Implementation of Precise Interrupts in Pipelined Processors
论文基本情况
acm dl 1985 SIGARCH
整体读下来还是一篇不错的论文(就是不太好读), 讲了 5 种处理精确中断的方法. 一开始我以为 1985 年的时候还没有流水线的设计, 所以作者没有把 EX MEM WB 分开, 结果看到最后发现在 8.4 Linear Pipeline Structures 的讨论中提到了流水线的实现, 前文只是在一个简单的处理器架构(PC register mem) 上探讨精确保存进程状态的实现方法
时至今日这一过程由硬件和操作系统内核共同承担(硬 + 软), 内核在中断发出时也会保存 process context, 具体的处理器架构应该也有对应的保存手段.
摘要(Abstract)
因为流水线处理器的指令会被预先执行,所以主要解决的问题是中如何精确处理中断
在并行流水线的前提下, 提出了五种解决措施,第一种强制指令按照架构顺序完成和修改进程状态, 其余四种允许指令以任何顺序完成, 但需要使用额外的硬件在中断发生的时候可以恢复状态.
除方案一性能下降 16%,其余方案性能相似,损失不大
研究动机(Motivation/Introduction)
进程状态包括:PC,寄存器,内存.当中断发生时需要软件/硬件/软件+硬件协同处理来保存信息
当发生中断的时候, 需要保证
- 已保存的 PC 之前的所有指令均已执行并已正确修改进程状态
- 已保存的 PC 之后未执行且未修改
- 如果中断是由程序中的指令引发的异常条件引起的,那么取决于处理器架构和具体的中断原因,中断要么已经完成要么尚未开始执行,不存在中间指令状态
在流水线架构当中指令并不会一条一条的完整顺次执行, 因此需要保证发生中断的时候上下文的进程状态是精确的. 这需要额外的硬件设备来储存和恢复进程状态.
历史调查(History Survey)
中断分两种类型:
- 程序内中断, 例如非法指令,除零,溢出,页错误
- 外部中断,比如定时器到达或者IO中断信号
在许多情况下,精确中断是必要的
- 对于 IO中断 & 定时器时钟 这样一些中断, 由于我们假设中断信号之后的指令不会执行, 因此中断处理结束后只需要从中断处继续执行指令即可, 对于恢复程序来说很方便
- 调试任务中需要依靠异常中断来精确分割指令和控制流程
- 算术异常,算术异常有很多种,比如除零,溢出,下溢,不合法操作,数据类型不匹配等等.除了需要各个处理器设计遵循 IEEE 标准(目前来说应该是 IEEE754 浮点规范),更多的应该是在软件层面处理,具体来说是编程语言和应用程序逻辑,比如异常检查,条件检查,类型检查,数据范围检查等等
- 当虚拟内存的地址映射出现页错误的时候需要由操作系统重新查找页表然后把对应的页面置换进内存,然后继续进程执行
- 系统软件模拟器可以扩展指令集来实现原体系结构未支持的操作码,识别未知操作码后利用中断信号传递给模拟器实现对应功能,这样可以在保持体系结构兼容性的基础上提高扩展性
- 当虚拟机中的操作系统试图执行一些需要特殊权限或特权的指令,但出现了错误,导致了一个中断(也就是操作系统的执行被中止),那么此时主机软件(即虚拟机管理程序)可以模拟虚拟机中特权指令的行为以便虚拟机的继续执行,不会中断用户体验
最开始 IBM 360/91 的中断不精确, 后续的 IBM 360 和 370 实现都使用了不太激进的流水线设计,指令以严格的程序顺序修改进程状态, 实现了精确中断. 后续的一些机器为了最大程度的并行性和设计简单性,牺牲了精确中断的优点(比如 CDC 6600/7600), 再后来的CDC STAR-100也支持了虚拟内存, 采用了一种叫做 invisible exchange package 的方法实现. 后续的 CYBER 180/990 都采用了 history buffer 的方式使用此"历史"信息将系统恢复到精确的状态. 这也是本文中 history buffer 的方法原型.
解决方案(Solution)
基本指令集表示方式:
- LOAD: Ri = (Rj + disp)
- STORE: (Rj + disp) = Ri
- 算术指令: Ri = Rj op Rk
- 一元算术指令: Ri = op Rk
- 条件指令: P = disp: Ri op Rj
最后的条件指令表示写法不够好,个人感觉应该写为 P = Ri op Rj ? disp : pc + x 这种条件表达式的方式比较好
一些异常情况可以在指令发出之前就被检测到,比如特权指令错误/非法指令码,外部异常等. 如果检测到这些异常则在下一条指令发出之前优先处理错误,处理结束之后再继续执行,这样就可以确保精确的中断状态了. 由于如上所述可以轻松处理指令之前检测到的异常情况,因此我们将不再进一步考虑它们.下面的讨论不考虑 cache, 不考虑条件转移指令
基础架构设计
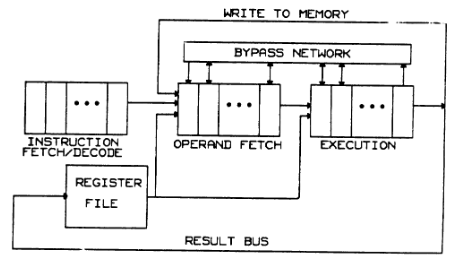
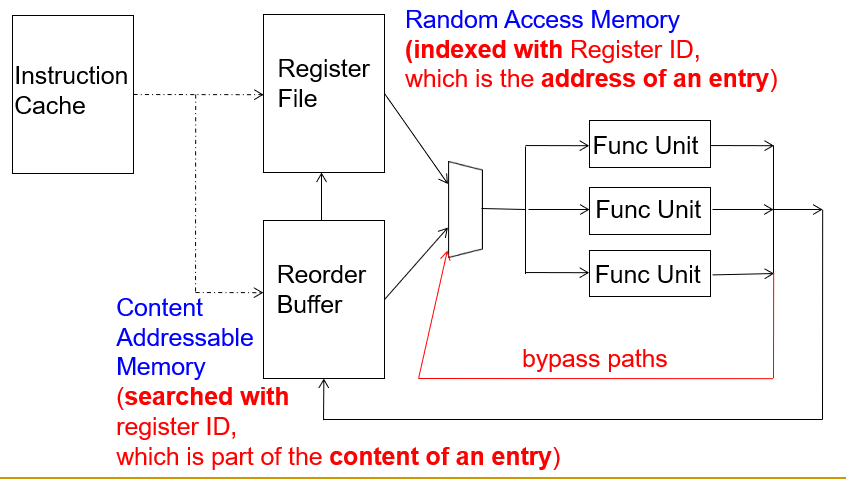
基础架构如下所示, 其中 FUNCTION UNIT 是一组可以同时执行的功能单元模块, 在指令解码之后将数据发送(issue)到功能单元模块, 最后再将执行结果写回到寄存器 REGISTER FILE 当中.
FUNCTION UNIT1/2 和 MEMORY ACCESS 是并列的多个运算单元,他们会同时接收到信号.信号发射之前需要检查寄存器是否上锁
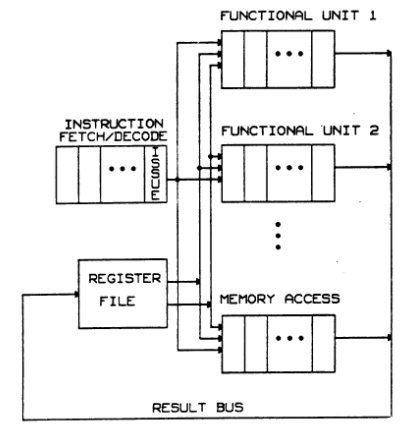
但是笔者认为这张图画的有一点歧义, decode 之后 issue 部分得到的是操作数和寄存器序号,操作数寄存器在指令发出时才会被读取, 所以ISSUE也应该有连线到REGISTER FILE. 所以实际上的结构应该如下图所示
汇编指令示例
0: R2 <- 0
1: R0 <- 0
2: R5 <- 1
3: R7 <- 100
4: R1 <- (R2 + A) # LOAD A(1) 11cp
5: R3 <- (R2 + B) # LOAD B(1) 11cp
6: R4 <- R1 + fR3 # Float add 6cp
7: R0 <- R0 + R5 # Inc 2cp
8: (R0 + C) <- R4
9: R2 <- R2 + R56 行是一个浮点数加法,需要11个时钟周期计算. 7 行是一个整数加法,需要2个时钟周期进行计算. 因此虽然 7 行指令会在 6 行之后发出,但是会在 6 之前执行完毕,因此如果 6 行浮点数加法存在溢出的异常中断,那么此时 R0 的值就是一个不正确的结果
对于不同类型的计算会交由不同的处理单元, 但是整数加法, 和浮点数除法, 它们的处理所需时间相差了很多个时钟周期
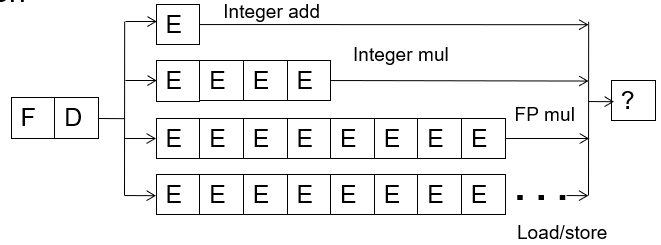
因此如下图所示, 2/3/4/6/7 后续的指令的 W 写回时刻要前于前面的指令, 在第一条指令更新寄存器之前后续的指令以无序的方式提前更新了架构状态, 这与冯诺依曼体系中指令执行的顺序语义相违背
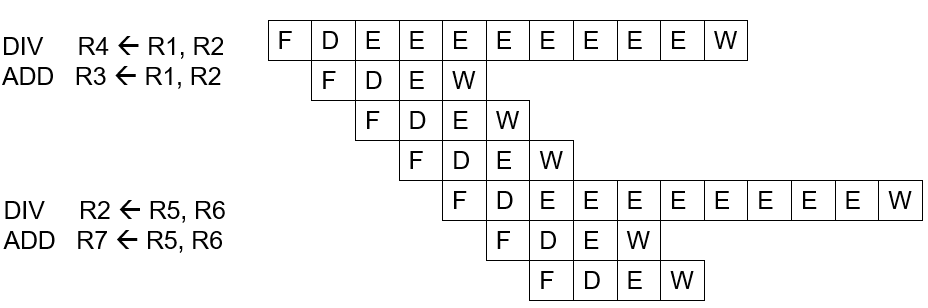
要么暂停流水线, 限制处理器只能顺序执行, 每条指令完整执行结束确保处于进程状态稳定后在发射下一条指令
但我们考虑的是流水线式的处理器模式, 所以需要改进该处理器架构, 添加一些功能部件已实现精确中断, 下面介绍 4 种解决方案
方案一: In-order
添加一个 result shift register (后文简称 RSR), 计算结果先写入 RSR 后再更新 REGISTER FILE.
指令逐条发射, 发射后将信息保存到 RSR 中. 指令的时钟周期对应应当在 RSR 中的表项(stage/entry), 每个时钟周期,控制信息向第一级下移一级.当它到达第一阶段时,它在下一个时钟期间用于控制结果总线,以便将功能单元结果放置在正确的结果寄存器中.
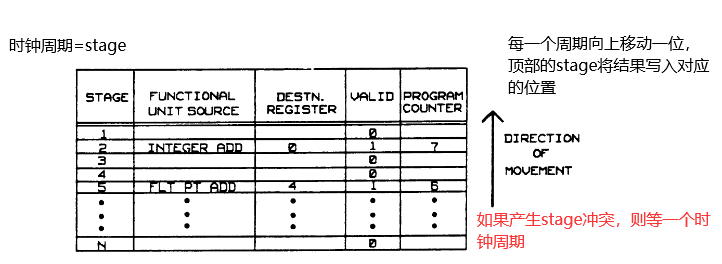
RSR 长度必须与最长的流水线级一样长
用上文的例子来说, 在导入 7 行 inc 指令之前需要检查一下是否存在 i < j && stage(i) > stage(j) ,如果存在那么此时 j 指令在 i 指令之后开始执行但在 i 之前执行结束,那么此时不导入 j 指令而是使用一条 null 指令,等待 5 个周期之后 float add 指令进入stage1,此时才可以加载 integer add 指令
换句话说,i 指令加载前需要检查 1-stage(i) 都没有被预定;加载后预定所有 1-stage(i)-1 阶段.
对于寄存器来说这样可以实现精确的进程状态保存, 但对于内存来说需要确保正确写入的对应的值, 因此需要保证存储指令在发出之前等待 RSR 为空, 即没有发生中断的可能. 可以在 RSR 中添加一个 dummy store 用于记录内存的读写操作,只有当 RSR 中全空才能说明没有异常情况,才能写内存.
对于 PC 来说发生中断时也只需要找到 RSR 表项中最靠前的一条指令的 PC 地址即可
缺点: 短周期的指令即使它们没有依赖性也可能会被阻塞, 因为需要等待 RSR 中前面的长周期指令(比如 float add)完整处理结束后才能继续
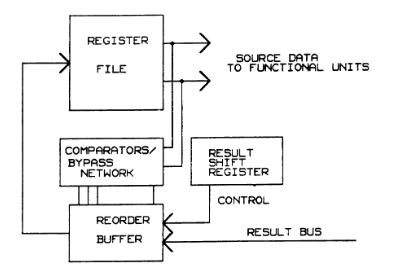
方案二: Reorder Buffer
ROB 增加了一个 reorder buffer(下文简称RD/重排缓冲区)
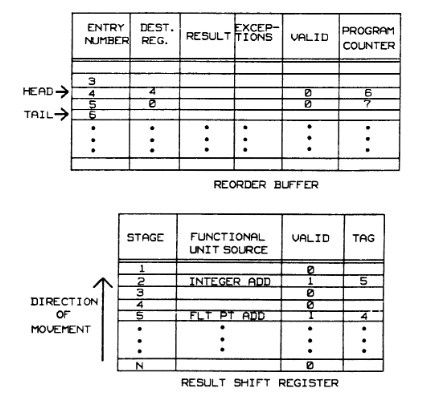
论文里解释的复杂了. 就是添加了一个重排缓冲区,HEAD-TAIL之间是缓冲区,HEAD记录正在执行的最后一条指令,TAIL记录下一条应该发射的指令
使用循环队列是因为硬件实现上的需要
当执行 float add(6) 时 HEAD = 6, TAIL = 7, 然后执行 integer add(7) ,此时 HEAD = 6, TAIL = 8,之后两个周期 7 执行结束,对于寄存器修改的执行结果由 RSR 发送到 RB, 但由于 7 位于缓冲区内, 需要等待 6 执行结束后, HEAD 指针后移, 才可以把对应的结果写入
对于主存的精确进程状态的处理还提到了交由内存管道管理,似乎还需要单独连线过去,感觉也没这个必要
重排缓冲区会因为等待一条长流水线指令而卡住指令执行, 因此条目数很少,与此同时 RSR 中条目数约等于最大流水线长度,RD 中才是卡住的的 PC 指针的位置, 当异常到达时直接返回 RD 首 PC 即可
与此同时 bypass 的方法也被考虑到了,可以将buffer中无关数据量提前送到后续指令处进行计算,而无需等待, 但是需要注意多重旁路的寄存器目的地址检查,以及旁路/多重旁路的具体电路实现.
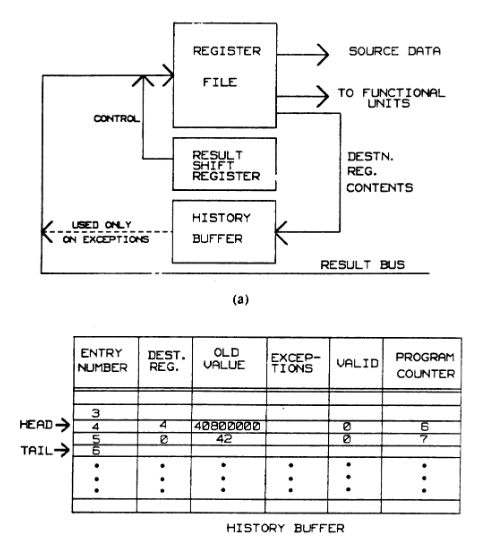
方案三: History Buffer
历史缓冲区的设计就是使用了更大的硬件电路, 在写寄存器之前额外记录原先寄存器的值,因此需要三个读端口(两个原先的 Ri Rj 以及读取 Rd 的值)
此时当中断发生时,从 TAIL -> HEAD 顺次从 Buffer 中将原数据更新写回寄存器,恢复初始状态.(有点类似数据库的回滚)
对于内存和PC的处理与前文相同
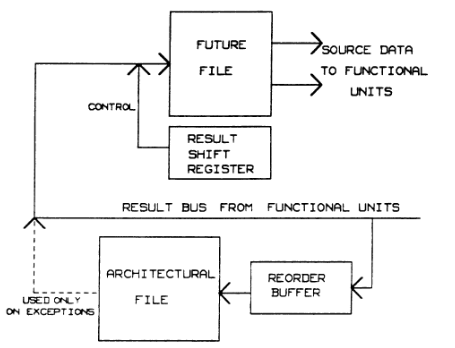
方案四: Future File
思路很清晰,双份寄存器,一份 future 不考虑顺序,一份采用 reorder 的方式用于保存精确状态.
出现异常的时候使用 reorder buffer 保存的数据以及恢复方式
实验结果
在 CRAY-1S 做的模拟测试, 测试传统标量架构的流水线实现
测试结果分三组
- In-order
- reorder buffer
- history buffer / future file
因为第三组中的方法会产生相同的系统性能. History buffer 和 future file 的实现中都嵌入了 reorder buffer. reorder buffer 的表项数量是自变量, 测试指标是相对原 CRAY-1S(1.0) 的性能比, 越接近 1.0 越好. 结果如下所示
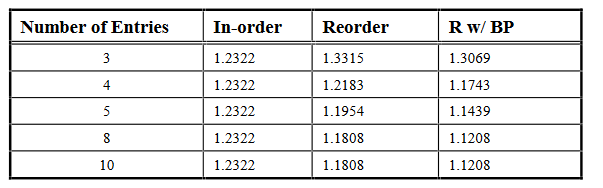
- In-order 列的模拟结果是恒定的,因为此方法不依赖于对指令重新排序的缓冲区.对于所有方法,都会出现一些性能下降.
- 当重新排序缓冲区较小时,按顺序方法产生的性能下降最少.小型重排序缓冲区(少于 3 个条目)限制了可以同时处于某个执行阶段的指令数量.一旦重新排序缓冲区大小增加到超过 3 个条目就会产生更好的性能.
- 与简单的重新排序缓冲区相比,具有旁路的重新排序缓冲区提供了卓越的性能.当缓冲区大小增加到超过 10 个条目时,模拟结果表明性能没有进一步提高.
- 对于简单的重新排序缓冲区,缓冲区必须至少有 5 个条目,才能获得比 In-order 方法更好的性能, 并且重新排序缓冲区中的条目超过 8 个也不会再提高性能. 然而,具有旁路的重排序缓冲区只需要 4 个条目就可以达到同样的性能结果.
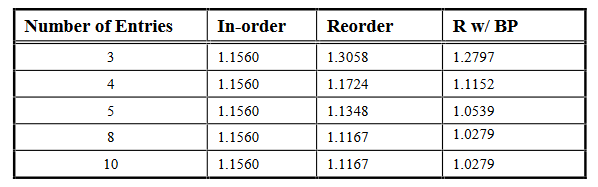
表 2 显示了使用内存管道处理内存的写操作的测试结果
- 内存管道方法有明显的改进.如果与具有旁路的 8 条目重排序缓冲区一起使用,则性能仅下降 3%.
- 性能下降和实施方法的成本之间存在权衡.按顺序方法可以与第一种方法结合起来, 这种方式基本上不需要成本, 但选择这种"廉价"方法会导致性能下降 23%.
- 如果无法接受性能的大幅下降,则必须将第二种存储方法与in-order方法一起使用,或者必须使用更复杂的方法之一.如果使用重新排序缓冲区方法,则必须使用至少有 3 或 4 个条目的缓冲区.
结论
介绍了五种解决实现精确中断下进程状态保存的措施, 在一个简单的处理器架构上讨论. 最后在一个处理器上做了一些测试, 得出来的一些包括缓冲区条目选择(>=3), bypass 的使用, 等等的结论. 最后说明除了性能, 硬件的价格和设计成本也是重要的考量因素.
自己的思考
前面基本在介绍几种方案, 最后又做了一些关于虚拟内存, cache, pipeline 方面的扩展我觉得值得一谈. 其中比较有趣的是对于 cache 的讨论. 提到了两种 Store-through Caches(存储直通缓存) 和 Write-Back Cache(写回缓存) 缓存种类.
- 对于存储直通缓存来说, 因为主存储器始终处于精确状态,但 cache 内容可能"领先于"精确状态. 因此如果在高速缓存可能处于这种状态时发生中断,则应强制刷新高速缓存.这才可以保证不会使用过早更新的缓存位置.然而这可能会导致性能问题,尤其是对于较大的缓存.
另一种选择是以类似于寄存器文件的方式处理高速缓存.例如,可以为缓存保留一个历史缓冲区.就像寄存器一样,必须在写入新值之前读取缓存位置.这并不一定意味着性能损失,因为必须在写入周期之前检查缓存是否命中.在许多高性能缓存组织中,历史数据的读取周期可以与命中检查并行完成.每个存储指令都会创建一个缓冲区条目,指示它已写入的高速缓存位置.缓冲区条目可用于恢复缓存组.当指令无异常地完成时,缓冲区条目将被丢弃.
这种思路很巧妙, 虽然可行性性有待商榷
- 对于回写式缓存可能是与实现精确中断最兼容的缓存类型.这是因为回写式高速缓存中的存储不是直接存储到内存中的.更新缓存和更新主内存之间存在内置延迟.
但是需要注意的是在执行实际的写回操作之前,应该清空重新排序缓冲区或者应该检查属于正在写回的行的数据.如果找到此类数据,则写回必须等待数据进入缓存.
如果使用历史缓冲区,则必须将高速缓存行保存在历史缓冲区中,或者回写必须等到相关指令到达缓冲区末尾为止.写回有时必须等到达到精确状态.
最后作者还讨论了关于流水线多阶段的处理方式, 这和现如今的流水线设计已经很接近了, 很有意思