python-riscv
作业要求:

运行结果
python src/homework1/main.pyjupyter 提交版见 main.ipynb
before
####################
mem[ 0] = 123 |mem[ 1] = 99 |mem[ 2] = 0 |mem[ 3] = 0 |
mem[ 4] = 0 |mem[ 5] = 0 |mem[ 6] = 0 |mem[ 7] = 0 |
mem[ 8] = 0 |mem[ 9] = 0 |mem[10] = 0 |mem[11] = 0 |
mem[12] = 0 |mem[13] = 0 |mem[14] = 0 |mem[15] = 0 |
mem[16] = 0 |mem[17] = 0 |mem[18] = 0 |mem[19] = 0 |
####################
r0 = 0 |r1 = 0 |r2 = 0 |r3 = 0 |r4 = 0 |r5 = 0 |r6 = 0 |r7 = 0 |
r8 = 0 |r9 = 0 |r10 = 0 |r11 = 0 |r12 = 0 |r13 = 0 |r14 = 0 |r15 = 0 |
r16 = 0 |r17 = 0 |r18 = 0 |r19 = 0 |r20 = 0 |r21 = 0 |r22 = 0 |r23 = 0 |
r24 = 0 |r25 = 0 |r26 = 0 |r27 = 0 |r28 = 0 |r29 = 0 |r30 = 0 |r31 = 0 |
####################
after
####################
mem[ 0] = 123 |mem[ 1] = 99 |mem[ 2] = 0 |mem[ 3] = 222 |
mem[ 4] = 0 |mem[ 5] = 0 |mem[ 6] = 0 |mem[ 7] = 0 |
mem[ 8] = 0 |mem[ 9] = 0 |mem[10] = 0 |mem[11] = 0 |
mem[12] = 0 |mem[13] = 0 |mem[14] = 0 |mem[15] = 0 |
mem[16] = 0 |mem[17] = 0 |mem[18] = 0 |mem[19] = 0 |
####################
r0 = 0 |r1 = 0 |r2 = 123 |r3 = 222 |r4 = 0 |r5 = 0 |r6 = 0 |r7 = 0 |
r8 = 0 |r9 = 0 |r10 = 0 |r11 = 0 |r12 = 0 |r13 = 0 |r14 = 0 |r15 = 0 |
r16 = 0 |r17 = 0 |r18 = 0 |r19 = 0 |r20 = 0 |r21 = 0 |r22 = 0 |r23 = 0 |
r24 = 0 |r25 = 0 |r26 = 0 |r27 = 0 |r28 = 0 |r29 = 0 |r30 = 0 |r31 = 0 |
####################实验报告
实验分析
本次实验要求非常不明确, 多方询问后得知大概意思是实现如图中四条伪汇编的指令解析以及处理器执行架构模拟
笔者本科计组学习的是 RISCV 架构, 五级流水线, 由于使用 python 来进行高级语言层面的模拟, 因此可以做一些更宏观和抽象的模拟, 而不是像 verilog 那种很时序很连线的仿真
实验设计
考虑到题目中的一些要求, 32 位, 内存单元 8 bit, 32 位寄存器, 因此选择使用 RISCV-32I 指令集, 展开为如下五条指令完成上述任务
xor r1, r1, r1
lb 0(r1), r2
lb 1(r1), r3
add r2, r3, r3
sb 3(r1), r3处理器执行架构采用单周期, 因为如果使用流水线中 lb 1(r1), r3 的 WB 与 add r2, r3, r3 EXE 也会产生数据冒险, 还需要再加一个冒泡才能解决
而且流水线写起来太麻烦了, 估计 debug 都要好长时间, 第一次作业没必要搞这么复杂...
本次实验不需要考虑大端小端, 因为题中每个 cell 是 8 bits, 且要求是地址 0 + 1 => 3, 因此运行过程不涉及大小端数据存储差异
实验过程
其中 RISCV-32I 为 32 位定长指令集, 共有六种指令类型, 分别为 R I S B U J, 如下图所示
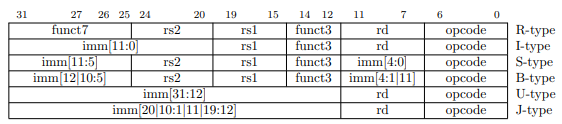
完整指令集如下图所示, 但本次实验只需要实现其中 4 条, 即用于读取内存的 LB, 写回内存的 SB, 加和的 ADD, 将寄存器值置零的XOR
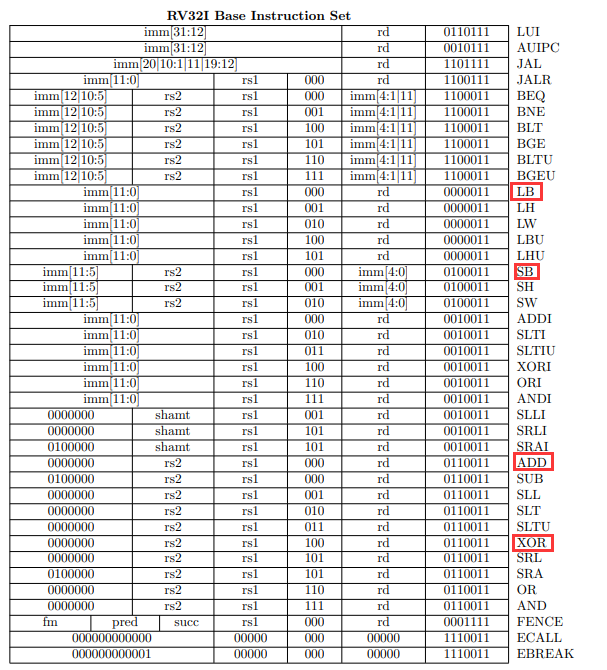
因此首先将 6 种指令类型的 opcode 以及每一种指令对应的 funct3 funct7 枚举类型定义出来
from enum import Enum
# RISCV-32I 6 种类型
class OpCode(Enum):
R = "0110011"
I = "0000011"
S = "0100011"
B = "1100011"
U = "0010111"
J = "1100111"
# 部分 I 型指令
class IFunct3(Enum):
LB = "000" # 本次需要
LH = "001"
LW = "010"
LBU = "100"
LHU = "101"
# 部分 S 型指令
class SFunct3(Enum):
SB = "000" # 本次需要
SH = "001"
SW = "010"
# 部分 R 型指令
class RFunct3(Enum):
ADD = "000" # 本次需要
SUB = "000"
SLL = "001"
SLT = "010"
SLTU = "011"
XOR = "100"
SRL = "101"
SRA = "101"
OR = "110"
AND = "111"
class RFunct7(Enum):
ADD = "0000000"
SUB = "0100000"
XOR = "0000000"主函数调用流程如下, 其中 instructions 即为五条指令的二进制汇编表示
def main():
# xor r1, r1, r1
# lb 0(r1), r2
# lb 1(r1), r3
# add r2, r3, r3
# sb 3(r1), r3
instructions = [
# 31 ---------------------------0
"00000000000100001100000010110011",
"00000000000000001000000100000011",
"00000000000100001000000110000011",
"00000000001100010000000110110011",
"00000000001100001000000110100011",
]
isa = ISA()
isa.memory[0] = 123
isa.memory[1] = 99
isa.show_info("before")
isa.load_instructions(instructions)
isa.run()
isa.show_info("after")
if __name__ == "__main__":
main()ISA 中的 run 为主体执行流程, 按照 RISCV 的设计分为 IF ID EXE MEM WB 五级流水线, 这里是单周期, 依次执行即可.
class ISA:
def run(self):
instructions_length = len(self.instructions)
while True:
self.stage_if()
self.pc += 1
self.stage_id()
self.stage_exe()
self.stage_mem()
self.stage_wb()
if self.pc >= instructions_length:
break具体的每个阶段对应的函数写的应该比较清楚了, 完成对应功能即可, 调用全局 register 和 memory 完成读取/写回