rob-tom
Tomasulo 算法的重排缓冲区(ROB)的代码实现, 本次并不是课程布置的作业, 仅觉得设计的还蛮有意思的所以就稍微修改实现了一下
运行结果
python src/homework6/main.py完整输出见 output.txt
----------------------------------------------------------------------
[instruction status]
Op dest j k | Issue Exec Write Commit
Load F6 34 R2 | 1 2 3 4
Load F2 45 R3 | 2 3 4 5
Mul F0 F2 F4 | 3 14 15 16
Sub F8 F6 F2 | 4 6 7 17
Div F10 F0 F6 | 5 55 56 57
Add F6 F8 F2 | 6 9 10 58
[reorder buffer]
Entry Busy Instruction Stat Dest value
head -> 1 No LOAD F6 34 R2 COMMIT F6 234
2 No LOAD F2 45 R3 COMMIT F2 345
3 No MUL F0 F2 F4 COMMIT F0 0
4 No SUB F8 F6 F2 COMMIT F8 234
5 No DIV F10 F0 F6 COMMIT F10 0.0
tail -> 6 No ADD F6 F8 F2 COMMIT F6 345
[reservation station]
Time Name | Busy Op Vj Vk Qj Qk A Dest
Load1 | No
Load2 | No
Load3 | No
Add1 | No
Add2 | No
Mult1 | No
Mult2 | No
[register result status]
F0 F2 F4 F6 F8 F10
Cycle 58实验报告
相比原先的 tomasulo 算法, rob 添加了右上角的重排缓冲区, 如下图所示
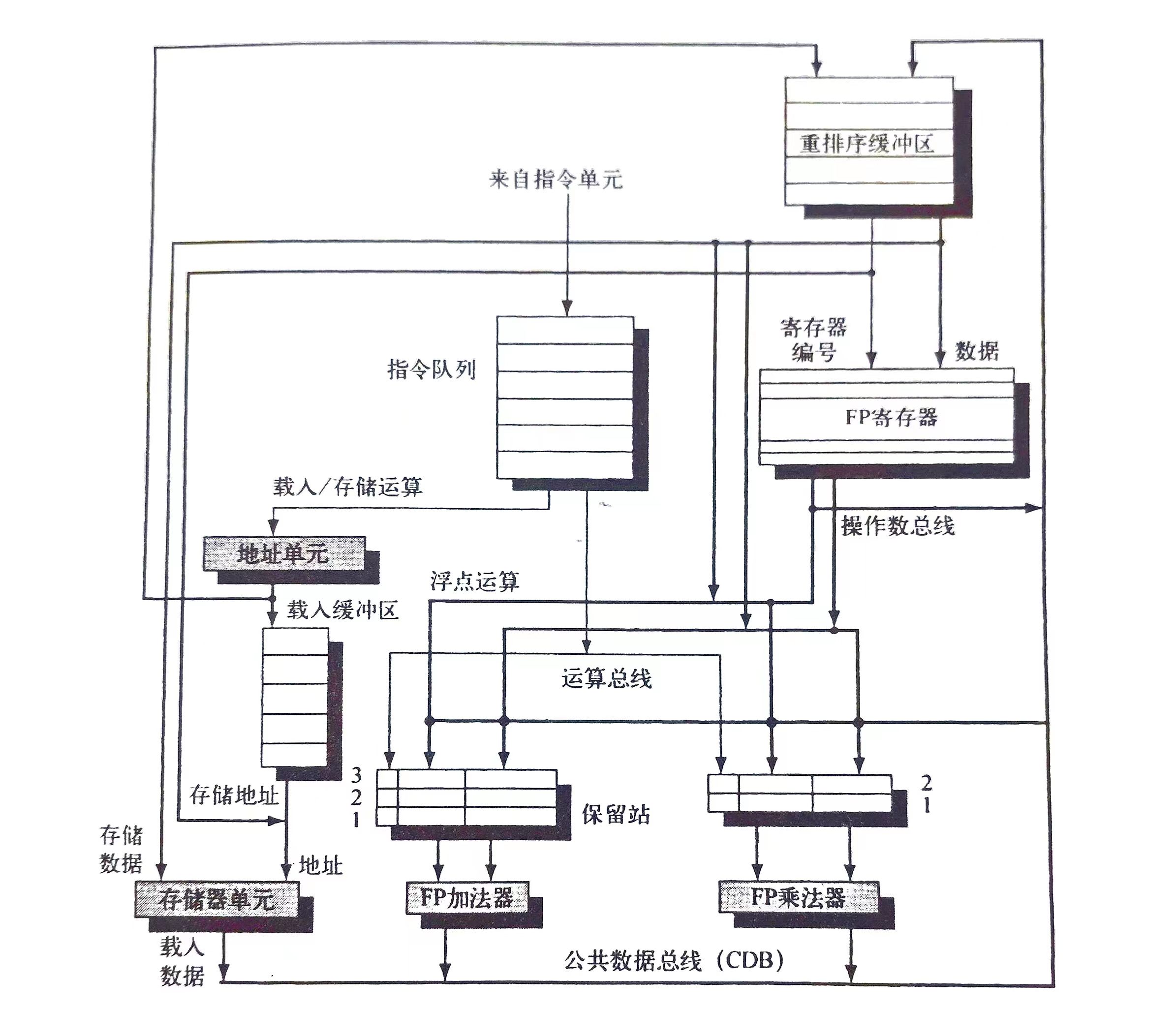
指令执行结束写回时并不直接写入到寄存器当中, 而是先进入 reorder buffer(下文简称 ROB), ROB 中维护了指令的发射顺序和提交顺序, 只有当前面的所有指令全部提交之后当前指令才可以提交(指写回寄存器). 有利于实现顺序提交和精确中断
相比原先其实并没有太大的改动, 只是多了一个 COMMIT 的阶段, 原先的 Qj Qk 改为 ROB 表项, 由 head/tail 维护的 COMMIT 提交顺序, 其余与 tomasulo 算法相同
笔者的输出中保留了
[instruction status]部分的阶段周期时刻表, 读者可以比较清晰的看到各个阶段的结束周期
代码实现
需要注意的是, 与 计算机体系结构-重排序缓存ROB 中不同, 笔者在周期 4 指令 2 写回的同时指令 3 并没有立即进入 exec 阶段, 正如作者所言: "接收到广播之后什么时候开始执行是由微体系结构决定的", 笔者选择的是多等待了一个周期时刻, 与老师的 PPT 示例相同
相比 tomasulo, ROB 部分只新增了 reorder_buffer 部分
class TomasuloROB:
def __init__(self, rg: RegisterGroup) -> None:
...
self.reorder_buffer = ReorderBuffer(buffer_size=6)相比 ReorderBuffer 由 n 个 缓冲区(ReorderBufferItem)组成, 指令会绑定到具体的一个 ReorderBufferItem
class ReorderBufferItem:
def __init__(self, entry: int, parent_rob: "ReorderBuffer") -> None:
self.entry = entry
self.Busy: bool = False
self.value = None
class ReorderBuffer:
def __init__(self, buffer_size: int) -> None:
self.buffer_size = buffer_size
self.head = 0
self.tail = -1
self.buffer: List[ReorderBufferItem] = []
for i in range(1, buffer_size + 1):
self.buffer.append(ReorderBufferItem(i, self))
self.is_head_move = False # head 指针是否移动
self.issued_instructions: List[Instruction] = []issued_instructions 的执行阶段挪到 ROB 内部的 run 里了
具体的阶段中需要注意的是 exec 结束就可以释放 unit, 并且只有当前指令是 head 的时候才可以 commit
class Instruction:
def run(self):
...
elif self.stage == InstructionStage.EXEC:
if self.return_value is not None:
self.stage = InstructionStage.WRITE
self.rob_item.value = self.return_value
# exec 结束就可以释放 unit
self.unit.status.Busy = False
self.dest.in_used_unit = None
self.stage_clocks.append(CLOCK)
else:
self.left_latency -= 1
if self.left_latency == 0:
self.return_value = self.unit.exec()
self.stage_clocks.append(CLOCK)
elif self.stage == InstructionStage.WRITE:
# 只有是 head 的时候才可以 commit
if self.rob_item.parent_rob.head + 1 == self.rob_item.entry:
# 更新 head 指针, 避免指令顺序影响
self.rob_item.parent_rob.is_head_move = True
self.stage = InstructionStage.COMMIT
self.dest.value = self.rob_item.value
self.dest.in_rob_item = None
self.rob_item.Busy = False
self.stage_clocks.append(CLOCK)