scoreboard

运行结果
jupyter 提交版见 main.ipynb
python src/homework4/main.py输出结果很多, 仅展示部分内容(clock1 和 clock62 的输出), 完整内容见 output.txt
[instruction status]
Op dest j k | Issue Read Exec Write
Load F6 34 R2 |
Load F2 45 R3 |
Mul F0 F2 F4 |
Sub F8 F6 F2 |
Div F10 F0 F6 |
Add F6 F8 F2 |
[functional unit status]
Time Name | Busy Op Fi Fj Fk Qj Qk Rj Rk
Integer | No No No
Mult1 | No No No
Mult2 | No No No
Add | No No No
Divide | No No No
[register result status]
F0 F2 F4 F6 F8 F10
Cycle 0
.
.
.
----------------------------------------------------------------------
[instruction status]
Op dest j k | Issue Read Exec Write
Load F6 34 R2 | 1 2 3 4
Load F2 45 R3 | 5 6 7 8
Mul F0 F2 F4 | 6 9 19 20
Sub F8 F6 F2 | 7 9 11 12
Div F10 F0 F6 | 8 21 61 62
Add F6 F8 F2 | 13 14 16 22
[functional unit status]
Time Name | Busy Op Fi Fj Fk Qj Qk Rj Rk
Integer | No No No
Mult1 | No No No
Mult2 | No No No
Add | No No No
Divide | No No No
[register result status]
F0 F2 F4 F6 F8 F10
Cycle 62各功能单元使用情况
Unit Instruction start end theoretical/running
Integer LOAD F6 34 R2 1 4 4/4
LOAD F2 45 R3 5 8 4/4
Mult1 MUL F0 F2 F4 6 20 13/15
Mult2
Add SUB F8 F6 F2 7 12 5/6
ADD F6 F8 F2 13 22 5/10
Divide DIV F10 F0 F6 8 62 43/55ScoreBoard 算法
背景
下面先来介绍一下 scoreboard 算法本身, 再来介绍一下笔者的类设计思路和代码运行逻辑
现代的高性能处理器基本都支持多发射和乱序执行,但处理器受到数据冒险的影响并不能轻易地实现乱序,所以业界提出了诸如 scoreboard 算法来控制这个过程
顺序执行要求指令一条接一条地流过各个流水段, 如果一条指令被阻塞,那么它后面的指令也被阻塞,即使后面的指令完全可以继续运算而不受被阻塞指令的影响.所以聪明的设计师想到要开几条"近道",好让后面的指令能绕过恰过前面的指令,从而继续执行.
例如当执行需要时间很长的访存指令 lw , 我们不希望下一条无关指令等待 lw 的 cache miss/data miss, 或者不需要等待一条耗时很长的 divide 除法运算
但在传统的五级流水线中,运算通路只有一条,每一条指令都需要依次通过处理器中的 ALU /存储器等部件,这个设定有一个言下之意,就是所有指令都按照一个计算流进行工作
但这不是事实.事实是不同类型的指令有不同的计算要求,前面的例子中 lw 指令需要 ALU 和存储器,但是后面的一连串计算指令不需要访问存储器,所以它们完全可以绕过存储器继续执行,但是因为五级流水线中设计每条指令都要经过存储器,所以后面的计算指令不得不等着 lw 把存储器让出来.
因此, 我们希望
- 每一条指令都可以去选择所需的阶段, 例如 lw 需要全部的 IF ID EX MEM WB 阶段, 但 addi 只需要 IF ID EX WB (即跳过访存 MEM 阶段);
- 与此同时, 计算指令也有各种各样的计算要求以及耗时 (例如浮点数除法的计算周期要远多于普通整数加法计算周期), 加法/乘法/除法指令所需要的计算部件肯定也是不一样的, 我们也期望可以使用不同的计算部件完成对应指令的计算
在五级流水线中只有一个配置,而乱序执行要求,实现"多配置"的流水线处理器, 为各种指令做个性化的配置, 以实现乱序执行.
算法流程
scoreboard 其本质是使用一个类似表格的信息存储单元, 通过在指令流水线中为每个指令维护一个"分数牌"(scoreboard),以实现指令的并发执行和解决数据依赖关系.通过分析指令的操作数和状态信息, 动态调度指令的执行
scoreboard 有两个重要的组成部分, 第一部分是 功能单元状态, 里面的 9 个状态非常关键:
Busy: 单元是否繁忙
Op: 部件执行的指令类型
F_i: 目的寄存器
F_j: 源寄存器
F_k: 源寄存器
Q_j: 如果源寄存器 F_j 不可用, 部件该向哪个功能单元要数据
Q_k: 如果源寄存器 F_k 不可用, 部件该向哪个功能单元要数据
R_j: 源寄存器 F_j 是否可读/需要读
R_k: 源寄存器 F_k 是否可读/需要读

现在这里可能有些抽象, 稍后笔者会结合具体的示例做解释
第二部分是 寄存器结果状态. 里面主要记录对于某一个寄存器,是否有功能单元正准备写入数据.

例如上图中 F4 对应 Mult1,这就表明功能模块 Mult1 的计算结果将要写入 F4.
CDC6600 处理器执行分为四个阶段, 即发射(issue), 读取(read), 执行(exec), 写回(write back)
再来看一下我们要执行的指令, 一共六条, 如下所示. 其中的前向数据关联和后向数据关联都以及在图中标记出来了

这几条指令的寄存器关联程度很高, 很适合作为数据冒险的示例来展示 scoreboard 算法的处理方式
计算处理单元有 5 个
- 1 个访存单元 Integer (我也不知道为什么要叫 Integer)
- 2 个乘法单元 Mult1, Mult2
- 1 个加法单元 Add (减法运算也由加法单元执行)
- 1 个除法单元 Divide
下面结合具体实例来说明一下 scoreboard 在各个周期执行的操作以及状态的变化
CLOCK 0
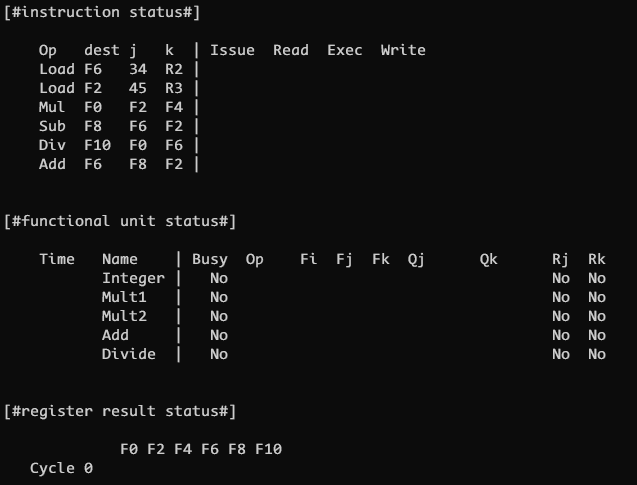
初始状态如上图所示, 所有指令都未发射, 所有功能单元都空闲, 所有寄存器结果状态为空
CLOCK 1
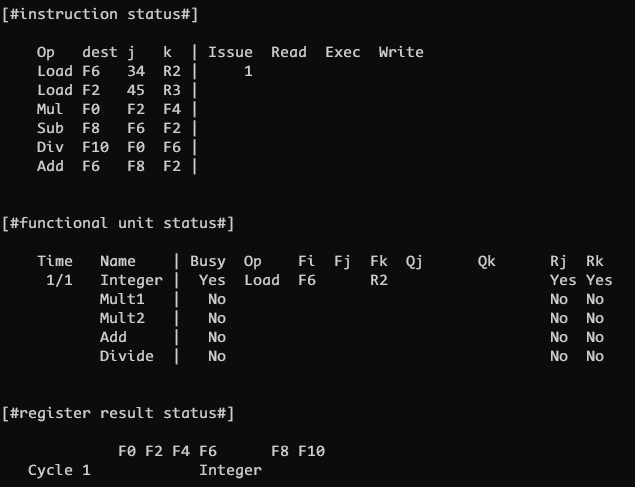
每个周期开始都会尝试发射下一条指令, 只要满足三个条件
- 如果有指令
- 有可用的功能单元
- 指令要写的目的寄存器没有别的指令将要写
CLOCK 1 时三个条件都满足, 因此发射指令 load F6, 34(R2), 设置 Integer 功能单元 Busy 为 True; Fi 更新为目的寄存器 F6, 同时将 F6 寄存器结果状态标记为 Integer , 表示该功能单元正在使用 F6 寄存器作为目的寄存器
Fj 是立即数置空即可, Fk 标记为源寄存器 F2; 此时 R2 R3 两个寄存器都是可读的, 且需要读取的, 所以标记 Rj Rk 为 Yes; 不需要 Qj Qk
CLOCK 2
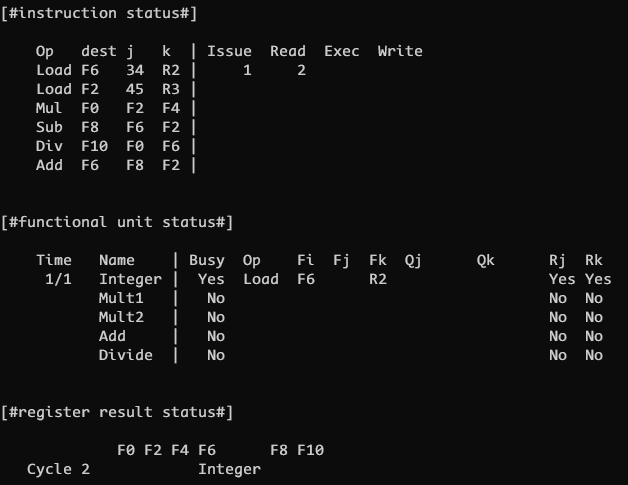
CLOCK 2 及之后需要做两件事, 首先尝试发射下一条指令, 其次尝试运行所有已发射的指令进入下一个阶段
由于指令2也是load指令需要 Integer 功能单元, 但是该单元已经被指令1占用了, 因此不发射
指令 1 进入 read 阶段, 读取寄存器 R2 R3 的值
这里分首先和其次是因为发射的条件要确定 指令要写的目的寄存器没有别的指令将要写, 因为已发射的指令有可能以相同的目的寄存器为写回目标. 写回需要一个周期去执行, 但是发射的瞬间就需要确定当前目的寄存器是可写的, 因此需要 先判断发射条件是否满足, 然后再执行
CLOCK 3
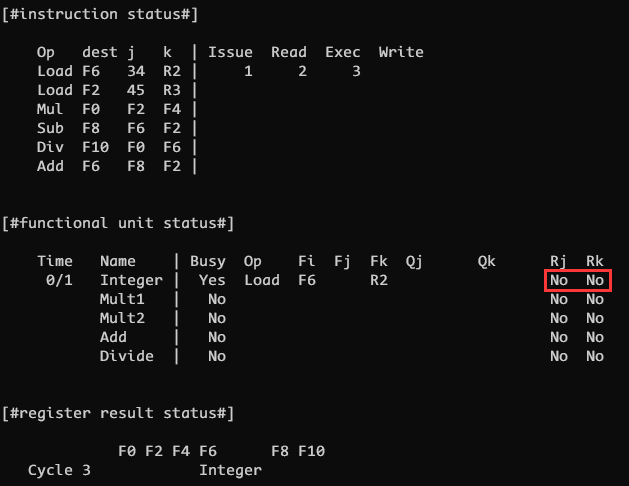
CLOCK 3 阶段指令 2 依然无法发射, 指令 1 进入 exec 阶段执行, 从对应存储器地址取值. 此时更新 Rj Rk 的值为 No, 因为 Rj Rk 既表示 Fj/Fk 寄存器是否可读, 也表示是否需要读, 此时经过了 Read 阶段指令 1 就不再需要读取寄存器的值了, 因此置为 No
Time 指的是执行指令所需要的时间, 即 exec 阶段的用时, 默认一般指令用时 1 个周期
CLOCK 4
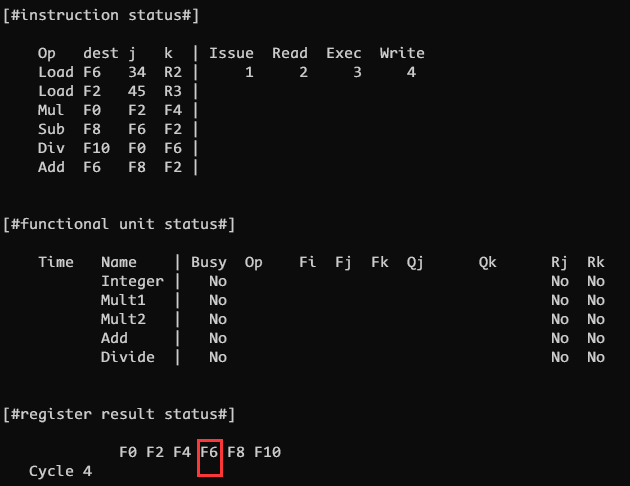
CLOCK 4 指令完成写回操作, 清空 Integer 功能单元, 置其 Busy 位为 False, 并清空 F6 寄存器结果状态中的 Integer 功能单元
CLOCK 5
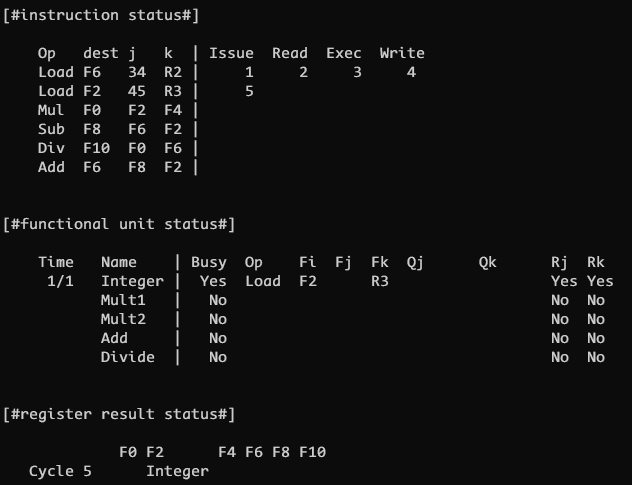
CLOCK 5 发射指令 2, 以相似的方式更新 Integer 功能单元 和 F2 寄存器结果状态
CLOCK 6
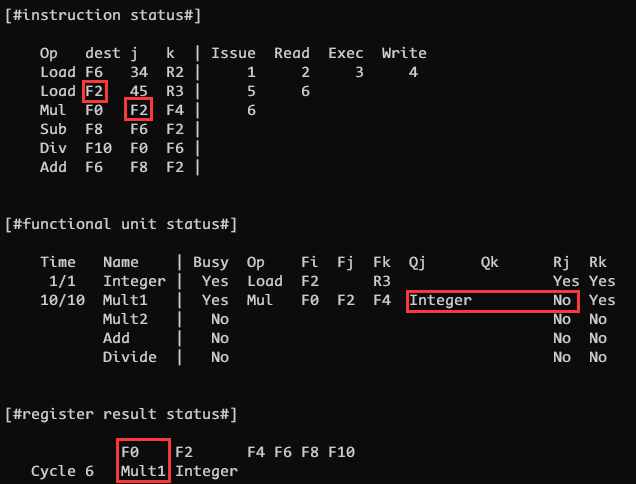
CLOCK 6 尝试做两件事情, 首先尝试发射一条新指令, 此时 有可用的功能单元(mult1) 且 指令要写的目的寄存器(F0)没有别的指令将要写, 因此发射指令 3, 更新 Mult1 功能单元 和 F0 寄存器结果状态
但此时注意到指令 3 的源寄存器 F2 和 指令 2 的目的寄存器 F2 冲突了, 这是一个经典的写后读(RAW), 因此 F2 寄存器暂时不可读, 置 Mult1 的 Rj 为 No, 并且标记 Qj 为 Integer, 表示只有当 Integer 功能单元执行结束了之后才可以读 F2 寄存器的值
或者说从 Integer 功能单元处拿到最新的 F2 的值
指令 2 进入 Read 阶段
CLOCK 7
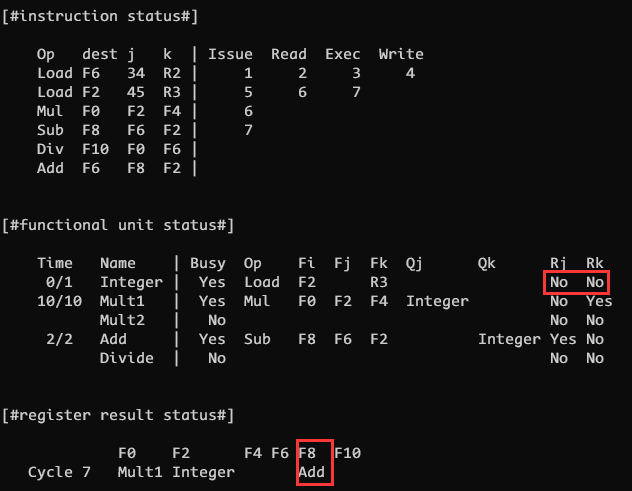
CLOCK 7 时指令 4 也满足发射条件, 因此可以发射指令 4, 更新 Add 功能单元 和 F8 结果寄存器状态; 同时也注意到指令 4 的源寄存器 F2 也和指令 2 的目的寄存器 F2 冲突(RAW), 因此设置 Rk 为 No, Qk 为 Integer
同时指令 2 进入 exec 阶段, 不再需要读寄存器, 置 Rj Rk 为 No
sub 虽然是减法但是也是用 add 加法单元来做的
CLOCK 8
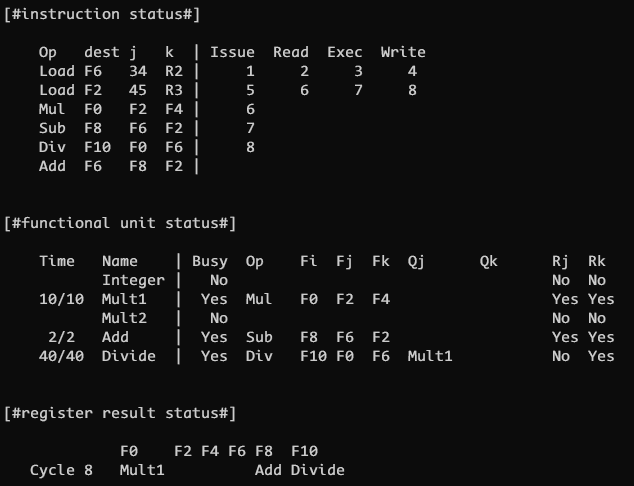
CLOCK 8 再次发射一条新指令 5, 但发现源寄存器 F0 和指令 4 的目的寄存器 F0 冲突了, 所以 Rj 置 No 且 Qj 置 Mult1
此时指令 2 完成写回操作, 即原先被占用的 F2 寄存器的值已经完成更新, 因此原先被卡住的指令3,4 所对应的 Mult1 和 Add 终于可以准备进入下一个阶段, 重新将其 Rj/Rk 置为 Yes 表示可以读了, 然后清空 Qj/Qk 表示其所对应的功能单元已经执行结束, 不再需要等待了
CLOCK 17 & CLOCK 22
CLOCK 9 - 16 没有什么要说的, 依然按照之前的流程来做, 相信读者应该已经掌握基本原理了
需要重点提一下的是 CLOCK 17, 我们先来看一下 CLOCK 16 的情况, 如下图所示
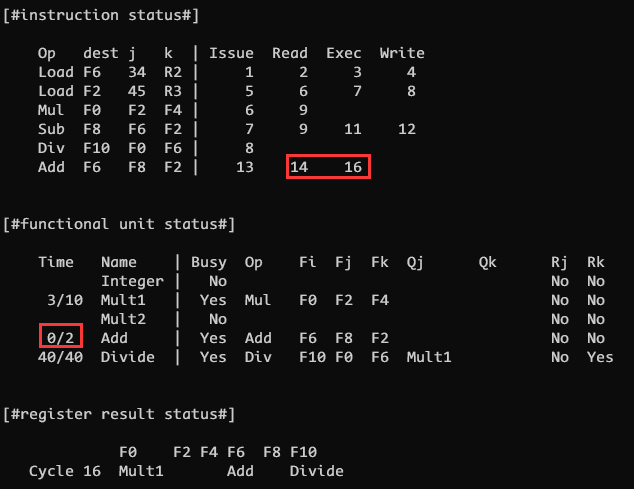
此时指令 6 对应的 Add 单元刚刚经历了 2 个周期的 exec 阶段, Mult1 还剩下 3 个周期执行, Divide 因为等待来自 Mult1 的 F0 被卡住, 其余指令均已执行完毕
但是 CLOCK 17 时 Add 并没有写回, 而是卡住, Mult1 继续执行一个周期
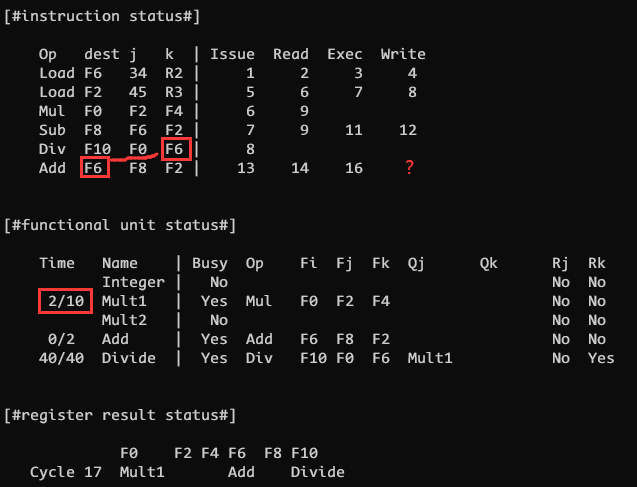
这是因为指令 6 的目的寄存器 F6 与 在其前面的指令 5 使用的源寄存器 F6 发生了冲突, 这是一个读后写(WAR). 正常来说读后写是不会遇到问题的(因为只要读出数据之后就随便写), 但是因为乱序执行所以 add 指令优先于 divide 指令执行结束, 即指令 5 在读之前, 其后的指令 6 就要写入该寄存器
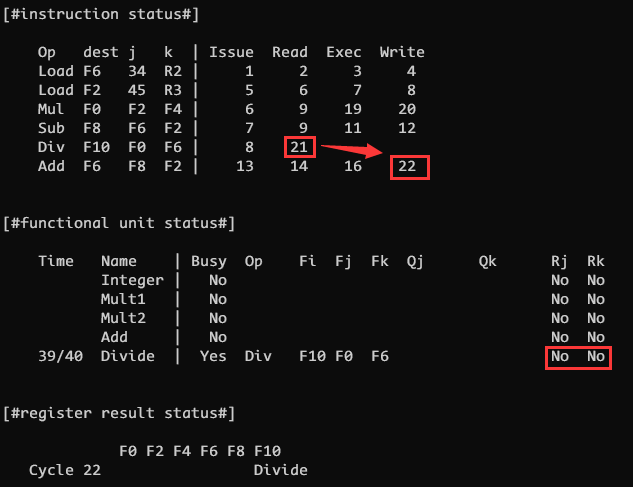
因此必须等到 CLOCK 21 时 Divide 完成 Read, 将 F6 寄存器的值读取结束之后, 才可以在 CLOCK 22 时将 Add 的 F6 写入
实验报告
实验分析
本次实验相对比较独立, 要求完成 scoreboard 算法的代码实现, 和之前写的流水线代码也没有相关性, 所以基本相当于重写
好在只是要求模拟算法本身的执行流程, 并不要求真正完成计算,
不然真好麻烦
代码实现
先来看一下主函数入口, 由于这是一组固定指令序列的模拟, 因此笔者并没有实现完整的指令集以及指令解析, 只是简单定义一些枚举类信息, 将对应的寄存器绑定到指令上.
值的一提的是这里的 latency, 严格来说延迟指的是除 EX 阶段本身耗时的一个周期之外额外的周期数, 即 latency 为 2 意味着 exec 阶段共需要 3 个周期执行结束, 不过从各方(老师PPT和其他scoreboard文章)来看这里的latency似乎指的是 exec 阶段总共的执行时间, 说实话笔者心里有些存疑, 不过还是按照后者的方式编写的代码实现, 即 latency = 2 意味着需要 2 个周期完成 exec, 默认指令的 latency 为 1
def main():
rg = RegisterGroup()
instructions = [
Instruction(Op=Operation.LOAD, dest=rg.F6, j=34, k=rg.R2, latency=1, unit_function=UnitFunction.INTEGER),
Instruction(Op=Operation.LOAD, dest=rg.F2, j=45, k=rg.R3, latency=1, unit_function=UnitFunction.INTEGER),
Instruction(Op=Operation.MUL, dest=rg.F0, j=rg.F2, k=rg.F4, latency=10, unit_function=UnitFunction.MULT),
Instruction(Op=Operation.SUB, dest=rg.F8, j=rg.F6, k=rg.F2, latency=2, unit_function=UnitFunction.ADD),
Instruction(Op=Operation.DIV, dest=rg.F10, j=rg.F0, k=rg.F6, latency=40, unit_function=UnitFunction.DIVIDE),
Instruction(Op=Operation.ADD, dest=rg.F6, j=rg.F8, k=rg.F2, latency=2, unit_function=UnitFunction.ADD),
]
scoreboard = ScoreBoard(rg)
scoreboard.load_instructions(instructions)
scoreboard.run()
if __name__ == "__main__":
main()这里选择在外侧创建 RegisterGroup 类实例对象并传入 ScoreBoard, 而不是在 ScoreBoard 内部创建主要有两个原因, 第一个是因为希望在指令(Instruction)初始化阶段就完成对于寄存器的绑定, 不然初始化时只能绑定一个字符串 "F6" 然后再在内部匹配对于寄存器, 有一点麻烦. 第二个是因为 ScoreBoard 算法本身只维护功能单元信息和寄存器结果状态, 本身寄存器的值以及其他信息就不应该是 ScoreBoard 类对象创建和维护, 因此选择在外部定义, rg 作为寄存器组对象的引用被传递进 ScoreBoard 类完成初始化
run 部分是 ScoreBoard 核心运行流程, 但是在看 run 之前先来看一下 Unit 功能单元的定义
首先 ScoreBoard 类对象初始化阶段定义的 functional_units 对应 5 个 Unit, 分别绑定对应的功能
class ScoreBoard:
def __init__(self, rg: RegisterGroup) -> None:
self.instructions: List[Instruction] = []
self.issued_instructions: List[Instruction] = []
self.pc: int = 0
self.functional_units: List[Unit] = [
Unit(name="Integer", function=UnitFunction.INTEGER),
Unit(name="Mult1", function=UnitFunction.MULT),
Unit(name="Mult2", function=UnitFunction.MULT),
Unit(name="Add", function=UnitFunction.ADD),
Unit(name="Divide", function=UnitFunction.DIVIDE),
]
self.register_group = rgUnit 内部的 status 表示当前功能单元的状态, 分别对应前文提到的 9 个状态
class UnitState:
def __init__(self) -> None:
self.Busy: bool = False # 单元是否繁忙
self.Op: Operation = None # 部件执行的指令类型
self.F_i: FloatRegister = None # 目的寄存器
self.F_j: FloatRegister = None # 源寄存器
self.F_k: FloatRegister = None # 源寄存器
self.Q_j: "Unit" = None # 如果源寄存器 F_j 不可用, 部件该向哪个功能单元要数据
self.Q_k: "Unit" = None # 如果源寄存器 F_k 不可用, 部件该向哪个功能单元要数据
self.R_j: bool = False # 源寄存器 F_j 是否可读/需要读
self.R_k: bool = False # 源寄存器 F_k 是否可读/需要读
class Unit:
def __init__(self, name: str, function: UnitFunction) -> None:
self.name = name
self.function = function
self.status = UnitState()
self.instruction: Instruction = None
self.usage_data: Dict[Instruction, List[int]] = {}接下来回头看一下 ScoreBoard 的运行核心 run 函数, 内部是一个 while 死循环, 只有全部指令都已发射并且所有功能单元都空闲时才退出. 执行流程分为三个阶段
- 尝试发射一条新指令: 当有指令 && 有可用的功能单元 && 指令要写的目的寄存器没有别的指令将要写
如果都满足, 则将对应的 unit 绑定到指令, 并将指令放入到 issued_instructions 中
- 运行所有已发射的指令(issued_instructions), 由每一条指令内部维护 issue -> read -> exec -> write 的执行顺序
- 在所有指令都执行结束之后一起更新 unit 的 Rj Rk Qj Qk 的状态, 因为 write back 阶段回清空目的寄存器, 但是由于前面指令执行的时候使用的是
for循环串行的调用issued_instruction.run(), 因此为了避免指令串行更新的干扰在这里统一更新, 解开由于因为目的寄存器和源寄存器读写冲突的 unit
class ScoreBoard:
def run(self):
self.show_status()
global CLOCK
CLOCK += 1
instruction_length = len(self.instructions)
while True:
# 当全部指令都已发射并且所有功能单元都空闲时退出
if self.pc == instruction_length:
busy_unit_number = 0
for unit in self.functional_units:
if unit.status.Busy:
busy_unit_number += 1
if busy_unit_number == 0:
break
# 尝试发射一条新指令
# 1. 如果有指令
# 2. 并且有可用的功能单元
# 3. 且指令要写的目的寄存器没有别的指令将要写
# 则发射下一条指令
if self.pc != instruction_length:
unit = self.has_available_unit(self.instructions[self.pc].unit_function)
if unit is not None and not self.has_write_conflict(self.instructions[self.pc].dest):
self.instructions[self.pc].unit = unit
unit.instruction = self.instructions[self.pc]
self.issued_instructions.append(self.instructions[self.pc])
self.pc += 1
# 所有指令发射后交由指令本身去执行
# 指令内部维护 issue -> read -> exec -> write 的执行顺序
for issued_instruction in self.issued_instructions:
issued_instruction.run()
# 所有指令都执行结束之后一起更新 unit 的 Rj Rk Qj Qk 的状态, 避免指令串行更新的干扰
for unit in self.functional_units:
if unit.status.R_j == False and unit.status.Q_j and unit.status.Q_j.status.Busy == False:
unit.status.R_j = True
unit.status.Q_j = None
if unit.status.R_k == False and unit.status.Q_k and unit.status.Q_k.status.Busy == False:
unit.status.R_k = True
unit.status.Q_k = None
self.show_status()
CLOCK += 1
self.show_usage_data()那么关键在于 instruction.run 的实现, 但我们先看一下寄存器(FloatRegister)的定义, 这对理解指令内部执行的代码很有帮助. 其中的三个变量的含义如下
ready_to_be_read: 表示当前寄存器是否可以被读
be_asked_to_read: 表示正在读当前寄存器的 unit 的数量
in_used_unit: 表示正在使用当前寄存器作为目的寄存器的 unit
class FloatRegister:
def __init__(self, name: str) -> None:
self.name = name
self.ready_to_be_read = True # 当前寄存器是否可以被读
self.be_asked_to_read = 0 # 正在读当前寄存器的 unit 的数量 (用于 WAR) 的判断
self.in_used_unit: Optional["Unit"] = None指令的执行分为四个阶段:
- 如果发现已完成
COMPLETE则直接返回.
- 如果还未发射
TOBE_ISSUE则进入发射阶段ISSUE, 并且更新 unit 的状态(update_status)
- 如果已发射
- 如果两个源寄存器都可读, 则进入
READ阶段
- 否则卡在这里等待对应的 unit 执行结束
- 如果两个源寄存器都可读, 则进入
- 如果在
READ阶段, 则进入EXEC阶段, 完成读取(finish_read)
- 如果在
EXEC阶段, 并且已经执行结束(left_latency == 0), 则说明指令完成COMPLETE
class Instruction:
def __init__(...) -> None:
...
self.unit: Unit = None # 执行当前指令的功能单元
self.stage: InstructionStage = InstructionStage.TOBE_ISSUE # 指令执行的阶段
self.left_latency = self.latency # 剩余执行时间
self.stage_clocks = [] # 四个阶段进入的时间节点
def run(self):
""" """
if self.stage == InstructionStage.COMPLETE:
return
if self.stage == InstructionStage.TOBE_ISSUE:
self.stage = InstructionStage.ISSUE
self.unit.update_status(self.Op, self.dest, self.j, self.k)
self.stage_clocks.append(CLOCK)
elif self.stage == InstructionStage.ISSUE:
# 当两个源寄存器都可读的时候继续
if self.unit.status.R_j and self.unit.status.R_k:
self.stage = InstructionStage.READ
self.stage_clocks.append(CLOCK)
elif self.stage == InstructionStage.READ:
self.stage = InstructionStage.EXEC
self.unit.finish_read()
self.left_latency -= 1
if self.left_latency == 0:
self.stage_clocks.append(CLOCK)
elif self.stage == InstructionStage.EXEC:
if self.left_latency > 0:
self.left_latency -= 1
if self.left_latency == 0:
self.stage_clocks.append(CLOCK)
else:
if self.unit.status.F_i.be_asked_to_read != 0:
# WAR hazard
return
self.stage = InstructionStage.WRITE
self.unit.status.Busy = False
self.unit.status.F_i.in_used_unit = None
self.unit.status.F_i.ready_to_be_read = True
self.stage = InstructionStage.COMPLETE
self.stage_clocks.append(CLOCK)
# 添加统计数据
self.unit.usage_data[self] = self.stage_clocks上述流程中除了表面上的代码还封装了两个位于 unit 中的函数 update_status 和 finish_read. 对于目的寄存器 Fi, 设置其正在被 self(即当前 unit) 占用, 以及作为要被写入的目的寄存器, 暂时不可被读取(ready_to_be_read = False)
j/k 寄存器如果是立即数单独处理一下, 否则直接更新 Fk Rk Qk 为对应的状态. 其中如果源寄存器是可读的(Rj/Rk == True), 则 be_asked_to_read 值加 1, 表示当前寄存器需要被/正在被读取, 用于判断前文提到的 CLOCK 17 CLOCK 22 的读后写问题
finish_read 就是当完成 READ 阶段更新 Rj/Rk 表示不再需要读取源寄存器了, 计数减一
class Unit:
def update_status(self, Op: Operation, dest: FloatRegister, reg_j: Union[int, FloatRegister], reg_k: FloatRegister):
self.status.Busy = True
self.status.Op = Op
self.status.F_i = dest
self.status.F_i.in_used_unit = self
self.status.F_i.ready_to_be_read = False
if type(reg_j) == int:
# 立即数
self.status.F_j = None
self.status.R_j = True
self.status.Q_j = None
else:
self.status.F_j = reg_j
self.status.R_j = reg_j.ready_to_be_read
self.status.Q_j = reg_j.in_used_unit
if self.status.R_j:
self.status.F_j.be_asked_to_read += 1
self.status.F_k = reg_k
self.status.R_k = reg_k.ready_to_be_read
self.status.Q_k = reg_k.in_used_unit
if self.status.R_k:
self.status.F_k.be_asked_to_read += 1
def finish_read(self):
self.status.R_j = False
self.status.R_k = False
if self.status.F_j is not None:
self.status.F_j.be_asked_to_read -= 1
self.status.F_k.be_asked_to_read -= 1因此最后的写回阶段, 只有当目的寄存器没有被前面发射的指令读的时候才可以写回 (self.unit.status.F_i.be_asked_to_read != 0), 然后做一些收尾的释放
最后是一些输出格式化之类的比较繁琐的内容