superscale

speculation(前瞻) 指乱序执行, 顺序确认
运行结果
jupyter 提交版见 main.ipynb
运行分为两部分, 首先是对于 PPT 中示例程序的模拟执行
python src/homework7/main.pyDADDIU 是 MIPS 指令集中的无符号双字加立即数, 这里修改为 ADD, 完整输出见 example.txt
指令执行流程
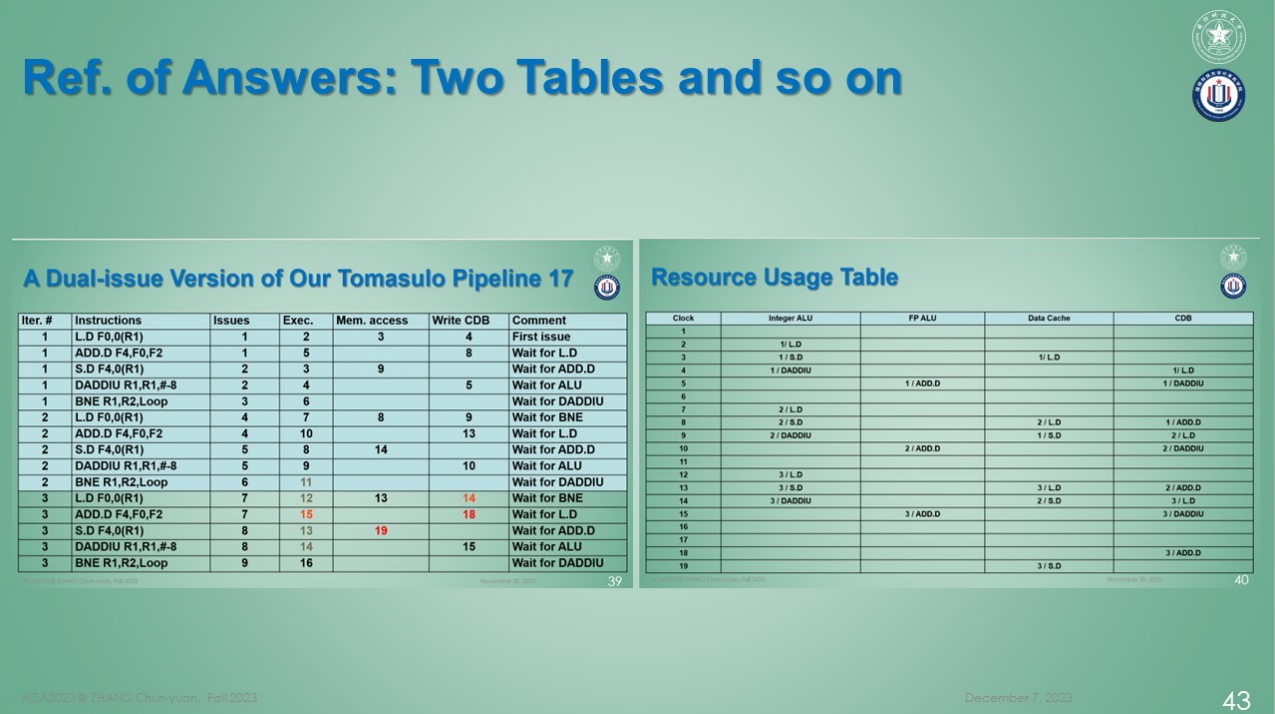
CLOCK 23
[instruction status]
ID Instructions | Issue Exec Mem Write Confi | Qj Qk stage
0 LOAD F0 0 R1 | 1 2 3 4 5 | COMPLETE
1 FADD F4 F0 F2 | 1 5 8 9 | COMPLETE
2 STORE F4 0 R1 | 2 3 9 11 | COMPLETE
3 ADD R1 -8 R1 | 2 4 5 12 | COMPLETE
4 BNE Loop R1 R2 | 3 6 13 | COMPLETE
5 LOAD F0 0 R1 | 4 7 8 9 14 | COMPLETE
6 FADD F4 F0 F2 | 4 10 13 15 | COMPLETE
7 STORE F4 0 R1 | 5 8 14 16 | COMPLETE
8 ADD R1 -8 R1 | 5 9 10 17 | COMPLETE
9 BNE Loop R1 R2 | 6 11 18 | COMPLETE
10 LOAD F0 0 R1 | 7 12 13 14 19 | COMPLETE
11 FADD F4 F0 F2 | 7 15 18 20 | COMPLETE
12 STORE F4 0 R1 | 8 13 19 21 | COMPLETE
13 ADD R1 -8 R1 | 8 14 15 22 | COMPLETE
14 BNE Loop R1 R2 | 9 16 23 | COMPLETE
[unit]
Name Func | status id
Integer ALU Add | Free 14
FP ALU Fadd | Free 11统计信息
CLOCK | Integer ALU | FP ALU | Data Cache | CDB
1 | | | |
2 | 0/Load | | |
3 | 2/Store | | 0/Load |
4 | 3/Add | | | 0/Load
5 | | 1/Fadd | | 3/Add
6 | 4/Bne | | |
7 | 5/Load | | |
8 | 7/Store | | 5/Load | 1/Fadd
9 | 8/Add | | 2/Store | 5/Load
10 | | 6/Fadd | | 8/Add
11 | 9/Bne | | |
12 | 10/Load | | |
13 | 12/Store | | 10/Load | 6/Fadd
14 | 13/Add | | 7/Store | 10/Load
15 | | 11/Fadd | | 13/Add
16 | 14/Bne | | |
17 | | | |
18 | | | | 11/Fadd
19 | | | 12/Store |
20 | | | |
21 | | | |
22 | | | |这里值得一提的是老师 PPT 表格当中并没有给出 BNE 指令, 笔者认为该指令执行也需要使用 Integer ALU 来进行计算以判断跳转条件是否成立, PPT 表格有问题
然后是本次作业要求的程序
python src/homework7/hw.py完整输出见 output.txt
指令执行流程
CLOCK 23
[instruction status]
ID Instructions | Issue Exec Mem Write Confi | Qj Qk stage
0 LOAD F0 0 R1 | 1 2 3 4 5 | COMPLETE
1 FADD F4 F0 F2 | 1 5 8 9 | COMPLETE
2 STORE F4 0 R1 | 2 3 9 11 | COMPLETE
3 ADD R1 -8 R1 | 2 3 4 12 | COMPLETE
4 BNE Loop R1 R2 | 3 5 13 | COMPLETE
5 LOAD F0 0 R1 | 4 5 6 7 14 | COMPLETE
6 FADD F4 F0 F2 | 4 8 11 15 | COMPLETE
7 STORE F4 0 R1 | 5 6 12 16 | COMPLETE
8 ADD R1 -8 R1 | 5 6 7 17 | COMPLETE
9 BNE Loop R1 R2 | 6 8 18 | COMPLETE
10 LOAD F0 0 R1 | 7 8 9 10 19 | COMPLETE
11 FADD F4 F0 F2 | 7 11 14 20 | COMPLETE
12 STORE F4 0 R1 | 8 9 15 21 | COMPLETE
13 ADD R1 -8 R1 | 8 9 10 22 | COMPLETE
14 BNE Loop R1 R2 | 9 11 23 | COMPLETE
[unit]
Name Func | status id
Integer ALU Add | Free 14
FP ALU Fadd | Free 11
Address ALU Integer | Free 12统计信息
CLOCK | Integer ALU | FP ALU | Address ALU | Data Cache | CDB
1 | | | | |
2 | | | 0/Load | |
3 | 3/Add | | 2/Store | 0/Load |
4 | | | | | 0/Load 3/Add
5 | 4/Bne | 1/Fadd | 5/Load | |
6 | 8/Add | | 7/Store | 5/Load |
7 | | | | | 5/Load 8/Add
8 | 9/Bne | 6/Fadd | 10/Load | | 1/Fadd
9 | 13/Add | | 12/Store | 2/Store 10/Load |
10 | | | | | 10/Load 13/Add
11 | 14/Bne | 11/Fadd | | | 6/Fadd
12 | | | | 7/Store |
13 | | | | |
14 | | | | | 11/Fadd
15 | | | | 12/Store |
16 | | | | |
17 | | | | |
18 | | | | |
19 | | | | |
20 | | | | |
21 | | | | |
22 | | | | |实验报告
所谓"超标量"是指 CPU 在一个时钟周期内获取/执行和提交多条指令,这个概念和"标量"对应,"标量"指 CPU 在一个时钟周期内获取/执行和提交一条指令;
"乱序"和"顺序"对应,"顺序"的意思是"顺序发射/顺序执行",是指 CPU 按照指令原始顺序逐条发射/逐条执行,而"乱序"就是指"乱序发射/乱序执行"."超标量"一般和"乱序"搭配,"标量"一般和"顺序"搭配,前两者是现代高速微处理器所广泛使用的技术.
运用这两种技术的"超标量乱序处理器"可以在每个时钟周期获取多条指令,并在内部并行地一次性乱序执行多条指令.这种特性提高了 CPU 的指令吞吐率,加快了程序的执行速度,让包括程序员和用户在内的每个人都从中获益.
实验分析
题目要求有点晦涩, 翻译一下就是
- 双发射处理器, 三次循环执行, 统计资源利用率
- 原先的单 ALU 部件现在变为两个, 一个用于地址计算, 一个用于执行 ALU 操作
- 两条 CDB 总线, 支持同时两条指令的写回 和 数据旁路
- 前瞻执行, 乱序执行, 顺序确认
以及一些假设
- 整数指令执行 ALU 需要 1 个周期
- 浮点数加法 FP.ADD 需要三个周期执行
- load/store 指令执行和访存各需要一个周期, 共需要两个周期
- 不需要访存的指令可以直接跳过访存阶段
- 分支预测是完美的, 分支指令单发射
代码实现
本次作业的代码可以说相当难写, 主要原因是指令不再独占 Unit, 使用完即释放, 这使得后续更新解决 RAW 数据冒险的问题变得复杂.
整体而言代码结构是基于之前的类设计, 但内部做了一些改变
新增了一个 CDB 类, 用于控制多条指令同时写回, 每次指令想要写回是都会先检查 available, 如果还有空闲 CDB 则 send_data, 否则等待下一周期的 CDB 写回, 每一周期结束后调用 finish_write_back 完成 CDB 的数据清除
class CDB:
def __init__(self, number=2) -> None:
self.number = number
self.available: bool = True
self.left_available_cdb = self.number
def send_data(self):
assert self.available
self.left_available_cdb -= 1
if self.left_available_cdb == 0:
self.available = False
def finish_write_back(self):
self.left_available_cdb = self.number
self.available = TrueUnitState 有了很大程度的简化. Qj Qk 表示当出现冲突的时候应该向哪个指令要数据, 因为指令执行完毕后会释放占用的 Unit, 因此 Q 表示当前指令的 J K 寄存器和之前哪条指令的 dest 冲突了, 这样当冲突指令进入 InstructionStage.COMPLETE 阶段即可更新 Qj Qk. write_mem 变量仅对于 STORE 有效
class UnitState:
def __init__(self) -> None:
self.Op: Operation = None # 部件执行的指令类型
self.Q_j: Instruction = None # J 冲突的指令
self.Q_k: Instruction = None # K 冲突的指令
self.write_mem: Instruction = None # 仅对于 STORE 有效由于并不需要真的执行, 因此并没有保存寄存器值
SuperScale 主循环处有较大修改, 首先是发射指令时一次性发射 multi_issue_number 条指令, 如果中途遇到 Branch 类指令则停止, 因为分支指令单发射.
最后在所有指令都执行结束之后一起更新 Qj Qk 的状态, 避免指令串行更新的干扰. 同时注意到这里循环更新检查的是 issued_instructions 而不是前几次代码实现当中的 functional_units, 这是因为发射的指令并不一定会占用 Unit, 可能处于等待状态.
因此需要每次检查指令是否存在冲突 Qj Qk, 如果存在则检查冲突指令是否进入 InstructionStage.COMPLETE 阶段, 如果是则说明冲突指令已经结束, 即可更新 Qj Qk 为 None 以解除冲突. 更新每条指令的 instruction.status.Q_j/k 和 instruction.unit.status.Q_j/k
指令执行结束后会释放 Unit (instruction.unit.in_use = False), 但例如 STORE 指令还需要判断能否写回内存(即 STORE 指令的执行条件仅为 Q_k 为空, 但访存条件是 dest 无数据冒险冲突)
class SuperScale:
def __init__(self, rg: RegisterGroup, multi_issue_number: int = 2, cdb_number: int = 2) -> None:
self.register_group = rg
self.multi_issue_number = multi_issue_number # 超标量个数
self.CDB = CDB(cdb_number)
self.pc: int = 0
self.functional_units: List[Unit] = [
Unit(name="Integer ALU", function=UnitFunction.ADD),
Unit(name="FP ALU", function=UnitFunction.FADD),
]
def run(self):
self.show_status()
global CLOCK
CLOCK += 1
instruction_length = len(self.instructions)
while True:
# 当全部指令都完成后退出
if self.pc >= instruction_length:
complete_instruction_number = 0
for instruction in self.instructions:
if instruction.stage == InstructionStage.COMPLETE:
complete_instruction_number += 1
if complete_instruction_number == instruction_length:
break
# 多发射新指令
if self.pc != instruction_length:
branch_operators = [Operation.BNE]
for _ in range(self.multi_issue_number):
instruction = self.instructions[self.pc]
unit = self.get_unit(instruction.unit_function)
# 给指令绑定 unit, 暂时不将 unit 绑定指令, 在 issue 阶段绑定
instruction.unit = unit
instruction.isa = self
self.issued_instructions.append(instruction)
self.pc += 1
# 如果是分支指令则发射一条指令
if instruction.Op in branch_operators:
break
if self.pc >= instruction_length:
break
# 如果下一条是分支则也停止
if self.instructions[self.pc].Op in branch_operators:
break
# 前瞻执行, 顺序确认
if (
self.confirm_p < len(self.issued_instructions)
and self.issued_instructions[self.confirm_p].stage == InstructionStage.CONFIRM
):
self.issued_instructions[self.confirm_p].stage_clocks[InstructionStage.CONFIRM] = CLOCK
self.issued_instructions[self.confirm_p].stage = InstructionStage.COMPLETE
self.confirm_p += 1
# 所有指令发射后交由指令本身去执行
# 指令内部维护 issue -> exec -> mem -> write 的执行顺序
for instruction in self.issued_instructions:
instruction.run()
# 所有指令都执行结束之后一起更新 unit 的 Qj Qk 的状态, 避免指令串行更新的干扰
for instruction in self.issued_instructions:
if instruction.stage == InstructionStage.EXEC and instruction.left_latency == 0:
if instruction.unit:
instruction.unit.in_use = False
instruction.unit = None
if instruction.status.Q_j and instruction.status.Q_j.stage == InstructionStage.CONFIRM:
instruction.status.Q_j = None
instruction.unit.status.Q_j = None
if instruction.status.Q_k and instruction.status.Q_k.stage == InstructionStage.CONFIRM:
instruction.status.Q_k = None
instruction.unit.status.Q_k = None
if instruction.status.write_mem and instruction.status.write_mem.stage == InstructionStage.CONFIRM:
instruction.status.write_mem = None
self.CDB.finish_write_back()
self.show_status()
CLOCK += 1
pass
self.show_usage_table()指令的 run 内部有了几点变化:
self.stage_clocks变为一个字典, 因为指令可能不需要访存, 不需要写回.
- 指令内部也新增了一个 UnitState 类型的
self.status, 因为指令发射的时候并未真的进入发射阶段, 只是指令流出. 如果当前指令对应的 Unit 被占用了, 则先等待, 此时不会更新对应的 Unit 的status
- 对于发射后的指令, 如果对应的 Unit 执行的指令不是该指令, 且 Unit 可用则占据该 Unit 使用. 否则说明没有空闲, 直接返回, 继续等待
- 对于 STORE 指令还需要判断能否写回内存(即 STORE 指令的执行条件仅为 Q_k 为空, 但访存条件是 dest 无数据冒险冲突), 因此还需要额外处理判断
self.status.write_mem != None
- 只有当指令所有前面的指令都处于完成状态后该指令才可以确认
- 写回的时刻判断
self.isa.CDB.available已确认 CDB 还有空闲信道可以写回
class Instruction:
def __init__() -> None:
self.unit: Unit = None # 执行当前指令的功能单元
self.isa: SuperScale = None
self.stage: InstructionStage = InstructionStage.TOBE_ISSUE # 指令执行的阶段
self.left_latency = self.latency # 剩余执行时间
self.stage_clocks: Dict[Enum, Optional[int]] = {
InstructionStage.ISSUE: None,
InstructionStage.EXEC: None,
InstructionStage.MEM: None,
InstructionStage.WRITE: None,
InstructionStage.CONFIRM: None,
} # 五个阶段进入的时间节点
self.status: UnitState = UnitState()
def run(self):
if self.stage in (InstructionStage.CONFIRM, InstructionStage.COMPLETE):
return
global USAGE_INFO_LIST
# 其实并未真的进入发射阶段, 只是指令流出
if self.stage == InstructionStage.TOBE_ISSUE:
self.stage = InstructionStage.ISSUE
self.update_status(self.Op, self.dest, self.j, self.k)
# 如果当前指令对应的 Unit 被占用了, 则先等待
if self.unit.in_use == False:
self.unit.in_use = True
self.unit.instruction = self
self.unit.status = self.status
self.stage_clocks[InstructionStage.ISSUE] = CLOCK
elif self.stage == InstructionStage.ISSUE:
if self.unit.instruction != self:
# 如果对应的 Unit 执行的指令不是该指令, 且 Unit 可用则占据该 Unit 使用
if self.unit.in_use == False:
self.unit.in_use = True
self.unit.instruction = self
self.unit.status = self.status
else:
# 否则说明没有空闲, 直接返回, 继续等待
return
# 如果有需要等待的数据, 直接返回
if self.unit.status.Q_j or self.unit.status.Q_k:
return
self.stage = InstructionStage.EXEC
self.stage_clocks[InstructionStage.EXEC] = CLOCK
self.left_latency -= 1
USAGE_INFO_LIST.append(
RecordInfo(clock=CLOCK, unit_name=self.unit.name, instruction_id=self.id, instruction_op=self.Op)
)
elif self.stage == InstructionStage.EXEC:
if self.left_latency == 0:
if self.Op in (Operation.LOAD, Operation.STORE):
if self.Op == Operation.STORE and self.status.write_mem != None:
return
self.stage = InstructionStage.MEM
self.stage_clocks[InstructionStage.MEM] = CLOCK
USAGE_INFO_LIST.append(
RecordInfo(clock=CLOCK, unit_name="Data Cache", instruction_id=self.id, instruction_op=self.Op)
)
elif self.Op == Operation.BNE:
self.stage = InstructionStage.CONFIRM
else:
if self.isa.CDB.available:
self.isa.CDB.send_data()
self.stage = InstructionStage.WRITE
self.stage_clocks[InstructionStage.WRITE] = CLOCK
self.stage = InstructionStage.CONFIRM
USAGE_INFO_LIST.append(
RecordInfo(clock=CLOCK, unit_name="CDB", instruction_id=self.id, instruction_op=self.Op)
)
else:
self.left_latency -= 1
elif self.stage == InstructionStage.MEM:
if self.Op == Operation.STORE:
self.stage = InstructionStage.CONFIRM
else:
if self.isa.CDB.available:
self.isa.CDB.send_data()
self.stage = InstructionStage.WRITE
self.stage_clocks[InstructionStage.WRITE] = CLOCK
self.stage = InstructionStage.CONFIRM
USAGE_INFO_LIST.append(
RecordInfo(clock=CLOCK, unit_name="CDB", instruction_id=self.id, instruction_op=self.Op)
)
else:
raise ValueError(self.stage.value)代码中的
USAGE_INFO_LIST是用于统计利用率的, 可以暂时忽略
对于本次作业的情况, 仅需新添加一个 Unit(name="Address ALU", function=UnitFunction.INTEGER) 用于单独处理地址计算, 然后将 LOAD/STORE 指令的 unit_function 设置为 UnitFunction.INTEGER 即可, 如 hw.py 中的修改所示