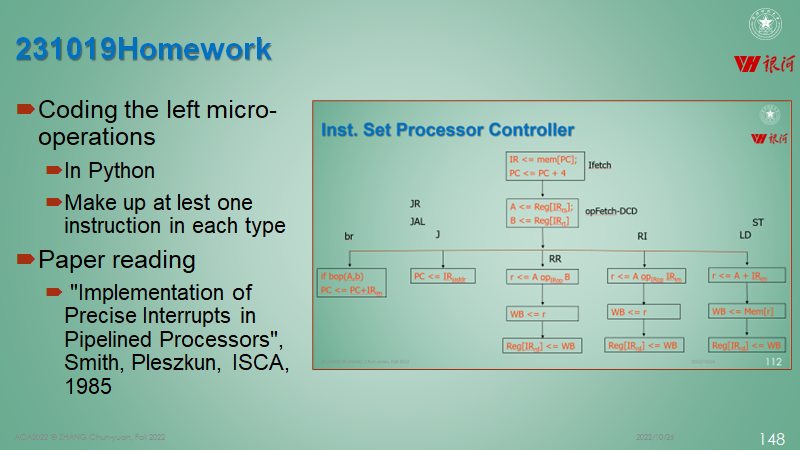
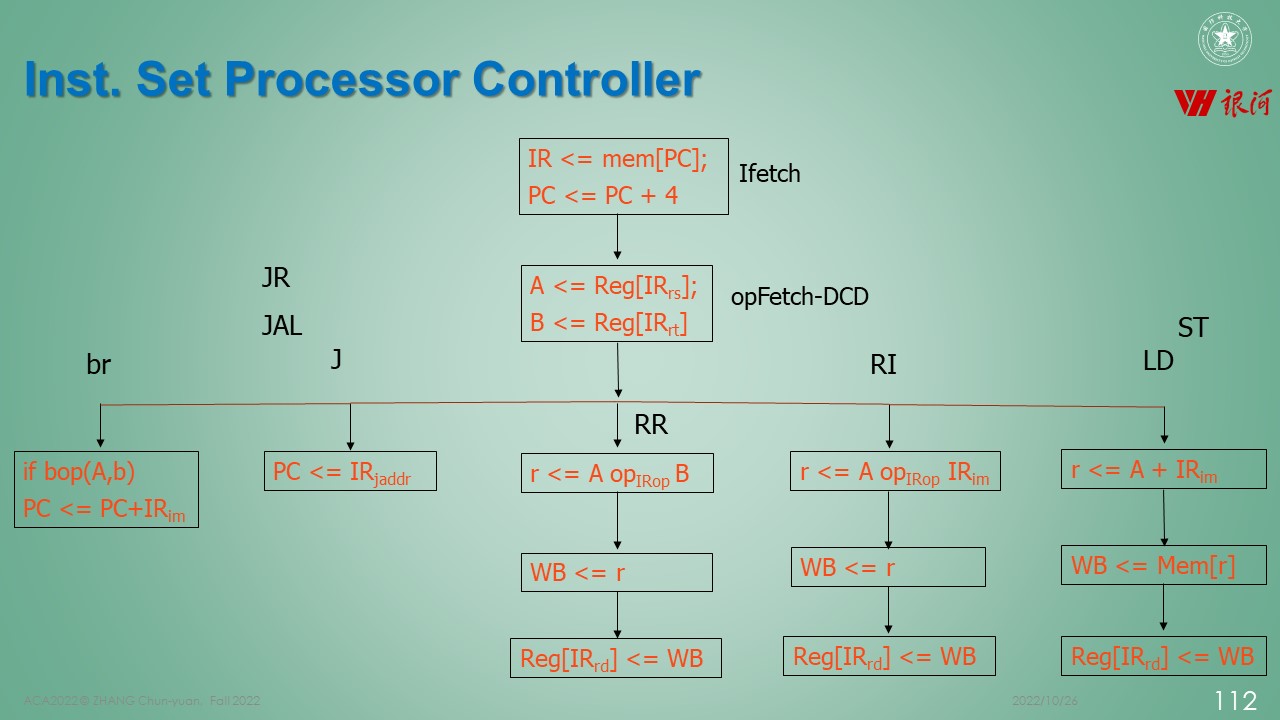
processor-controllor
作业要求:
运行结果
python src/homework2/main.pyjupyter 提交版见 main.ipynb
运行结果为一段汇编的机器码表示:
xor a0, a0, a0 # a0 置零 RR
lb a1, 0(a0) # 取地址 0 的值 LD
lb a2, 1(a0) # 取地址 1 的值 LD
L1:
addi a1, a1, 1 # a1 += 1 RI
addi a2, a2, 3 # a2 += 3 RI
bne a1, a2, L1 # if a1 != a2, goto L1 BR
jal a4, L2 # goto L2 JR
lb a5, 1(a0) # 三条无用指令, 测试 jal 跳转地址
lb a6, 1(a0)
lb a7, 1(a0)
L2:
sb a2, 3(a0) # 保存 a2 的值到地址 3 ST其中 mem[0] = 20, mem[1] = 0, RISCV 中 a0-a7 对应的是 r10-r17, 最后 mem[3] 的值是 0 和 20 以 2 为差距追逐 10 步后的 30 的结果. 且 a5 a6 a7 寄存器也没有被更新, jal 也没有问题. 结果如下
before
####################
mem[ 0] = 20 |mem[ 1] = 0 |mem[ 2] = 0 |mem[ 3] = 0 |
mem[ 4] = 0 |mem[ 5] = 0 |mem[ 6] = 0 |mem[ 7] = 0 |
mem[ 8] = 0 |mem[ 9] = 0 |mem[10] = 0 |mem[11] = 0 |
mem[12] = 0 |mem[13] = 0 |mem[14] = 0 |mem[15] = 0 |
mem[16] = 0 |mem[17] = 0 |mem[18] = 0 |mem[19] = 0 |
####################
r0 = 0 |r1 = 0 |r2 = 0 |r3 = 0 |r4 = 0 |r5 = 0 |r6 = 0 |r7 = 0 |
r8 = 0 |r9 = 0 |r10 = 0 |r11 = 0 |r12 = 0 |r13 = 0 |r14 = 0 |r15 = 0 |
r16 = 0 |r17 = 0 |r18 = 0 |r19 = 0 |r20 = 0 |r21 = 0 |r22 = 0 |r23 = 0 |
r24 = 0 |r25 = 0 |r26 = 0 |r27 = 0 |r28 = 0 |r29 = 0 |r30 = 0 |r31 = 0 |
####################
after
####################
mem[ 0] = 20 |mem[ 1] = 0 |mem[ 2] = 0 |mem[ 3] = 30 |
mem[ 4] = 0 |mem[ 5] = 0 |mem[ 6] = 0 |mem[ 7] = 0 |
mem[ 8] = 0 |mem[ 9] = 0 |mem[10] = 0 |mem[11] = 0 |
mem[12] = 0 |mem[13] = 0 |mem[14] = 0 |mem[15] = 0 |
mem[16] = 0 |mem[17] = 0 |mem[18] = 0 |mem[19] = 0 |
####################
r0 = 0 |r1 = 0 |r2 = 0 |r3 = 0 |r4 = 0 |r5 = 0 |r6 = 0 |r7 = 0 |
r8 = 0 |r9 = 0 |r10 = 0 |r11 = 30 |r12 = 30 |r13 = 0 |r14 = 284 |r15 = 0 |
r16 = 0 |r17 = 0 |r18 = 0 |r19 = 0 |r20 = 0 |r21 = 0 |r22 = 0 |r23 = 0 |
r24 = 0 |r25 = 0 |r26 = 0 |r27 = 0 |r28 = 0 |r29 = 0 |r30 = 0 |r31 = 0 |
####################实验报告
实验分析
第二次作业和第一次作业关联性很大, 也是在初始指令集架构的基础上进行扩展, 完成几组类型的指令
- 分支指令
- 跳转指令
- 寄存器 & 寄存器的运算指令
- 寄存器 & 立即数的运算指令
- 访存指令
RISCV-32I 指令集回顾
RV32I指令集中包含了40条基础指令,涵盖了整数运算/存储器访问/控制转移和系统控制几个大类.本实验中无需实现系统控制的ECALL/EBREAK/内存同步FENCE指令及CSR访问指令,所以共需实现37条指令
RV32I的指令编码非常规整,分为六种类型,其中四种类型为基础编码类型,其余两种是变种:

每种指令的格式划分如上图所示, 其中需要注意的是
- B 型指令和 J 型指令除了需要按照说明重新拼接立即数 imm , 此外 imm 是没有 imm[0] 项的, 也就是拼接后需要左移一位
这是考虑到 riscv 32I 指令集定长, 且 4 字节对齐, 所以转移指令只需要跳转到偶数地址即可, 扩大跳转范围. J 的 imm 有 20 位, 比 B 的 13 位 imm 更大, 可跳转的 PC 范围更大
- U 型指令的 imm 是 [31:12], 所以最后需要左移 12 位
U 型指令是一个长指令, 提供了 lui 的大立即数赋值指令和 auipc 长地址跳转指令. U 的 imm 对应的是立即数的 [31:12] 位, 低12位需要补零来得到一个完整的 32 位立即数

- 所有带 imm 的指令都是考虑补码形式的, I S B U J, 如果 imm 首位为 1 则需要按照补码形式进行计算
跳转指令部分会经常用到
- 虽然说只有六种指令类型, 但是每一种指令类型的 Opcode 不是唯一

R 型指令(10)
寄存器操作数指令,含2个源寄存器rs1,rs2和一个目的寄存器rd
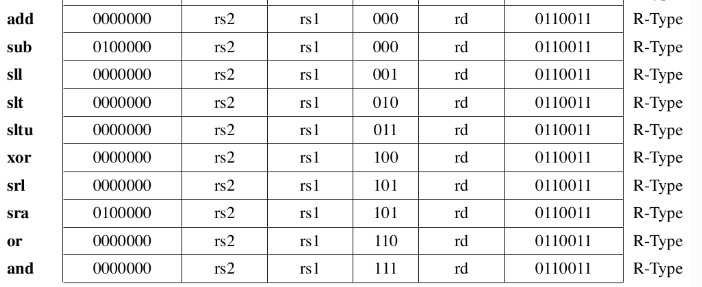
需要额外注意的是大部分指令可以通过 funct3 直接区分确定, 但 add/sub, srl/sra 的 funct3 相同, 需要依靠 funct7 来确定. 这种设计很巧妙,因为 funct3 只有三位, 总共8种, 但需要表示10种指令; 与此同时 add/sub srl/sra 的功能十分接近, 例如 sub 只需要取反加一, sra 只需要转换移位方向. 所以只需要在 funct7[1] 的那一位引脚接一个取反装置即可, 设计的比较优雅.
I 型指令(15)
立即数操作指令,含一个源寄存器和一个目的寄存器和一个12bit立即数操作数
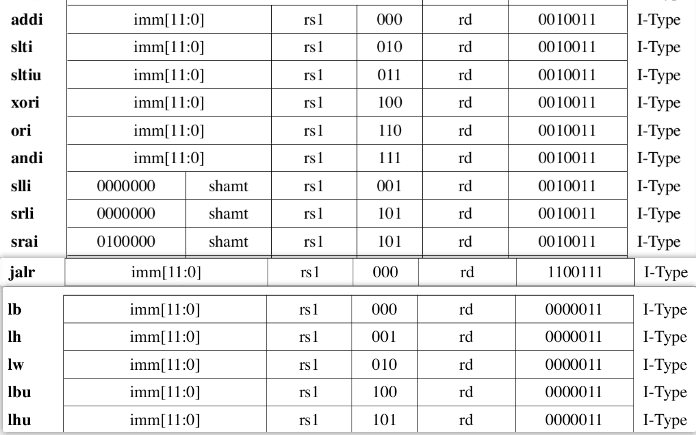
I 型指令的 OpCode 有三类, 分别是计算类的
I_CALC(0010011), 跳转I_JALR(1100111)和访存I_LOAD(0000011)
S 型指令(3)
存储器写指令,含两个源寄存器和一个12bit立即数

B 型指令(6)
跳转指令,实际是S-Type的变种.与S-Type主要的区别是立即数编码
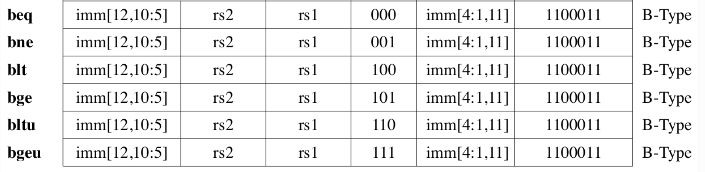
U 型指令(2)
长立即数指令,含一个目的寄存器和20bit立即数操作数

J 型指令(1)
长跳转指令,实际是U-Type的变种
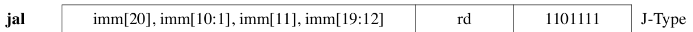
RISCV-32I 汇编
了解所有的 37 条指令之后就需要手动编写汇编指令, 然后利用 GNU 的工具编译为机器代码以及查看反汇编二进制形式
寄存器出现顺序是 rd > rs2 > rs1, 例如 Inst rd, rs2, rs1, 立即数括号括起来, 如 Inst a0, 100(a1)
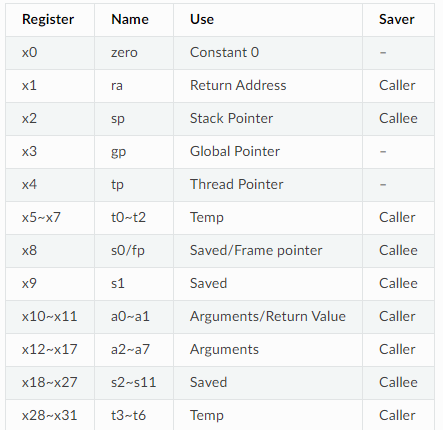
寄存器表, RISCV 对于寄存器(register)和寄存器名(name)做了一组映射, 编写汇编的时候使用的应该是 name 的部分, 这里使用 a0-a7 就可以了
题目中要求完成所有基础指令, 这里笔者构建了如下的一段汇编代码
xor a0, a0, a0 # a0 置零 RR
lb a1, 0(a0) # 取地址 0 的值 LD
lb a2, 1(a0) # 取地址 1 的值 LD
L1:
addi a1, a1, 1 # a1 += 1 RI
addi a2, a2, 3 # a2 += 3 RI
bne a1, a2, L1 # if a1 != a2, goto L1 BR
jal a4, L2 # goto L2 JR
lb a5, 1(a0) # 三条无用指令, 测试 jal 跳转地址
lb a6, 1(a0)
lb a7, 1(a0)
L2:
sb a2, 3(a0) # 保存 a2 的值到地址 3 ST上面的部分就是一个比较简单的取地址, 各自自增然后比较, 如果不相同则循环, 否则跳出. 也覆盖了所有的指令功能情况
然后需要通过编译器将汇编语言转换为机器码, 这里需要 RISCV-gcc 的编译器, 编译时需要编译为 RSICV-32 平台的可执行文件, 所以需要两个编译选项指定 arch 和 ABI
sudo apt-get install gcc-riscv64-linux-gnu binutils-riscv64-linux-gnu将上述代码保存为 example.S
riscv64-linux-gnu-gcc -march=rv32i -mabi=ilp32 -c example.S -o example.o
riscv64-linux-gnu-objdump example.o -d扩展的小知识: riscv-gcc 编译选项
- -march=rv32i:生成针对32位基本整数指令集(RV32I)的代码.
- -march=rv32im:生成针对32位整数乘法扩展(M)的代码.
- -march=rv32imac:生成针对32位整数乘法和原子扩展(IMAC)的代码.
- -march=rv32gc:生成针对32位整数乘法/原子和压缩指令扩展(GC)的代码.
- -march=rv64i:生成针对64位基本整数指令集(RV64I)的代码.
- -march=rv64im:生成针对64位整数乘法扩展(M)的代码.
- -march=rv64imac:生成针对64位整数乘法和原子扩展(IMAC)的代码.
- -march=rv64gc:生成针对64位整数乘法/原子和压缩指令扩展(GC)的代码.
- -march=rv32i 和 -march=rv64i 用于生成纯整数指令集的代码,而 -march=rv32g 和 -march=rv64g 用于生成全能指令集的代码
- -mabi=ilp32:生成针对32位整数类型的ILP32 ABI的代码.这是默认的ABI.
- -mabi=ilp32d:生成针对32位整数类型的ILP32 ABI,但使用双精度浮点寄存器.
- -mabi=lp64:生成针对64位整数类型的LP64 ABI的代码.
- -mabi=lp64d:生成针对64位整数类型的LP64 ABI,但使用双精度浮点寄存器.
编译 & 反汇编得到如下所示的结果
Disassembly of section .text:
00000000 <L1-0xc>:
0: 00a54533 xor a0,a0,a0
4: 00050583 lb a1,0(a0)
8: 00150603 lb a2,1(a0)
0000000c <L1>:
c: 00158593 addi a1,a1,1
10: 00360613 addi a2,a2,3
14: fec59ce3 bne a1,a2,c <L1>
18: 0100076f jal a4,28 <L2>
1c: 00150783 lb a5,1(a0)
20: 00150803 lb a6,1(a0)
24: 00150883 lb a7,1(a0)
00000028 <L2>:
28: 00c501a3 sb a2,3(a0)至此得到了本次需要执行的代码
instructions = [
0x00A54533,
0x00050583,
0x00150603,
0x00158593,
0x00360613,
0xFEC59CE3,
0x0100076f,
0x00150783,
0x00150803,
0x00150883,
0x00c501a3,
]代码实现
本次较上次代码整体架构修改较大, 考虑到后续的复用性和扩展性, 重新设计了一下调用流程, 采用面向对象的方式
src/homework2 目录结构如下
.
├── Makefile # make 编译 + 反汇编
├── example.S # 汇编程序
├── instructions.py # 所有指令实现
├── isa.py # ISA 实现
├── main.ipynb # 需要提交的作业(没用到, 不重要)
└── main.py # 主函数, RISCV ISA 实现其中 isa.py 中实现的基础 ISA 的处理器执行架构, 以及指令 Instruction 的基类
class ISA:
"""
基础处理器架构
"""
def __init__(self) -> None:
# 基础配置信息
register_number = 32
memory_range = 0x200
self.pc = 0
self.registers = [0] * register_number # 寄存器组
self.memory = [0] * memory_range # 内存
self.instruction: Instruction = None # 当前指令
self.instruction_info = InstructionInfo() # 当前指令的信息拆分
self.IR = IR()
class Instruction:
def __init__(self, isa: "ISA") -> None:
self.isa = isa
self.pc_inc = True
def stage_ex(self):
"""
EX-执行.对指令的各种操作数进行运算
IF ID 阶段操作相对固定, EX MEM WB 阶段需要根据具体指令在做调整
单指令可以继承 Instruction 类并重写此方法
"""
def stage_mem(self):
"""
MEM-存储器访问.将数据写入存储器或从存储器中读出数据
单指令可以继承 Instruction 类并重写此方法
"""
def stage_wb(self):
"""
WB-写回.将指令运算结果存入指定的寄存器
单指令可以继承 Instruction 类并重写此方法
"""
if self.pc_inc:
self.isa.pc += 4instructions.py 中的所有 RISCV-32I 的指令都需要继承 Instruction 类, 并覆写该指令对应的 EX MEM WB 三阶段内容, 例如 addi 指令
class I_ADDI(Instruction):
def stage_ex(self):
self.isa.IR.value = self.isa.IR.rs1 + self.isa.instruction_info.imm
def stage_wb(self):
self.isa.registers[self.isa.instruction_info.rd] = self.isa.IR.value
return super().stage_wb()主函数执行时, 首先初始化一个继承自 ISA 的 RISCV32 处理器, 设置内存地址 0 1 位置的值(这是考虑到写的汇编指令需要值循环判断执行), 然后 load_instructions 导入指令后执行 run
def main():
instructions = [
0x00A54533,
0x00050583,
0x00150603,
0x00158593,
0x00360613,
0xFEC59CE3,
0x0100076f,
0x00150783,
0x00150803,
0x00150883,
0x00c501a3,
]
isa = Riscv32()
isa.memory[0] = 20
isa.memory[1] = 0
isa.show_info("before")
isa.load_instructions(instructions)
isa.run()
isa.show_info("after")
if __name__ == "__main__":
main()load_instructions 导入代码段的位置是 0x100, 使用小端存储在内存中
def load_instructions(self, instructions, pc=0x100):
self.pc = pc
# 小端存储
for inst in instructions:
instruction_str = format(inst, "032b")
self.memory[pc + 3] = int(instruction_str[:8], 2)
self.memory[pc + 2] = int(instruction_str[8:16], 2)
self.memory[pc + 1] = int(instruction_str[16:24], 2)
self.memory[pc] = int(instruction_str[24:], 2)
pc += 4run 时依次执行 ISA 的五个阶段, IF 阶段从 PC 处小端存储的方式取指, 如果全 0 则认为结束. ID 阶段由不同指令集不同实现, 因此需要 RISCV32 覆写此方法
def run(self):
while True:
self.stage_if()
if self.pc == -1:
break
self.stage_id()
self.stage_ex()
self.stage_mem()
self.stage_wb()
def stage_if(self):
"""
IF-取指令.根据PC中的地址在指令存储器中取出一条指令
"""
# 小端取数
self.instruction = ""
self.instruction += format(self.memory[self.pc + 3], "08b")
self.instruction += format(self.memory[self.pc + 2], "08b")
self.instruction += format(self.memory[self.pc + 1], "08b")
self.instruction += format(self.memory[self.pc], "08b")
# 全 0 默认运行完所有指令, 退出
if int(self.instruction) == 0:
self.pc = -1
def stage_id(self):
"""
ID-译码 解析指令并读取寄存器的值
"""
raise NotImplementedError("should implement stage ID")ID 阶段除了需要切分判断不同格式, 还需要具体定位到是哪一条指令, 然后将其实例化
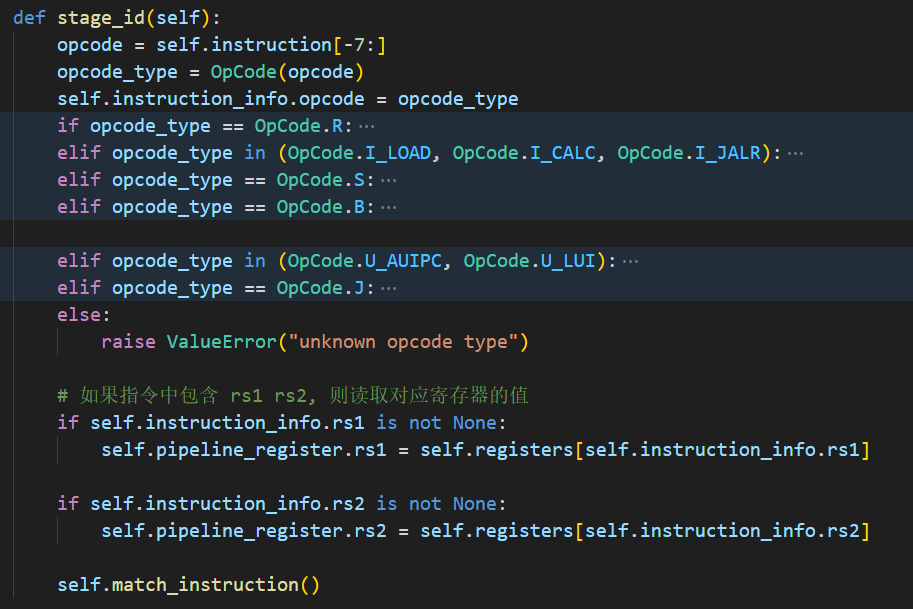
这里定义了一个字典, 用于对应所有指令的类名
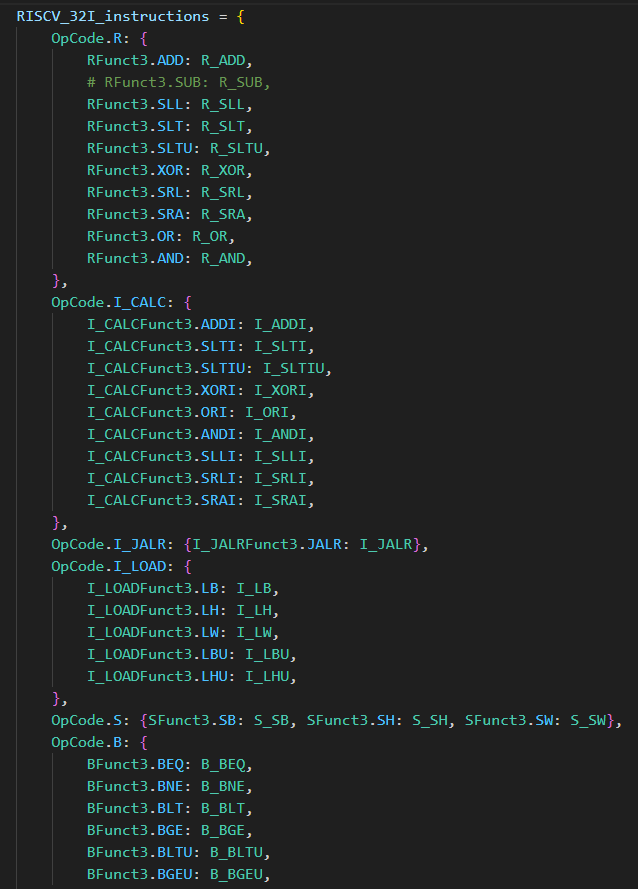
对于一些特殊情况单独做判断, 其余的在列表中索引找到, 并将类实例化为对象保存在 instruction 当中
if (
self.instruction_info.funct3 == RFunct3.SUB
and self.instruction_info.funct7 == RFunct7.SUB
):
self.instruction = R_SUB(self)
elif (
self.instruction_info.funct3 == RFunct3.SRA
and self.instruction_info.funct7 == RFunct7.SRA
):
self.instruction = R_SRA(self)
elif self.instruction_info.opcode == OpCode.U_AUIPC:
self.instruction = U_AUIPC(self)
elif self.instruction_info.opcode == OpCode.U_LUI:
self.instruction = U_LUI(self)
elif self.instruction_info.opcode == OpCode.J:
self.instruction = J_JAL(self)
else:
self.instruction = RISCV_32I_instructions[self.instruction_info.opcode][
self.instruction_info.funct3
](self)这种设计的好处就在于, ISA 的后面三个阶段便可交由指令自己执行, 大大提高了指令的扩展性, 不再需要写一个个的 if else 了
class ISA:
def stage_ex(self):
"""
EX-执行.对指令的各种操作数进行运算
"""
self.instruction.stage_ex()
def stage_mem(self):
"""
MEM-存储器访问.将数据写入存储器或从存储器中读出数据
"""
self.instruction.stage_mem()
def stage_wb(self):
"""
WB-写回.将指令运算结果存入指定的寄存器
"""
self.instruction.stage_wb()如果想要新增一条指令, 只需要简单的继承 Instruction, 然后在指令集字典中注册一下即可
class R_XOR(Instruction):
def stage_ex(self):
self.isa.IR.value = (
self.isa.IR.rs1 ^ self.isa.IR.rs2
)
def stage_wb(self):
self.isa.registers[self.isa.instruction_info.rd] = self.isa.IR.value
return super().stage_wb()需要额外注意的一点是, RISCV 的跳转指令的偏移量是当前指令的 PC. 下面的 bne 跳转到 L1 的位置, 此时 imm 的值为 -8, 也就是说从 0x14 跳转到 0xc 的位置执行
这一点和 X86 不同, X86 取指阶段后直接 pc 变化了, RISCV 最后阶段才更新 PC
0000000c <L1>:
c: 00158593 addi a1,a1,1
10: 00360613 addi a2,a2,3
14: fec59ce3 bne a1,a2,c <L1>
18: 0100076f jal a4,28 <L2>
1c: 00150783 lb a5,1(a0)
20: 00150803 lb a6,1(a0)
24: 00150883 lb a7,1(a0)
00000028 <L2>:
28: 00c501a3 sb a2,3(a0)因此笔者在设计 Instruction 基类的时候留了一个 pc_inc 变量控制是否自增 PC, 对于 B J 型指令只需要设置 pc_inc = False 即可
def stage_wb(self):
"""
WB-写回.将指令运算结果存入指定的寄存器
单指令可以继承 Instruction 类并重写此方法
"""
if self.pc_inc:
self.isa.pc += 4最后的执行结果
mem[ 0] = 20 |mem[ 1] = 0 |mem[ 2] = 0 |mem[ 3] = 30 |
mem[ 4] = 0 |mem[ 5] = 0 |mem[ 6] = 0 |mem[ 7] = 0 |
mem[ 8] = 0 |mem[ 9] = 0 |mem[10] = 0 |mem[11] = 0 |
mem[12] = 0 |mem[13] = 0 |mem[14] = 0 |mem[15] = 0 |
mem[16] = 0 |mem[17] = 0 |mem[18] = 0 |mem[19] = 0 |
####################
r0 = 0 |r1 = 0 |r2 = 0 |r3 = 0 |r4 = 0 |r5 = 0 |r6 = 0 |r7 = 0 |
r8 = 0 |r9 = 0 |r10 = 0 |r11 = 30 |r12 = 30 |r13 = 0 |r14 = 284 |r15 = 0 |
r16 = 0 |r17 = 0 |r18 = 0 |r19 = 0 |r20 = 0 |r21 = 0 |r22 = 0 |r23 = 0 |
r24 = 0 |r25 = 0 |r26 = 0 |r27 = 0 |r28 = 0 |r29 = 0 |r30 = 0 |r31 = 0 |RISCV 中 a0-a7 对应的是 r10-r17, 最后 mem[3] 的值是 0 和 20 以 2 为差距追逐 10 步后的 30 的结果. 且 a5 a6 a7 寄存器也没有被更新, jal 也没有问题