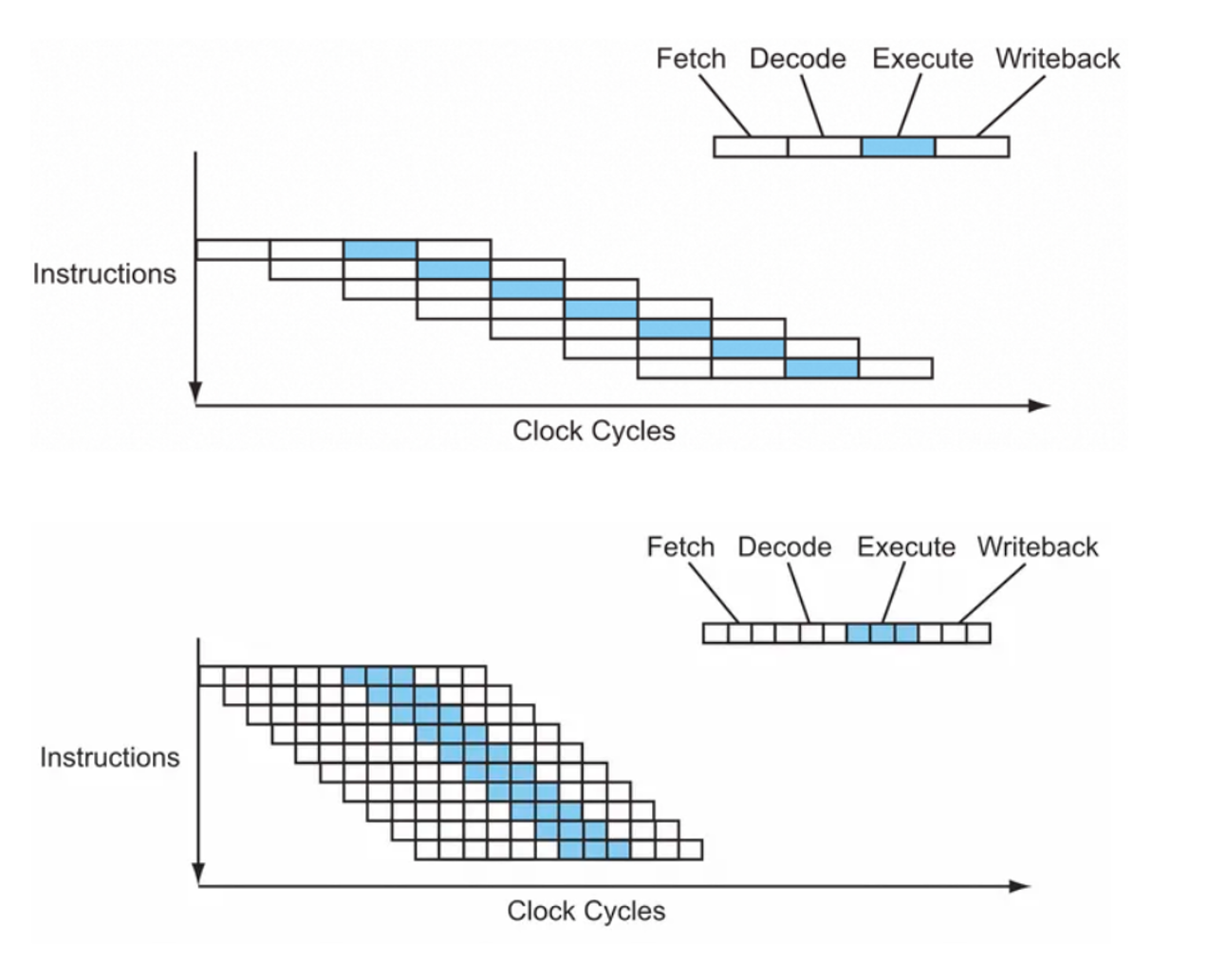
为了战胜AMD,Intel推出的奔腾四(P4)处理器采用的NetBrust架构就开始疯狂的堆流水线来提高主频,直接把频率提到了1.5GHz,它所使用的核心有三个发展阶段
- 第一代P4威廉核心(Willamette)只有13级流水线,频率基本没有上2G,性能中规中矩;
- 第二代P4北木核心(Northwoog)使用了20级流水线,这个级数比较符合当时的处理能力,当时也成功地把AMD速龙XP系列CPU压制住了,北木被认为很成功的一个架构
- 第三代P4波塞冬核心(Prescott)又进一步把流水线长度增加到了31级,频率也来到了惊人的3.8GHz.按照当时的预测,奔腾四在该架构下,最终可以把主频提高到10GHz.但由于流水线过长,使得单位频率效能低下, CPU计算资源未被充分利用,分支预测失败带来的惩罚也很大,性能上反而还不如早些时推出的产品;加上由于缓存的增加和漏电流控制不利使得功耗大幅度增加, 散热问题也越来越成为一个无法逾越的障碍。在芯片功耗超过150瓦后,现有的风冷散热系统已经无法满足散热的需要,当时的奔腾四至尊版最高功耗可达135瓦,高频率所带来的高发热量会导致芯片运行不稳定,所以最终奔腾四的最高频率也被定格在了3.8GHz

总结一下过去几十年的处理器发展历史我们可以看到其实从单核到多核是一种历史必然,现代计算机实现技术的基础核心是以晶体管为基本单元的平面集成电路,非常有名的摩尔定律指出集成电路芯片上所集成的晶体管数目每隔18个月就翻一倍
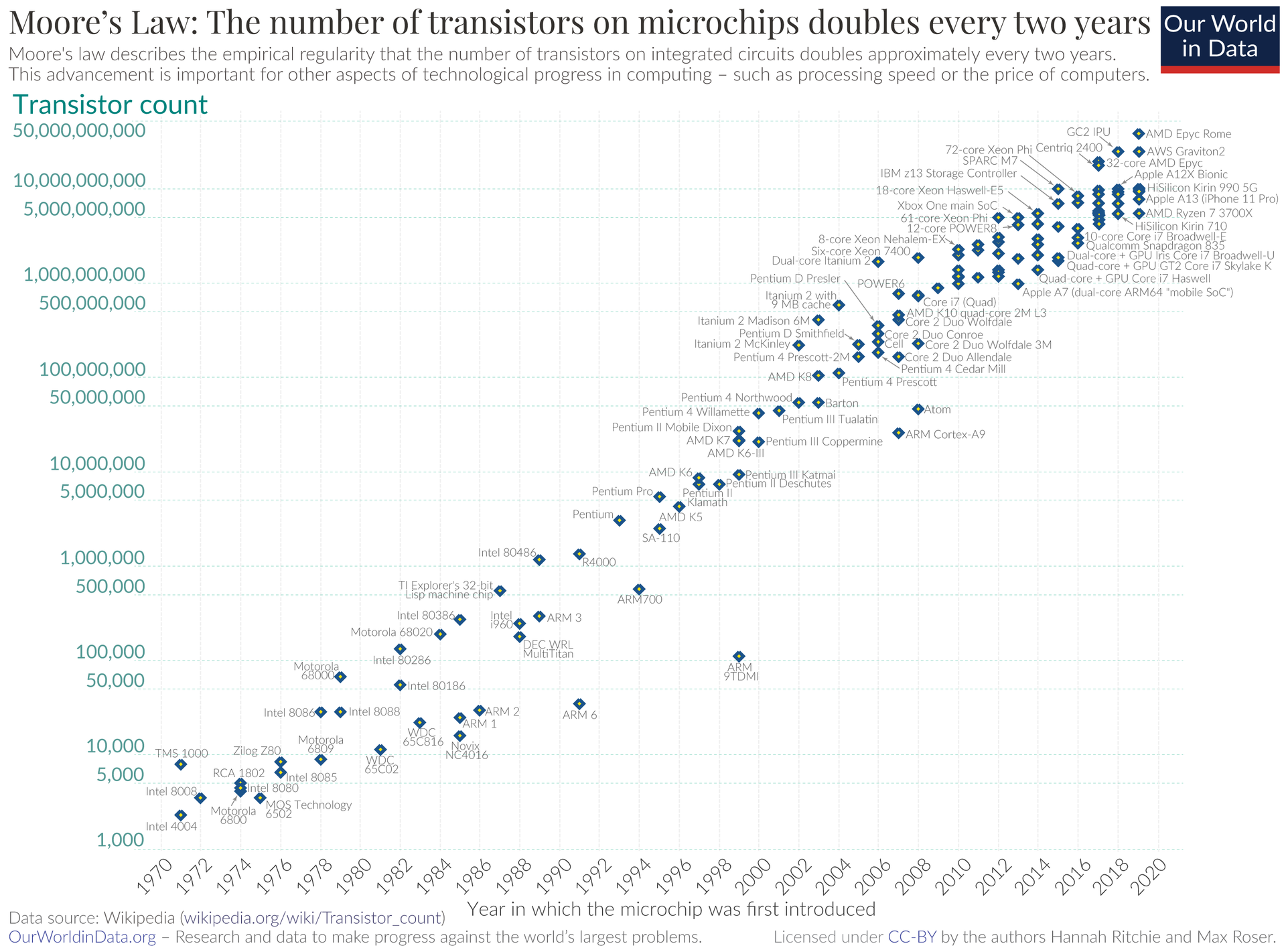
指数式增长速度是非常可怕的, 因此摩尔定律是不可能永远或者长期无限发展下去的,这个定律能维持50余年,已经堪称集成电路设计制造人员创造的奇迹。我们可以看到在早些时候这里的点还很稀疏,基本上每两年芯片上的晶体管数量就可以翻一倍,但这种指数级的增长是很可怕的,近些年摩尔定律的速度已经放缓了,很多人声称摩尔定律已经失效、集成电路进入后摩尔时代,但芯片设计制造人员一直在不断改进设计与制造工艺为摩尔定律续命。未来CPU的发展趋势应该是降低功耗、优化性能设计、提高功效等,而不是单纯的堆叠晶体管数量。
频率只是CPU性能指标之一而已, 架构先进程度, 制程工艺, 缓存大小快慢, 核心数量等等都是判断一个 CPU 是否优秀的重要指标
除了摩尔定律增速放缓带来的晶体管数量有限,前面我们提到的通过拉长流水线去单纯的提升主频,也无法明显提升系统整体性能,反而会导致大幅的功率提升以及芯片散热不稳定这样一系列问题
除此之外现在基于WEB的许多应用都要求并行进行, 对并行性技术要求愈来愈高。尤其在网络和服务器方面,很多程序也都会使用多进程或者多进程希望并行的处理一些任务。那么在晶体管数量有限,处理器主频有限的情况下,我们自然就会想到在单芯片上设计多个处理器核来获得成倍的性能提升,此外单核时代时的多处理器系统的并行处理结构、编程模型等可以直接应用于多核处理器上,为研制多核处理器打下了很好的技术基础。
多处理器体系结构
那我们知道提高硬件性能最简单,最便宜的方法之一是在主板上放置多个 CPU,正常我们的PC主板是只有一个CPU插槽,但是很多的服务器主板上都会提供至少两个CPU插槽

在处理并行任务中, 计算和通信都是很重要的环节, 其中我们重点关注多处理器的通信部分。通信模型分为两种:
- 共享地址: 通过 load/store 通信, 需要显式同步, 因为接收核心需要知道存储何时发生
- 消息传送: 通过消息通信, 隐式同步, 因为传输消息的时候就已经完成了同步
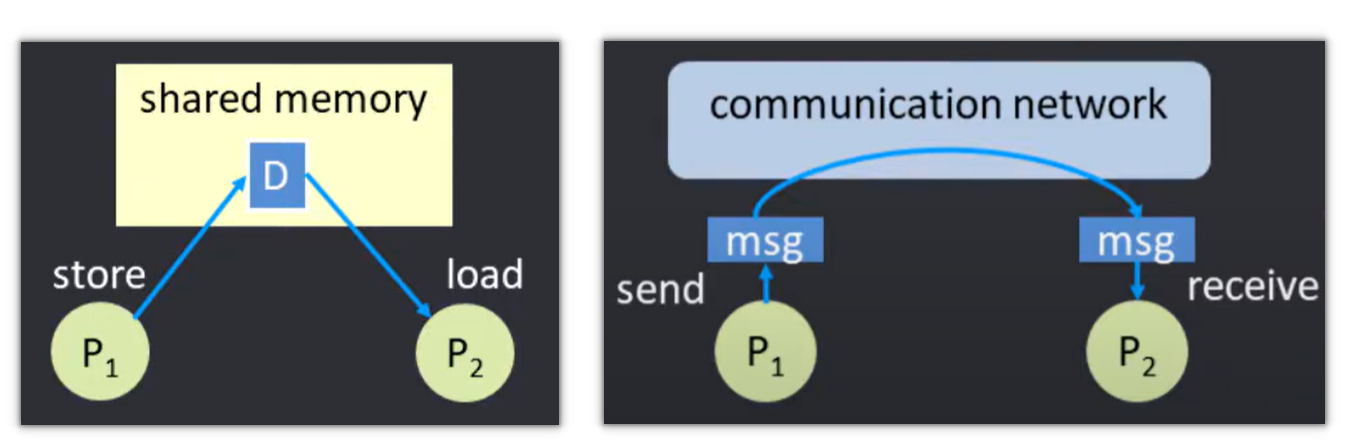
下文我们重点看一下共享地址的多处理器体系结构, 我们应该如何去处理这样多个CPU它们之间的联系呢? 主要为两种模式:
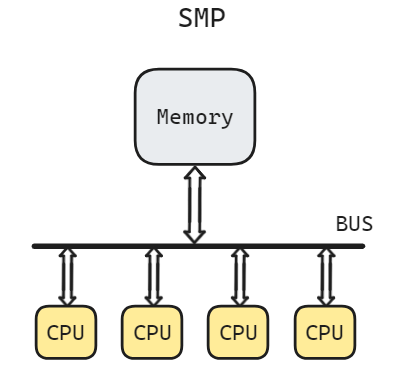
- 第一种方式是SMP, 指的是将多个CPU汇集在同一总线上,我们会将同一个工作平衡地分布到多个CPU上运行,任务在不同CPU上共享着相同的物理内存; 这种内存组织是集中式的; 每个CPU到内存的访问时间是相等的,称为均匀内存访问模型,叫 UMA(uniform memory access)
- 另一种方式是将存储器分散在节点之间, 各节点的 CPU 有本地的内存和远端内存, 访问时间不均匀; 其内存组织形式是分布式的; 内存访问模型是不均匀的, 称为 NUMA(non-uniform memory access)
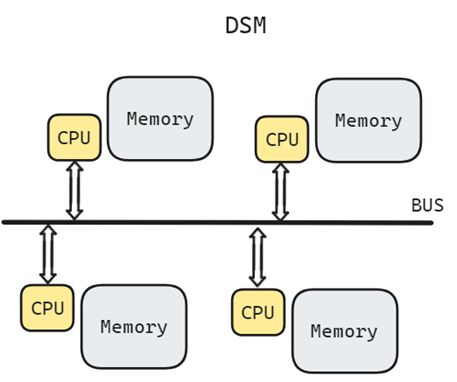
在 SMP(对称多处理技术) 和 DSM(分布式共享存储器) 这两种体系结构中, 线程之间的通信是通过共享地址空间完成的, 存储器的地址统一编码, 任何一个拥有正确寻址权限的处理器都可以向任意存储器位置发出存储器引用. 共享存储器的含义就是指共享地址空间。
UMA
Uniform Memory Access,简称UMA, 即均匀存储器存取模型。所有处理器对所有内存有相等的访问时间
UMA这种方式是最简单直接的,但问题也同样明显, BUS 会成为性能的杀手. 多个 CPU 需要平分总线的带宽, 这显然非常不利于计算。
NUMA
基于总线的计算机系统有一个瓶颈, 有限的带宽会导致可伸缩性问题。系统中添加的CPU越多,每个节点可用的带宽就越少。此外,添加的CPU越多,总线就越长, 延迟也就越高。
因此在另一种设计方法中, 多处理器采用物理分布式存储器, 为了支持更多的处理器, 存储器必须分散在处理器之间, 而不应当是集中式的;
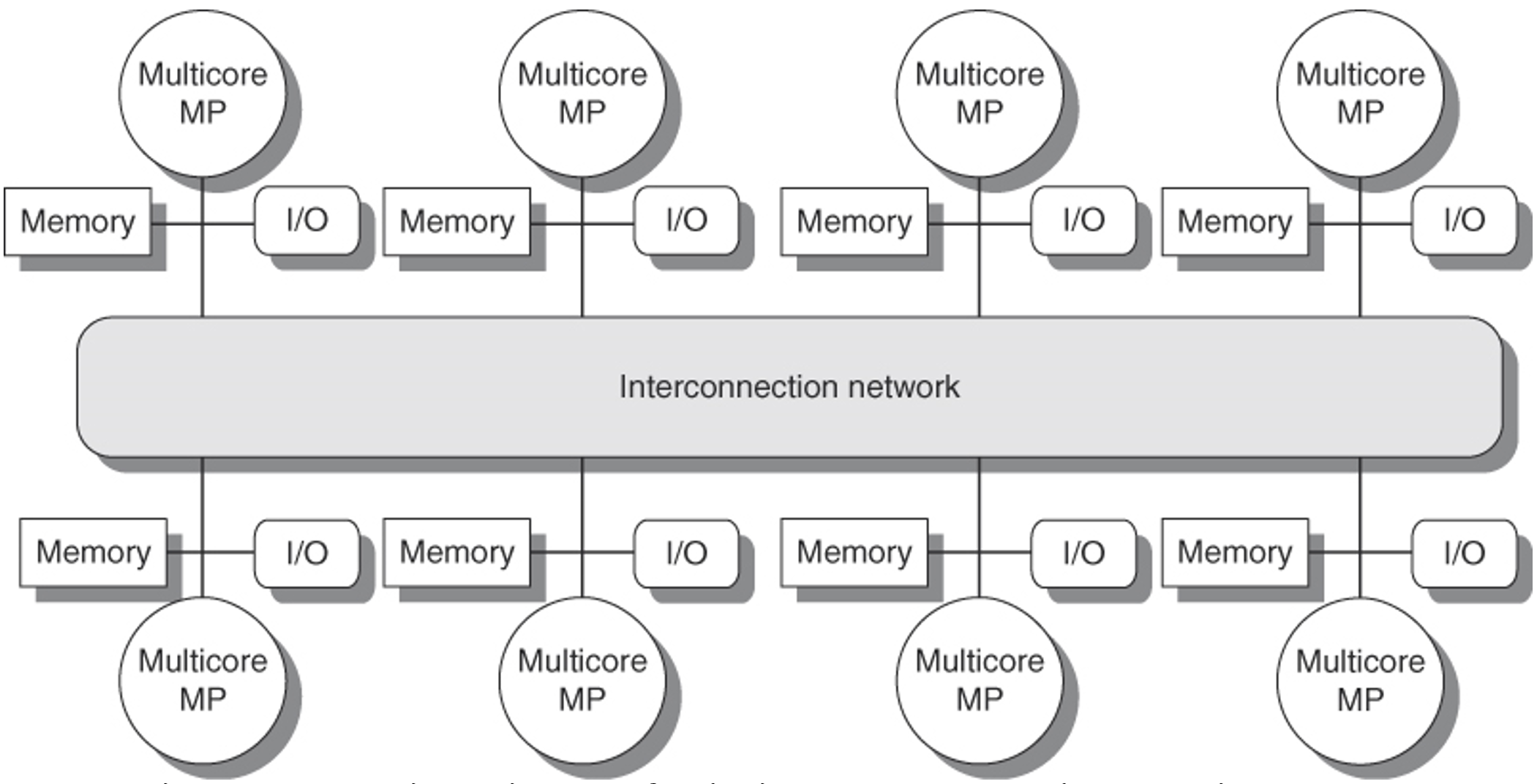
将存储器分散在节点之间, 既增加了带宽, 也缩短了到本地存储器的延迟。DSM 多处理器也被称为 NUMA(非一致存储器访问), 这是因为它的访问时间取决于数据字在存储器的位置。 DSM 的关键缺点是处理器之间传送数据的过程变得复杂了一些, 需要在软件中多花一些力气, 以充分利用分布式存储器提升的存储器带宽。
其中中间部分的互联网络可以是主板上的总线(PCIe/QPI等高速总线), 如下所示
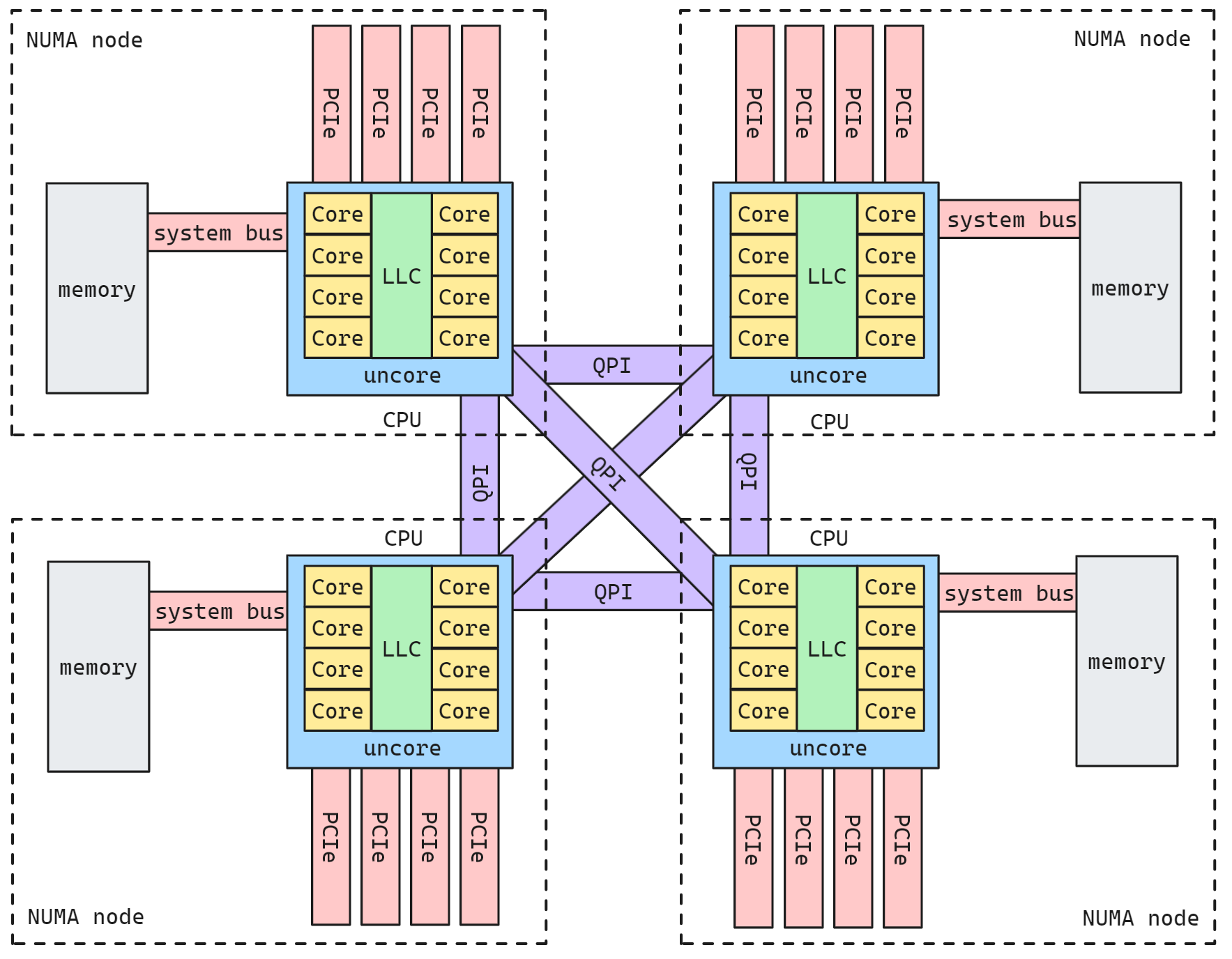
也可以是互联网络, 例如无线网卡, 光纤等
与UMA不同的是,在NUMA中每个处理器有属于自己的本地物理内存(local memory),对于其他CPU来说是远程物理内存(remote memory).一般而言,访问本地物理内存由于路径更短,其访存时间要更短。

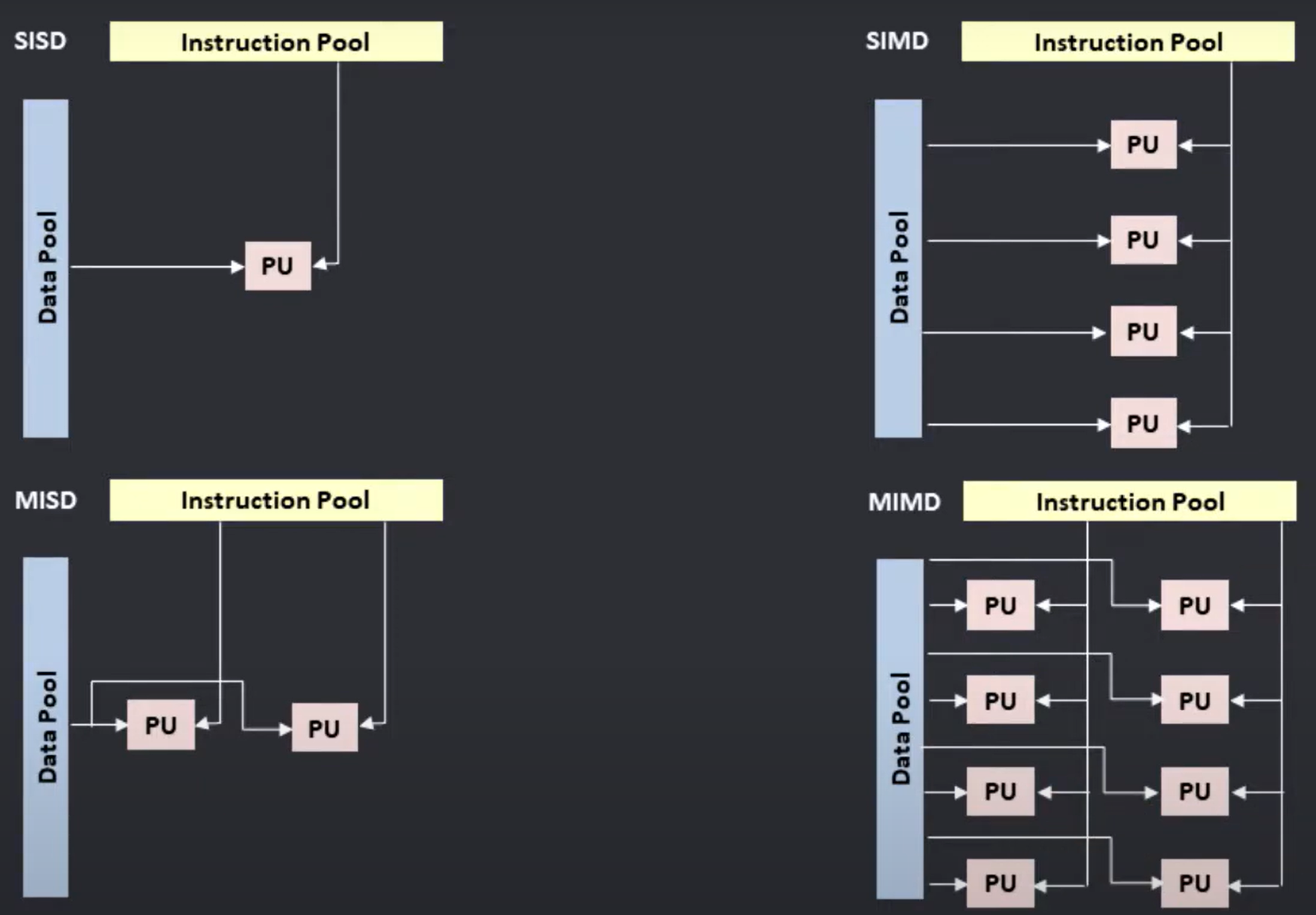
指令和数据
单指令多数据 SIMD 和多指令多数据 MIMD

参考
- 多核多线程处理器的发展及其软件系统架构