MallocLab
前言
malloc lab是设计一个自己的用于分配和管理内存的malloc free的实验
在文件夹内可以看到两个short1-bal.rep short2-bal.rep的测试文件, 但这里的测试文件并不全, 在编译之前首先需要添加 traces/ 文件夹, 可以在这里找到 traces, 然后将移动到本实验的根目录, 然后修改config.h中的路径
#define TRACEDIR "traces/"└── traces
├── amptjp-bal.rep
├── binary-bal.rep
├── binary2-bal.rep
├── cccp-bal.rep
├── coalescing-bal.rep
├── cp-decl-bal.rep
├── expr-bal.rep
├── random-bal.rep
├── random2-bal.rep
├── realloc-bal.rep
└── realloc2-bal.repmake编译即可
任务目标
我们需要完成的是mm.h中声明的四个函数, 在mm.c中实现
extern int mm_init (void);
extern void *mm_malloc (size_t size);
extern void mm_free (void *ptr);
extern void *mm_realloc(void *ptr, size_t size);- mm_init: 测试程序会首先调用 mm_init 分配一块内存, 我们之后的所有 mm_malloc mmrealloc mm_free 都是在分配的这段内存中进行操作, 即创建一个内存池
- mm_malloc: 与malloc类似, 在堆中分配一段 size 大小的连续内存, 测试程序会将mm_malloc与libc中的malloc实现对比, 并且由于malloc返回的指针是八字节对齐的, 所以我们的mm_malloc实现也应该是八字节对齐
- mm_free: 与free类似, 释放 ptr 指针指向的内存. 同时我们必须要保证指针指向的地址是之前通过 mm_malloc 或 mm_realloc 分配的, 并且没有被释放过的
- mm_realloc: 与realloc 相似
- ptr == NULL, 等同于 mm_malloc
- size == 0, 等同于 mm_free
- ptr != NULL && size != 0, 将原先 ptr 指针指向的内存重分配为 size 大小, 返回一个 ptr 指针可能与原先相同, 可能与原先不同, 这取决于 mm_realloc 的实现以及新老内存块的大小
我们并不能直接使用 malloc free realloc 等函数, 在 memlib.c 中提供了如下函数使用
- mem_sbrk: 扩展堆
- mem_heap_lo: 堆的最低地址(起始地址)
- mem_heap_hi: 堆的最高地址(结尾地址)
- mem_heapsize: 堆大小
- mem_pagesize: 返回系统页大小(linux 4kb)
堆检查器
由于动态内存分配器的设计, 在编写代码的过程中很容易导致一些内存未释放, 指针悬挂等问题. 为了更好的检查我们的内存分配器的正确性, 作者建议我们在开始之前先完成一个 堆检查器(heap checker), int mm_check(void) 主要用于检查
- 空闲列表中标记的空闲块都是空闲的么?
- 是否有连续的空闲块没有被合并?
- 所有的空闲块都在空闲列表中么?
- 空闲列表中的所有指针都指向了合法的空闲块么?
- 已分配的块是否存在重叠?
- 在堆上的指针是否指向的是合法的地址(已分配块的开头)?
关于这部分的设计与实现笔者将会放到最后面介绍, 笔者完成了此部分并扩展实现了一个堆内存的检查器: valloc
memlib.c
memlib.c 中包含着实验内存模型的设计, 其中关键函数 mem_init 和 mem_sbrk 如下所示. 其中初始化阶段程序调用 mem_init 构建了整个实验内存系统. 宏 MAX_HEAP 的值是 (20 * (1 << 20)) 也就是 20MB, mem_start_brk, mem_brk, mem_max_addr 分别代表堆的起始地址, 堆顶位置, 最高地址
这里说的初始化阶段调用 mem_init 是指测试程序 mdriver.c(289行) 去初始化整个实验, 整个实验是在 20MB 的一个堆内存中再做一个动态内存分配器. 这一步并不是前文提到的 mm_init, mm_init 是指初始化我们需要实现的动态内存分配器的一些数据结构等东西
注意这三个变量都是 static ,所以并不能在程序中直接调用, 需要依赖 memlib.c 中提供的函数间接调用.
mem_init 初始化后 mem_brk = mem_start_brk, 也就是堆大小暂时为 0
mem_sbrk 为堆扩容操作, 在函数内部将 mem_brk 堆顶指针上移, 返回扩容前的堆顶地址, 如果超过了最大堆大小则报错退出
正常来说 mem_sbrk 的函数原型 void *sbrk(intptr_t increment) 中的 increment 是支持正负两个方向的变化的, 这里没有考虑那么多, 也没必要考虑那么多...
/* private variables */
static char *mem_start_brk; /* points to first byte of heap */
static char *mem_brk; /* points to last byte of heap */
static char *mem_max_addr; /* largest legal heap address */
/*
* mem_init - initialize the memory system model
*/
void mem_init(void) {
/* allocate the storage we will use to model the available VM */
if ((mem_start_brk = (char *)malloc(MAX_HEAP)) == NULL) {
fprintf(stderr, "mem_init_vm: malloc error\n");
exit(1);
}
mem_max_addr = mem_start_brk + MAX_HEAP; /* max legal heap address */
mem_brk = mem_start_brk; /* heap is empty initially */
}
void *mem_sbrk(int incr) {
char *old_brk = mem_brk;
if ((incr < 0) || ((mem_brk + incr) > mem_max_addr)) {
errno = ENOMEM;
fprintf(stderr, "ERROR: mem_sbrk failed. Ran out of memory...\n");
return (void *)-1;
}
mem_brk += incr;
return (void *)old_brk;
}前置知识
开始本实验之前建议先复习一下虚拟内存动态内存分配 9.9 节, 读者也可以阅读笔者的一些文档
这里做一个简要的回顾, 采用隐式静态链表连接各个块, 结构如下
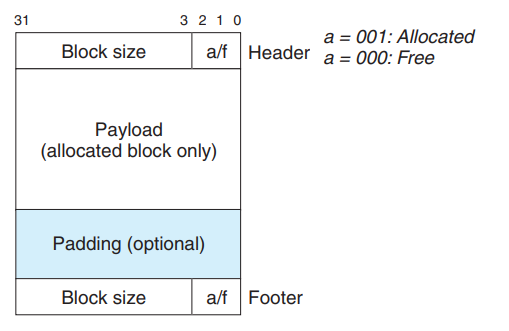
堆中隐式链表的上各个块的组织结构如下
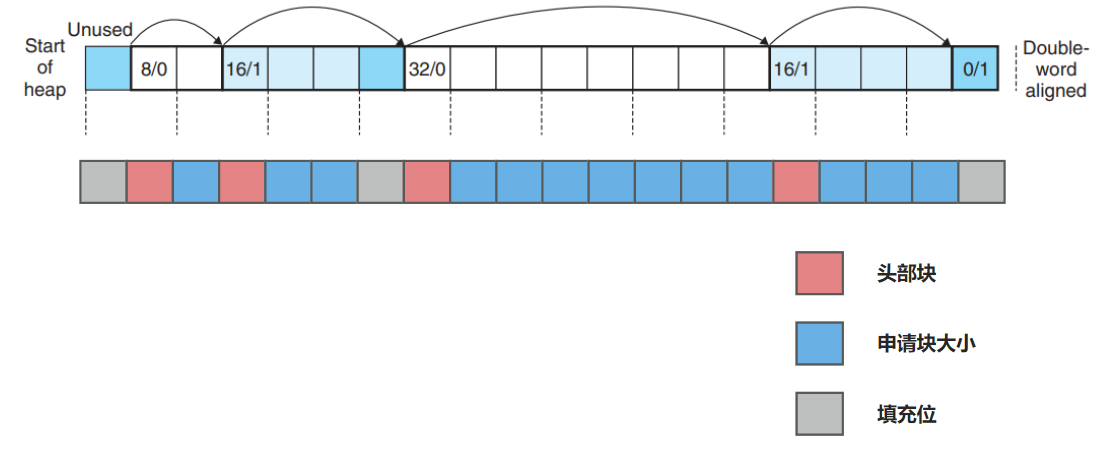
其中每一个正方形块代表 4 字节, 这里的 8/0 16/1 表示的意思是 分配块的大小/已分配位, 红色块为链表头, 蓝色块为实际申请的内存大小, 灰色块为填充位. 所以整个堆被划分为了几部分, 4字节空闲 + 8字节已分配 + 24字节空闲 + 12字节已分配, 中间穿插着一些头部信息块和填充块. 再创建一个链表结构保存头节点的相关信息, 以实现后续的分配释放
当分配器释放一个块的时候有四种情况, 其中中间空白处+前后的头/尾组成了一个完整的分配块, m1 m2为块大小, a/f 表示这个块是已分配的还是空闲的. 蓝色的块是当前分配器考虑释放的块
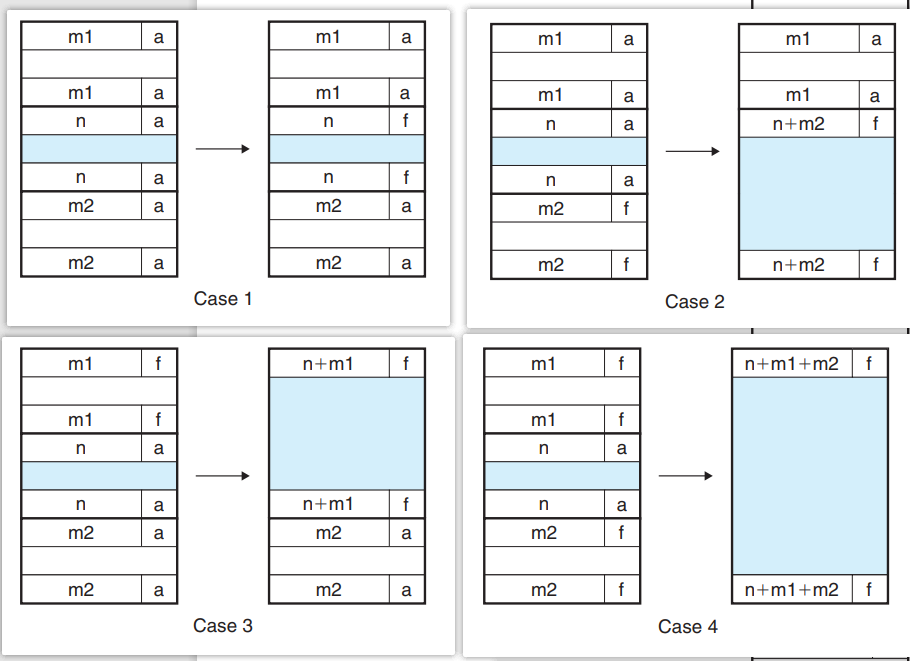
- 前后都是已分配的
- 前是已分配的, 后是空闲的
- 前是空闲的, 后是已分配的
- 前后都是空闲的
隐式空闲链表
CSAPP 书中给出了相关的代码说明, 这里做一个补充总结
完整代码实现见 mm_implicit.c
宏定义
下面介绍一下代码中涉及到的宏定义
#define WSIZE 4 // 单字大小
#define DSIZE 8 // 双字大小
#define CHUNKSIZE (1 << 12) // 扩展堆时的默认大小
#define MAX(x, y) ((x) > (y) ? (x) : (y)) // 比较大小
#define GET(p) (*(unsigned int *)(p))
#define PUT(p, val) (*(unsigned int *)(p) == (val))
#define PACK(size, alloc) ((size) | (alloc))
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1)
#define HDRP(bp) ((char *)(bp)-WSIZE)
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp)-WSIZE)))
#define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp)-DSIZE)))
void *heap_listp;
static void *extend_heap(size_t words); // 堆空间不足时扩展
static void *coalesce(void *bp); // 合并空闲块
static void *first_fit(size_t size);
// static void *best_fit(size_t size);
void *(*search_method)(size_t size) = first_fit; // 搜索算法
static void place(void *bp, size_t size);其中 WSIZE 和 DSIZE 分别为单字和双字, CHUNKSIZE 为默认的扩展堆大小(4MB). MAX 比较大小
GET(p) 和 PUT(p,val) 分别为取值和赋值, 注意因为 p 是 void * 类型所以这里使用了 unsigned int* 来做一个强制类型转换读取四字节的数据
PACK GET_SIZE GETALLOC 这三个宏比较清晰, 对应上文提到的每一个块的头部的数据含义, 最低一位代表是否分配, 低三位因为对齐所以不考虑其对大小的影响
HDRP 根据实际块指针向前推4字节得到链表块的头部, 这里的变量名 bp 代表块指针(payload部分), p 是整个块的指针
这里的堆是从低地址向高地址增长,所以是-WSIZE.
FTPR 得到链表块的尾部, 块指针加上块大小, 再向后推一个头一个尾8字节得到当前块的尾部地址.
NEXT_BLKP 和 PREV_BLKP 分别是得到前一个和后一个块指针
最后再定义一个全局符号 heap_listp 代表头指针, 用于后续查找. 全局符号 search_method 用于搜索算法的选择, 这样可以比较方便的切换 first_fit 和 best_fit 或者其他
mm_init
mm_init 用于初始化动态内存分配器
int mm_init(void) {
if ((heap_listp = mem_sbrk(4 * WSIZE)) == (void *)-1) {
return -1;
}
PUT(heap_listp, 0);
PUT(heap_listp + (1 * WSIZE), PACK(DSIZE, 1));
PUT(heap_listp + (2 * WSIZE), PACK(DSIZE, 1));
PUT(heap_listp + (3 * WSIZE), PACK(0, 1));
heap_listp += 2 * WSIZE;
if (extend_heap(CHUNKSIZE / WSIZE) == NULL) {
return -1;
}
return 0;
}首先使用 mem_sbrk 扩展堆, 申请四个块. 这四个块用于维护我们后续的链表
- 块1 不使用, 只是作为填充位, 为了使分配的地址是 8 字节对齐的
- 块2,3 是一个 序言块, 这是一个 8 字节的已分配的块, 只有头尾块没有申请块, 作为整个链表的头部
- 块4 是一个结尾块, 这个块的设计比较巧妙
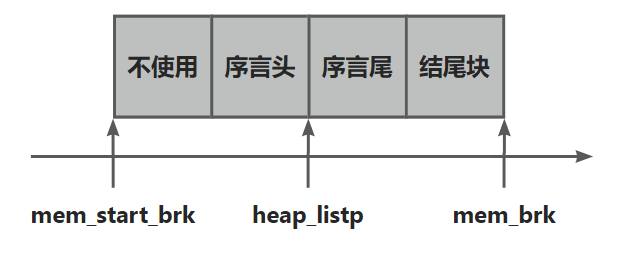
回顾一下前面提到的宏的含义, PUT 用于赋值, PACK 合并size和分配位. 最后将 heap_listp 指向序言块的中间位置. 接着调用 extend_heap 扩展堆大小
这里的 heap_listp 现在是 += 2 WSIZE, 实际上改为 4 WSIZE 更好, 因为跳过序言块直接指向第一个空闲块
extend_heap 传入的参数需要考虑 8 字节对齐, 所以传参的时候使用 CHUNKSIZE / WSIZE 然后在内部判断对于奇数补齐.
static void *extend_heap(size_t words) {
char *bp;
size_t size;
size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE;
if ((long)(bp = mem_sbrk(size)) == -1) {
return NULL;
}
PUT(HDRP(bp), PACK(size, 0)); // 头部块置0
PUT(FTRP(bp), PACK(size, 0)); // 尾部块置0
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); // 重置结尾块
return coalesce(bp);
}接下来的操作比较有意思, 申请了一块 size 大小的堆空间, 返回 bp 为原先 mem_brk 的位置, 新的 mem_brk 移到尾部
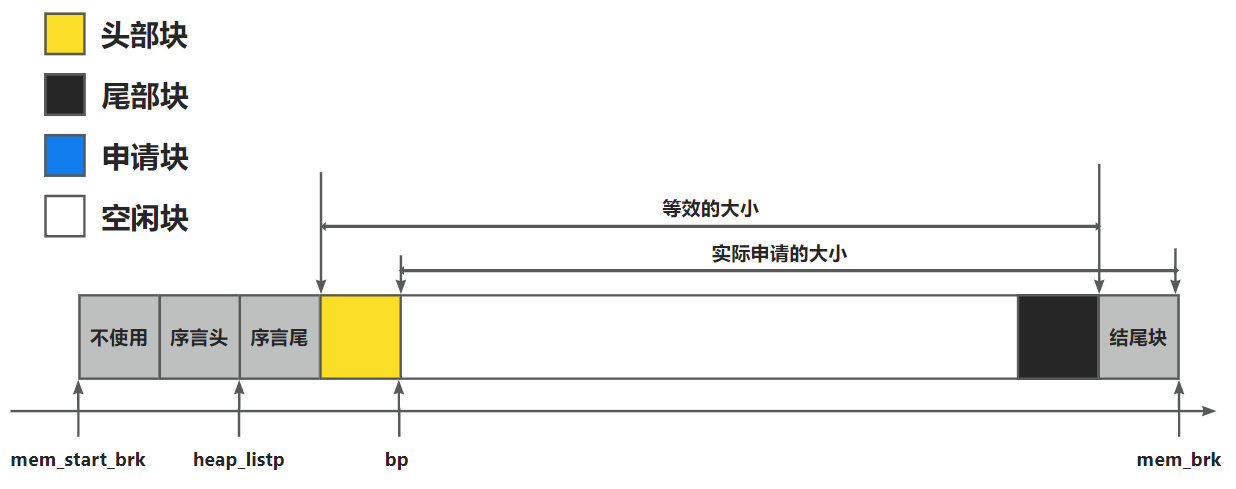
现在的结构如上图所示, 实际上分配的 size 是 (bp, mem_brk) 的区间, 但由于每一个块都是 WSIZE 大小, 所以相当于等效的前移一个块的位置. 因此可以直接将通过 mem_sbrk 返回的指针 bp 看作是一个空分配的区间块, PUT 设置其 HDRP 和 FTRP 为未分配0, 然后再通过 NEXT_BLKP(bp) 找到下一个的位置, 也就是新的结尾块.
extend_heap 会在两种情况下被调用
- 初始化堆
- mm_malloc 找不到一个可用的(足够大)块, 扩容堆空间
最后在结尾处调用了 coalesce(bp) 尝试合并块
因为扩容的时候可能最后一个是空闲块, 但是大小不够分配. 所以需要把新扩容的空闲块和最后一个空闲块合并为一个空闲块
考虑之前提到的合并的四种情况, 只需要考虑当前块前面和后面的块的状态
对应下面四种情况的代码, 通过之前定义的宏, 可以比较方便的找到对应的头尾, 修改为更新后的 size
static void *coalesce(void *bp) {
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size = GET_SIZE(HDRP(bp));
// case 1: 前后都被占用
if (prev_alloc && next_alloc) {
return bp;
} else if (prev_alloc && !next_alloc) {
// case 2: 前占后不占
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
return bp;
} else if (!prev_alloc && next_alloc) {
// case 3: 前不占后占
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
return PREV_BLKP(bp);
} else {
// case 4: 前后都空
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
return PREV_BLKP(bp);
}
}另外现在回看使用的序言块和结尾块, 将开头和结尾都设置了已分配, 这样可以避免边界情况的判断, 省去不少麻烦
同时也可以看到之前定义的一些宏相当有作用, 看起来代码很简洁可读
值得一提的是, 如果需要修改一个块的 HDRP 和 FTRP 的size, 应该先修改 HDRP, 因为 FTRP 的定位需要 GET_SIZE, 这依赖了 HDRP 的size的值
mm_malloc
mm_malloc 的实现如下, 首先根据 size 重新计算一下实际上需要分配的块大小 block_size, 然后通过一个搜索算法找到一个合适的块, 使用 place 将这个块分配. 如果没有找到合适的块则扩容后 place
扩容的大小是 MAX(block_size, CHUNKSIZE)
void *mm_malloc(size_t size) {
size_t block_size; // 块大小
size_t extend_size; // 额外分配的堆空间
void *bp;
if (size == 0) {
return NULL;
}
// 小于等于 DSIZE 的大小直接补齐 2*DSIZE
if (size <= DSIZE) {
block_size = 2 * DSIZE;
} else {
// DSIZE 对齐 + 头尾 DSIZE
block_size = (size + DSIZE - 1) / DSIZE * DSIZE + DSIZE;
}
// 通过搜索算法找到一个合适的空闲块
if ((bp = search_method(block_size)) != NULL) {
place(bp, block_size);
return bp;
}
// 如果没找到, 说明需要扩容堆空间
extend_size = MAX(block_size, CHUNKSIZE);
if ((bp = extend_heap(extend_size / WSIZE)) == NULL) {
// 扩容失败, 堆已达最大 MAX_HEAP
return NULL;
}
place(bp, block_size);
return bp;
}首次适配算法就是找到第一个 free 的, 并且 size 足够大的
如果 block_size 是0, 那么就说明到达了结尾块
注意之前在 mm_init 的时候将结尾块设置了 size = 0, 除了这个块之外的所有块的大小至少是 DSIZE
void *first_fit(size_t size) {
void *bp = heap_listp;
while (1) {
// 已被分配, 下一个
size_t block_size = GET_SIZE(HDRP(bp));
if (GET_ALLOC(HDRP(bp))) {
bp = NEXT_BLKP(bp);
} else {
// 空闲块
if (block_size >= size) {
// 大小足够, 直接返回
return bp;
} else {
bp = NEXT_BLKP(bp);
}
}
if (block_size == 0) {
return NULL;
}
}
}最佳适配就是找到一个满足的 block_size 最小的块用于分配
void *best_fit(size_t size) {
void *bp = heap_listp;
void *best_bp = NULL;
size_t min_block_size = -1;
while (1) {
// 已被分配, 下一个
size_t block_size = GET_SIZE(HDRP(bp));
if (GET_ALLOC(HDRP(bp))) {
bp = NEXT_BLKP(bp);
} else {
// 空闲块
if (block_size >= size) {
if (block_size < min_block_size) {
min_block_size = block_size;
best_bp = bp;
}
}
bp = NEXT_BLKP(bp);
}
if (block_size == 0) {
break;
}
}
return best_bp;
}place 的实现如下, 需要判断一下当前块的剩余空间是否足够大, 是否分裂
最小的块的大小应该是只有一个 header 和 footer, 也就是 DSIZE, 小于等于这个值就说明不值得被分裂. 直接将一整块都分配过去, 也就是修改的分配的 size 为 block_size
void place(void *bp, size_t size) {
size_t block_size = GET_SIZE(HDRP(bp));
size_t block_rest_size = block_size - size;
// 剩余块的大小 <= 最小块大小
if (block_rest_size <= DSIZE) {
PUT(HDRP(bp), PACK(block_size, 1));
PUT(FTRP(bp), PACK(block_size, 1));
} else {
// 分裂
PUT(HDRP(bp), PACK(size, 1));
PUT(FTRP(bp), PACK(size, 1));
PUT(HDRP(NEXT_BLKP(bp)), PACK(block_rest_size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(block_rest_size, 0));
}
}mm_free
mm_free 的实现就比较简单了, 直接将这里的分配位置为 0 即可
当然, 这里的假设是free的ptr一定是之前已经分配过的, 真实情况的处理还需要考虑 double free 以及 ptr 地址无效的情况
void mm_free(void *ptr) {
size_t size = GET_SIZE(HDRP(ptr));
PUT(HDRP(ptr), PACK(size, 0));
PUT(FTRP(ptr), PACK(size, 0));
coalesce(ptr);
}mm_realloc
mm_realloc 的实现稍微复杂一些, 首先回顾一下 realloc 的时候可能出现的情况
- ptr == NULL, 等同于 mm_malloc
- size == 0, 等同于 mm_free
- ptr != NULL && size != 0
对于最后一种情况再分类讨论一下
- size == block_size: 直接返回
- size < block_size: 在当前块中修改, 同时需要注意一下是否需要分裂
- size > block_size:
- 下一个块是否是空闲且空间足够, 如果足够则合并后面的块, 同时需要注意一下是否需要分裂
- 重新 mm_malloc 一个新的块, 然后把之前的使用 memcpy 复制到新的块, 释放原先的块
最后需要注意一点的是 memcpy(bp, ptr, block_size - DSIZE), 这里的复制的大小是 block_size - DSIZE, 这是因为 block_size 实际上是整个分配块的大小, 也就是 header + payload + padding + footer 的大小, 实际有效的分配空间是 payload + padding, 这部分才是需要copy过去的大小, 因此对于 ptr 这个指针的位置复制 block_size - DSIZE 空间即可
void *mm_realloc(void *ptr, size_t size) {
if (ptr == NULL) {
return mm_malloc(size);
}
if (size == 0) {
mm_free(ptr);
return NULL;
}
size = (size + DSIZE - 1) / DSIZE * DSIZE + DSIZE;
size_t block_size = GET_SIZE(HDRP(ptr));
if (size == block_size) {
return ptr;
} else if (size < block_size) {
// 在当前分配块中修改大小
size_t block_rest_size = block_size - size;
// 判断是否分裂
if (block_rest_size > DSIZE) {
PUT(HDRP(ptr), PACK(size, 1));
PUT(FTRP(ptr), PACK(size, 1));
PUT(HDRP(NEXT_BLKP(ptr)), PACK(block_rest_size, 0));
PUT(FTRP(NEXT_BLKP(ptr)), PACK(block_rest_size, 0));
}
return ptr;
} else {
if (!GET_ALLOC(HDRP(NEXT_BLKP(ptr))) &&
(GET_SIZE(HDRP(NEXT_BLKP(ptr))) >= (size - block_size))) {
// 下一个块就有空间
size_t next_block_rest_size = GET_SIZE(HDRP(NEXT_BLKP(ptr))) + block_size - size;
if (next_block_rest_size <= DSIZE) {
size_t new_size = GET_SIZE(HDRP(NEXT_BLKP(ptr))) + block_size;
PUT(HDRP(ptr), PACK(new_size, 1));
PUT(FTRP(ptr), PACK(new_size, 1));
return ptr;
} else {
PUT(HDRP(ptr), PACK(size, 1));
PUT(FTRP(ptr), PACK(size, 1));
PUT(HDRP(NEXT_BLKP(ptr)), PACK(next_block_rest_size, 0));
PUT(FTRP(NEXT_BLKP(ptr)), PACK(next_block_rest_size, 0));
return ptr;
}
} else {
void *bp = mm_malloc(size);
if (bp == NULL) {
return NULL;
}
memcpy(bp, ptr, block_size - DSIZE);
mm_free(ptr);
return bp;
}
}
}实验结果
make
./mdriver -V -t traces/first_fit 的结果 75/100
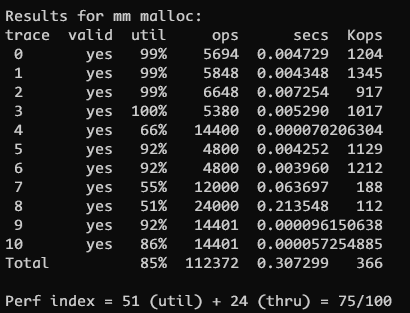
best_fit 的结果 68/100, 主要是因为 best_fit 需要扫描所有块
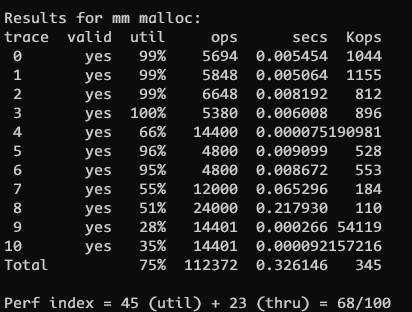
显然 75 分并不够理想, 我们需要考虑一下如下优化程序. 观察一下测试结果, 其中手册中提到了评分标准, 正确性20%, 空间利用率 util 和操作数Kops 分别 35%, 最后 10% 是代码规范性
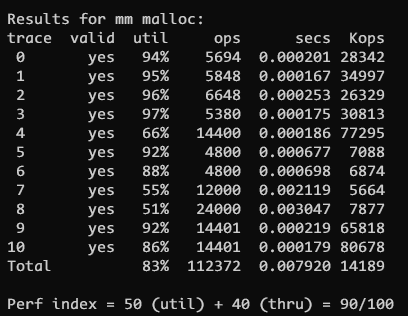
Results for mm malloc:
trace valid util ops secs Kops
0 yes 99% 5694 0.004722 1206
1 yes 99% 5848 0.004367 1339
2 yes 99% 6648 0.007349 905
3 yes 100% 5380 0.005558 968
4 yes 66% 14400 0.000072200278
5 yes 92% 4800 0.004250 1129
6 yes 92% 4800 0.003929 1222
7 yes 55% 12000 0.064229 187
8 yes 51% 24000 0.215506 111
9 yes 92% 14401 0.000096150010
10 yes 86% 14401 0.000055260888
Total 85% 112372 0.310133 362
Perf index = 51 (util) + 24 (thru) = 75/100考虑一下导致分数不佳的原因, 也就是整体拖慢程序的性能的根源, 在于 first_fit 的搜索.
malloc 主要的难点就是在于如何在尽可能短的时间内找到一个合适的块用于分配, 目前的 first_fit 近乎 O(N) 的时间复杂度, 随着块的分配数量越来越多, 耗时会越来越长, 这显然是不甚理想的
显式空闲链表
完整代码实现见 mm_explicit.c
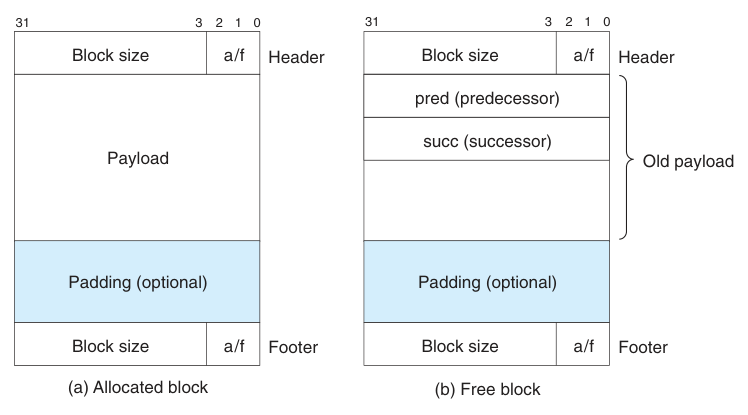
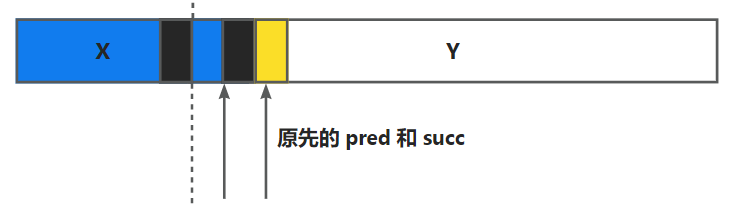
显式空闲链表的又进一步设置了两个小块, pred 和 succ 分别记录前驱和后继. 如下所示
需要注意的是, 只有空闲块会有这两个结构, 如果一个块被分配出去了, 那么还是在原先的 payload 的位置保存数据, 分配块是不需要记录前驱后继的信息的. 空闲块反正后面的空间也没有人使用, 占了也就占了. 这样就可以把 first_fit 搜索全部块优化为通过链表搜索空闲块.
这里使用双向链表的原因是为了分配的时候可以在 O(1) 找到前一个和后一个空闲块, 否则只能不断地 NEXT/PRED + GET_ALLOC 的去找
这样的一个显然的好处就是只会搜索空闲块, 如果在已分配块很多的情况下效率就会高很多.
当然, 带来的一个问题就是又加入了新的结构, 每一个分配块的最小大小又增加了, 内部空间碎片率也会更高
与此同时还需要考虑的一个问题就是如何更新和维护这个双向链表. 如下图A所示, "?" 块刚刚被释放, 它需要作为一个空闲块加入链表, 那么如何更新链表呢
这里实际上是双向链表, 做了一步画图上的省略
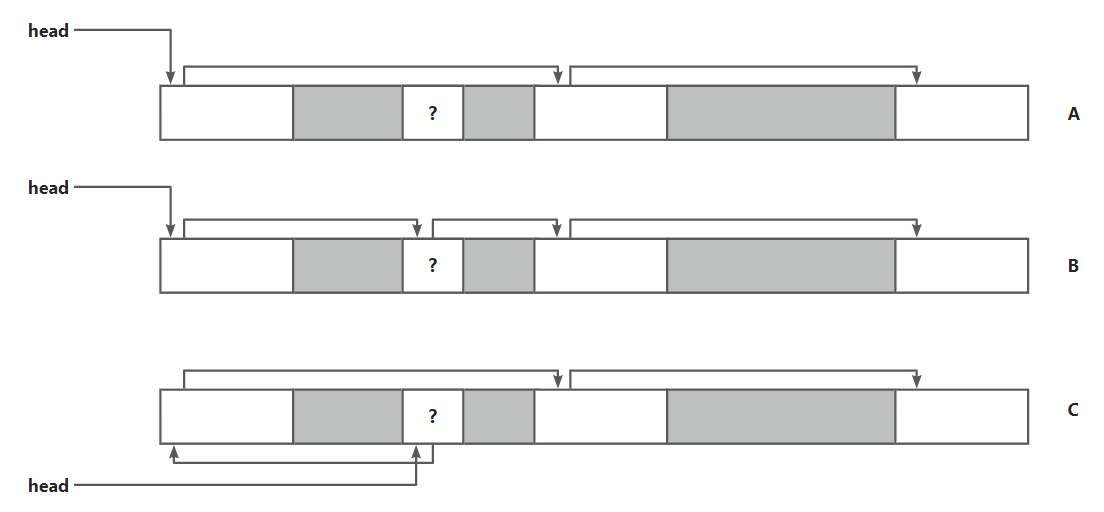
第一种方式 B 就是直接按照顺序加入, 但是显然这需要 O(N) 的时间搜索前一个空闲块的位置
第二种方式 C 直接将释放的块插入到链表的头部, 这样就可以实现在 O(1) 时间内完成回收.
宏定义
对照原先的宏定义又添加了如下
#define PUT_ADDR(p, val) (*(unsigned long *)(p) = (unsigned long)(val))
#define VAL(val) (val == NULL ? 0 : (*(unsigned long *)val))
#define PRED(bp) ((char *)(bp))
#define SUCC(bp) ((char *)(bp) + DSIZE)
#define NEXT_FREE_BLKP(bp) ((void *)*(unsigned long *)SUCC(bp))
#define PREV_FREE_BLKP(bp) ((void *)*(unsigned long *)PRED(bp))其中 PUT_ADDR 用于将一个值赋给一个指针, 这会在更新双向链表的时候使用到. VAL 用于取出当前地址的值(判断一下NULL的话取0). PRED 和 SUCC 分别用于得到两个链表指针的位置
NEXT_FREE_BLKP PREV_FREE_BLKP 则是通过链表指针得到下一个和前一个空闲块的地址
这里需要注意的是, 笔者将 PRED SUCC 指针均看作 8 字节, 也就是 DSIZE 大小, 实际上在 Makefile 中看到编译选项使用了 -m32 作为一个 32 位地址来计算的. 也就是说 PRED SUCC 指针使用 WSIZE 大小是完全没有问题的.
这里是为了考虑 64 位兼容所以做的扩容, 也是考虑到 (void *) 的强制类型转换得到的地址 8 字节应该合理一些
mm_init
整个堆的初始化结构基本没有变化, 唯一修改的位置是 heap_listp = NULL;, 之前 heap_listp 指向整个链表的头部, 显示空闲链表终稿则应该指向 第一个空闲块
int mm_init(void) {
if ((heap_listp = mem_sbrk(4 * WSIZE)) == (void *)-1) {
return -1;
}
PUT(heap_listp, 0);
PUT(heap_listp + (1 * WSIZE), PACK(DSIZE, 1));
PUT(heap_listp + (2 * WSIZE), PACK(DSIZE, 1));
PUT(heap_listp + (3 * WSIZE), PACK(0, 1));
heap_listp = NULL;
if (extend_heap(CHUNKSIZE / WSIZE) == NULL) {
return -1;
}
return 0;
}extend_heap 的部分没有变化, 但是在其中的 coalesce 需要大幅修改. 依然需要考虑 (前)/(后) x (占)/(空) 四种情况, 但是还需要注意(前)/(后) 节点是否为 NULL
因为是一个双向链表, 所以需要同时考虑更新多个节点的指针值, 这里需要额外小心注意, 不然很容易空指针错误. 建议采用下面这种写法, 比较清晰的判断.
if (PREV_FREE_BLKP(next_bp) && NEXT_FREE_BLKP(next_bp)) {
// ...
} else if (!PREV_FREE_BLKP(next_bp) && NEXT_FREE_BLKP(next_bp)) {
// ...
} else if (PREV_FREE_BLKP(next_bp) && !NEXT_FREE_BLKP(next_bp)) {
// ...
} else {
// ...
}修改后的代码如下所示
void *coalesce(void *bp) {
size_t size = GET_SIZE(HDRP(bp));
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
// case 1: 前后都被占用, 加到链表头
if (prev_alloc && next_alloc) {
PUT_ADDR(PRED(bp), 0);
PUT_ADDR(SUCC(bp), heap_listp);
if (NEXT_FREE_BLKP(bp)) {
PUT_ADDR(PRED(NEXT_FREE_BLKP(bp)), bp);
}
heap_listp = bp;
} else if (prev_alloc && !next_alloc) {
// case 2: 前占后不占, 合并后面的块, 修改链表
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
void *next_bp = NEXT_BLKP(bp);
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
// 更新链表
if (PREV_FREE_BLKP(next_bp) && NEXT_FREE_BLKP(next_bp)) {
PUT_ADDR(PRED(bp), PREV_FREE_BLKP(next_bp));
PUT_ADDR(SUCC(bp), NEXT_FREE_BLKP(next_bp));
PUT_ADDR(SUCC(PREV_FREE_BLKP(bp)), bp);
PUT_ADDR(PRED(NEXT_FREE_BLKP(bp)), bp);
} else if (!PREV_FREE_BLKP(next_bp) && NEXT_FREE_BLKP(next_bp)) {
PUT_ADDR(PRED(bp), 0);
heap_listp = bp;
PUT_ADDR(SUCC(bp), NEXT_FREE_BLKP(next_bp));
PUT_ADDR(PRED(NEXT_FREE_BLKP(next_bp)), bp);
} else if (PREV_FREE_BLKP(next_bp) && !NEXT_FREE_BLKP(next_bp)) {
PUT_ADDR(PRED(bp), PREV_FREE_BLKP(next_bp));
PUT_ADDR(SUCC(PREV_FREE_BLKP(next_bp)), bp);
PUT_ADDR(SUCC(bp), 0);
} else {
PUT_ADDR(PRED(bp), 0);
heap_listp = bp;
PUT_ADDR(SUCC(bp), 0);
}
} else if (!prev_alloc && next_alloc) {
// case 3: 前不占后占, 直接合并
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
bp = PREV_BLKP(bp);
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
} else {
// case 4: 前后都空, 合并三个空闲块, 更新第一个块的节点
void *pre_bp = PREV_BLKP(bp);
void *next_bp = NEXT_BLKP(bp);
size += GET_SIZE(HDRP(pre_bp)) + GET_SIZE(FTRP(next_bp));
PUT(HDRP(pre_bp), PACK(size, 0));
PUT(FTRP(pre_bp), PACK(size, 0));
// 更新链表
if (PREV_FREE_BLKP(next_bp) && NEXT_FREE_BLKP(next_bp)) {
PUT_ADDR(SUCC(PREV_FREE_BLKP(next_bp)), VAL(SUCC(next_bp)));
PUT_ADDR(PRED(NEXT_FREE_BLKP(next_bp)), PREV_FREE_BLKP(next_bp));
} else if (PREV_FREE_BLKP(next_bp) && !NEXT_FREE_BLKP(next_bp)) {
PUT_ADDR(SUCC(PREV_FREE_BLKP(next_bp)), 0);
} else if (!PREV_FREE_BLKP(next_bp) && NEXT_FREE_BLKP(next_bp)) {
PUT_ADDR(PRED(NEXT_FREE_BLKP(next_bp)), 0);
heap_listp = NEXT_FREE_BLKP(next_bp);
} else {
// 永远不应该到达这里...
printf("%p\n", heap_listp);
}
}
return bp;
}这里着重介绍一下最后一种, 前空后空的合并方式, 这个问题要比想象中的复杂一些
看起来这个链表应该是下面这样的结构, A/B/C/D 分别代表 PRED SUCC 的出入节点
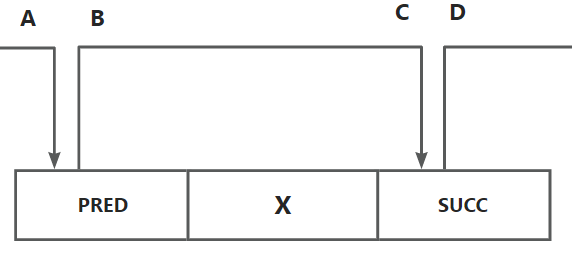
但实际上由于可能存在空闲块插入到链表头部的情况, 所以两个相邻的空闲块并不一定在链表中就是相邻的, 它们之间还可能隔了 N 个块
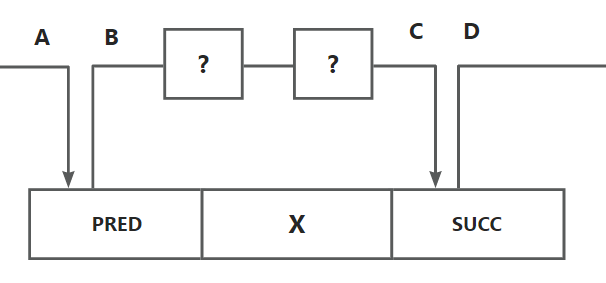
同时由于可能存在插入到头部的情况,所以甚至顺序可能都是反过来的
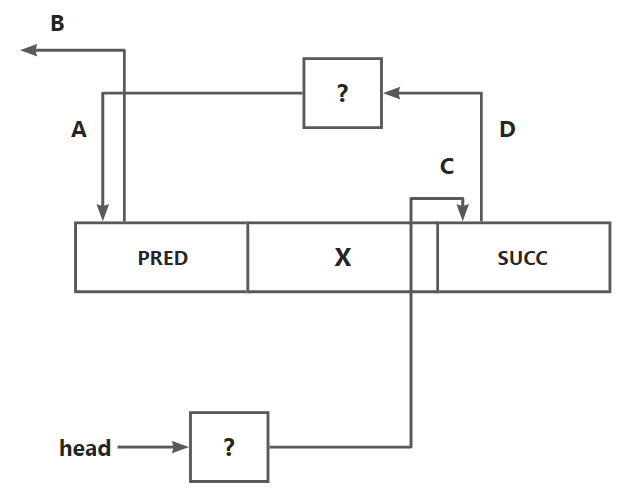
但是不要慌, 情况虽然很多但思路一定要清晰. 合并之后的块一定是 (PERD + x + SUCC), 这个新块(暂且叫Y)的 pred 和 succ 指针一定原先 PRED 块的位置的, 因为块一定是地址小到大的, 所以需要更新的只有 PRED 块的 pred 和 succ. 目前 PRED 块已经有 pred 和 succ 指针使其存在在这个链表当中了, 所以我们需要做的就是更新 SUCC 块及其前后的空闲块节点指针, 具体来说就是 把C指向D
这里的 C 和 D 只是代指, 实际上是说更新 SUCC 块的前后空闲块的 pred 和 succ 指针, 让它们跳过 SUCC 块直接连接起来. 当然需要考虑边界情况
mm_malloc
malloc 代码只有一个小变化, 由于增加了 pred succ 指针, 这两个指针虽然是在 payload 中不占空间, 但是最小块的大小也随之变化
header + footer + pred + succ = WSIZE + WSIZE + DSIZE + DSIZE = 3 * DSIZE
// 小于等于 DSIZE 的大小直接补齐 3*DSIZE
if (size <= DSIZE) {
block_size = 3 * DSIZE;
} else {
// DSIZE 对齐 + 头尾 DSIZE
block_size = (size + DSIZE - 1) / DSIZE * DSIZE + DSIZE;
}需要变化的是其中的 place 和 first_fit
放置块的时候需要更新链表
void place(void *bp, size_t size) {
size_t block_size = GET_SIZE(HDRP(bp));
size_t block_rest_size = block_size - size;
// 剩余块的大小 <= 最小块大小
if (block_rest_size < 3 * DSIZE) {
PUT(HDRP(bp), PACK(block_size, 1));
PUT(FTRP(bp), PACK(block_size, 1));
if (!PREV_FREE_BLKP(bp) && !NEXT_FREE_BLKP(bp)) {
heap_listp = NULL;
} else if (PREV_FREE_BLKP(bp) && !NEXT_FREE_BLKP(bp)) {
PUT_ADDR(SUCC(PREV_FREE_BLKP(bp)), 0);
} else if (!PREV_FREE_BLKP(bp) && NEXT_FREE_BLKP(bp)) {
PUT_ADDR(PRED(NEXT_FREE_BLKP(bp)), 0);
heap_listp = NEXT_FREE_BLKP(bp);
} else {
PUT_ADDR(SUCC(PREV_FREE_BLKP(bp)), NEXT_FREE_BLKP(bp));
PUT_ADDR(PRED(NEXT_FREE_BLKP(bp)), PREV_FREE_BLKP(bp));
}
} else {
// 分裂
PUT(HDRP(bp), PACK(size, 1));
PUT(FTRP(bp), PACK(size, 1));
void *next_bp = NEXT_BLKP(bp);
PUT(HDRP(next_bp), PACK(block_rest_size, 0));
PUT(FTRP(next_bp), PACK(block_rest_size, 0));
// 更新链表
PUT_ADDR(PRED(next_bp), VAL(PRED(bp)));
if (PREV_FREE_BLKP(bp)) {
PUT_ADDR(SUCC(PREV_FREE_BLKP(bp)), next_bp);
} else {
heap_listp = next_bp;
}
PUT_ADDR(SUCC(next_bp), VAL(SUCC(bp)));
if (NEXT_FREE_BLKP(bp)) {
PUT_ADDR(PRED(NEXT_FREE_BLKP(bp)), next_bp);
}
}
}首次适配的时候不再需要判断 alloc, 因为全部都是 free 的块, 只需要判断大小符合即可. 最后一个块的 succ 是 NULL 则说明到结尾了
void *first_fit(size_t size) {
void *bp = heap_listp;
// 没有空闲块
if (bp == NULL) {
return NULL;
}
while (1) {
size_t block_size = GET_SIZE(HDRP(bp));
if (block_size >= size) {
return bp;
} else {
bp = NEXT_FREE_BLKP(bp);
if (bp == NULL) {
return NULL;
}
}
}
}mm_realloc
mm_free 没有变化, 因为修改的部分都在 coalesce 当中, mm_realloc 的变化也比较大, 主要是判断前后边界情况
另外需要注意一点的是对于下一个块就是空闲块, 并且下一个块需要分裂的情况. 应该先记录 pred succ 指针的位置, 最后更新 header 和 footer, 因为如果先更新可能会覆盖原先的 pred 和 succ, 这样就会出现问题
void *mm_realloc(void *ptr, size_t size) {
if (ptr == NULL) {
return mm_malloc(size);
}
if (size == 0) {
mm_free(ptr);
return NULL;
}
if (size <= DSIZE) {
size = 3 * DSIZE;
} else {
size = (size + DSIZE - 1) / DSIZE * DSIZE + DSIZE;
}
size_t block_size = GET_SIZE(HDRP(ptr));
if (size == block_size) {
return ptr;
} else if (size < block_size) {
// 在当前分配块中修改大小
size_t block_rest_size = block_size - size;
// 判断是否分裂
if (block_rest_size >= 3 * DSIZE) {
PUT(HDRP(ptr), PACK(size, 1));
PUT(FTRP(ptr), PACK(size, 1));
void *next_bp = NEXT_BLKP(ptr);
// 多出来的块直接放在链表最前面
PUT(HDRP(next_bp), PACK(block_rest_size, 0));
PUT(FTRP(next_bp), PACK(block_rest_size, 0));
PUT_ADDR(PRED(next_bp), 0);
PUT_ADDR(SUCC(next_bp), heap_listp);
if (NEXT_FREE_BLKP(next_bp)) {
PUT_ADDR(PRED(NEXT_FREE_BLKP(next_bp)), next_bp);
}
heap_listp = next_bp;
}
return ptr;
} else {
if (!GET_ALLOC(HDRP(NEXT_BLKP(ptr))) && (GET_SIZE(HDRP(NEXT_BLKP(ptr))) >= (size - block_size))) {
// 下一个块就有空间
size_t next_block_rest_size = GET_SIZE(HDRP(NEXT_BLKP(ptr))) + block_size - size;
if (next_block_rest_size < 3 * DSIZE) {
void *bp = NEXT_BLKP(ptr);
size_t new_size = GET_SIZE(HDRP(bp)) + block_size;
PUT(HDRP(ptr), PACK(new_size, 1));
PUT(FTRP(ptr), PACK(new_size, 1));
if (!PREV_FREE_BLKP(bp) && !NEXT_FREE_BLKP(bp)) {
heap_listp = NULL;
} else if (PREV_FREE_BLKP(bp) && !NEXT_FREE_BLKP(bp)) {
PUT_ADDR(SUCC(PREV_FREE_BLKP(bp)), 0);
} else if (!PREV_FREE_BLKP(bp) && NEXT_FREE_BLKP(bp)) {
PUT_ADDR(PRED(NEXT_FREE_BLKP(bp)), 0);
heap_listp = NEXT_FREE_BLKP(bp);
} else {
PUT_ADDR(SUCC(PREV_FREE_BLKP(bp)), NEXT_FREE_BLKP(bp));
PUT_ADDR(PRED(NEXT_FREE_BLKP(bp)), PREV_FREE_BLKP(bp));
}
return ptr;
} else {
// 分裂
void *bp = NEXT_BLKP(ptr);
void *new_bp = (char *)ptr + size;
void *pre_bp = PREV_FREE_BLKP(bp);
void *next_bp = NEXT_FREE_BLKP(bp);
if (!pre_bp && !next_bp) {
PUT_ADDR(PRED(new_bp), 0);
PUT_ADDR(SUCC(new_bp), 0);
heap_listp = new_bp;
} else if (pre_bp && !next_bp) {
PUT_ADDR(PRED(new_bp), pre_bp);
PUT_ADDR(SUCC(pre_bp), new_bp);
PUT_ADDR(SUCC(new_bp), 0);
} else if (!pre_bp && next_bp) {
PUT_ADDR(PRED(new_bp), 0);
heap_listp = new_bp;
PUT_ADDR(SUCC(new_bp), next_bp);
PUT_ADDR(PRED(next_bp), new_bp);
} else {
PUT_ADDR(PRED(new_bp), pre_bp);
PUT_ADDR(SUCC(pre_bp), new_bp);
PUT_ADDR(SUCC(new_bp), next_bp);
PUT_ADDR(PRED(next_bp), new_bp);
}
PUT(HDRP(new_bp), PACK(next_block_rest_size, 0));
PUT(FTRP(new_bp), PACK(next_block_rest_size, 0));
PUT(HDRP(ptr), PACK(size, 1));
PUT(FTRP(ptr), PACK(size, 1));
return ptr;
}
} else {
void *bp = mm_malloc(size);
if (bp == NULL) {
return NULL;
}
memcpy(bp, ptr, block_size - DSIZE);
mm_free(ptr);
return bp;
}
}
}实验结果
显式空闲链表就可以达到 90/100 的结果, 说实话有些令我惊讶. 这已经是一个可以令人接收的分数了, 不过既然书中也提到了其他的实现方式, 不妨也动手实现一下
简单分离存储
如果说显式空闲链表的也存在一些不足之处, 那就是所有的空闲链表都链接在一起. 如果合适的空闲块排在很后面, 那么每次寻找都需要依次比较.
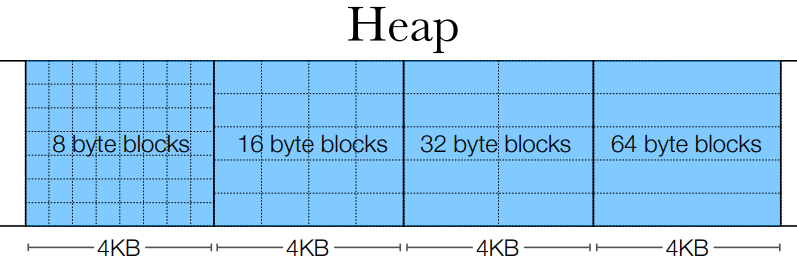
那么显然一种新的思路就是将这些空闲块按照大小分为几类, 也就是用多个空闲链表. 比如可以根据 2 的幂来划分: {1-31}, {32-63}, {64-127}, {128,255}, ...
简单分离存储的思路是: 将每一个 CHUNK 分为等大的块, 比如全是 8/16/32. 这些块不分割, 不合并. 也就是说如果需要分配一个 33 字节大小的空闲, 那么就选择 64 大小的空闲链表, 找到一个空闲块
每一个空闲链表分别对应一类的块, 这样 malloc 寻找空闲块的时候可以先根据需要分配的 size 大小确定应该到哪一个链表中找, 再在这个链表中查询即可
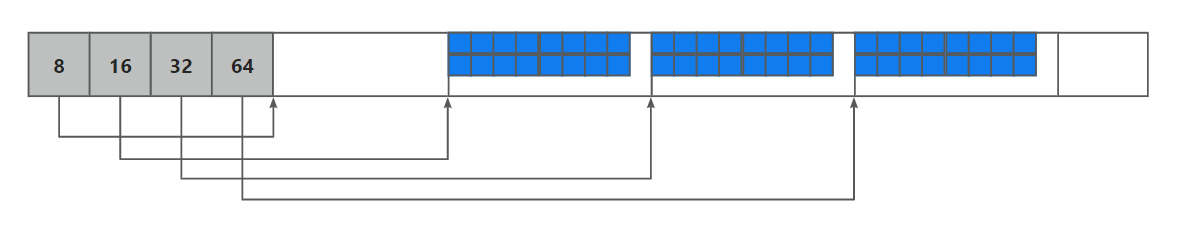
如下所示, 在堆的开头创建一小块数组用于存储分离链表头, 每一个链表指向一块区域, 区域中等大的分割为一个个小块, 单向链表连接

看起来这个思路比较好, 但是实现起来会有很大的问题!
首先书中提到了 "不需要头部和脚部" "由于每一个片中只有相同大小的块, 所以一个已分配的块的大小就可以从它的地址推断出来". 这句话是错的, 实际上当 free 的时候, 对于地址 32 它可能是 5th for 8/ 3rd for 16/ 1st for 32. 对于 0 来说他可能是任意大小的块的开头. 如果不使用其他信息记录不可能判断的出来需要释放的块有多大. 笔者在 stackoverflow 找到了一个相同的问题
这里是笔者对这个问题的解答
总结来说就是书上的说法有问题. 而且不建议读者尝试用这个方法实现, 笔者实现了一下, 使用的是添加头部. 虽然但是即使实现了测试用例也无法通过, realloc 的几个根本过不了, 因为这种方法就没有合并, 前面的 malloc 也可能会因为 out of memory 挂掉
真是一段痛苦的经历, 读者不要尝试用这种方法了, 很不好!
分离适配
这部分实现了好几版, 分别是
- 最初版本 84 分的做法 mm_seg_fit_84.c
- 修改后的 93 分的做法 mm_seg_fit_93.c
- 另一个修改也是 93 分的做法 mm_seg_fit_firstfit.c
分离适配的方法思路也差不多, 不过更加合理的添加了对空闲块的分割和合并. 同样在开头添加一个数组用于存储分离链表头, 不过每一个链表都会指向一个对应的区间块, 比如根据 2 的幂来划分: {1-31}, {32-63}, {64-127}, {128,255}, 那么 0 号链表的所有空闲块都是 1-31 大小的, 2 号链表的所有空闲块都是 32-63 的.
malloc 的时候先根据 size 判断应该到哪一个链表中找, 如果能找到一个合适的块那么直接分配. 如果找不到则到下一个链表中找, 如果都找不到那么扩展堆.
与此同时考虑分割和合并的时候, 只需要把原先的块从对应的链表中删除, 再把合并后的块插入到合并后大小所对应的链表中即可.
下面先来介绍一下最初版本 84 分的做法 mm_seg_fit_84.c
mm_init
初始化的时候只需要添加对于链表数组的初始化
#define MAX_FREELIST_NUMBER 16
for (int i = 0; i < MAX_FREELIST_NUMBER; i++) {
*(unsigned long *)((char *)free_listp + DSIZE * i) = 0;
}合并的时候有较大的修改
void *coalesce(void *bp) {
size_t size = GET_SIZE(HDRP(bp));
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
// case 1: 前后都被占用, 加到链表头
if (prev_alloc && next_alloc) {
insert(bp);
} else if (prev_alloc && !next_alloc) {
// case 2: 前占后不占, 合并后面的块, 修改链表
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
void *next_bp = NEXT_BLKP(bp);
delete (next_bp);
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
// 更新链表
insert(bp);
} else if (!prev_alloc && next_alloc) {
// case 3: 前不占后占, 直接合并
delete (PREV_BLKP(bp));
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
bp = PREV_BLKP(bp);
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
insert(bp);
} else {
// case 4: 前后都空, 合并三个空闲块, 更新第一个块的节点
void *pre_bp = PREV_BLKP(bp);
void *next_bp = NEXT_BLKP(bp);
delete (pre_bp);
delete (next_bp);
size += GET_SIZE(HDRP(pre_bp)) + GET_SIZE(FTRP(next_bp));
PUT(HDRP(pre_bp), PACK(size, 0));
PUT(FTRP(pre_bp), PACK(size, 0));
// 更新链表
insert(pre_bp);
bp = pre_bp;
}
return bp;
}相比之前代码有了很大程度的精简, 其中函数 insert 和 delete 分别用于插入和删除
void delete (void *bp) {
void *free_listp_i = get_freelist_index(GET_SIZE(HDRP(bp)));
void *pre_bp = PREV_FREE_BLKP(bp);
void *next_bp = NEXT_FREE_BLKP(bp);
if (pre_bp && next_bp) {
PUT_ADDR(SUCC(pre_bp), next_bp);
PUT_ADDR(PRED(next_bp), pre_bp);
} else if (!pre_bp && next_bp) {
PUT_ADDR(PRED(next_bp), 0);
PUT_ADDR(free_listp_i, next_bp);
} else if (pre_bp && !next_bp) {
PUT_ADDR(SUCC(pre_bp), 0);
} else {
PUT_ADDR(free_listp_i, 0);
}
}
void insert(void *bp) {
void *free_listp_i = get_freelist_index(GET_SIZE(HDRP(bp)));
PUT_ADDR(PRED(bp), 0);
PUT_ADDR(SUCC(bp), VAL(free_listp_i));
if (NEXT_FREE_BLKP(bp)) {
PUT_ADDR(PRED(NEXT_FREE_BLKP(bp)), bp);
}
PUT_ADDR(free_listp_i, bp);
}函数 get_freelist_index 的作用就是根据这个块找到对应的链表, 对于超大块的统一放在最后一个链表中
void *get_freelist_index(size_t size) {
size--;
int index = -5;
while (size) {
size = size >> 1;
index++;
}
if (index > MAX_FREELIST_NUMBER - 1) {
index = MAX_FREELIST_NUMBER - 1;
}
return (void *)((char *)free_listp + index * DSIZE);
}mm_malloc
mm_malloc 函数主体没有改动, 其中的 place 函数有了变化
void place(void *bp, size_t size) {
size_t block_size = GET_SIZE(HDRP(bp));
size_t block_rest_size = block_size - size;
// 剩余块的大小 <= 最小块大小
if (block_rest_size < 3 * DSIZE) {
PUT(HDRP(bp), PACK(block_size, 1));
PUT(FTRP(bp), PACK(block_size, 1));
delete (bp);
} else {
// 分裂
delete (bp);
PUT(HDRP(bp), PACK(size, 1));
PUT(FTRP(bp), PACK(size, 1));
void *next_bp = NEXT_BLKP(bp);
PUT(HDRP(next_bp), PACK(block_rest_size, 0));
PUT(FTRP(next_bp), PACK(block_rest_size, 0));
// 更新链表
insert(next_bp);
}
}以及首次适配算法有了很大改动, 先找到对应的 list, 如果当前list不满足则继续向后找, 都找不到扩展
void *first_fit(size_t size) {
size_t origin_size = size;
size--;
int index = -5;
while (size) {
size = size >> 1;
index++;
}
if (index > MAX_FREELIST_NUMBER - 1) {
index = MAX_FREELIST_NUMBER - 1;
}
while (index < MAX_FREELIST_NUMBER) {
void *free_listp_i = (void *)((char *)free_listp + index * DSIZE);
if (VAL(free_listp_i) == 0) {
index++;
} else {
void *bp = (void *)VAL(free_listp_i);
while (GET_SIZE(HDRP(bp)) < origin_size) {
bp = NEXT_FREE_BLKP(bp);
if (bp == NULL) {
break;
}
}
if (bp) {
return bp;
}
index++;
}
}
return NULL;
}realloc 有变化, 不过也差不多, free 没有变化
这个方法测试下来只有 84 分, 令我有点奇怪. 看了下最后的 realloc 的 util 利用率很低. 感觉是我代码写错了, 但是真找不到哪里有问题了...
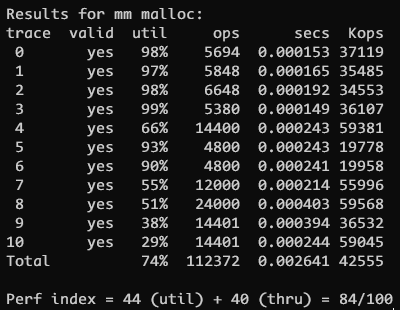
后来根据一位大佬的实现, 发现只需要在 place 中额外判断一下, 如果 size >= 96 那么直接反过来, 把分配的块放到最后面
void *place(void *bp, size_t size) {
size_t block_size = GET_SIZE(HDRP(bp));
size_t block_rest_size = block_size - size;
// 剩余块的大小 <= 最小块大小
if (block_rest_size < 3 * DSIZE) {
PUT(HDRP(bp), PACK(block_size, 1));
PUT(FTRP(bp), PACK(block_size, 1));
delete (bp);
} else if (size >= 96) {
delete (bp);
PUT(HDRP(bp), PACK(block_rest_size, 0));
PUT(FTRP(bp), PACK(block_rest_size, 0));
insert(bp);
PUT(HDRP(NEXT_BLKP(bp)), PACK(size, 1));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 1));
bp = NEXT_BLKP(bp);
} else {
// 分裂
delete (bp);
PUT(HDRP(bp), PACK(size, 1));
PUT(FTRP(bp), PACK(size, 1));
void *next_bp = NEXT_BLKP(bp);
PUT(HDRP(next_bp), PACK(block_rest_size, 0));
PUT(FTRP(next_bp), PACK(block_rest_size, 0));
// 更新链表
insert(next_bp);
}
return bp;
}效果居然惊人的提到 93 分!
修改后的 93 分的做法 mm_seg_fit_93.c
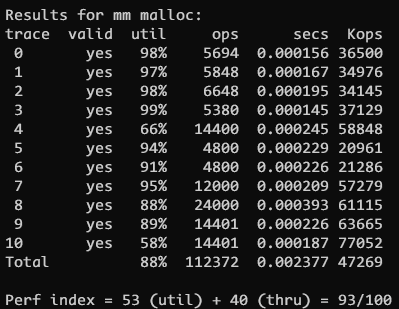
最后又参考了另一个大佬的题解, 考虑修改 first_fit 的算法, 也就是在插入的时候按块大小排序, 然后这样 first_fit 的时候只需要判断第一个块是否满足即可
void insert(void *bp) {
void *free_listp_i = get_freelist_index(GET_SIZE(HDRP(bp)));
void *curr_bp = (void *)VAL(free_listp_i);
if (curr_bp == NULL) {
PUT_ADDR(PRED(bp), 0);
PUT_ADDR(SUCC(bp), 0);
PUT_ADDR(free_listp_i, bp);
} else {
if (GET_SIZE(HDRP(curr_bp)) <= GET_SIZE(HDRP(bp))) {
PUT_ADDR(PRED(bp), 0);
PUT_ADDR(SUCC(bp), curr_bp);
PUT_ADDR(free_listp_i, bp);
PUT_ADDR(PRED(curr_bp), bp);
} else {
void *pred_bp = curr_bp;
curr_bp = NEXT_FREE_BLKP(curr_bp);
while (curr_bp && GET_SIZE(HDRP(curr_bp)) > GET_SIZE(HDRP(bp))) {
pred_bp = curr_bp;
curr_bp = NEXT_FREE_BLKP(curr_bp);
}
if (curr_bp == NULL) {
PUT_ADDR(SUCC(pred_bp), bp);
PUT_ADDR(PRED(bp), pred_bp);
PUT_ADDR(SUCC(bp), 0);
} else {
PUT_ADDR(SUCC(pred_bp), bp);
PUT_ADDR(PRED(bp), pred_bp);
PUT_ADDR(PRED(curr_bp), bp);
PUT_ADDR(SUCC(bp), curr_bp);
}
}
}
}void *first_fit(size_t size) {
size_t origin_size = size;
size--;
int index = -5;
while (size) {
size = size >> 1;
index++;
}
if (index > MAX_FREELIST_NUMBER - 1) {
index = MAX_FREELIST_NUMBER - 1;
}
while (index < MAX_FREELIST_NUMBER) {
void *free_listp_i = (void *)((char *)free_listp + index * DSIZE);
if (VAL(free_listp_i) == 0) {
index++;
} else {
if (GET_SIZE(HDRP(VAL(free_listp_i))) < origin_size) {
index++;
} else {
return (void*)VAL(free_listp_i);
}
}
}
return NULL;
}这种做法也是 93 分没有变化
也是 93 分的做法 mm_seg_fit_firstfit.c