Tomasulo

运行结果
运行标准示例程序, 与前面的 scoreboard 的示例程序相同, 但采用 tomasulo 算法
python src/homework5/main.py完整输出见 classic_example.txt
----------------------------------------------------------------------
[instruction status]
Op dest j k | Issue Exec Write
Load F6 34 R2 | 1 3 4
Load F2 45 R3 | 2 4 5
Mul F0 F2 F4 | 3 15 16
Sub F8 F6 F2 | 4 7 8
Div F10 F0 F6 | 5 56 57
Add F6 F8 F2 | 6 10 11完成本次要求的作业, 三次循环展开
python src/homework5/loop.py完整输出见 loop.txt
----------------------------------------------------------------------
[instruction status]
Op dest j k | Issue Exec Write
Load F0 0 R2 | 1 3 4
Add F2 F0 R3 | 2 6 7
Store F2 0 R2 | 3 8 9
Load F4 -4 R2 | 4 6 7
Add F6 F4 R3 | 5 9 10
Store F6 -4 R2 | 6 11 12
Load F8 -8 R2 | 7 9 10
Add F10 F8 R3 | 8 12 13
Store F10 -8 R2 | 9 14 15Tomasulo 算法
思路
前文提到的 Scoreboard 算法利用多个功能部件实现指令的发射与乱序执行, 同时由控制单元精确监控各条指令之间数据冒险, 如果出现冲突则依然需要 暂停发射, 等待执行结束 或者 延迟写回, 因此导致指令发射停滞,指令流截断, 也大大地影响了处理器性能
那么为了解决上述问题, 我们希望最大限度地挖掘出指令的乱序潜力, 即更有效地处理指令间的数据冒险. 数据相关有四种,分别是读后读/读后写/写后写/写后读.其中"读后读"不会影响指令的执行,所以提数据相关的时候一般忽略"读后读"
对于 WAW 和 WAR 来说, 其实它们并不是真正的数据冒险, 因为我们可以采用寄存器重命名的方式消除掉这两种冒险, 如下图所示

处理器需要的只是这两条指令的计算结果, 这个结果计算出来放在哪里不重要, 只需要为它找到一个以后可以找到的空位就可以了. 因此"写后写"和"读后写"冒险不是真冒险,没必要为他们阻塞指令的流动
但是"写后读"冒险无法解决,因为后序指令读取的数据由前序指令算得,这个过程有明确的数据依赖.
Scoreboard算法的问题就是太局限于寄存器的名字,特别典型的就是记分牌会因为写后写冒险而阻塞流水,即记分牌会为一个没用的/马上就被覆盖的旧值而阻塞新值的写入,这个做法在Tomasulo面前着实有些古板和僵硬了. Tomasulo 算法可以在逻辑寄存器之外额外有一组物理寄存器, 即为处理器提供超过逻辑寄存器数量的寄存器
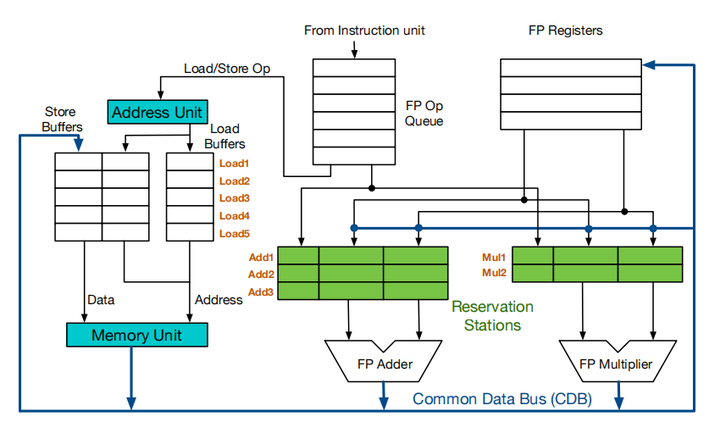
tomasulo 的设计结构如上图所示, 其中与 scoreboard 设计结构上最大的区别是: scoreboard 的每一个功能单元都对应一个真实物理部件, tomasulo 可以利用缓冲区将 add1/2/3 共用一个物理部件, 只有在执行的时候才会真正占用该功能部件
绿色模块是加法单元和乘法单元的保留站, Tomasulo算法为每一条通路配置了一组缓冲, 指令可以在功能单元忙碌的时候发射到保留站的缓冲区待命
算法流程
Tomasulo 的状态少了很多
Busy: 单元是否繁忙
Op: 部件执行的指令类型
V_j: 源寄存器 j 的值
V_k: 源寄存器 k 的值
Q_j: 如果源寄存器 j 的值暂不可读, 部件该向哪个功能单元要数据
Q_k: 如果源寄存器 k 的值暂不可读, 部件该向哪个功能单元要数据
A: 地址, 对于 Load/Store Unit 有效
同时只有三个阶段: ISSUE EXEC WRITE_BACK
需要注意的是, ISSUE 阶段
下面的部分假定 Load/Store 指令的 EX 需要 1 个周期, add 的 EX 需要 2 个周期
CLOCK 0
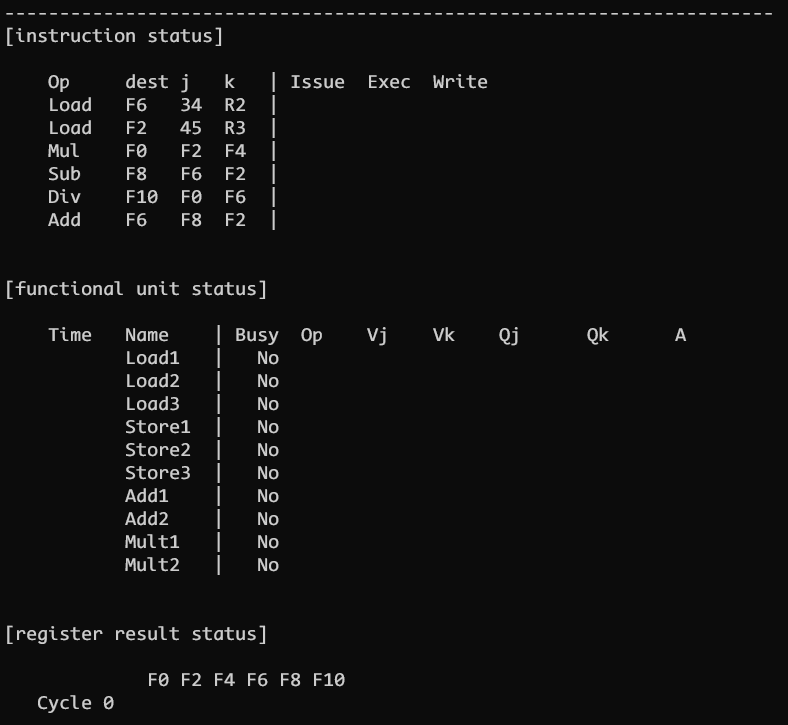
执行的指令序列和 scoreboard 相同, tomasulo 的功能单元一共有 4 种, 其中 load/store/add/mult 的 buffer 数量分别为 3/3/2/2
CLOCK 1
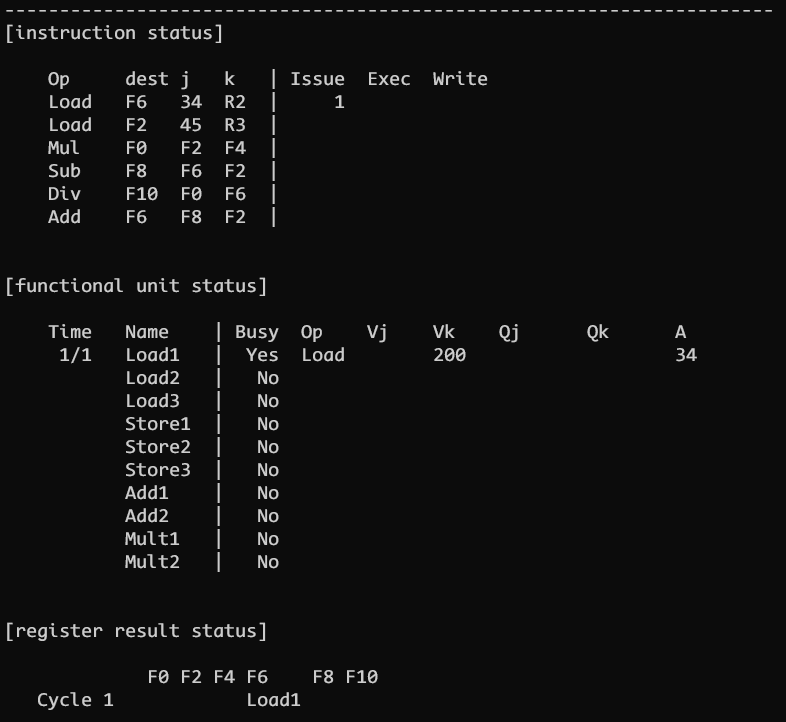
CLOCK 1 发射第一条指令, 读取所有寄存器的值并更新 Vk, 并将 A 地址更新为立即数 j 的值
CLOCK 2
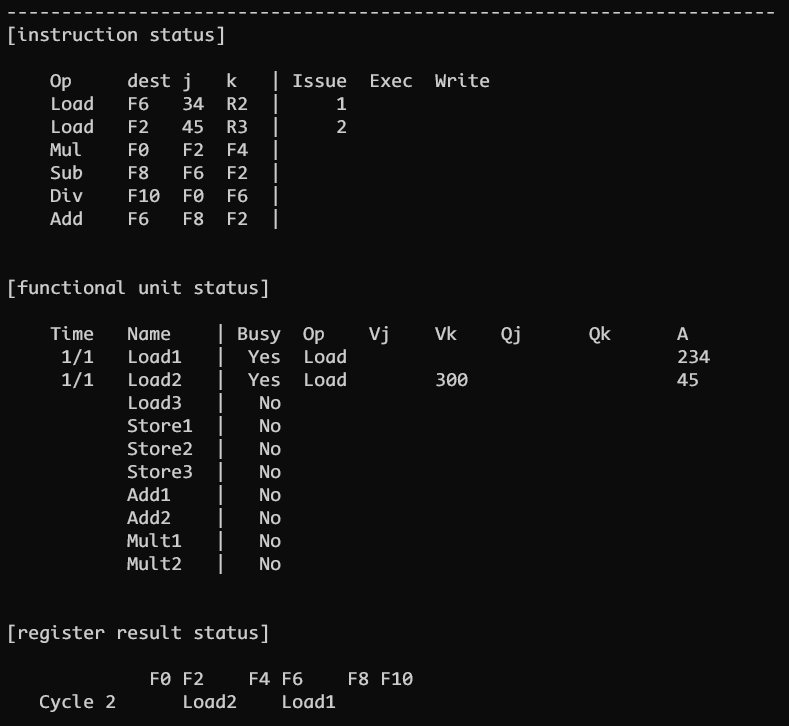
CLOCK 2 及之后的周期都需要做两件事情, 第一能否发射下一条指令, 第二执行所有已发射的指令
判断能否发射的唯一标准是指令对应通路的保留站是否有空余位置,只要保留站有空余,就可以把指令发射到保留站中, 这样大大减少了因为数据冒险冲突导致流水线发射中断的情况
发射指令 2, 更新对应的 unit 的状态. 同时需要注意的是指令 1 并没有进入 EXEC 阶段, 而是仍然处于 ISSUE 阶段, 但是完成了对于最终目的地址 A 的计算
也就是说对于 立即数 + 寄存器值 类型的指令, ISSUE 都需要两个周期, 第一个周期读数, 第二个周期计算. EXEC 执行阶段用来执行对应指令的内容
CLOCK 3
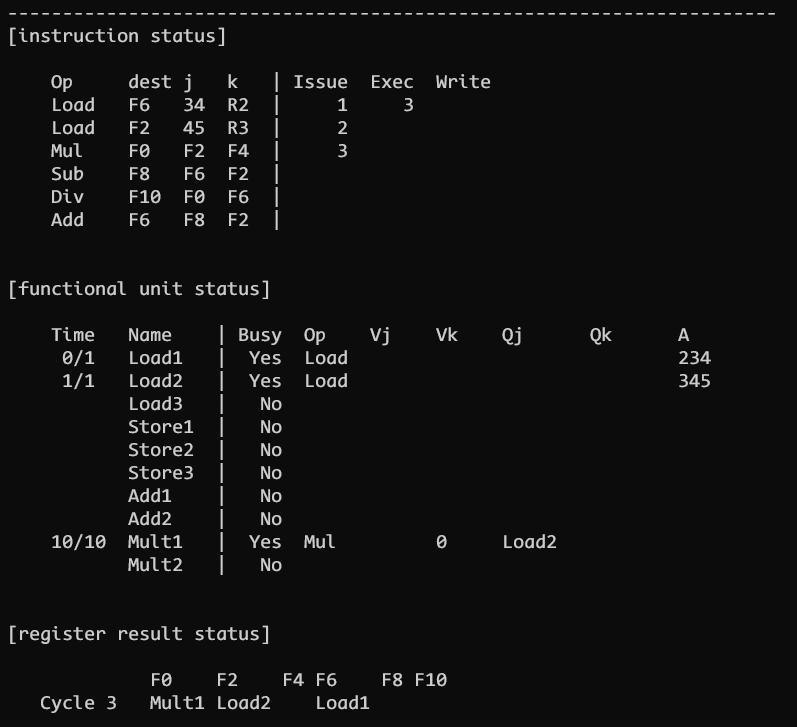
CLOCK 3 发射指令 3, 指令 1 进入 EXEC 阶段, 指令 2 仍处于 ISSUE 并计算得到 A
此时发射的指令 3 的 F2 源寄存器与指令 2 的目的寄存器 F2 冲突, 这是一个 RAW 的数据冒险, 没有办法避免, 所以设置 Qj 为 load2 等待对于功能单元写回
后续阶段的执行方式与 scoreboard 类似, 不再赘述
实验报告
实验分析
本次实验是要求执行三次循环, 由于 Tomasulo 无法处理 bne 等跳转指令,因此通过循环展开直接删除 bne, 进而直接删除对 R2 的整数加法 addi, 改为直接使用立即数 -4 -8 来计算地址
通过寄存器重命名的方式处理 WAW,所以每一轮循环分别采用两个寄存器 a0/a2 a4/a6 a8/10, 因此最后执行的汇编指令如下
lw a0,0(R2)
fadd a2,a0,R3
sw a2,0(R2)
lw a4,-4(R2)
fadd a6,a4,R3
sw a6,-4(R2)
lw a8,-8(R2)
fadd a10,a8,R3
sw a10,-8(R2)这里有一个额外的问题需要注意, 就是这个 store 指令, 之前的例子中没有提到. sw 这个指令的格式是 sw rd, imm(rs1), 但是它的 rd 位置上的寄存器并不是目的寄存器, issue 阶段就可以把 F2 R2 和 imm 的值都读出来,然后再一个周期算出来目的地址 A = imm + (R2), 然后 EX 阶段把 F2 的值写入到 A 地址
与此同时 lw 与 fadd, fadd 与 sw 都存在 RAW 这种不可避免的数据冒险, 所以都需要等待前一阶段的指令完成写回后才可以执行
代码实现
基本代码框架和 scoreboard 代码类似, 但是需要修改几个地方. 首先是新建了一个 Buffer 类, 每个类内创建 unit, 充当一个功能单元的缓冲区
class Buffer:
def __init__(self, function: UnitFunction, buffer_size: int) -> None:
self.units: List["Unit"] = []
self.function = function
for i in range(1, buffer_size + 1):
unit = Unit(name=f"{function.value}{i}", function=function)
unit.buffer = self
self.units.append(unit)
class Tomasulo:
def __init__(self, rg: RegisterGroup) -> None:
self.instructions: List[Instruction] = []
self.issued_instructions: List[Instruction] = []
self.pc: int = 0
self.functional_buffers: List[Buffer] = [
Buffer(function=UnitFunction.LOAD, buffer_size=3),
Buffer(function=UnitFunction.STORE, buffer_size=3),
Buffer(function=UnitFunction.ADD, buffer_size=2),
Buffer(function=UnitFunction.MULT, buffer_size=2),
]
self.register_group = rg核心的 run 阶段与之前类似, 需要注意的是当全部指令都已发射并且所有 buffer 的所有功能单元都空闲时退出, 判断是否可以发射下一条指令(has_available_buffer)只需要判断 对应的功能单元是否还有 buffer
class Tomasulo:
def run(self):
self.show_status()
global CLOCK
CLOCK += 1
instruction_length = len(self.instructions)
while True:
# 当全部指令都已发射并且所有 buffer 的所有功能单元都空闲时退出
if self.pc == instruction_length:
busy_unit_number = 0
for buffer in self.functional_buffers:
busy_unit_number += buffer.get_busy_unit_number()
if busy_unit_number == 0:
break
# 尝试发射一条新指令
# 1. 如果有指令
# 2. 对应的功能单元还有 buffer
# 则发射下一条指令
if self.pc != instruction_length:
unit = self.has_available_buffer(self.instructions[self.pc].unit_function)
if unit is not None:
self.instructions[self.pc].unit = unit
unit.instruction = self.instructions[self.pc]
self.issued_instructions.append(self.instructions[self.pc])
self.pc += 1
# 所有指令发射后交由指令本身去执行
# 指令内部维护 issue + read -> exec -> write 的执行顺序
for issued_instruction in self.issued_instructions:
issued_instruction.run()
# 所有指令都执行结束之后一起更新 unit 的 Qj Qk 的状态, 避免指令串行更新的干扰
for buffer in self.functional_buffers:
for unit in buffer.units:
if unit.status.Q_j and unit.status.Q_j.status.Busy == False:
unit.status.V_j = unit.status.Q_j.instruction.dest.value
unit.status.Q_j = None
if unit.status.Q_k and unit.status.Q_k.status.Busy == False:
unit.status.V_k = unit.status.Q_k.instruction.dest.value
unit.status.Q_k = None
self.show_status()
CLOCK += 1
def has_available_buffer(self, unit_function: UnitFunction) -> Optional[Unit]:
"""
检查当前缓冲区是否还有 unit_function 类的功能单元可用
如有返回对应的 Unit
没有返回 None
"""
for buffer in self.functional_buffers:
if buffer.function == unit_function:
for unit in buffer.units:
if unit.status.Busy == False:
return unit
return NoneInstruction 的 run 阶段就是按照 Tomasulo 的算法来, 其中值得注意的是当指令试图从 ISSUE 阶段进入 EXEC 阶段, 此时既需要检查 Qj Qk, 也需要检查当前 buffer 没有其他指令正在执行, 即 check_exec_instruction. 因为一个 buffer 虽然内部有很多个虚拟的 unit, 但是只对应一个物理的功能单元, 也就是说同一时刻只能执行一条指令
class Instruction:
def run(self):
...
elif self.stage == InstructionStage.ISSUE:
# 如果有需要等待的数据, 直接返回
if self.unit.status.Q_j or self.unit.status.Q_k:
return
# 进入执行阶段前需要判断当前 buffer 是否有其他正在执行的单元
# 因为只有一个功能部件, 如果有其他指令正在使用则当前指令需要等待
if self.unit.buffer.check_exec_instruction():
return
self.stage = InstructionStage.EXEC
self.left_latency -= 1
if self.left_latency == 0:
self.return_value = self.unit.exec()
self.stage_clocks.append(CLOCK)
self.stage = InstructionStage.WRITE
elif self.stage == InstructionStage.EXEC:
self.left_latency -= 1
if self.left_latency == 0:
self.return_value = self.unit.exec()
self.stage_clocks.append(CLOCK)
self.stage = InstructionStage.WRITE