cache-coherence
人们发现使用大型的多级缓存可以充分降低处理器对于存储器带宽的需求, 但是缓存策略总是伴随着数据一致性的问题
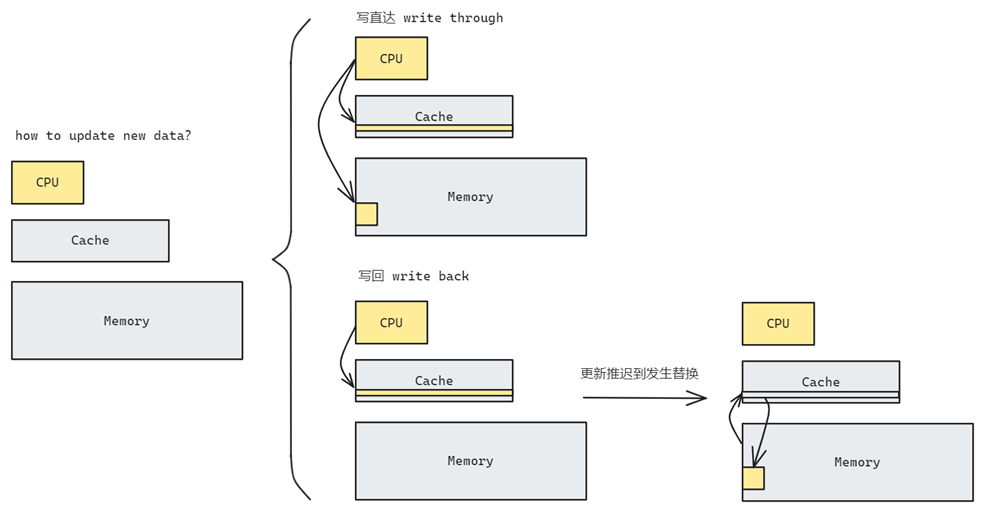
首先思考单核CPU下,何时将缓存数据的修改同步至内存中,使得缓存与内存数据一致?
假设CPU计算得到了一个最新的数值然后要把它写回去,这时候缓存和内存中的都有原先数据的副本,那么应该写到那里呢?
第一种方式叫写直达,也就是说我同时更新缓存和内存中的副本,这样所有存储的值都是同步的都是最新的.但是我们知道写操作是很慢的,如果每一次更新都需要写回内存那这个时间就太长了.另一种方式是只把数据写回cache,反正CPU读数据就直接从cache里面读了,只有当这个缓存行需要被替换的时候我们才把数据更新到内存里面.
缓存一致性问题
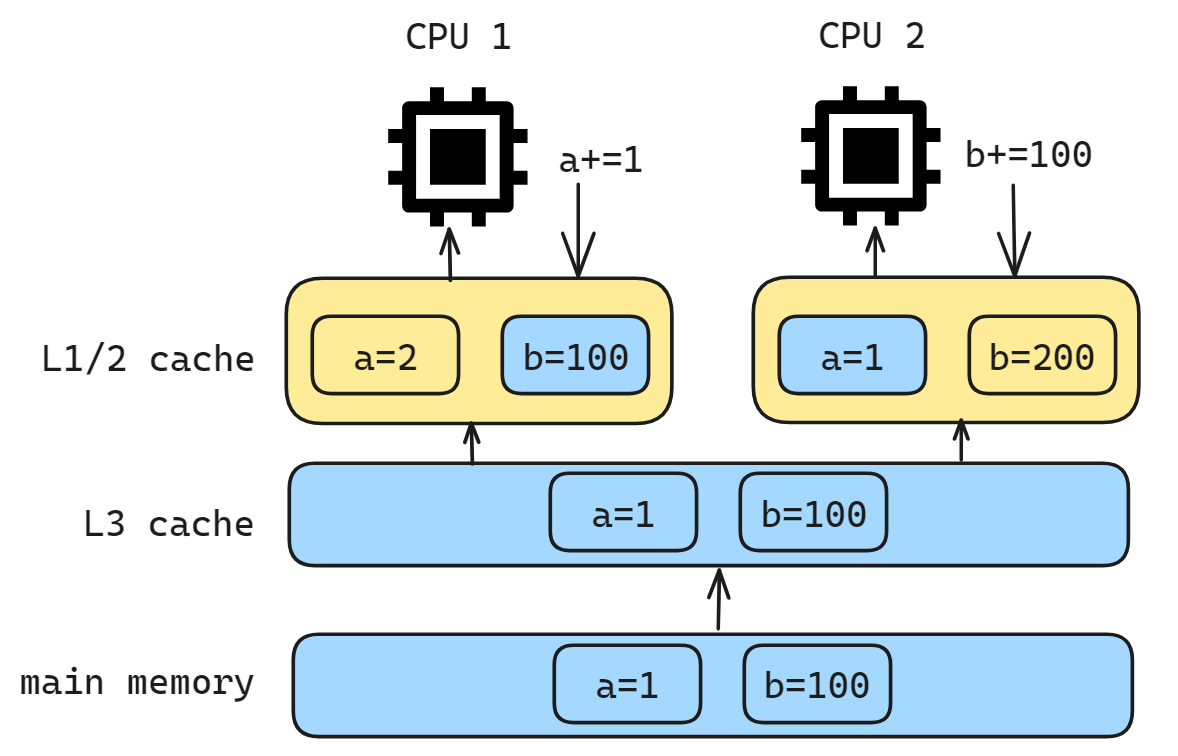
假设 CPU1 和 CPU2 同时运行两个线程,都操作共同的变量 a 和 b, 为了考虑性能,使用了我们前面所说的写回策略, 把执行结果直接写入到 L1/L2 Cache 中,这个时候数据其实没有被同步到内存中的,因为写回策略只有在Cache Block 要被替换的时候,数据才会写入到内存里. 由于 CPU 1/2 的缓存策略, 导致数据在这个时候是不一致,从而可能会导致执行结果的错误.这也就带来了不同存储节点中同一条数据副本之间不一致这样一个问题
那么,要解决这一问题,就需要一种机制,来同步两个不同核心里面的缓存数据.要实现的这个机制的话,要保证做到下面这 2 点:
- 某个 CPU 核心里的 Cache 数据更新时,必须要传播到其他核心的 Cache, 称为写传播(Write Propagation);
- 某个 CPU 核心里对数据的操作顺序,必须在其他核心看起来顺序是一样的, 称为事务的串形化(Transaction Serialization).
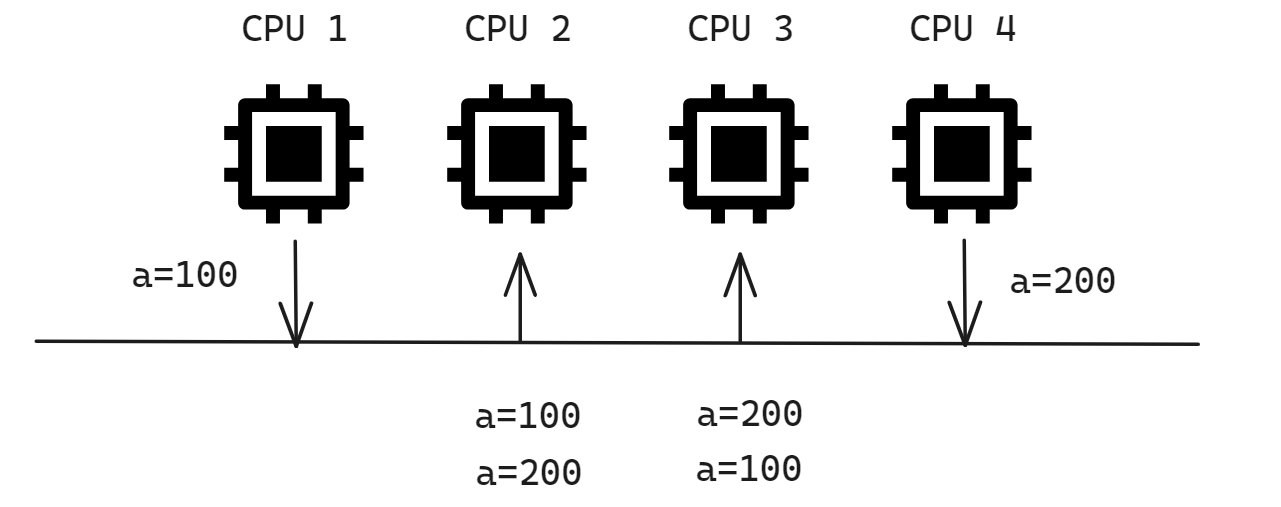
第一点写传播很容易就理解,当某个核心在 Cache 更新了数据,就需要同步到其他核心的 Cache 里; 第二点事务的串行化指的是不同 CPU 要看到相同顺序的数据变化,比如两个线程同时执行 a=100 和 a=200, 所有其他核心收到的更新变化都应该是相同的, 比如变量 a 都是先变成 100,再变成 200
缓存一致性
我们期望的是有这样一个一致性的内存系统: 所有处理器在任何时刻对每一个内存位置的最后一个全局写入值有一个一致的视图.
一致性缓存提供了迁移的能力, 可以将数据项移动到本地缓存中, 并以透明的方式加以使用. 这种迁移既缩短了访问远程共享数据项的延迟, 也降低了对共享存储器的带宽要求.实现缓存一致性协议的关键在于跟踪数据块的所有共享状态, 那么就需要来维护数据的相关性(coherence)和一致性(consistency)
- 相关性(coherence): 一个数据项的任何读均可得到该数据最近被写的值
the situation in which all the parts of sth fit together well
- 一致性(consistency): 一个处理器何时读到另一处理器最近更新的内容.
the quality of always behaving in the same way or of having the same opinions, standard, etc.
实现缓存一致性协议的关键在于跟踪数据块的所有共享状态, 目前使用的协议有两类, 分别是监听协议(snooping, 也可以叫嗅探)和目录协议(directory-based);
监听协议
写传播的原则就是当某个 CPU 核心更新了 Cache 中的数据,要把该事件广播通知到其他核心. 与此同时处理器会监听来自总线上广播事件, 如果当前 CPU 的缓存中有该缓存块的副本则应该以某种方式做出反应(更新)
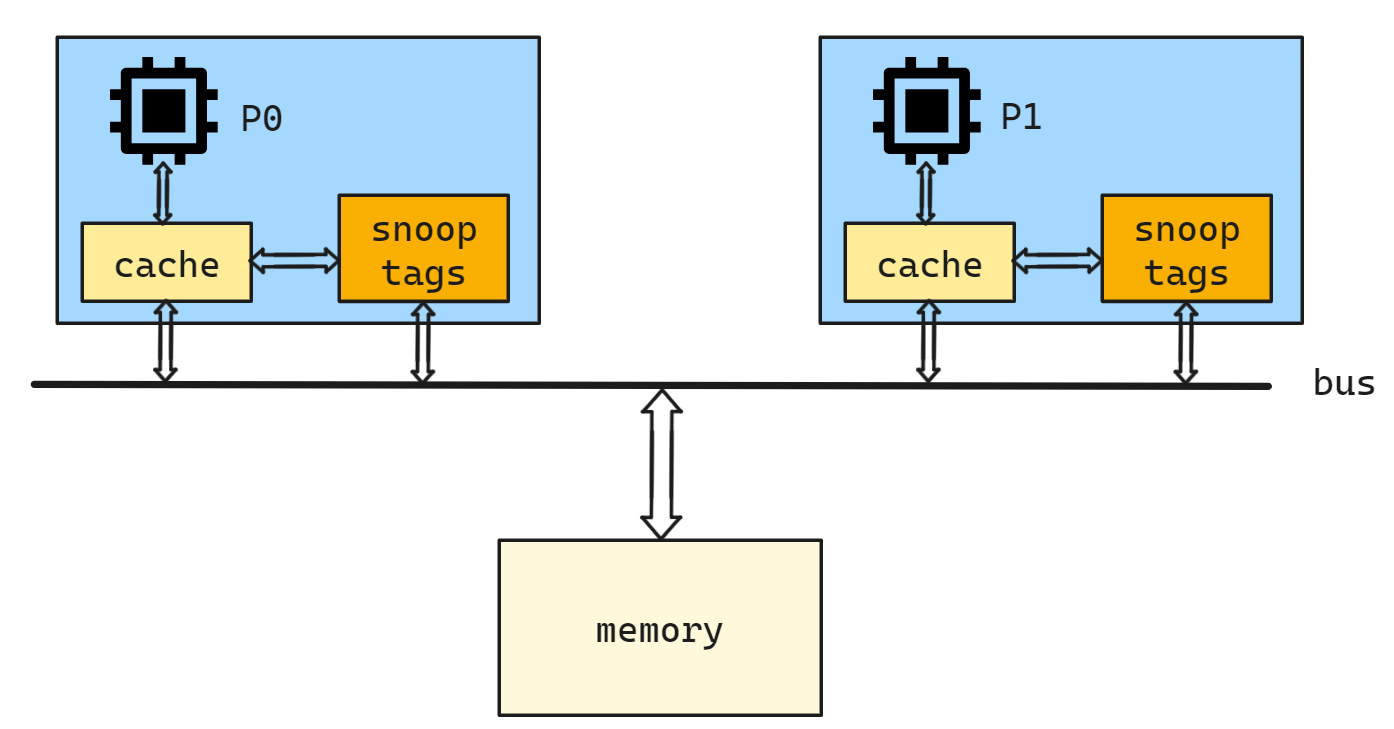
当任何一个 CPU 核心修改了 L1 Cache 中变量的值, 都会通过总线把这个事件广播通知给其他所有的核心. 每个 CPU 核心都会监听总线上的广播事件,并检查是否有相同的数据在自己的 L1 Cache 里面,如果其他 CPU 核心的 L1 Cache 中有该数据,那么也需要把该数据更新到自己的 L1 Cache.
监听协议的实现又分为两种: 写入失效(write invalid protocal) 和 写入更新(write update/boardcast)
- 写入失效
写入失效指当一个处理器更新 X 的值后, 广播通知所有其他处理器关于 X 的副本 cache 失效
下面是一个写入失效的例子, A B 处理器分别读取 X 的值并保存到 cache 中, 当 A 更新 X 的值后在 bus 上广播
invalid X信号, 所有其他处理器收到该信号后均将其 cache 内 X 的缓存行的 valid 置为 0下图中清空了 P_b cache 的值, 实际上只是将其 valid 位置 0 完成失效操作
最后当 B 试图读取 X 的最新值时可以直接从 A cache 当中取到, 并且更新内存中的 X 的值.
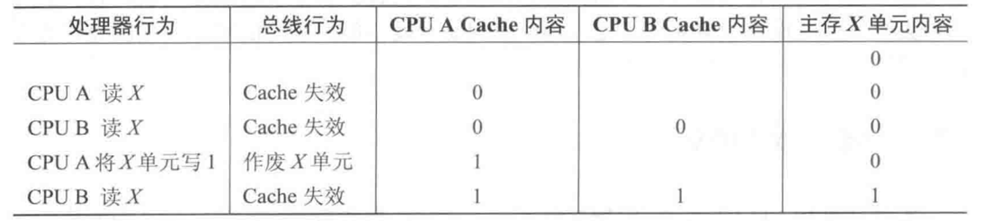
对于写入操作我们需要确保执行的处理器拥有独占访问, 禁止任何其他处理器同时写入. 如果有多台处理器同时尝试写入同一数据, 则只有其中一个将会在竞争中获胜, 因此这一协议实现了写入串行化.
- 写入更新
写入更新的操作并不会使其他处理器的 cacheline 失效, 它会在每次写入时通知所有其他处理器更新 cache 的数据, 如下图所示
当 A 更新 X 后广播
update X信号, 此时 B 的 cache 和内存中的数据一同更新, 这样所有其他处理器总是可以获取到最新的数据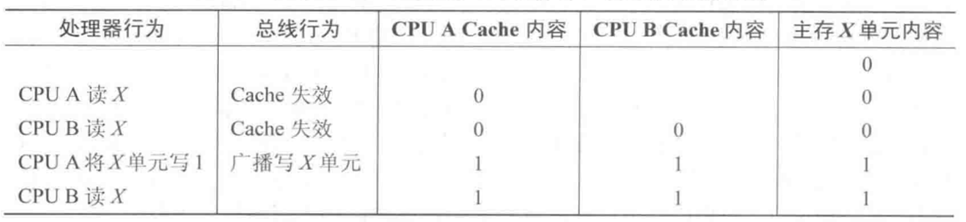
写入更新的方法要求每次 write 都广播到共享缓存线上, 这无疑会占用相当多的总线带宽, 而且 CPU 需要每时每刻监听总线上的一切活动发出每一个广播事件. 而对于写入失效的方法来说, 在一些情况下的 write 不会广播
修改(M)状态下的 write 不需要广播 invalid, 无效(I)状态下不需要监听, 后文 MSI 协议中会提到
写更新和写作废协议性能上的差别来自三个方面:
- 对同一数据的多个写而中间无读操作的情况,写更新协议需进行多次写广播操作,而在写作废协议下只需一次作废操作.
- 对同一块中多个字进行写,写更新协议对每个字的写均要进行一次广播,而在写作废协议下仅在对本块第一次写时进行作废操作即可.写作废是针对Cache块进行操作的,而写更新则是针对字(或字节)进行操作的.
- 从一个处理器写到另一个处理器读之间的延迟通常在写更新模式中较低,因为它写数据时马上更新了相应的其他Cache中的内容(假设读的处理器Cache中有此数据).而在写作废协议中,需要读一个新的备份.
在基于总线的多处理机中,总线和存储器带宽是最紧缺的资源, 因此现代多处理器大多选择 写入失效(write invalid protocal) 作为监听协议的实现, 后文将会介绍基于写入失效的 MSI write-invalid protocol
下面对于图片部分和状态转移的内容有些复杂, 具体解释可以参考笔者的视频: 【技术杂谈】缓存一致性
MSI
MSI 规定了缓存行(cache line)的 M S I 三种状态:
Modified: 已修改, 此时缓存中的数据和内存中的数据不一致, 最新的数据只存在于当前的缓存块当中
Shared: 共享, 此时缓存数据和内存中的数据一致
Invalidated: 已失效, 该缓存块无效
其中同一时刻 M 状态最多只会存在一个, 而 S 状态可以同时存在很多个
我们可以为每个 cache line 添加一个 dirty flag 用于记录是否已修改且未写回内存; M S I 三种状态是针对每一个 cache line 的.
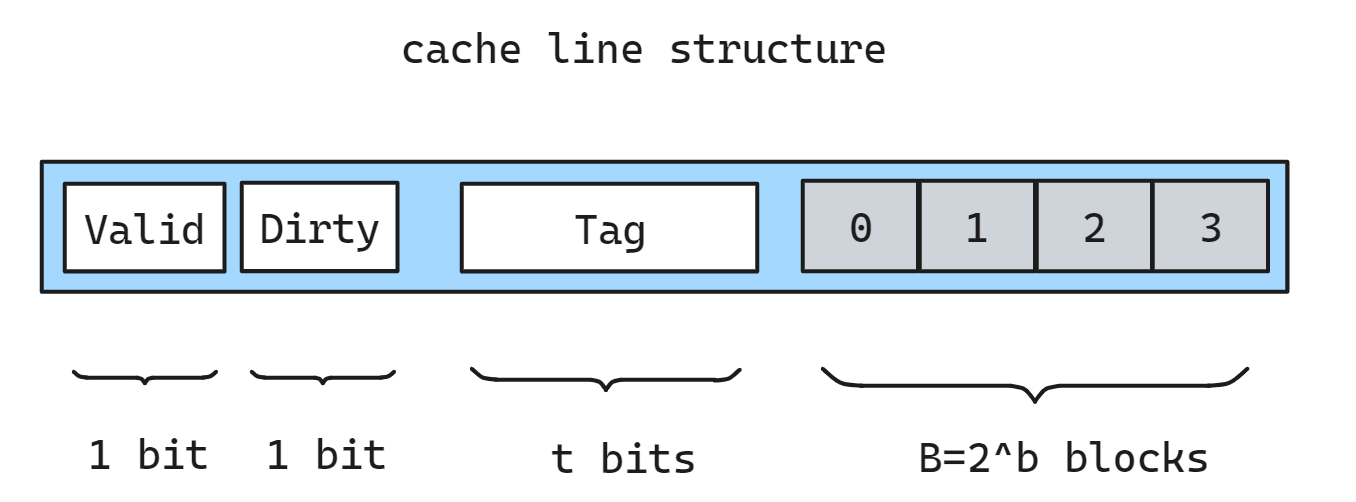
这里省略了 LRU 的计数保留位
这三种状态会随着 CPU 的 read/write cache 请求而发生状态的转换, 其中蓝色代表 CPU 的 read 信号, 紫色代表 CPU write 的信号, 黑色表示伴随该请求在 BUS 上广播的信号, 整个状态转换图如下.
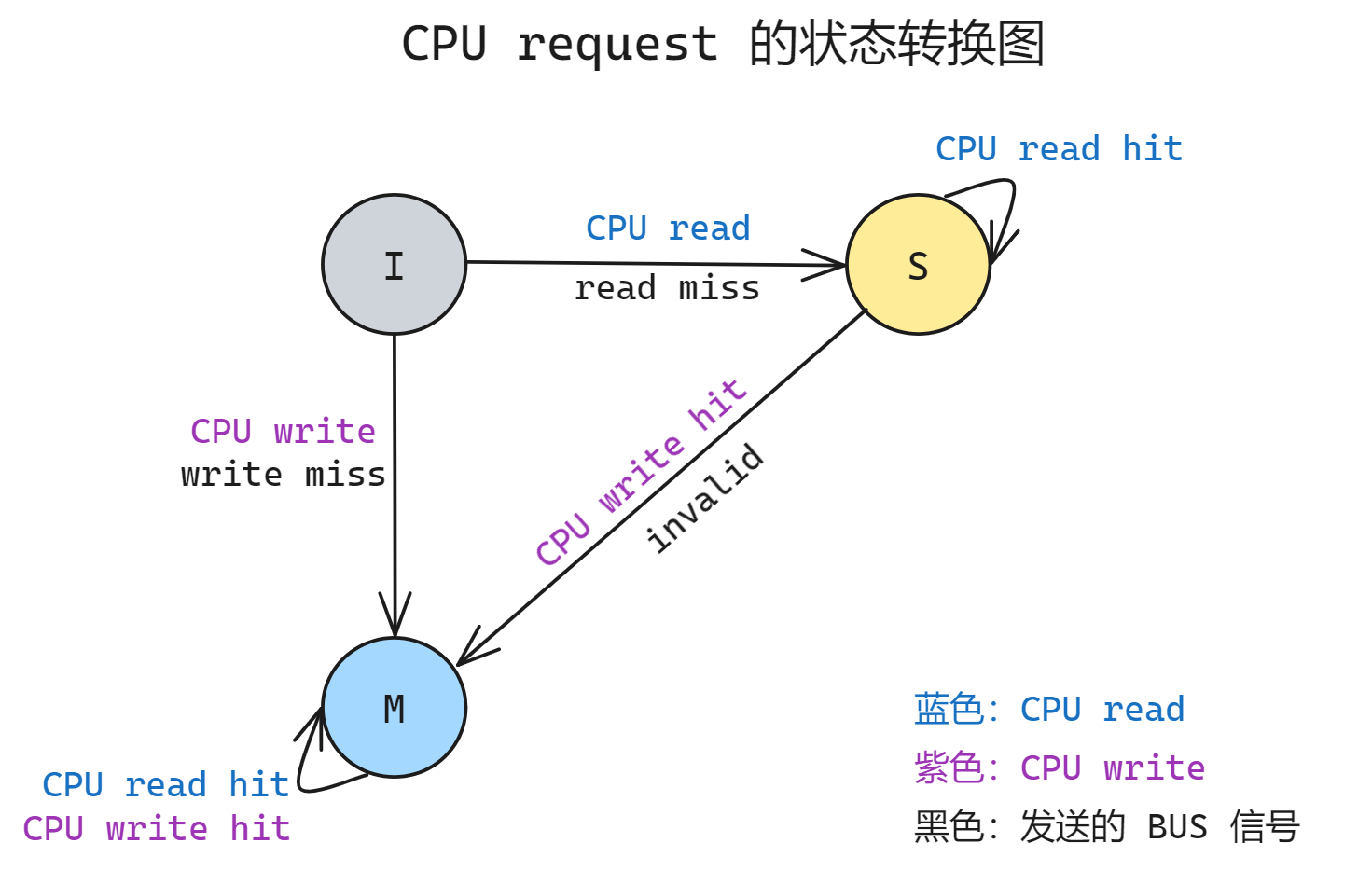
该转换图下面我们针对转换图分别描述一下:
- I 状态的 read/write 必然 cache miss
- 对于 read 转换到 S, 同时广播
read miss
- 对于 write 转换到 M, 同时广播
write miss
- 对于 read 转换到 S, 同时广播
- S 状态如果 read hit 则保持不变; 如果 write hit 则转换为 M, 同时广播
invalid使其他所有 cache 失效
- M 状态的 read/write hit 都保持在原状态不变, 不发出信号
这里书上的图还有关于 S/M 状态的 read/write miss 的箭头, 这里我觉得没有必要画出来, 因为实际上是替换的策略.
正常来说 S/M 状态的数据在 cache 中不会 miss, 这里是指对于另一个地址(假设为 B)在直接映射的高速缓存中对应的 cache line 和当前某个状态 S/M 的 cache line (假设地址为 A)发生了地址冲突, 此时 那么此时需要替换掉 A 的 cache line
- 在 A 的 S 状态下 B 的 CPU read miss 发生后只需要直接替换, 广播 B 的 read miss; B 的状态依旧保持 A 之前的 S
- 在 A 的 M 状态下 B 的 CPU write miss 发生后需要先写回 A 的 data, 广播 B 的 write miss; B 保持 M 状态
- 在 A 的 M 状态下 B 的 CPU read miss 发生后需要先写回 A 的 data, 广播 B 的 read miss; B 进入 S 状态
上图表示的是当前 CPU 在发出 read/write 请求后对于 cache hit/miss 的情况下当前 cache line 的状态转移图; 下图是位于总线上的其他 CPU监听到来自总线的信号后进行的状态转移图
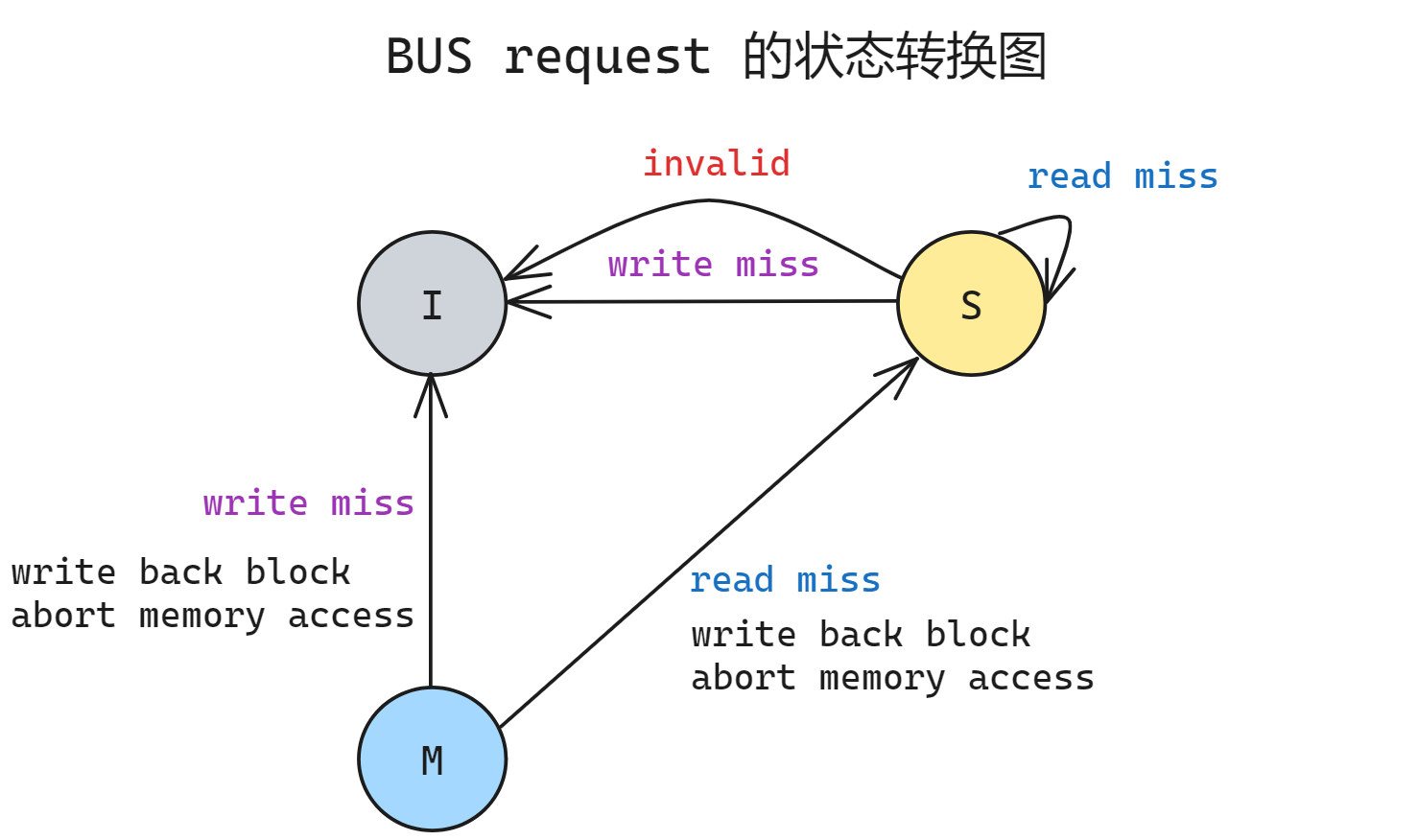
- I 状态无需监听任何信号, 因为本身 cache 就是失效的
- S 状态可能会收到全部的 read miss/ write miss/ invalid 三种信号
- read miss 时保持 S 不变, 此时共享缓存可以为发生 read miss 的 CPU 提供数据
- invalid/write miss 的情况相似, 都说明有另外一个 CPU 试图写入(只是一个成功了一个失败了), 所有其他 cache line 进入 I 状态
- M 状态只可能收到两种信号 read miss/ write miss
- read miss 说明有其他 CPU 试图读, 此时 M 状态中的数据为最新的值, 需要先写回 memory 同时尝试同发出信号的 CPU 共享数据, 此时该 cache 的数据不再是唯一的了, 所以进入 S 状态
- write miss 说明有其他 CPU 试图写入, 此时 M 状态中的数据为最新的值, 需要先写回 memory 同时尝试同发出信号的 CPU 共享数据, 因为同一时刻只会有一个 M 状态, 因此该 CPU 进入 I 状态, 让另一个 write 的 CPU 进入 M
M 状态只会收到 read/write miss 两种信号而不会收到 invalid 信号是因为当一个 cache line 处于 M 状态时, 所有其他的 cache line 应当全部由于写入时的 invalid/write miss 信号进入 I 状态, 因此不可能有处于 S 状态的其他 cache line. 所以不可能发出 invalid 信号
我们来看一道例题, 有三个 CPU 1/2/3, 初始都处于无缓存的 I 状态, 对于 t1-t4 时刻的 read/write, 总线上的 bus request 和三个 CPU 的 cache 状态如何变化?
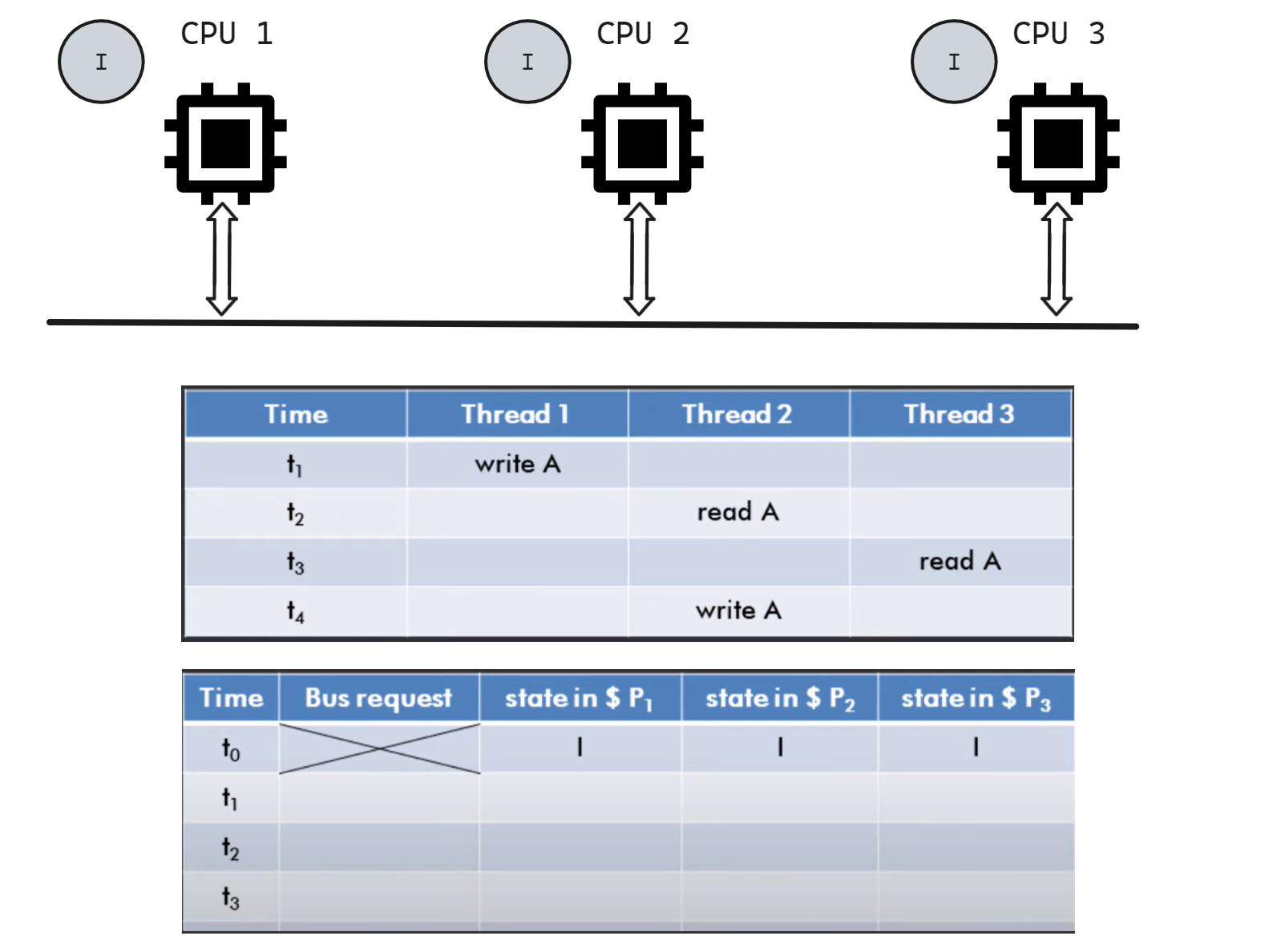
t1 时 CPU1 write A, 此时 CPU1 先从 memory 中读取 A 的值, 更新 cache, 由 I -> M, 并在总线广播 write miss 信号; 其余 CPU 收到该信号后没有变化(或者说 I 状态不监听信号).
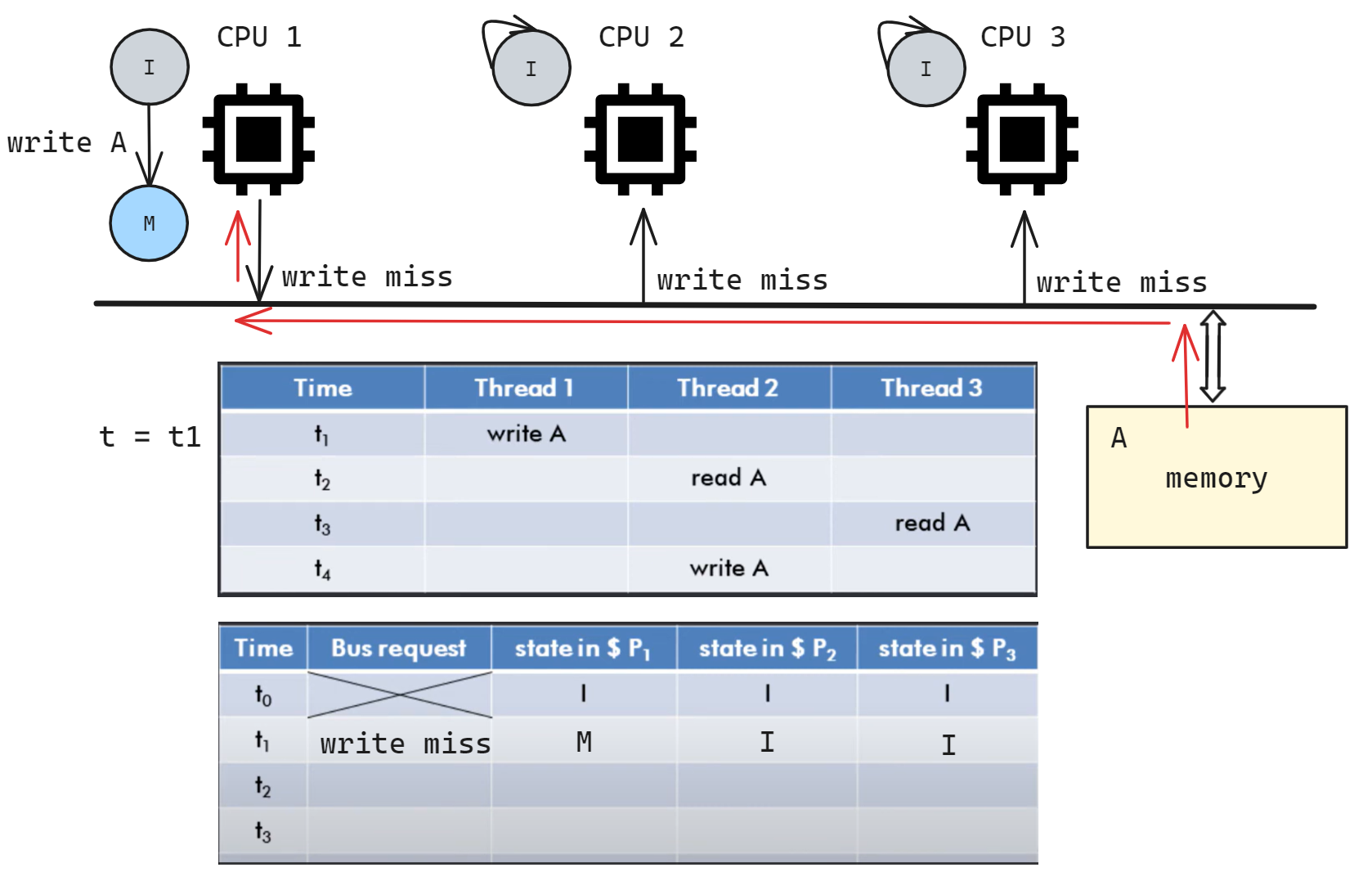
这里的 bus request 走的共享缓存总线, 还有数据总线和地址总线用于传输数据, 图中合并到一条 bus 中了没有画出来
t2 时 CPU2 read A, 此时 CPU2 进入 S 状态, 在总线广播 read miss; CPU1 收到信号后也转换为 S 状态, 并将自身最新的 A 数据发送给 CPU2, 同时写回内存, 中断 CPU2 的读内存请求; CPU3 不变.
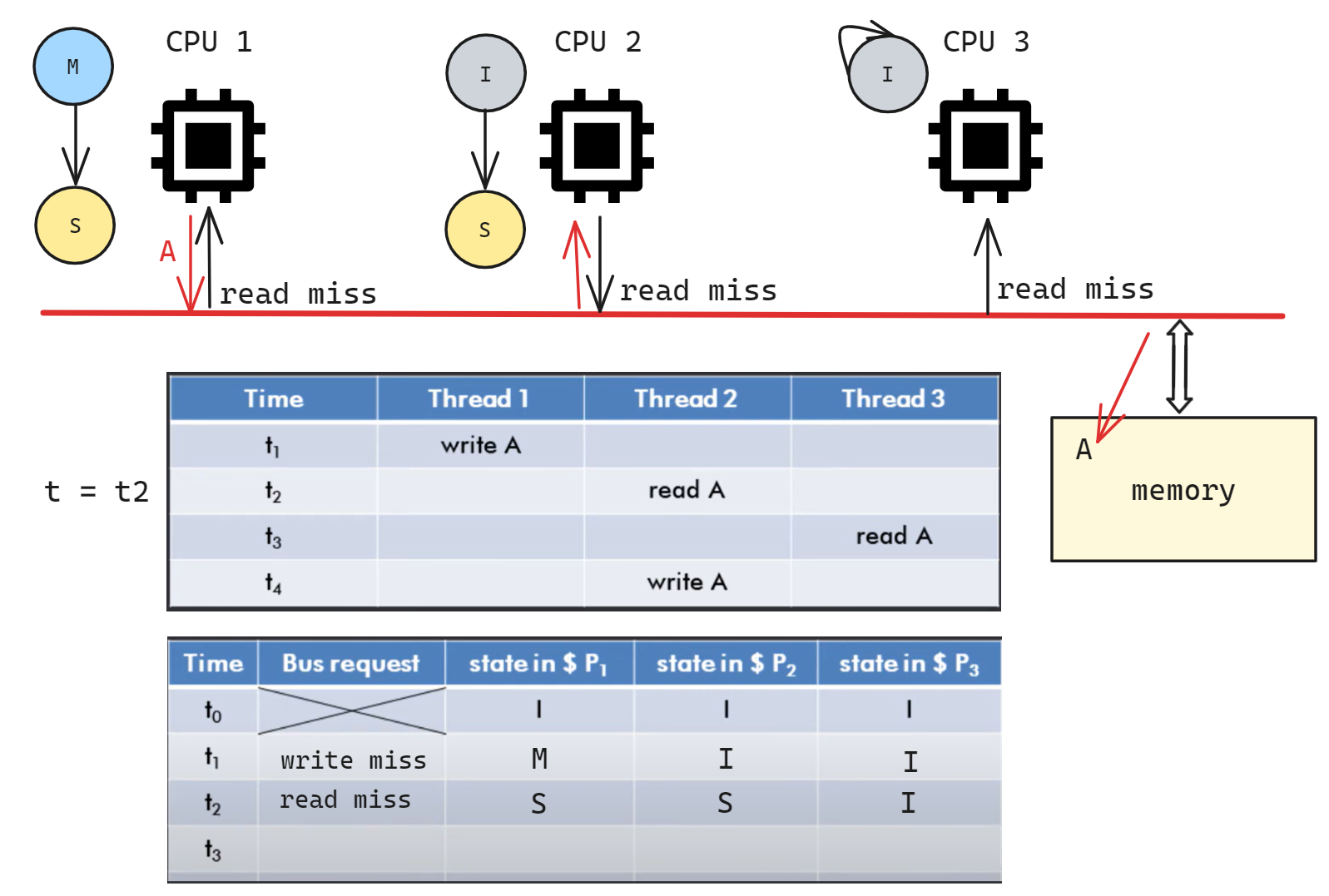
t3 时 CPU3 read A, 此时 CPU3 进入 S 状态, 在总线广播 read miss; CPU1/CPU2 收到信号后状态不变, 任意一个都可以将数据共享给 CPU3(图中标记 CPU2 共享数据, 实际上 CPU1 也可以)
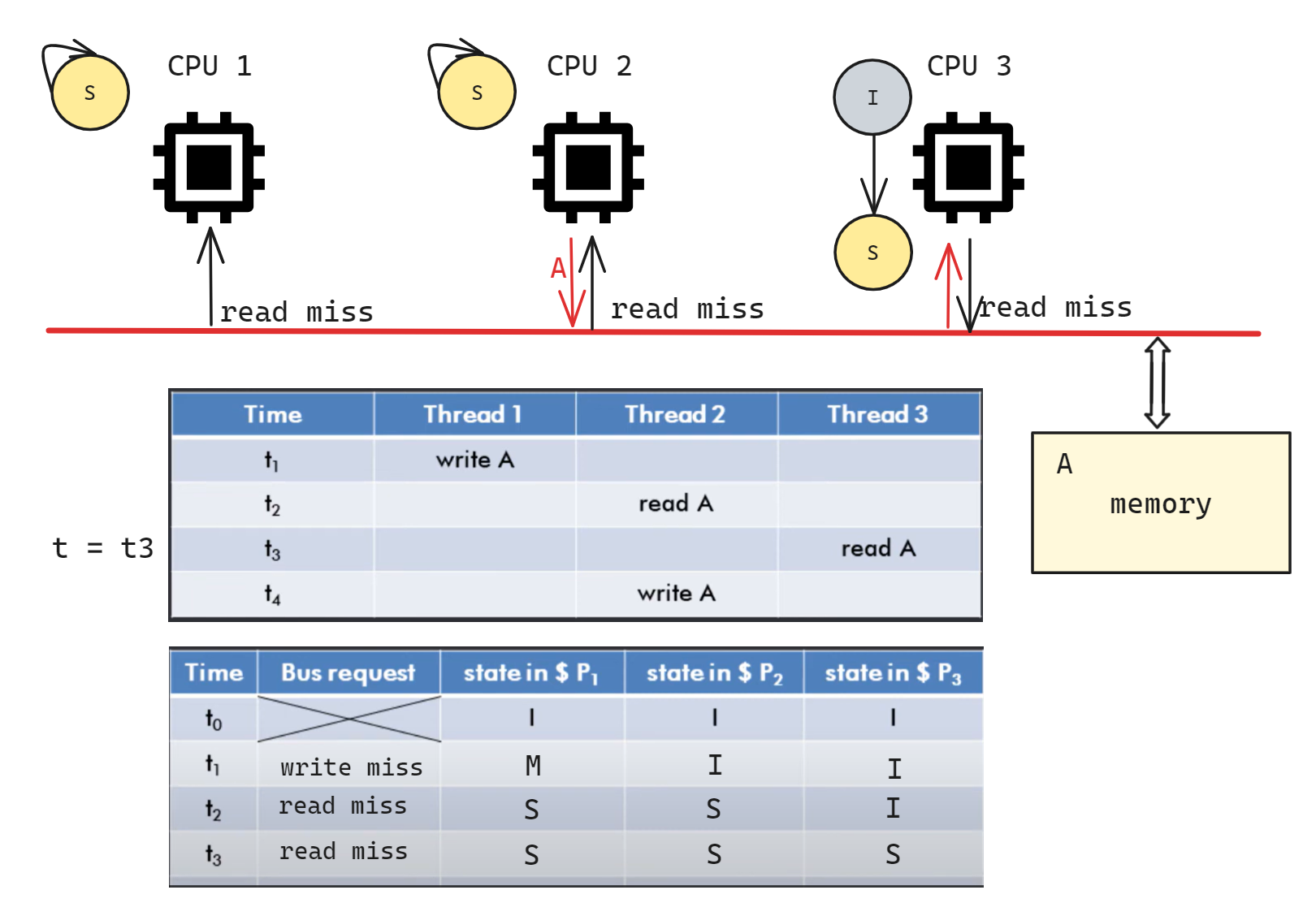
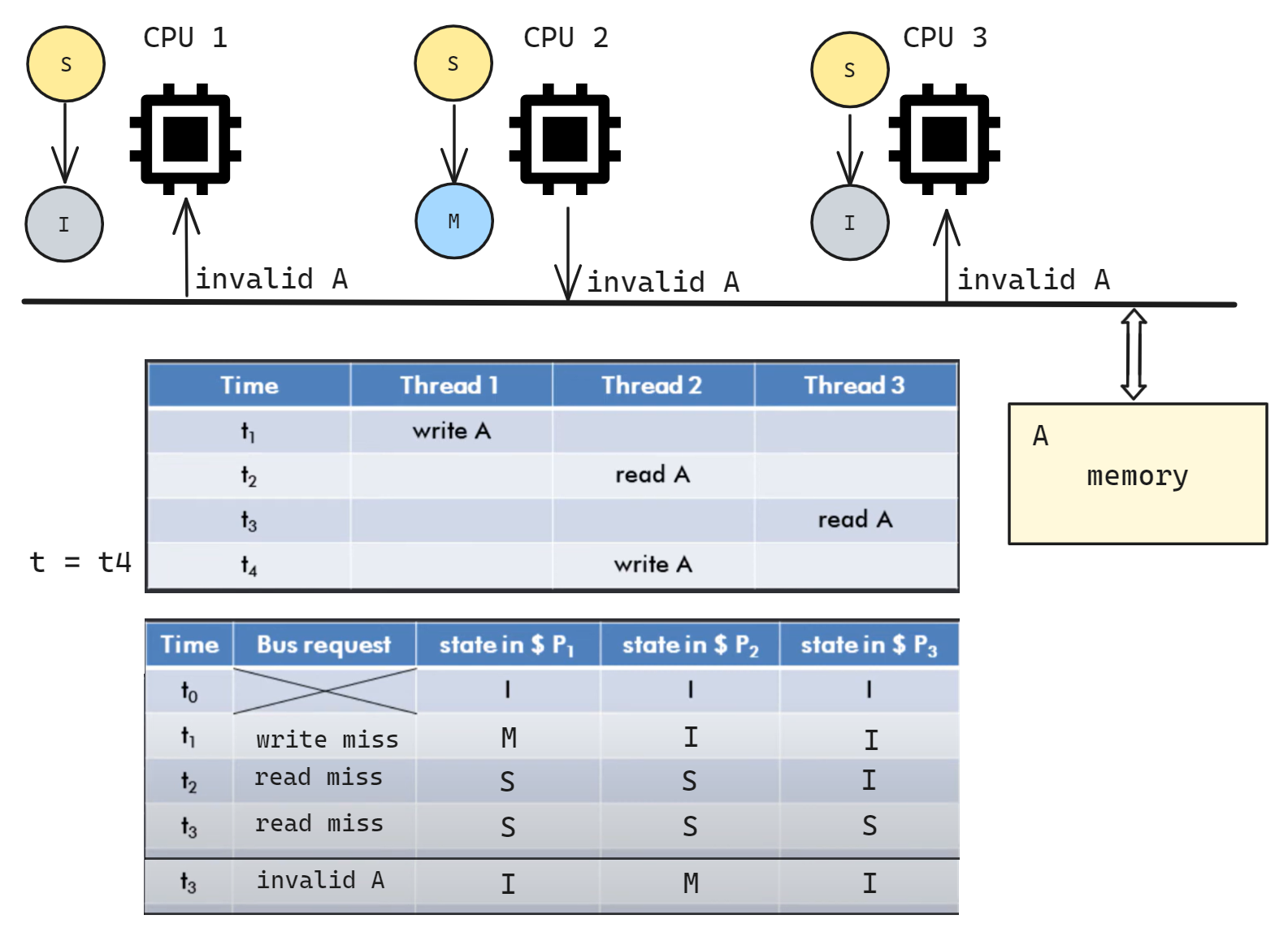
t4 时 CPU2 write A, 此时 CPU2 进入 M 状态, 在总线广播 invalid A; CPU1/3 收到信号后进入 I;
MESI
考虑对于下图的 t1-t4 的操作, 右侧为按照 MSI 协议 P1 P2 cache 的状态转换和 bus request 情况.
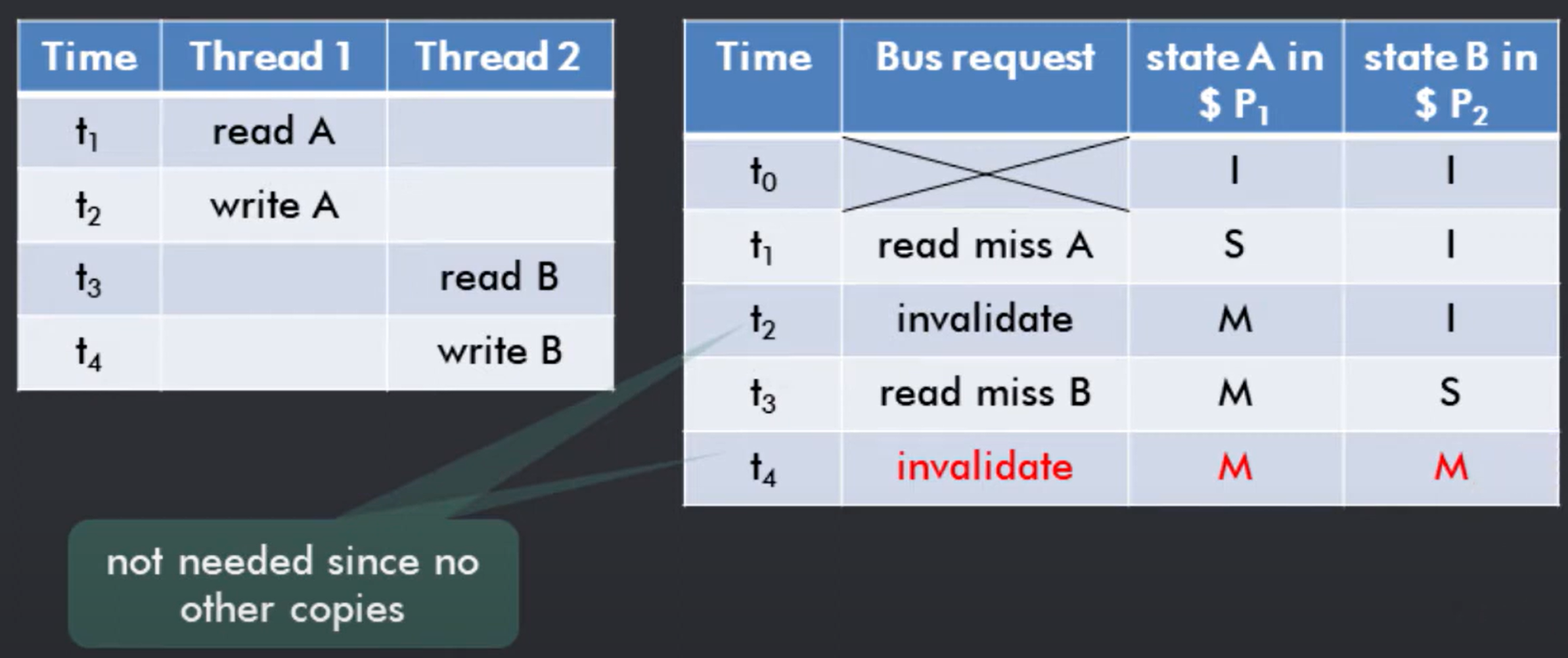
可以发现在 t2 和 t4 时刻, 由于写操作导致 S -> M, 此时需要在总线上广播 invalid 信号. 但实际上该操作是不必要的, 因为其实只有 P1 拥有唯一的 A cache, 这个信号占用了无效的总线带宽. 因此如果我们可以判断只有一个线程独占的拥有此数据,那么就可以避免广播无用的信号.
由此引出了改进的 MESI 协议, 其在 MSI 协议的基础上新增了一个 E 独占状态
Modified: 已修改, 此时缓存中的数据和内存中的数据不一致, 最新的数据只存在于当前的缓存块当中
Shared: 共享, 此时缓存数据和内存中的数据一致
Invalidated: 已失效, 该缓存块无效
Exclusive: 独占, 指数据和内存中的数据一致, 且数据只存在于本缓存块中
E 状态仅可能存在在一个高速缓存中, 这意味着相应的处理器可以直接写入而无需使其他的副本失效
下图为 MESI CPU request 的状态转移图, 相比 MSI 唯一的区别就是新增了一个 E 状态, S 状态维持不变; I 状态的 read miss 会先转换到 E 状态; 不会因为本机 CPU request 导致 E -> S 的转换, E -> S 的转换是总线的信号引发的
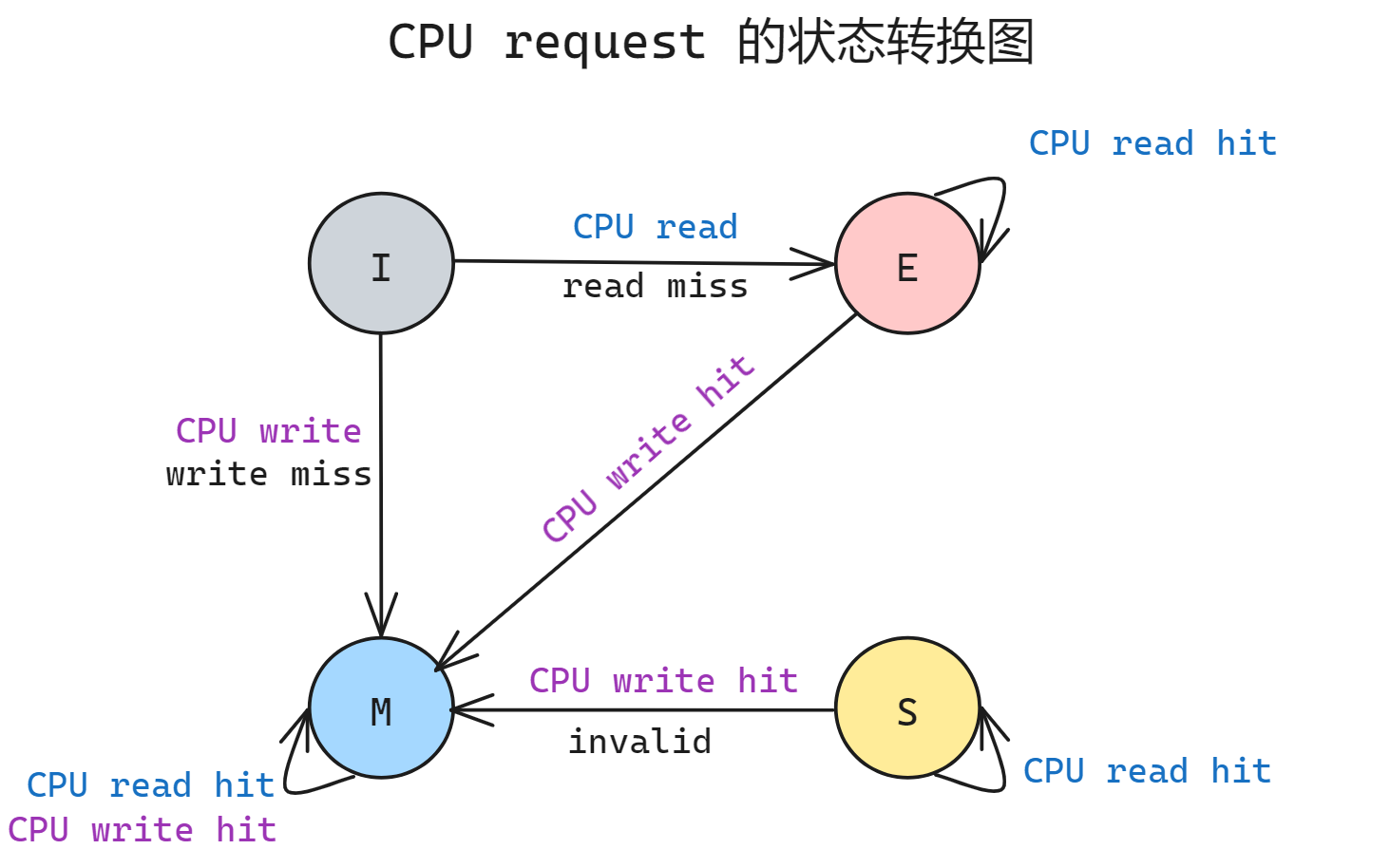
由于是独享的缓存, 所以 E 状态的 write hit 不会在总线广播 invalid 信号, 这样节约了总线带宽.
BUS request 转换图如下:
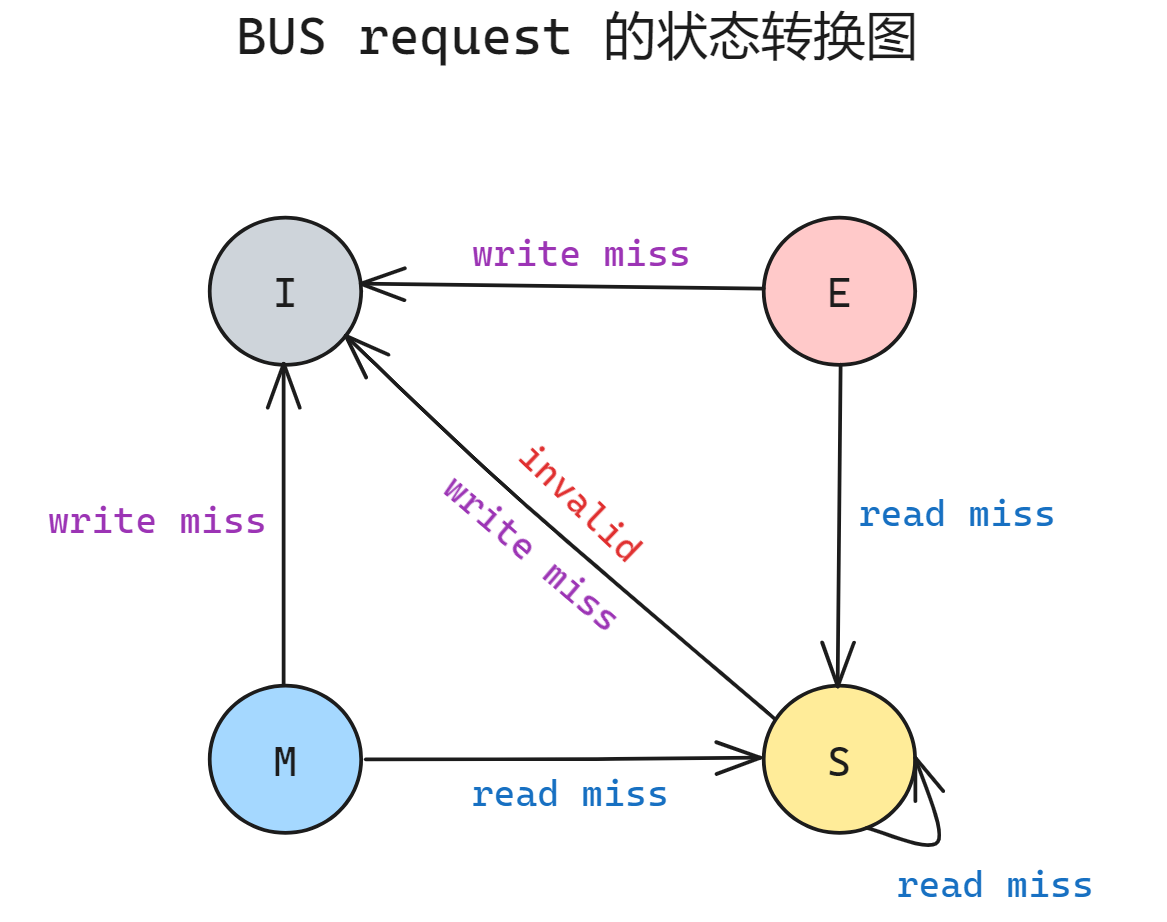
MESI 协议非常受欢迎因为他对于大多数的并行编程工作负载都表现得很好, 因为实际上大多情况下进程之间从不/很少通信, 因为不存在数据共享, 因此没有必要使得其他副本失效.
尽管这些协议是正确的, 但是它省略了许多复杂的因素, 比如该协议假定操作具有原子性, 即在完成一项操作的过程中不会发生任何中间操作. 例如这里假定可以采用单个原子动作形式来检测写入缺失, 获取总线和接收响应, 但现实情况是即使是读取缺失也可能不具备原子性, 非原子性的操作可能会导致死锁.
简单的总线嗅探系统模型:原子请求与原子事务, 复杂一些的总线嗅探系统模型:非原子请求与原子事务
其他一致性协议:MOESI / MESIF / Dragon / Firefly / Synapse 的内容暂时省略
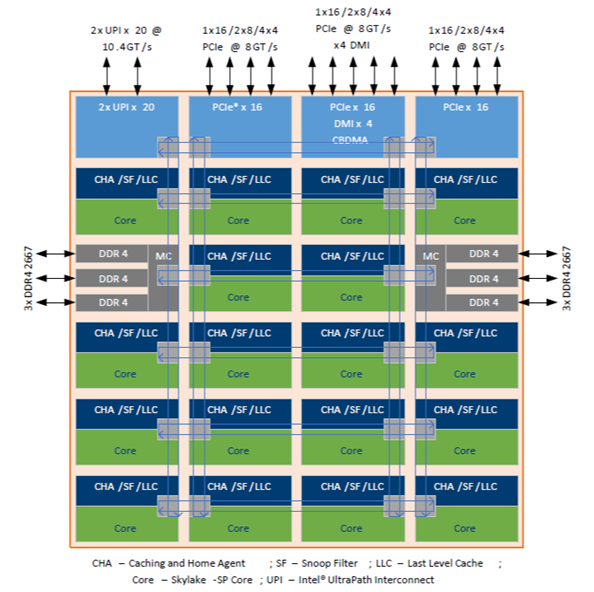
intel的这个多核处理器的Die结构中每一个核心上面都标有CHA/SF/LLC, 这里的 CHA 和 SF 就是和缓存一致性相关的功能部件
- CHA(Cache Home Agent)负责缓存一致性
- LLC (Last level Cache) 最后一级缓存,也就是L3
- SF(Snoop filter) 嗅探过滤一些多余的缓存更改消息
- UPI(Ultra Path Interconnect)负责CPU与CPU之间的互联
- PCIe/DMI CPU链接外设的主要接口
- MC/DDR4 (Memory control) 内存控制单元与内存
- MESH总线(黄色的那些连线),CPU内部各个单元的链接总线
目录协议
监听协议依赖基于广播的互联, 需要发送消息通知所有缓存. 自然广播介质是总线, 然而总线在这个模块中无法自然扩展, 更多处理器时需要扩展总线, 这也使得其长度和延迟的增大, 以及每个节点的可用带宽的减少.
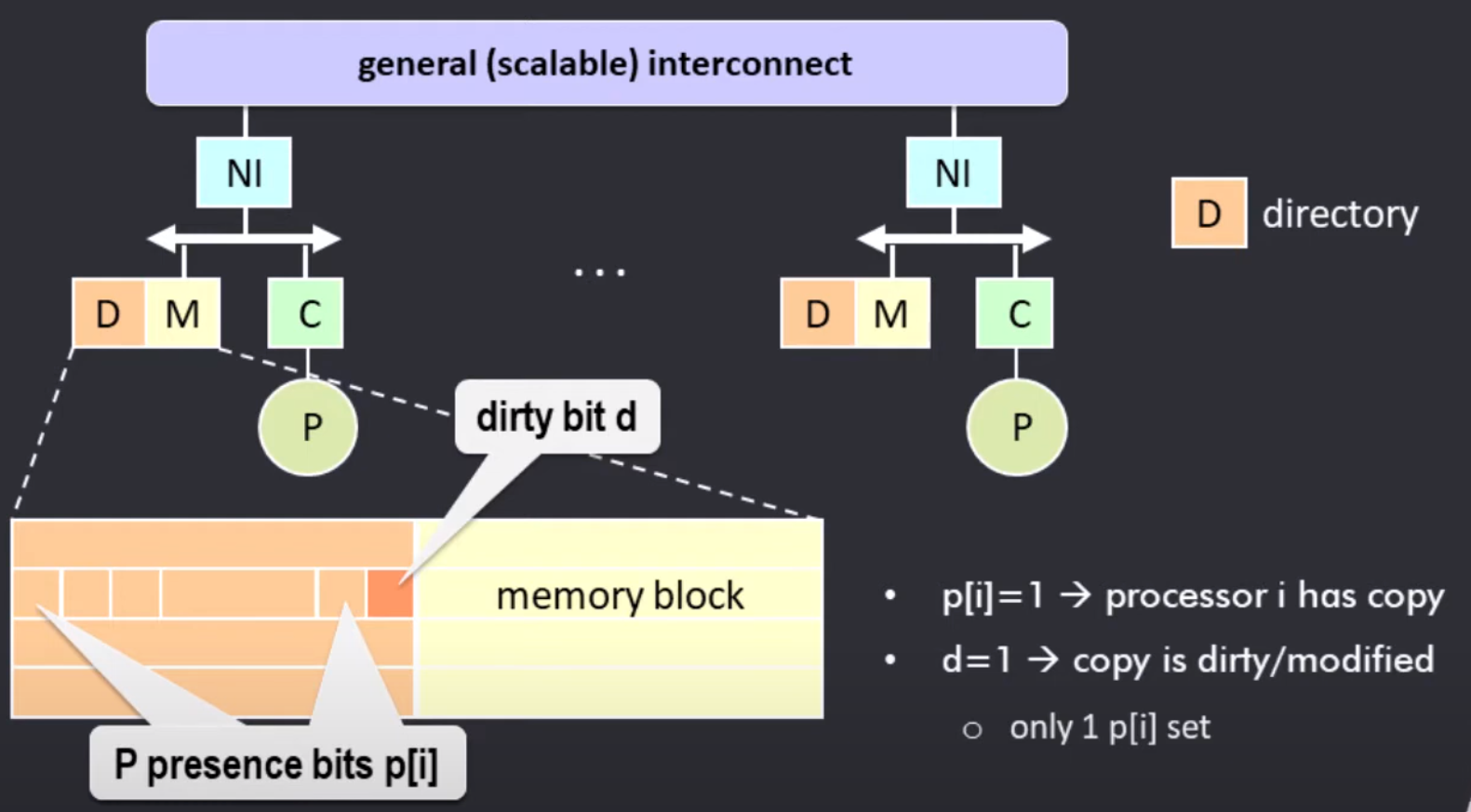
目录协议指的是所有共享数据块的信息都保存在中央的一个位置, 称为目录(directory-base). 目录保存所有块的状态, 例如是否含有 cache 的副本, dirty/modified 等信息
例如对于如下的一条目录项, 记录了缓存块 B 在所有处理器中是否有副本.

两个 1 代表 node 1 和 node 3 具有 copied cache line
对于 SMP 类型的目录协议, 我们需要一个集中的节点统一管理所有节点的缓存块情况. 节点分为三种类型:
local node/request node: 指发出 request 的节点
home node: 根节点, 记录所有缓存块的状态
remote node: 远端节点
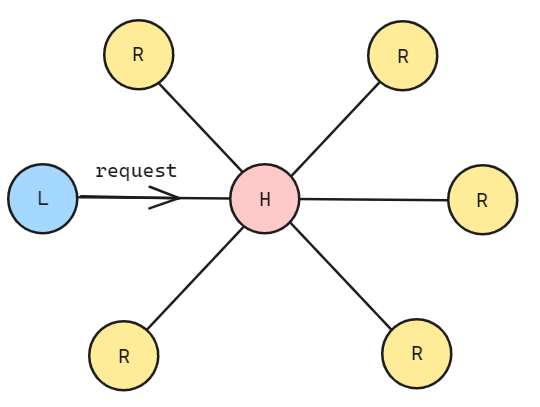
处理器的本地内存中保留一份目录, 目录的每个部分都由许多目录条目组成, 每个条目对应每个内存块.
对于 read miss / write hit / write miss 的情况 local node 都先与 home node 通信, 然后处理缓存一致性的问题, 这一点和 MSI 协议相同, 如下所示:
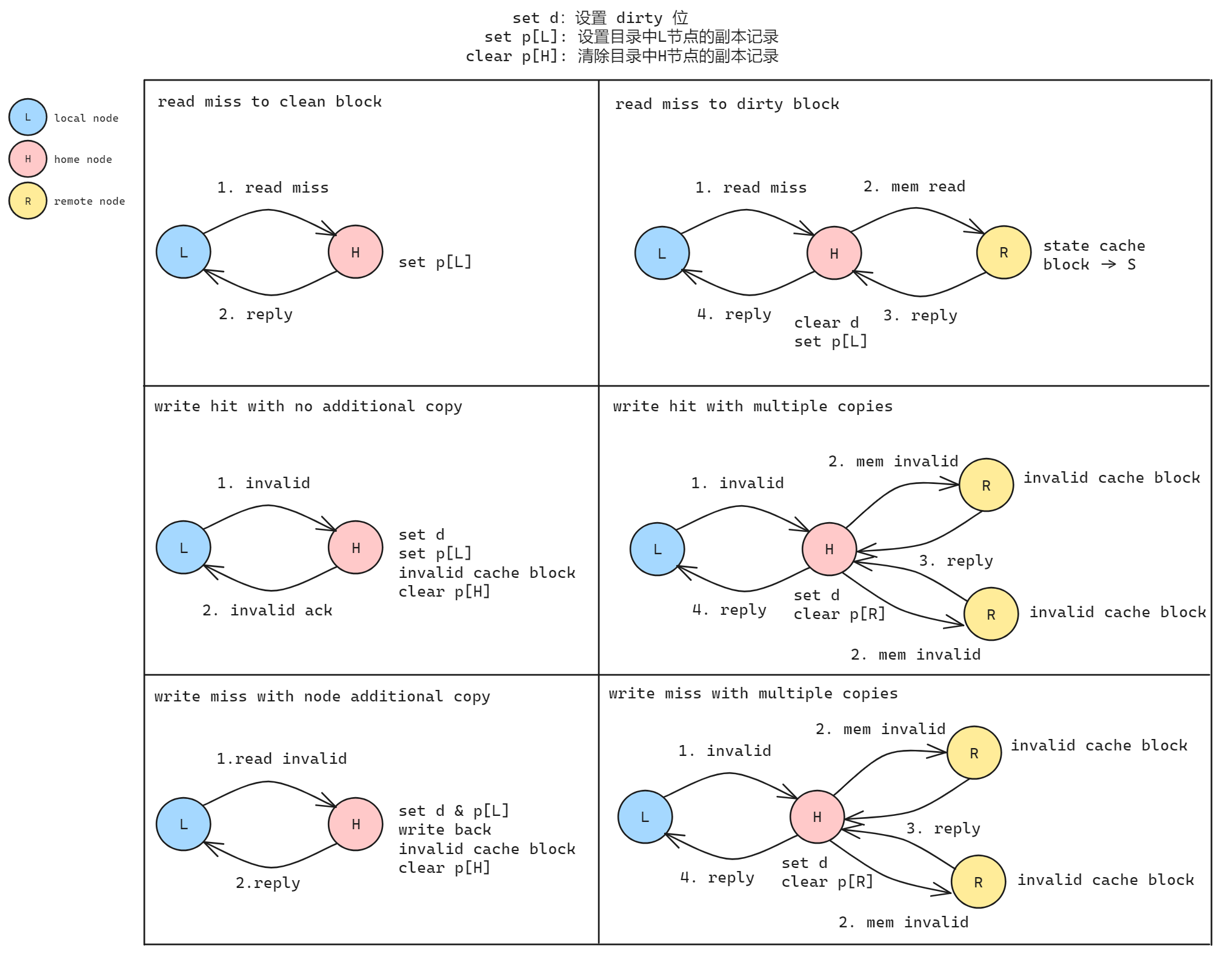
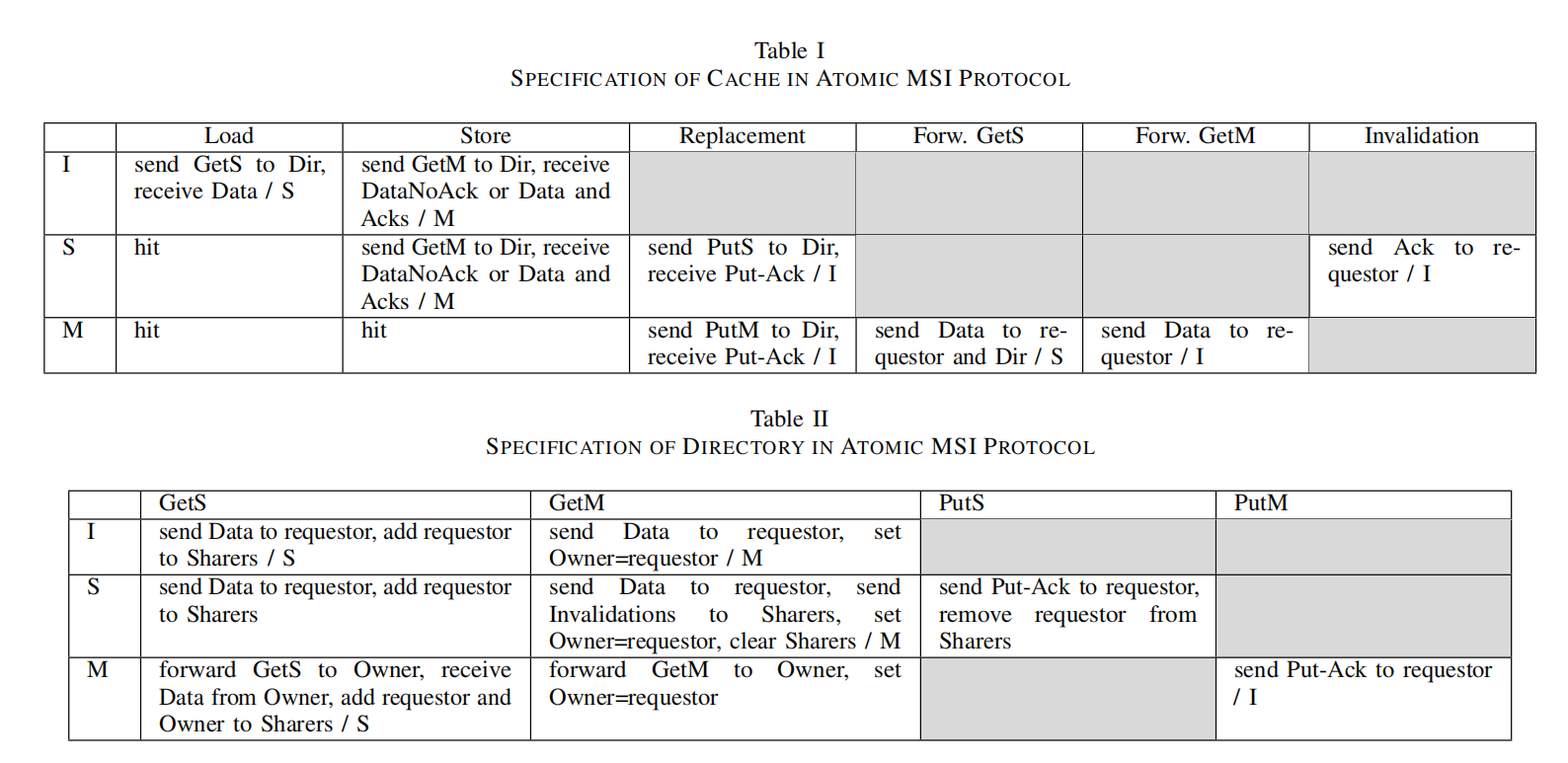
图源论文 "ProtoGen: Automatically generating directory cache coherence protocols from atomic specifications"
对于 DSM 的情况, 分布式的目录协议要更加复杂一些, 每个处理器的内存都保存一份目录副本; 业界一般采用 RDMA 或者 CXL 技术来负责 NUMA 节点之间的通信, 这里不做展开.