cpu
Intel & AMD
- 1947年,固体物理学家WilliamB.Shockley、JohnBardeen和WalterBrattain在贝尔电话实验室共同发明了晶体管,并因此分享了1956年诺贝尔物理奖;
- 1958年,JackKilby在德州仪器(TI)公司发明了集成电路理论模型,并因此获得2000年诺贝尔物理奖;
- 1959年,BobNoyce在仙童(Fairchild)公司发明了平面集成电路,1961年开始批量生产。
- 1965年,时任仙童公司研发实验室主任的摩尔(GordonMooer)在Electronics上撰文,认为集成电路密度大约每两年翻一番,这就是著名的摩尔定律。
AMD 和 intel 渊源很深, 在 1950 年代,很难获得专业的半导体知识, 威廉·肖克利 (William Shockley) 领导下的研究人员面临着无数挑战。员工认为肖克利是一个不称职的商人, Shockley 的项目跳跃倾向导致的巨额研究成本也威胁着公司的未来。综合而言,肖克利半导体公司内部的环境是轻蔑、压力和令人窒息的。泡沫注定随时会破灭。
因此肖克利博士手下有八个工程师, 因为不满于肖克利博士怪异的性格, 于是接受了投资出来自己创办了的仙童半导体公司 (fairchild)

该小组拥有在纸上取得成功所需的所有要素。其中六人拥有博士学位。Noyce是一名半导体研究员,而Grinich则精通电子学。Hoerni带来了强大的科学知识和管理技能。尽管并非所有人都是经验丰富的专业人士,但他们在肖克利手下的学术培训和学徒期的经验给公司带来了巨大的希望。最后,他们共同的观点、远见和青春活力促使他们离开肖克利并创建了自己的公司。

Fairchild 在其最初的成功之后为半导体领域做出了许多其他贡献。其成立后的几十年间不时出现大大小小的发展:
- 为阿波罗太空计划提供动力的电阻晶体管逻辑 IC
- 电荷耦合器件及其 8 位微处理器 F8
- Channel F 视频游戏系统,为 Atari 和任天堂自己的游戏奠定了基础
随着岁月的流逝,仙童自己的命运发生了变化。该公司在 1960 年代后期陷入财务困境_面临来自地区初创公司的新竞争,并因此导致股价下跌。1968年仙童公司总裁罗伯特·诺伊斯(Robert Noyce)与研发主管摩尔(Gordon Moore),工艺专家格鲁夫(Andy Grove)离开仙童成立了intel; 1969年,仙童全球营销总监桑德斯离开仙童创立了AMD;
在1971年 Intel 推出的全球第一颗通用型微处理器4004,由2300个晶体管构成, 这也是世界上第一颗商用 4 位 CPU

1972 年 intel 8008, 1978 年推出第一个 16 位 CPU 8086, 这也是第一颗 x86 架构的 CPU, 随后, Intel 推出了一系列成功的处理器,如80286、80386和80486,这些处理器推动了个人电脑的普及

当时AMD并没有独立研发高端处理器的能力, 但 AMD 仅仅使用一张 intel 8080 的晶圆照片逆向推导出设计原理, 不过还真让 AMD 做出来了, 并命名为 AMD 9080, 而此时正在与Zilog公司Z80处理器对抗的 intel 看到AMD可以仿制出自家的8080处理器便有意将AMD拉到自己魔下作为第二供应商, 于是 intel 在 1976 年和 AMD 签署授权协议, 其中著名的 X86 架构作为协议的一部分也自然而言授权给了 AMD, 因此很长一段时间AMD和intel都还是合作关系。
时间来到 80 年代, 个人PC产业开始蓬勃发展, AMD的出货量也理所当然的迅速膨胀, intel 很快发现技术授权给"缺的就是技术"的AMD会威胁到自己的地位, 于是准备把 AMD 踢出局。但此时的"蓝色巨人"IBM也想借这场东风入局个人PC行业, 但是 IBM 并不能自己制造处理器, 所以就把目标瞄上了在CPU领域如日中天的intel. 但是,如果只使用intel一家公司的CPU, 就可能造成因为没有竞争压力从而使intel坐地起价, 于是,IBM要求intel授权AMD为第二供应商. intel 虽然不情愿, 但是 IBM 毕竟还是那个蓝色巨人, 所以,intel在1982年又和AMD签署了新的技术协议, 这样 AMD又可以生产intel 最新的处理器了, 也是在这个时期生产的CPU上,你甚至可以看到AMD和intel两家的LOGO

就这样,AMD在 Intel 手底下当起了小兵,但就像拿破仑说过的,不想当将军的士兵不是好士兵,AMD对这句话也是深入领悟,于是借着合作时期的授权,AMD在同一年成功研制出最新80286的克隆品AM286,但作为克隆品的AM286,却打败了原版的80286,原因是,当时 Intel 80286设定的最高频率,只有12.5MHz,AMD的AMR6最高频率可达20MHz,而且AM286性能更强的同时,价格却比80286更加便宜

所以在1985年, intel单方面撕毁了合作协议,一脚踢开了AMD,开始自己独家生产新一代的80386处理器。在不久后,AMD便起诉了 Intel ,历史多年,双方又设计近百名证人及千件证物,及万叶各类文书,甚至不惜耗费几千万美元,最终以AMD胜诉才结束了这场旷日持久的官司
但 Intel 也获得拖住AMD的时间,在1994年才许可了AMD生产80386处理器,但这个时候的80386已经是过时产品了,虽然AMD在打官司期间留了一条后路,就是在这期间的1989年,独立研发出兼容80386的AM386,但 Intel 在同一年已经量产了80486处理器,94年更是早已发布新一代的586处理器,AMD可谓毫无胜算
而 Intel 发布的新一代处理器,并没有按照传统命名为586,而是使用了一个全新的名字,奔腾(Pentium),这标志着公司从数字命名转向品牌命名。
AMD这边经历了这场旷日持久的官司以后,急需一场振奋人心的战斗来鼓舞士气,此时他们有两条路可选,一是继续逆向 Intel 处理器,把设计原型推导出来,但面对CPU内部设计逐步复杂,逆向工程需要大量的时间,更何况,即使真的克隆出来了,也可能再次惹上官司,AMD显然不想重蹈覆辙,于是在1996年,推出了全部为自主研发的全新K5架构,但这个AMD全新的K5架构性能却仅仅和92年发布的初代奔腾互有胜负,更不用说同期 Intel 发布的奔腾pro了,K5对奔腾,也标志着AMD和 Intel 开始了正面交锋

时间来到1997年, Intel 在奔腾pro的基础上,稍微提了提频率和缓存,就发布了下一代的继承者,奔腾二。得益于奔腾pro上原本就足够优秀的P6架构,以及多媒体MMX指令集的加持,使得奔腾二还是可以继续称霸市场

准备硬刚 Intel 的AMD在1996年就下血本,花了8.57亿美元收购了NexGen公司,也就是在97年发布了K6,信心满满的叫嚣 Intel 的奔腾二,后续改良版本的K6-2也进步鼓舞了AMD阵营的士气,但 Intel 这边却悄悄给AMD使了个绊子,其实在这之前的时间里,AMD和 Intel 的CPU接口是一模一样的,都是socket接口,但1997年, Intel 推出了具有专利保护的slot1接口,抛弃了一直沿用的socket7接口,这就意味着AMD无法使用 Intel 的slot1接口了,毕竟当时AMD并不具备独立研发独立主板芯片组的能力

此时人们对AMD的认知还是千年老二,虽然K6系列的价格非常优秀,但只要运行浮点运算性能就非常差劲,根本无法招架当时 Intel 的奔腾三,但在1999年,AMD终于拿出了让 Intel 的畏惧的实力,因为在这一年,AMD发布了全新的K7,由K7化身的速龙处理器全面登场,不仅浮点性能改进巨大,时钟频率更是来到了新的高度,2000年3月,搭载雷鸟核心的速龙1000频率更是率先达到1016MHz, 在千禧年抢先intel一步夺得 1GHz 冠军。
被打蒙的 Intel ,随即发布了1.3GHz的铜矿奔腾三,但这个处理器更像是匆忙加压硬超上来的,刚上市就大规模出现问题,各种死机不稳定, Intel 只能匆匆忙忙召回铜矿奔腾三,造成了严重的负面影响,铜矿奔腾三,后来更是被网友调侃成铜渣和矿渣
AMD的速龙1000,也毫无疑问地成为了前几年最快CPU,而 Intel 面对AMD这个曾经只是自己第二供应商的反超,这场AMD率先突破的频率升级革命,显然是让 Intel 颜面扫地,面对一而再再而三的冲击, Intel 终于忍无可忍,于是在2000年底祭出了大杀器奔腾四

而 Intel 的奔腾四才刚上市,就闹出了一个天大的动静,因为它的频率直接来到了1.5GHz,但这是为什么呀,要知道几个月前的铜矿奔腾三,连1.13GHz都稳不住,还bug乱飞,这 Intel 的工程师是吃了什么灵丹妙药了,很快玩家就买到了奔腾四,但买了奔腾四的玩家却发现了有一丝不对劲呀,你说这CPU是1.5GHz吧,好像也没什么问题,但怎么感觉速度没什么提升呀,接口测试傻眼了,好家伙,号称1.5GHz的奔腾四,竟打不过自家上一代的1GHz奔腾三
原来初代奔腾四的 NetBurst 架构把流水线堆到了20级,奔腾三和速龙还都是十级流水线,长流水线的好处是容易把频率做的很高,但是代价是效率下降严重,因为分支预测错误的惩罚严重,而且比性能还要糟糕的是发热还更加严重了,而此时AMD没有选择加入盲目提升频率,而是选择将最新的130NM新工艺,应用在新品速龙XP上面,正经的优化架构,提升性能,从而降低发热,用性价比扛下 Intel 的疯狂反扑
虽然奔腾四的流水线过长,导致效率不尽如人意,但就是仗着频率高,而且提升频率相对容易,性能还是步步紧逼AMD的K7,此时AMD也知道了,仅仅靠优化K7架构是无法完全打败奔腾四的,所以在2003年带来了全新的K8架构,并首次带来了X86-X64的64位技术,并将64位技术,加持在自家的速龙64CPU上面

其实在此之前, Intel 就已经有64位技术了,并命名为IA64(intel architecture),搭载于安腾处理器上面,但 Intel 的64位并不兼容X86处理器,这就导致应用面十分有限,反观AMD的X64,不仅是64位技术还同时兼容X86处理器,毫无疑问的占领了市场,前文提到过X86架构是 Intel 授权给AMD的,这才造就了AMD的高性能处理器的前提
但是现在情况就有些不一样了,AMD把X64授权给了 Intel ,帮助 Intel 有了制造X64高性能处理器的能力,被感动到泪流满面的 Intel 随即将奔腾四的流水线丧心病狂的提高到了31级,频率更是来到3.8GHz, 按照当时的预测,奔腾四在该架构下,最终可以把主频提高到10GHz.但由于流水线过长,使得单位频率效能低下, CPU计算资源未被充分利用, 分支预测失败带来的惩罚也很大,性能上反而还不如早些时推出的产品; 再加上由于缓存的增加和漏电流控制不利使得功耗大幅度增加, 散热问题也越来越成为一个无法逾越的障碍。在芯片功耗超过150瓦后,现有的风冷散热系统已经无法满足散热的需要,当时的奔腾四至尊版最高功耗可达135瓦,高频率所带来的高发热量会导致芯片运行不稳定,所以最终奔腾四的最高频率也被定格在了3.8GHz,时任 Intel CEO贝尔特竟公开下跪道歉,也正式宣布了奔腾四时代结束
奔腾四所使用的核心有三个发展阶段:
- 第一代P4威廉核心(Willamette)只有13级流水线,频率基本没有上2G,性能中规中矩;
- 第二代P4北木核心(Northwoog)使用了20级流水线,这个级数比较符合当时的处理能力,当时也成功地把AMD速龙XP系列CPU压制住了,北木被认为很成功的一个架构
- 第三代P4波塞冬核心(Prescott)又进一步把流水线长度增加到了31级,频率也来到了惊人的3.8GHz
AMD在这次对决中取得了全面的领先,在消费级领域售价屡创新高,高端的速龙64FX系列,售价甚至一度高达999美元,同时AMD还跻身利润更高的服务器市场,抢占 Intel 的市场份额,那段时间的AMD获得可叫一个滋润,都到这个时候了, Intel 还想靠 NetBrust 架构赌一把,他们在2005年发布了一颗双核处理器奔腾D,但本质上奔腾D还是有两颗奔腾四共享FSB(Front-side bus 前端总线)得来的, 发热和性能都不甚理想, 因此又被戏称为胶水双核,

看见 Intel 发布双核处理器,AMD自然也没有闲着呀,仅仅一周后就推出了自己的双核产品,速龙64 X2,凭借出色的价格优势,理所当然地打败了奔腾D,也顺便挑起了真假双核的言论, 可谓把 Intel 迷信 NetBrust 架构火焰彻底浇灭了

Intel 也终于意识到了自己的错误,于是痛定思痛,在2005年制定出了摆钟计划, tick-tock 战略,tick更新制程, tock 革新架构,滴答滴答的像摆钟一样稳步前进,永不停止,靠着摆钟计划的 Intel 逆转了形势
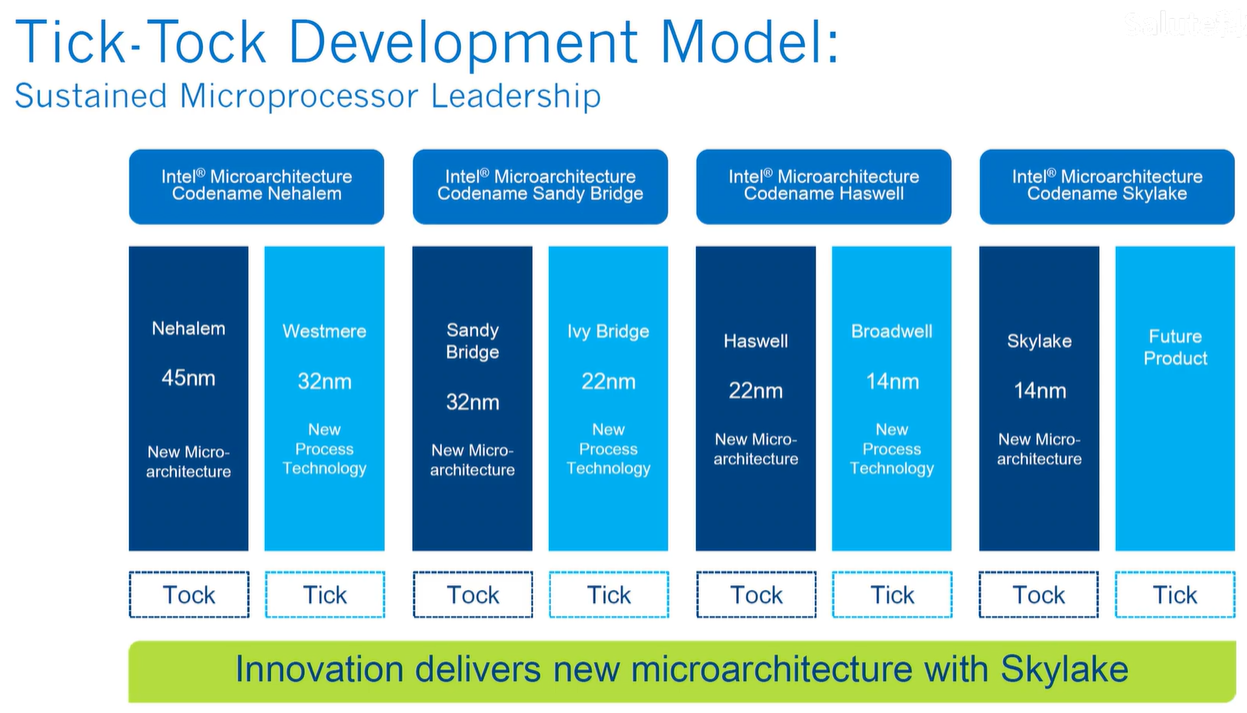
终于在2006年,推出了一个改变战局的全新架构: 酷睿二。酷睿二是 Intel 的一次巨大飞跃,它的解码器升级到了四组; 缓存也较前代奔腾四有了大幅提升,一级缓存来到32KB,二级缓存为两颗核心共享4MB; 加入乱序执行了大幅改进以及预测器的加入,带来的是酷睿二技能直接飞跃40%. 更重要的是,酷睿二抛弃了前代过长的31级流水线设计,只使用精简的14级流水线,又采用65nm的新制程工艺,酷睿二在性能提高40%的同时,功耗也暴跌40%
凭借core2出色的性能,重新在AMD手中夺回了被速龙系列占据多年的第一,AMD这边却是屋漏偏逢连夜雨,AMD在这一年花了54亿美元,收购了当时全球第二大GPU巨头ATI,要知道当时AMD手头只有30亿美元的现金,根本不足以支撑收购费用,所以又向摩根士丹利借款15亿美元,才完成了收购,但CPU研发不仅要钱,显卡研发也要钱呀,刚刚完成收购的AMD元气大伤,根本没有那么多钱支持研发
好不容易重生的 Intel ,自然不会让对手有喘息之机,于是乘胜追击,紧接着在年底发布了首款四核心处理器,core2 quad,AMD自然不甘示弱地随即发布了四核心的翼龙应对,但酷睿二架构实在是太强了,翼龙最终还是没能打败 Intel ,无奈败下阵来,而且翼龙发热量也相对较高,更要命的是还爆出tlb bug,不修复就会影响使用,但修复了就会影响性能,AMD当时还坚持说,tlb bug发生的概率相当之小,在一般应用中根本就不会出现,但对于追求百分百完美的CPU来说,怎么可能容忍影响使用的bug,所以AMD在那个时候信誉一落千丈,也就是从此刻, Intel 对AMD开始了以后,将近10年的压制
在高端市场优势荡然无存,AMD只能重新扛起性价比大旗,调整CPU产品的布局,盘踞在中低端市场,对抗 Intel 的酷睿二和奔腾四,恰巧当时正值双核CPU普及的年代,AMD的速龙64 X2性价比出众,深得消费者的喜爱,其中速龙64 X2 3600+ 就因价格合理,而且还有不错的超频能力,成为了双核普及先锋,但这仅仅是和低端的酷睿216千系列,双核打的有来有回, Intel 还有高端的E7000系列,甚至E8000系列,AMD的速龙64X2双核根本毫无胜算,于是AMD又想到了一个骚招式啊,让生产翼龙四核心的时候,不合格的产品阉割掉一颗核心,做成翼龙三核心处理器,反正四核心里就一颗不合格的核心全丢掉,也浪费,做成三核心翼龙打双核酷睿二岂不美哉? AMD就是靠这样的阉割大法,顺利的进入了45NM时代
尝到甜头的AMD决定继续发挥刀法,将六核心的CPU阉割成四核心的速龙X4640,或者翼龙X4 960 T4核心的再不合格,就阉割成单核心的速龙X3 440,或者双核心的速龙5000,速龙X2220,速龙X27750等双核心,要是再不合格,就阉割成单核心的闪140,买到阉割产品的玩家在折腾一段时间以后,突然嗅到了一丝香气,因为他们发现这些阉割的产品,竟可以将屏蔽的核心再次打开,性能直接提升一个档次,这样的消息已经传出,自然吸引了大批消费者购买,但这毕竟只是在中低端市场取得了一些进展,在这个时间, Intel 早已经用全新划分的I3 I5 I7,发展出了低中高端市场

AMD自然也想破局啊,所以在2011年发布了基于模块化设计理念的推土机架构,AMD认为,随着CPU物理核心数量越来越多,CPU核心面积也会越来越大,功耗更是会成倍增加,传统CMP暴力复制核心的方式
会造成大量重复性的电路,而为了减少电路冗余的最好方法就是整合,通过把两个核心整合在一起,共用一套指令,发热器和解码器及缓存,这听起来好像很厉害,但是AMD还不是把完整的两个核心整合在了一起,而是保留完整的整数单元,但浮点单元为两颗核心共享一个,这就导致推土机架构的CPU单核性能严重受到拖累,后续的打桩机,挖掘机,压路机也都是类似的设计,这根本无法和 Intel 正面硬刚销量上不去,还有为研发继续砸钱,这样的失败带来的是资金的短缺
AMD 在2016年又遇到了资金短缺,只能卖掉位于桑尼威尔总部大楼来渡过难关,为了节省开支,又搬到硅谷其他更加便宜,面积更加小的地方去了,在外界看来,AMD正在为如何生存下去而努力奔波,甚至随时可能倒闭,翻身之日更是遥遥无期,此时人们已经对AMD的产品发布提不起兴趣了,毕竟每次都会被 Intel 的酷睿吊打,在这个时间点, Intel 如期发布了他们的第七代酷睿处理器,Kaby lake,依然沿用经典的14nm I3 I5 I7的参数,也依然是双核四线程,四核四线程,四核八线程,这一点从酷睿I系列第一代开始就没有变过,好在第七代酷睿性能,勉强还比上一代提升了那么一点点,毕竟老对手AMD的一蹶不振, Intel 开始沉迷于挤牙膏的乐趣当中了, 毕竟高端处理器消费者没有别的选择。
这边躺着挣钱的 Intel ,正准备吸干消费者的钱包呢,苏姿丰博士和吉姆凯勒就带领着AMD在2017年2月21日重新杀了回来,这一天AMD拿出了研发多年的杀手锏, Zen 架构锐龙(Ryzen),这次不同于前代推土机的羸弱性能,锐龙无论是单核还是多核性能都有了质的飞跃,IPC相比上一代直接大幅提升了52%,借助架构的这种飞跃,以及从32NM升级到14NM工艺

锐龙首发的八核心处理器,R7 1800X和R7 1700X,TDP仅为95瓦,R71700更是只有65瓦, 同时 R7 1800X的价格却只要I7 6900K的一半! 终于回过神来的 Intel ,意识到自己已经处于水深火热当中,于是急忙把牙膏里的八代 core挤了出来,更是把I3 I5 I7的核心数同时增加了两颗,要知道之前 Intel 的酷睿,从第一代到第七代的核心数就完全没变化过

AMD的反击显然是让 Intel 慌了,而且AMD在同年8月又祭出了大杀器 Threadripper 线程撕裂者,史无前例地将消费级处理器核心数堆到16颗,暴打当时 Intel 所有消费机处理器,直接登顶性能榜首, Intel 也同时祭出了全新的I9系列反击AMD,其中最强的老大哥便是I97980XE,把核心素暴力堆到18颗,重新夺回性能王座,虽然勉强夺回了第一的位置,但这场战役也让 Intel 知道了,AMD这个对手已经成长到可怕的地步,接下来的战斗绝不能再有一丝怠慢
第一次 ZEN 架构和 Intel 酷睿的对垒,暴露出单核性能还是很吃亏,而且使用的GF14纳米制造工艺,竟只有 Intel 22NM水平,实验室里早已改良好的下一代锐龙,还不足以和 Intel 比较单核性能,于是他们决定先将下一代锐龙发布,然后开足马力研发第二的Zen,于是在2018年初发布了改良的Zen+架构锐龙2000系列, 基本参数也没什么变化,一样多的核心线程,一样大的缓存容量,功率小幅升级到GF12纳米,IPC同样也小幅提升3%到5%,同时改进了前代内存延迟和兼容性问题,其实从本家的命名上也可以看出,这更像是一个过渡产品,真正的主角往往在最后出现
2019年5月27日,基于全新zen2架构的锐龙3000系列强势来袭,这是继初代Zen架构的又一次革新,AMD在zen2架构上大动干戈,相较于前代增加,不仅是缓存容量翻倍,而且缓存速度也翻了一倍,更重要的是,浮点运算单元从前代的128位,翻倍到256位,使得浮点性能也翻倍,最终造就的是正面的IPC相比增加,再次提高了15%,zen2架构终于实现了单核性能, Intel 眼看着AMD马上就要超过自己了,急急忙忙发布了十代酷睿I9,核心数增加了两颗,从八核来到十核,但加入了超线程,并把Die削薄了,使得散热表现更好一些,内核还是skylake, 还是经典的14NM制造工艺,综合性能提升了一些,但单核性能几乎就是原地踏步
如果说zen2性能是追平了 Intel ,那么现在的zen3就是把 Intel 按在地上打了,2020年10月9日发布的zen3架构,再次大幅革新。相比zen2架构里,每个CCD里含有两颗四核八线程的CCX,zen3架构将其合二为一,这使得CPU间的隔阂被打通了,每个CCD之间包含八核16线程的CCX. 三级缓存也从两个 16MB 并成一个32MB, 通信延迟大幅下降,加入分支预测器和执行引擎的大幅改进,zen3架构的IPC,相比zen2再次提升了19%
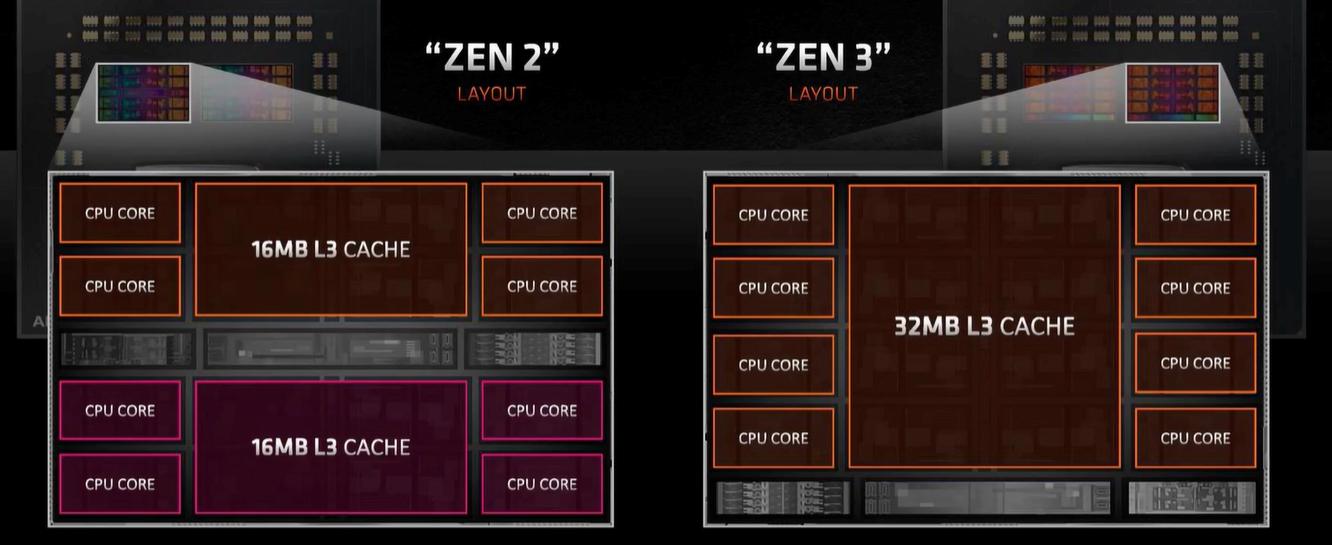
多核与Die
是不是把很多个CPU连在一起就叫多核处理器了呢? 能否造一个100核的超级CPU呢?
实际上这个问题和CPU的制造工艺有关系, 首先将碳和沙石中的二氧化硅经过一系列复杂的电化学反应得到高纯度的多晶硅(99.99%). 随后将纯化后的多晶硅被融化后放入一个坩埚(Quartz Crucible)中,再将籽晶放入坩埚中匀速转动并且向上提拉,则熔融的硅会沿着子晶向长成一个圆柱体的硅锭(ingot).这种方法就是现在一直在用的CZ法(Czochralski),也叫单晶直拉法.单晶直拉法工艺中的旋转提拉决定了硅锭的圆柱型,从而决定晶圆是圆形的。
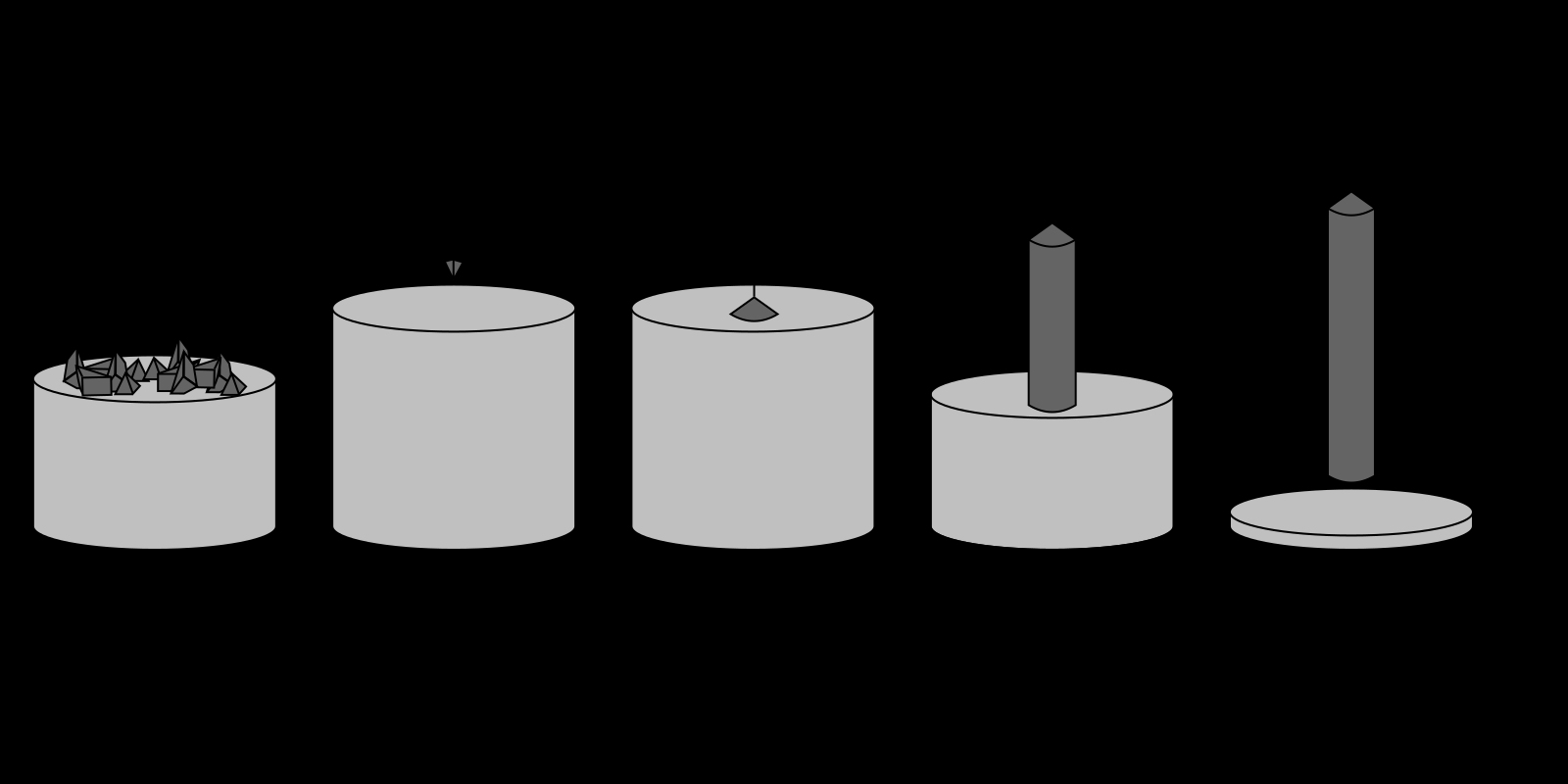
随后硅锭在经过金刚线切割变成硅片, 在经过一系列打磨处理就变成了我们看到的晶圆。
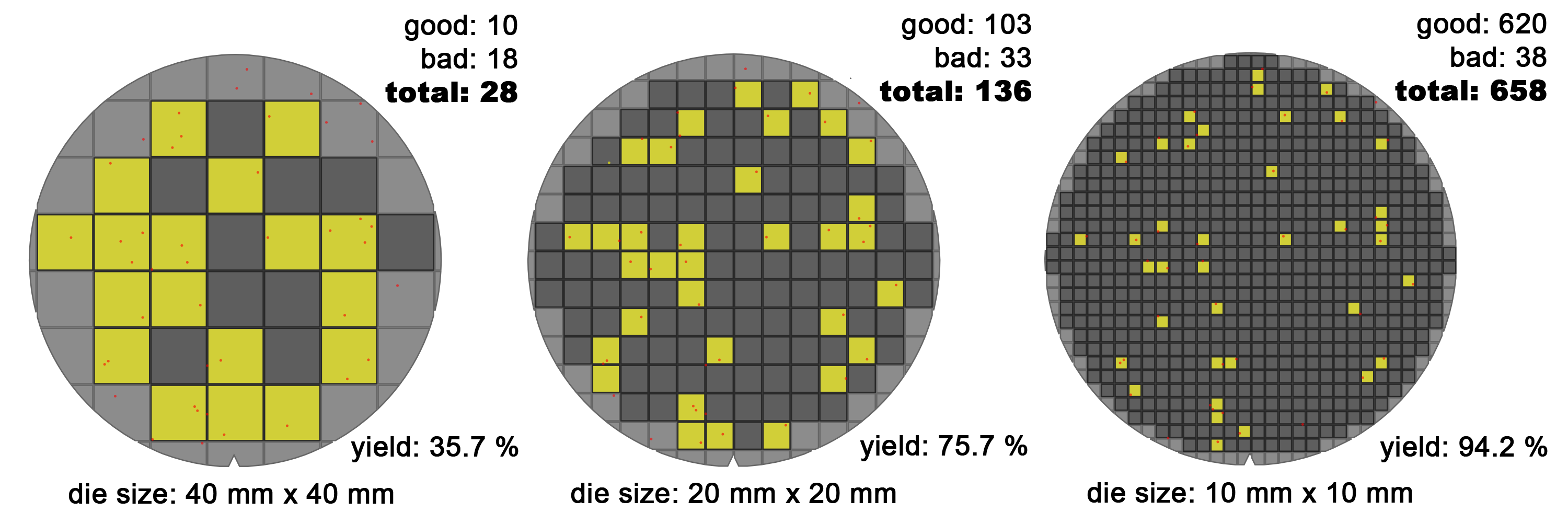
我们会将一个圆形的晶圆切割成很多个矩形的小芯片,每一个芯片我们叫做Die,不完整的圆形边缘的部分就浪费掉了。如下图所示, 随着Die尺寸的缩小浪费的部分是在变少的。由于晶圆在制造过程中是没有办法完全避免缺陷的, 有缺陷的小红点部分就会分布在整个晶圆上;
当Die很大时,那么有很大概率它的范围内会有缺陷,那这个黄色的芯片就报废了;在Die比较小的时候,它的良品率也会大大提高。单纯的把很多个单核CPU连起来并不叫多核,把很多个CPU核心都放到一个Die上才叫多核
奔腾D使用了两个CPU,但它们之间实际上是使用片外总线来进行通信的, 速度相比片上总线要差了很多个数量级
元器件是需要面积的,所以要想放下很多个CPU核心就需要增大Die的尺寸,虽然性能提高了但是由于良品率的下降它的成本也就上去了,所以不去疯狂的堆核心数量实际上是性能,工艺和成本之间的取舍
- 从经济角度来看,制造大型CPU的成本非常高,例如服务器级别的CPU,如志强线程撕裂者,虽然体积较大、性能较强,但其高昂的价格使得它们主要应用于服务器领域,而不适合消费市场。
- 技术层面上,CPU内部电流的传递速度接近光速(3x10^8m/s),但即便如此,信号在单位时间内能够传播的距离也有限。对于消费级CPU,其频率已经达到5G赫兹以上,而信号传播的最大距离大约为6cm,这意味着芯片的物理尺寸不能过大,否则会影响频率和性能。服务器级CPU虽然核心多,但频率不高,主要依靠多核性能。
制造CPU使用的是如晶圆、光刻等高成本技术,这些技术的成本已经固定,而且晶圆的大小也是标准化的。在晶圆上制造更小的核心可以降低单个核心的成本,并且减少由于晶圆边缘浪费带来的成本增加。此外,晶圆上的缺陷会导致废品,小芯片由于面积小,更容易绕开缺陷区域,提高了良率和容错率。
芯片的完整制造过程如下所示
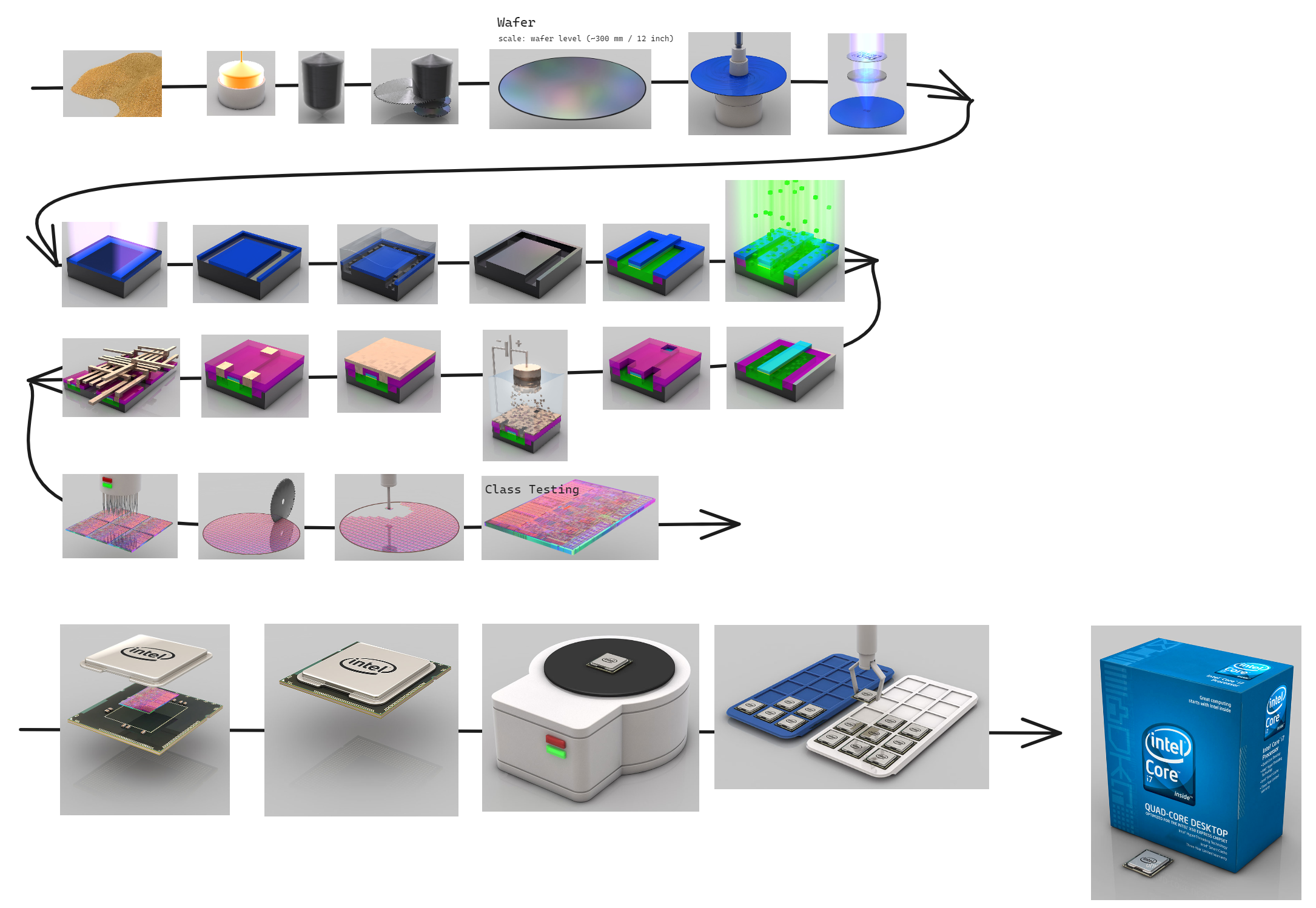
intel 的工艺比较先进所以可以在一个 die 上放下很多个 core, 速度也很快
AMD当时工艺比较落后,但还想要堆多核,所以就采取了封装多个Die的做法,这样每个Die可以分几个核心,既不影响良品率,又可以核心数目好看。而且即使某一个Die检测出故障了,也可以从四核满血版砍成三核残血版来作为一个中端芯片来卖,也不耽误。

上图为 AMD Zen2 EPYC I/O 的 CPU 架构, 四个Die使用高速片外总线进行通信

不过总归来说片商总线要比片外总线快很多
频率
电脑中所有的信号都需要频率协调统一才能一起工作, 因此需要一个统一的频率来协同工作, 这个元器件是主板上的晶振。
主板晶振(XO),也称为晶体振荡器或晶振,是一种在电脑主板上使用的电子元件,它的主要作用是产生稳定的时钟信号.这些时钟信号是计算机系统正常运行的基础,因为它们为主板上的各个组件提供了同步的基准频率。
晶振通常由石英晶体构成,利用石英晶体的压电效应来工作。这种晶体有一个很重要的特性,如果给它施加交变电压,它就会产生机械振荡,反之,如果给它机械振动,它又会产生交变电压。在特定的频率下,晶体的振动幅度会显著增加,这个现象称为压电谐振。晶振的频率非常稳定,因此它们能够提供高精度的时钟信号.
由主板晶振产生的基础频率被称为 BCLK(base clock), 主板上所有元器件都和该频率统一, 这个基础频率也被称为外频. 由于技术的现代处理器的频率已经远高于其他设备的工作频率, 为了解决这个问题工程师设计出倍频的概念, 我们将 CPU 的主频分为 外频 和 倍频, CPU 主频 = 外频 x 倍频
我们假设主板晶振规定的外频是 100MHz, CPU的工作频率在外频的基础上翻42倍, 那你的CPU频率就变成了42 x 100MHz也就是4200MHz也就是4.2GHz,这里这个42倍就是CPU的倍频。这样的话CPU一方面可以保证外频100Mhz和其他设备同步,另一方面保证自己工作的时候能提高性能全速运转不受到其他设备的影响
超频
既然频率会影响性能,而频率是Intel或者AMD设定的,那只要他们不锁定频率,我们就可以人为的修改这个频率,把它往高了拉,这就是超频了。
不过超频是有一定限制的,首先就是你的CPU要不锁频率你才可以超频,其次你需要保证你的主板是具有超频功能的,满足这两个条件后你才可以超频,其次你还需要为超频准备更好的电源和主板。
一定要超频的话, 最好是只动倍频, 因为你动了外频后,整个电脑所有平台里的外频都要跟着变动,虽然所有的设备性能都提升了,但是这样的话牵扯到的设备就会非常多,假设你外频调整到了110Mhz,那只要有一个设备不能正常的工作在110Mhz下,你的电脑就会出现不稳定的现象,轻则蓝屏死机,重则直接烧毁,而你动倍频的话,只会影响到CPU本身,这样的话不稳定因素就会少很多了,你只需要专注调整CPU的参数就可以了
除了CPU之外,内存也有相应的外频和倍频,比如2400的内存,同样的为了保证和主板上其他设备同步其外频就为100Mhz,倍频为24,这时候等效频率为2400Mhz,这也就是我们说的2400内存
CPU 术语
大多数CPU都是在二维平面上构建的。CPU还必须添加集成内存控制器。对于每个CPU核心,有四个内存总线(上,下,左,右)的简单解决方案允许完全可用的带宽,但仅此而已。CPU在很长一段时间内都停滞在4核状态。当芯片变成3D时,在上面和下面添加痕迹允许直接总线穿过对角线相反的CPU.在卡上放置一个四核CPU,然后连接到总线,这是合乎逻辑的下一步。
如今每个处理器都包含许多核心,这些核心都有一个共享的片上缓存和片外内存,并且在服务器内不同内存部分的内存访问成本是可变的。提高数据访问效率是当前CPU设计的主要目标之一, 因此每个CPU核都被赋予了一个较小的一级缓存(32 KB)和一个较大的二级缓存(256 KB).各个核心随后共享几个MB的3级缓存,其大小随着时间的推移而大幅增长。
为了避免缓存丢失(请求不在缓存中的数据),需要花费大量的研究时间来寻找合适的CPU缓存数量,缓存结构和相应的算法。详见 缓存一致性
一个 CPU 有如下的一些术语: socket core ucore threads
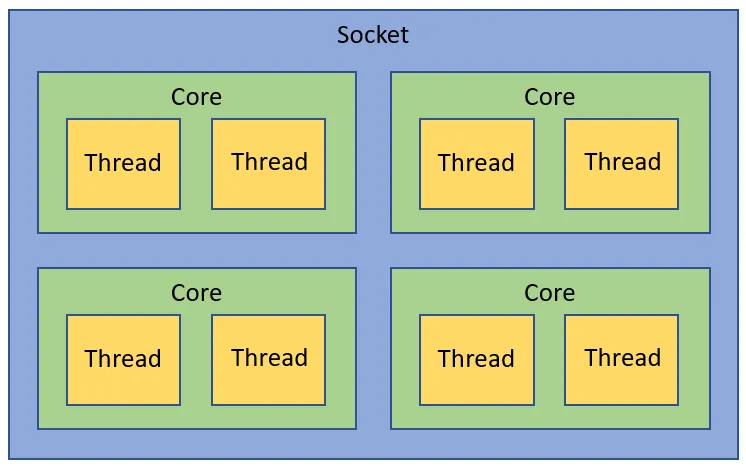
- Socket: 一个Socket对应一个物理CPU. 这个词大概是从CPU在主板上的物理连接方式上来的,可以理解为 Socket 就是主板上的 CPU 插槽。处理器通过主板的Socket来插到主板上。尤其是有了多核(Multi-core)系统以后,Multi-socket系统被用来指明系统到底存在多少个物理CPU.
- Core: CPU的运算核心. x86的核包含了CPU运算的基本部件,如逻辑运算单元(ALU), 浮点运算单元(FPU), L1和L2缓存。一个Socket里可以有多个Core.如今的多核时代,即使是单个socket的系统, 由于每个socket也有多个core, 所以逻辑上也是SMP系统。
但是,一个物理CPU的系统不存在非本地内存,因此相当于UMA系统。
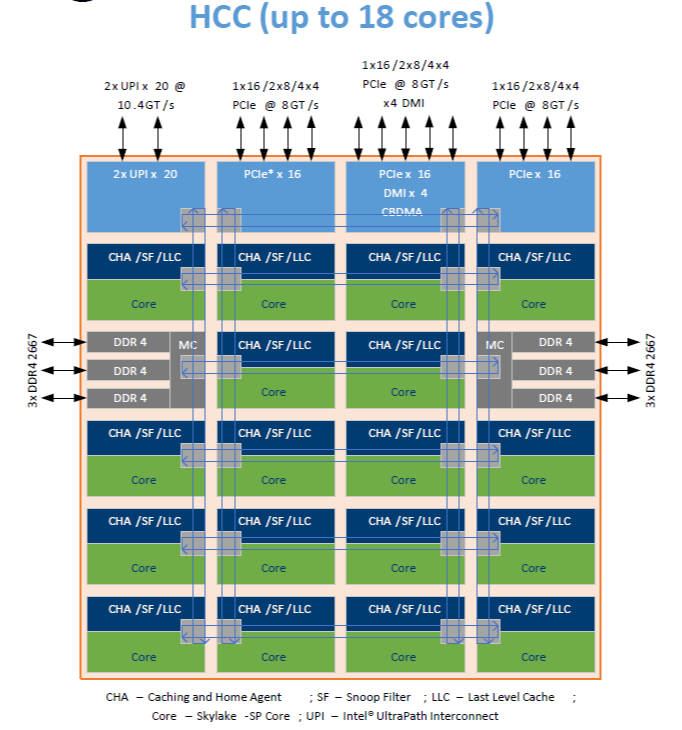
- Uncore: Intel x86物理CPU里没有放在Core里的部件都被叫做Uncore.Uncore里集成了过去x86 UMA架构时代北桥芯片的基本功能。在Nehalem时代,内存控制器被集成到CPU里,叫做iMC(Integrated Memory Controller). 而PCIe Root Complex还做为独立部件在IO Hub芯片里。到了SandyBridge时代,PCIe Root Complex也被集成到了CPU里。现今的Uncore部分,除了iMC,PCIe Root Complex,还有QPI(QuickPath Interconnect)控制器, L3缓存,CBox(负责缓存一致性),及其它外设控制器。
- Threads: 这里特指CPU的多线程技术。在Intel x86架构下,CPU的多线程技术被称作超线程(Hyper-Threading)技术。Intel的超线程技术在一个处理器Core内部引入了额外的硬件设计模拟了两个逻辑处理器(Logical Processor), 每个逻辑处理器都有独立的处理器状态,但共享Core内部的计算资源,如ALU,FPU,L1,L2缓存。这样在最小的硬件投入下提高了CPU在多线程软件工作负载下的性能,提高了硬件使用效率。x86的超线程技术出现早于NUMA架构。
因此, 一个CPU Socket里可以由多个CPU Core和一个Uncore部分组成。每个CPU Core内部又可以由两个CPU Thread组成。每个CPU thread都是一个操作系统可见的逻辑CPU.对大多数操作系统来说,一个八核HT(Hyper-Threading)打开的CPU会被识别为16个CPU
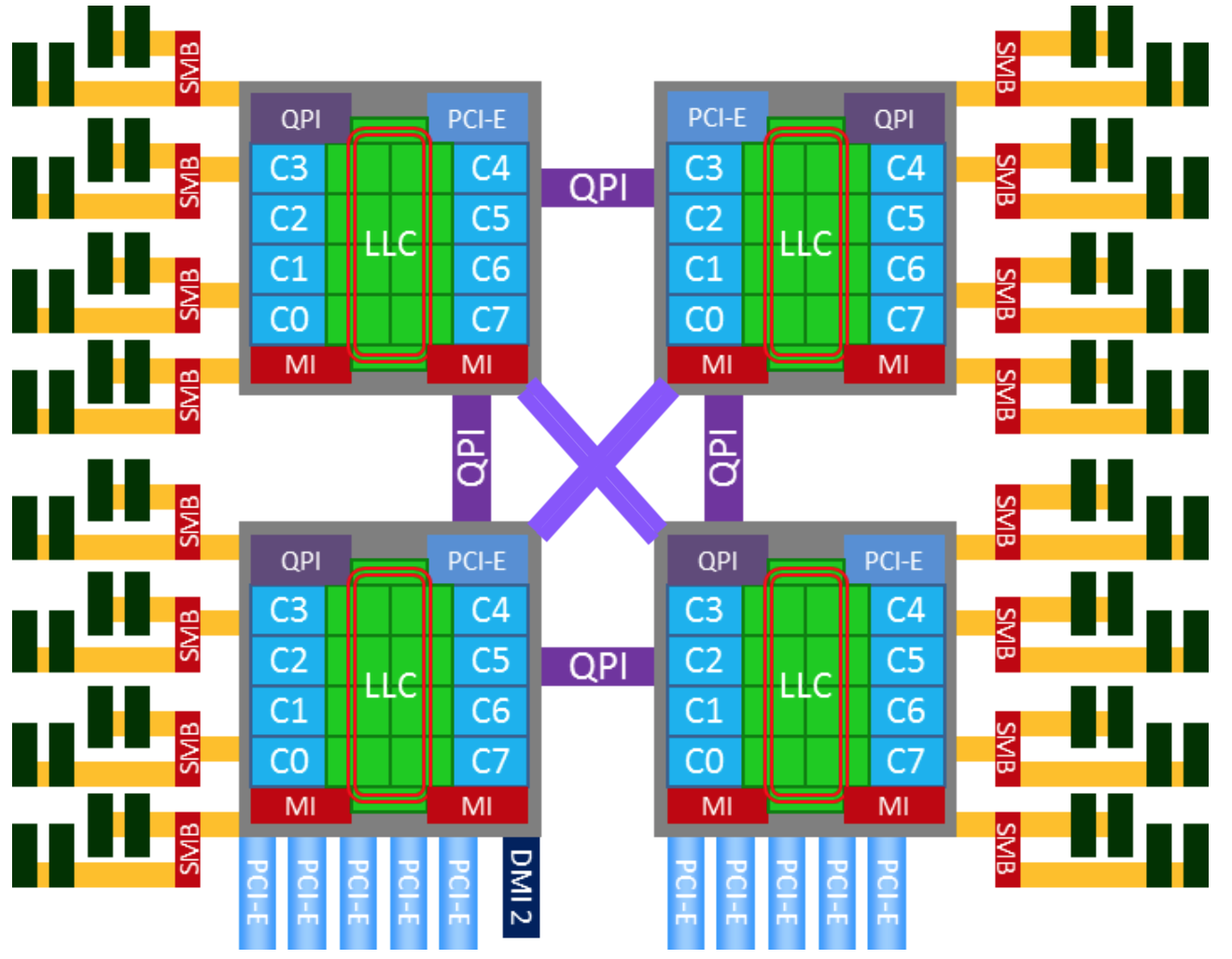
QPI(QuickPath Interconnect)是英特尔(Intel)处理器架构中使用的一种高速互联技术。它用于处理器与其他组件(如内存,I/O设备和其他处理器)之间的通信。
LLC(Last-Level Cache):LLC 是处理器架构中的最后一级缓存。在多级缓存结构中,处理器通常具有多个级别的缓存,而最后一级缓存(通常是共享的)被称为 LLC.LLC 位于处理器核心和主存之间,用于存储频繁访问的数据,以加快处理器对数据的访问速度。
MI(Memory Interleaving):MI 是一种内存交错技术,用于提高内存子系统的性能。在内存交错中,内存地址空间被划分为多个连续的区域,并将这些区域分配到不同的物理内存模块中。这样,内存访问可以并行地在多个内存模块之间进行,提供更高的带宽和更快的数据访问速度。